I.K. GUJRAL PUNJAB TECHNICAL UNIVERSITY, JALANDHAR
GJIMT || 2022
A
Laboratory File
On
Artificial Intelligence & Soft Computing
Submitted
For
Master of Computer Applications
In
GJIMT Lab
At
Gian Jyoti Institute of Management and Technology
2022
Subject Code:- PGCA1929
Submitted To:-
Submitted By:-
Ms. Harmeet Kaur (Astt. Peofessor)
Manjit Sir (Lab Incharge)
GJIMT Mohali
Ajit Kumar
MCA 3rd Semester
Roll No.:-2111914
GJIMT || 2022
-: INDEX :Sr. No
1.
2.
3.
Experiment
Page No.
Use logic programming in Python to check for prime
numbers.
Use logic programming in Python parse a family tree and
infer the relationships between the family members.
3
4, 5, 6, 7, 8
4.
Python script for building a puzzle solver.
Implementation of uninformed search techniques in
Python.
5.
Implementation of heuristic search techniques in Python.
6.
Python script for tokenizing text data.
17, 18
7.
19, 20
8.
Extracting the frequency of terms using a Bag of Words
model.
Predict the category to which a given piece of text belongs.
9.
Python code for visualizing audio speech signal.
10.
Python code for Generating audio signals.
26, 27, 28, 29
Create a perception with appropriate no. of inputs and
outputs. Train it using fixed increment learning algorithm
30. 31, 32
until no change in weights is required. Output the final
weights.
Implement AND function using ADALINE with bipolar
33, 34, 35
inputs and outputs.
Implement AND function using MADALINE with bipolar
36, 37, 38
inputs and outputs.
Construct and test auto associative network for input
39
vector using HEBB rule.
Construct and test auto associative network for input
40
vector using outer product rule.
Construct and test heteroassociative network for binary
41, 42, 43
inputs and targets.
11.
12.
13.
14.
15.
16.
17.
Create a back propagation network for a given input
pattern. Perform 3 epochs of operation.
18.
Implement Union, Intersection, Complement and
Difference operations on fuzzy sets. Also create fuzzy
relation by Cartesian product of any two fuzzy sets and
perform maxmin composition on any two fuzzy relations.
Maximize the function f(x)=x2 using GA, where x ranges
form 0-25. Perform 6 iterations.
19.
Remarks
9, 10
11, 12
13, 14, 15, 16
21, 22, 23
24, 25
44, 45, 46
47, 48, 49,
50, 51, 52
53, 54
Page | 2
GJIMT || 2022
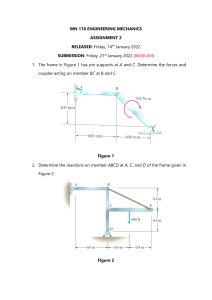
Experiment:- 01
Aim:- Use logic programming in Python to check for prime numbers.
Prime Numbers:- Prime numbers are natural numbers that are divisible by only 1
and the number itself.
Example:- 2, 3, 5, 7, 11, 13, etc.
Code:# Input from the user
num = int(input("Enter a number: "))
# If number is greater than 1
if num > 1:
# Check if factor exist
for i in range(2,num):
if (num % i) == 0:
print(num,"is not a prime number")
break
else:
print(num,"is a prime number")
else:
print(num,"is not a prime number")
Output:-
Page | 3
GJIMT || 2022
Experiment:- 02
Aim:- Use logic programming in Python parse a family tree and infer the relationships between
the family members.
Family Tree: The core of the Family Tree data model are the individual persons that, linked
together by relationships, create the Tree. The purpose of the other data objects is
to give support and detailed information about the person, relationships and the
research recorded in the Family Tree.
Parsing a family tree: Now that we are more familiar with logic programming, let's use it to solve
an interesting problem. Consider the following family tree:-
John and Megan have three sons - William, David, and Adam. The wives of
William, David, and Adam are Emma, Olivia, and Lily respectively. William and
Emma have two children - Chris and Stephanie. David and Olivia have five
children - Wayne, Tiffany, Julie, Neil, and Peter. Adam and Lily have one child Sophia. Based on these facts, we can create a program that can tell us the name of
Wayne's grandfather or Sophia's uncles are. Even though we have not explicitly
specified anything about the grandparent or uncle relationships, logic programming
can infer them.
Page | 4
GJIMT || 2022
These relationships are specified in a file called relationships.json provided for you.
The file looks like the following: Code:- relationships.json
{
"father": [
{ "John": "William" },
{ "John": "David" },
{ "John": "Adam" },
{ "William": "Chris" },
{ "William": "Stephanie" },
{ "David": "Wayne" },
{ "David": "Tiffany" },
{ "David": "Julie" },
{ "David": "Neil" },
{ "David": "Peter" },
{ "Adam": "Sophia" }
],
"mother": [
{ "Megan": "William" },
{ "Megan": "David" },
{ "Megan": "Adam" },
{ "Emma": "Stephanie" },
{ "Emma": "Chris" },
{ "Olivia": "Tiffany" },
{ "Olivia": "Julie" },
{ "Olivia": "Neil" },
{ "Olivia": "Peter" },
{ "Lily": "Sophia" }
]
}
Code:- family.py
import json
from kanren import Relation, facts, run, conde, var, eq
# Check if 'x' is the parent of 'y'
def parent(x, y):
return conde([father(x, y)], [mother(x, y)])
# Check if 'x' is the grandparent of 'y'
def grandparent(x, y):
temp = var()
return conde((parent(x, temp), parent(temp, y)))
# Check for sibling relationship between 'a' and 'b'
Page | 5
GJIMT || 2022
def sibling(x, y):
temp = var()
return conde((parent(temp, x), parent(temp, y)))
# Check if x is y's uncle
def uncle(x, y):
temp = var()
return conde((father(temp, x), grandparent(temp, y)))
if __name__=='__main__':
father = Relation()
mother = Relation()
with open (r'C:\\Users\ajitk\Desktop\PythonAI\.vscode\relationships.json') as f:
d = json.loads(f.read())
for item in d['father']:
facts(father, (list(item.keys())[0], list(item.values())[0]))
for item in d['mother']:
facts(mother, (list(item.keys())[0], list(item.values())[0]))
x = var()
# John's children
name = 'John'
output = run(0, x, father(name, x))
print("\nList of " + name + "'s children:")
for item in output:
print(item)
# William's mother
name = 'William'
output = run(0, x, mother(x, name))[0]
print("\n" + name + "'s mother:\n" + output)
# Adam's parents
name = 'Adam'
output = run(0, x, parent(x, name))
print("\nList of " + name + "'s parents:")
for item in output:
print(item)
# Wayne's grandparents
name = 'Wayne'
output = run(0, x, grandparent(x, name))
Page | 6
GJIMT || 2022
print("\nList of " + name + "'s grandparents:")
for item in output:
print(item)
# Megan's grandchildren
name = 'Megan'
output = run(0, x, grandparent(name, x))
print("\nList of " + name + "'s grandchildren:")
for item in output:
print(item)
# David's siblings
name = 'David'
output = run(0, x, sibling(x, name))
siblings = [x for x in output if x != name]
print("\nList of " + name + "'s siblings:")
for item in siblings:
print(item)
# Tiffany's uncles
name = 'Tiffany'
name_father = run(0, x, father(x, name))[0]
output = run(0, x, uncle(x, name))
output = [x for x in output if x != name_father]
print("\nList of " + name + "'s uncles:")
for item in output:
print(item)
# All spouses
a, b, c = var(), var(), var()
output = run(0, (a, b), (father, a, c), (mother, b, c))
print("\nList of all spouses:")
for item in output
print('Husband:', item[0], '<==> Wife:', item[1])
Page | 7
GJIMT || 2022
Output:-
Page | 8
GJIMT || 2022
Experiment:- 03
Aim:- Python script for building a puzzle solver.
Code:from kanren import *
from kanren.core import lall
# Declare the variable
people = var()
# Define the rules
rules = lall(
# There are 4 people
(eq, (var(), var(), var(), var()), people),
# Steve's car is blue
(membero, ('Steve', var(), 'blue', var()), people),
# Person who owns the cat lives in Canada
(membero, (var(), 'cat', var(), 'Canada'), people),
# Matthew lives in USA
(membero, ('Matthew', var(), var(), 'USA'), people),
# The person who has a black car lives in Australia
(membero, (var(), var(), 'black', 'Australia'), people),
# Jack has a cat
(membero, ('Jack', 'cat', var(), var()), people),
# Alfred lives in Australia
(membero, ('Alfred', var(), var(), 'Australia'), people),
# Person who owns the dog lives in France
(membero, (var(), 'dog', var(), 'France'), people),
# Who is the owner of the rabbit?
(membero, (var(), 'rabbit', var(), var()), people)
)
# Run the solver
solutions = run(0, people, rules)
# Extract the output
output = [house for house in solutions[0] if 'rabbit' in house][0][0]
# Print the output
print('\n' + output + ' is the owner of the rabbit')
print('\nHere are all the details:')
Page | 9
GJIMT || 2022
attribs = ['Name', 'Pet', 'Color', 'Country']
print('\n' + '\t\t'.join(attribs))
print('=' * 57)
for item in solutions[0]:
print('')
print('\t\t'.join([str(x) for x in item]))
Output:-
Page | 10
GJIMT || 2022
Experiment:- 04
Aim:- Implementation of uninformed search techniques in Python.
Uninformed Search:- Uninformed search is a class of general-purpose search
algorithms which operates in brute force-way. Uninformed search algorithms do
not have additional information about state or search space other than how to
traverse the tree, so it is also called blind search.
Following are the various types of uninformed search algorithms:
Breadth-first Search
Depth-first Search
Depth-limited Search
Iterative deepening depth-first search
Uniform cost search
Bidirectional Search
Breadth-first Search:- Breadth-First Search (BFS) is an algorithm used for
traversing graphs or trees. Traversing means visiting each node of the graph.
Breadth-First Search is a recursive algorithm to search all the vertices of a graph or
a tree. BFS in python can be implemented by using data structures like a dictionary
and lists. Breadth-First Search in tree and graph is almost the same. The only
difference is that the graph may contain cycles, so we may traverse to the same
node again.
BFS Pseudo Code:- The pseudo code for BFS in python goes as below:create a queue Q
mark v as visited and put v into Q
while Q is non-
empty
remove the head u of Q
mark and enqueue all(unvisited) neighbors of u
BFS implementation in Python: Now, we will see how the source code of the program for implementing
breadth first search in python.
Consider the following graph which is implemented in the code below:-
Page | 11
GJIMT || 2022
Code:graph = {
'5' : ['3','7'],
'3' : ['2', '4'],
'7' : ['8'],
'2' : [],
'4' : ['8'],
'8' : []
}
visited = [] # List for visited nodes.
queue = [] #Initialize a queue
def bfs(visited, graph, node): #function for BFS
visited.append(node)
queue.append(node)
while queue:
# Creating loop to visit each node
m = queue.pop(0)
print (m, end = " ")
for neighbour in graph[m]:
if neighbour not in visited:
visited.append(neighbour)
queue.append(neighbour)
# Driver Code
print("Following is the Breadth-First Search")
bfs(visited, graph, '5') # function calling
Output:-
Page | 12
GJIMT || 2022
Experiment:- 05
Aim:- Implementation of heuristic search techniques in Python.
Heuristic Search:- A heuristic technique is a problem specific approach that
employs a practical method that often provides sufficient accuracy for the
immediate goals.
Following are the various types of uninformed search algorithms:
A* search
Simulated Annealing
Hill Climbing
Optimal search
Greedy best-first search
Memory bounded heuristic search
A* Search Algorithm: A* search is the most commonly known form of best-first search. It uses the
heuristic function h(n) and cost to reach the node n from the start state g(n).
It has combined features of UCS and greedy best-first search, by which it
solve the problem efficiently.
It finds the shortest path through the search space using the heuristic
function. This search algorithm expands fewer search tree and gives optimal
results faster.
A* Search implementation in Python: we are going to find out how the A* search algorithm can be used to find the
most cost-effective path in a graph. Consider the following graph below.
Page | 13
GJIMT || 2022
Code:def aStarAlgo(start_node, stop_node):
open_set = set(start_node)
closed_set = set()
g = {} #store distance from starting node
parents = {}# parents contains an adjacency map of all nodes
#ditance of starting node from itself is zero
g[start_node] = 0
#start_node is root node i.e it has no parent nodes
#so start_node is set to its own parent node
parents[start_node] = start_node
while len(open_set) > 0:
n = None
#node with lowest f() is found
for v in open_set:
if n == None or g[v] + heuristic(v) < g[n] + heuristic(n):
n=v
if n == stop_node or Graph_nodes[n] == None:
pass
else:
for (m, weight) in get_neighbors(n):
#nodes 'm' not in first and last set are added to first
#n is set its parent
if m not in open_set and m not in closed_set:
open_set.add(m)
parents[m] = n
g[m] = g[n] + weight
#for each node m,compare its distance from start
i.e g(m) to the
#from start through n node
else:
if g[m] > g[n] + weight:
#update g(m)
g[m] = g[n] + weight
#change parent of m to n
parents[m] = n
Page | 14
GJIMT || 2022
#if m in closed set,remove and add to
open
if m in closed_set:
closed_set.remove(m)
open_set.add(m)
if n == None:
print('Path does not exist!')
return None
# if the current node is the stop_node
# then we begin reconstructin the path from it to the start_node
if n == stop_node:
path = [ ]
while parents[n] != n:
path.append(n)
n = parents[n]
path.append(start_node)
path.reverse()
print('Path found: {}'.format(path))
return path
# remove n from the open_list, and add it to closed_list
# because all of his neighbors were inspected
open_set.remove(n)
closed_set.add(n)
print('Path does not exist!')
return None
#define fuction to return neighbor and its distance
#from the passed node
def get_neighbors(v):
if v in Graph_nodes:
return Graph_nodes[v]
else:
return None
#for simplicity we ll consider heuristic distances given
#and this function returns heuristic distance for all nodes
def heuristic(n):
H_dist = {
'A': 11,
Page | 15
GJIMT || 2022
'B': 6,
'C': 99,
'D': 1,
'E': 7,
'G': 0,
}
return H_dist[n]
#Describe your graph here
Graph_nodes = {
'A': [('B', 2), ('E', 3)],
'B': [('C', 1),('G', 9)],
'C': None,
'E': [('D', 6)],
'D': [('G', 1)],
}
aStarAlgo('A', 'G')
Output:-
Page | 16
GJIMT || 2022
Experiment:- 06
Aim:- Python script for tokenizing text data.
Tokenizing:- Tokenization is a common task a data scientist comes across when
working with text data. It consists of splitting an entire text into small units, also
known as tokens. Most Natural Language Processing (NLP) projects have
tokenization as the first step because it’s the foundation for developing good
models and helps better understand the text we have.
Following are some ways for Tokenizing text data: Simple tokenization with .split: Code:my_text = """Hey I'm Ajit Kumar . I Just Love Coding ."""
print(my_text.split('. '))
print(my_text.split())
Output:-
Tokenization with NLTK: Code:# import the existing word and sentence tokenizing
# libraries
import nltk
nltk.download('punkt')
from nltk.tokenize import sent_tokenize, word_tokenize
text = "Natural language processing (NLP) is a field " + \
"of computer science, artificial intelligence " + \
"and computational linguistics concerned with " + \
"the interactions between computers and human " + \
"(natural) languages, and, in particular, " + \
"concerned with programming computers to " + \
"fruitfully process large natural language " + \
Page | 17
GJIMT || 2022
"corpora. Challenges in natural language " + \
"processing frequently involve natural " + \
"language understanding, natural language" + \
"generation frequently from formal, machine" + \
"-readable logical forms), connecting language " + \
"and machine perception, managing human-" + \
"computer dialog systems, or some combination " + \
"thereof."
#print(sent_tokenize(text))
print(word_tokenize(text))
Output:-
Page | 18
GJIMT || 2022
Experiment:- 07
Aim:- Extracting the frequency of terms using a Bag of Words model.
Bag of Words model:- Bag of Words model is used to preprocess the text by
converting it into a bag of words, which keeps a count of the total occurrences of most
frequently used words.
This model can be visualized using a table, which contains the count of words
corresponding to the word itself.
Code:def vectorize(tokens):
vector=[]
for w in filtered_vocab:
vector.append(tokens.count(w))
return vector
def unique(sequence):
seen = set()
return [x for x in sequence if not (x in seen or seen.add(x))]
#create a list of stopwords.You can import stopwords from nltk too
stopwords=["to","is","a"]
#list of special characters.You can use regular expressions too
special_char=[",",":"," ",";",".","?"]
#Write the sentences in the corpus,in our case, just two
string1="Welcome to Great Learning , Now start learning"
string2="Learning is a good practice"
#convert them to lower case
string1=string1.lower()
string2=string2.lower()
#split the sentences into tokens
tokens1=string1.split()
tokens2=string2.split()
print(tokens1)
Page | 19
GJIMT || 2022
print(tokens2)
#create a vocabulary list
vocab=unique(tokens1+tokens2)
print(vocab)
#filter the vocabulary list
filtered_vocab=[]
for w in vocab:
if w not in stopwords and w not in special_char:
filtered_vocab.append(w)
print(filtered_vocab)
#convert sentences into vectords
vector1=vectorize(tokens1)
print(vector1)
vector2=vectorize(tokens2)
print(vector2)
Output:-
Page | 20
GJIMT || 2022
Experiment:- 08
Aim:- Predict the category to which a given piece of text belongs.
Code:#import sentimentintensityAnalyzer class
#from VaderSentiment.VaderSentiment import
SentimentIntensityAnalyzer from nltk.sentiment.vader
import SentimentIntensityAnalyzer
import nltk
from PIL import
Image
#nltk.download()
from tkinter
import*
root=Tk()
root.title("Senti
ment Analysis")
root.configure(background='#FFE4C4')
label1=Label(root,text="SENTIMENT
ANALYSIS!",background='#FFE4C4',fg="#D2691E",font="Arial 50
bold").place(x=380,y=30)
label1=Label(root,text="Text:",background='#FFE4C4',fg='#D2691E',font="Ari
al 35 bold").place(x=550,y=240)
large_font=('verdana',30)
entry1Var=StringVar(value='large_font')
ent1=Entry(root,font='large_font')
ent1.place(x=750,y=250)
analyzer=
SentimentIntensityAnalyzer()
#function is prime sentiment
Page | 21
GJIMT || 2022
def
sentime
nt_scor
es():
sentenc
e=
ent1.ge
t()
sid_obj=SentimentIntensityAnalyzer()
sentiment_dict=sid_obj.polarity_scores(
sentence) print("Overall Sentiment
Dictionary is:",sentiment_dict)
print("Sentence was rated
as:",sentiment_dict['neg']*100,"% Negative")
print("Sentence was rated
as:",sentiment_dict['neu']*100,"% Neutral")
print("Sentence was rated
as:",sentiment_dict['pos']*100,"% Positive")
print("Sentence was overall rated as:",end=' ')
if sentiment_dict['compound']>=0.05:
print("Positive")
result="Positive"
elif sentiment_dict['compound']<=-0.05:
print("Negative")
result="Negative" else:
print("Neutral") result="Neutral"
messagebox.showinfo(title='Result',message="
Sentence was overall rated as:%s"%(result))
button1=Button(root,text="predict",command=
Page | 22
GJIMT || 2022
sentiment_scores,width=10,background='#A05
2 2D',font="Arial 15",fg="#D2691E")
button1.place(x=600,y=400)
button2=Button(root,text="Quit",command=ro
ot.destroy,width=10,background='#A0522D',fo
n t="Arial 15",fg="#D2691E")
button2.place(x=800,y=400)
root.mainloop()
Output:-
Page | 23
GJIMT || 2022
Experiment:- 09
Aim:- Python code for visualizing audio speech signal.
Code:def showing_audiotrack():
# We use a variable previousTime to store the time when a plot update
is made
# and to then compute the time taken to update the plot of the audio
data.
previousTime = time.time()
# Turning the interactive mode on
plt.ion()
# Each time we go through a number of samples in the audio data that
corresponds to one second of audio,
# we increase spentTime by one (1 second).
spentTime = 0
# Let's the define the update periodicity
updatePeriodicity = 2 # expressed in seconds
# Plotting the audio data and updating the plot
for i in range(n):
# Each time we read one second of audio data, we increase
spentTime :
if i // Fs != (i-1) // Fs:
spentTime += 1
# We update the plot every updatePeriodicity seconds
if spentTime == updatePeriodicity:
# Clear the previous plot
plt.clf()
# Plot the audio data
plt.plot(time_axis, sound_axis)
# Plot a red line to keep track of the progression
plt.axvline(x=i / Fs, color='r')
plt.xlabel("Time (s)")
plt.ylabel("Audio")
plt.show() # shows the plot
plt.pause(updatePeriodicity-(time.time()-previousTime))
# a forced pause to synchronize the audio being played with the
audio track being displayed
previousTime = time.time()
spentTime = 0
GJIMT || 2022
Output:-
GJIMT || 2022
Experiment:- 10
Aim:- Python code for Generating audio signals.
Code:#!/usr/bin/env python
import sys
import wave
import math
import struct
import random
import argparse
from itertools import *
def grouper(n, iterable, fillvalue=None):
"grouper(3, 'ABCDEFG', 'x') --> ABC DEF Gxx"
args = [iter(iterable)] * n
return izip_longest(fillvalue=fillvalue, *args)
def sine_wave(frequency=440.0, framerate=44100, amplitude=0.5):
'''
Generate a sine wave at a given frequency of infinite length.
'''
period = int(framerate / frequency)
if amplitude > 1.0: amplitude = 1.0
if amplitude < 0.0: amplitude = 0.0
lookup_table
=
[float(amplitude)
*
math.sin(2.0*math.pi*float(frequency)*(float(i%period)/float(framerate)
)) for i in xrange(period)]
return (lookup_table[i%period] for i in count(0))
def square_wave(frequency=440.0, framerate=44100, amplitude=0.5):
for s in sine_wave(frequency, framerate, amplitude):
if s > 0:
yield amplitude
elif s < 0:
yield -amplitude
else:
yield 0.0
def damped_wave(frequency=440.0, framerate=44100, amplitude=0.5,
length=44100):
if amplitude > 1.0: amplitude = 1.0
if amplitude < 0.0: amplitude = 0.0
GJIMT || 2022
return (math.exp(-(float(i%length)/float(framerate))) * s for i, s in
enumerate(sine_wave(frequency, framerate, amplitude)))
def white_noise(amplitude=0.5):
'''
Generate random samples.
'''
return (float(amplitude) * random.uniform(-1, 1) for i in count(0))
def compute_samples(channels, nsamples=None):
'''
create a generator which computes the samples.
essentially it creates a sequence of the sum of each function in the
channel
at each sample in the file for each channel.
'''
return islice(izip(*(imap(sum, izip(*channel)) for channel in
channels)), nsamples)
def write_wavefile(filename, samples, nframes=None, nchannels=2,
sampwidth=2, framerate=44100, bufsize=2048):
"Write samples to a wavefile."
if nframes is None:
nframes = -1
w = wave.open(filename, 'w')
w.setparams((nchannels, sampwidth, framerate, nframes, 'NONE', 'not
compressed'))
max_amplitude = float(int((2 ** (sampwidth * 8)) / 2) - 1)
# split the samples into chunks (to reduce memory consumption and
improve performance)
for chunk in grouper(bufsize, samples):
frames = ''.join(''.join(struct.pack('h', int(max_amplitude * sample))
for sample in channels) for channels in chunk if channels is not None)
w.writeframesraw(frames)
w.close()
return filename
def
write_pcm(f,
bufsize=2048):
samples,
sampwidth=2,
framerate=44100,
GJIMT || 2022
"Write samples as raw PCM data."
max_amplitude = float(int((2 ** (sampwidth * 8)) / 2) - 1)
# split the samples into chunks (to reduce memory consumption and
improve performance)
for chunk in grouper(bufsize, samples):
frames = ''.join(''.join(struct.pack('h', int(max_amplitude * sample))
for sample in channels) for channels in chunk if channels is not None)
f.write(frames)
f.close()
return filename
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-c', '--channels', help="Number of channels to
produce", default=2, type=int)
parser.add_argument('-b', '--bits', help="Number of bits in each
sample", choices=(16,), default=16, type=int)
parser.add_argument('-r', '--rate', help="Sample rate in Hz",
default=44100, type=int)
parser.add_argument('-t', '--time', help="Duration of the wave in
seconds.", default=60, type=int)
parser.add_argument('-a', '--amplitude', help="Amplitude of the wave
on a scale of 0.0-1.0.", default=0.5, type=float)
parser.add_argument('-f', '--frequency', help="Frequency of the wave
in Hz", default=440.0, type=float)
parser.add_argument('filename', help="The file to generate.")
args = parser.parse_args()
# each channel is defined by infinite functions which are added to
produce a sample.
channels = ((sine_wave(args.frequency, args.rate, args.amplitude),)
for i in range(args.channels))
# convert the channel functions into waveforms
samples = compute_samples(channels, args.rate * args.time)
# write the samples to a file
if args.filename == '-':
filename = sys.stdout
else:
filename = args.filename
GJIMT || 2022
write_wavefile(filename,
samples,
args.channels, args.bits / 8, args.rate)
if __name__ == "__main__":
main()
Output:-
Experiment:- 11
args.rate
*
args.time,
GJIMT || 2022
Aim:- Create a perception with appropriate no. of inputs and outputs. Train it using fixed
increment learning algorithm until no change in weights is required. Output the final
weights.
Code:class Perceptron:
#constructor
def __init__ (self):
self.w = None
self.b = None
#model
def model(self, x):
return 1 if (np.dot(self.w, x) >= self.b) else 0
#predictor to predict on the data based on w
def predict(self, X):
Y = []
for x in X:
result = self.model(x)
Y.append(result)
return np.array(Y)
def fit(self, X, Y, epochs = 1, lr = 1):
self.w = np.ones(X.shape[1])
self.b = 0
accuracy = {}
max_accuracy = 0
wt_matrix = []
#for all epochs
for i in range(epochs):
for x, y in zip(X, Y):
y_pred = self.model(x)
if y == 1 and y_pred == 0:
self.w = self.w + lr * x
self.b = self.b - lr * 1
GJIMT || 2022
elif y == 0 and y_pred == 1:
self.w = self.w - lr * x
self.b = self.b + lr * 1
wt_matrix.append(self.w)
accuracy[i] = accuracy_score(self.predict(X), Y)
if (accuracy[i] > max_accuracy):
max_accuracy = accuracy[i]
chkptw = self.w
chkptb = self.b
#checkpoint (Save the weights and b value)
self.w = chkptw
self.b = chkptb
print(max_accuracy)
#plot the accuracy values over epochs
plt.plot(accuracy.values())
plt.xlabel("Epoch #")
plt.ylabel("Accuracy")
plt.ylim([0, 1])
plt.show()
#return the weight matrix, that contains weights over all epochs
return np.array(wt_matrix)
Output:-
GJIMT || 2022
Experiment:- 12
GJIMT || 2022
Aim:- Implement AND function using ADALINE with bipolar inputs and outputs.
Code:# import the module numpy
import numpy as np
# the features for the or model , here we have
# taken the possible values for combination of
# two inputs
features = np.array(
[
[-1, -1],
[-1, 1],
[1, -1],
[1, 1]
])
# labels for the or model, here the output for
# the features is taken as an array
labels = np.array([-1, 1, 1, 1])
# to print the features and the labels for
# which the model has to be trained
print(features, labels)
# initialise weights, bias , learning rate, epoch
weight = [0.5, 0.5]
bias = 0.1
learning_rate = 0.2
epoch = 10
for i in range(epoch):
# epoch is the number of the model is trained
# with the same data
print("epoch :", i+1)
# variable to check if there is no change in previous
# weight and present calculated weight
# initial error is kept as 0
sum_squared_error = 0.0
# for each of the possible input given in the features
for j in range(features.shape[0]):
GJIMT || 2022
# actual output to be obtained
actual = labels[j]
# the value of two features as given in the features
# array
x1 = features[j][0]
x2 = features[j][1]
# net unit value computation performed to obtain the
# sum of features multiplied with their weights
unit = (x1 * weight[0]) + (x2 * weight[1]) + bias
# error is computed so as to update the weights
error = actual - unit
# print statement to print the actual value , predicted
# value and the error
print("error =", error)
# summation of squared error is calculated
sum_squared_error += error * error
# updation of weights, summing up of product of learning
rate ,
# sum of squared error and feature value
weight[0] += learning_rate * error * x1
weight[1] += learning_rate * error * x2
# updation of bias, summing up of product of learning rate
and
# sum of squared error
bias += learning_rate * error
print("sum of squared error = ", sum_squared_error/4, "\n\n")
Output:-
GJIMT || 2022
Experiment:- 13
GJIMT || 2022
Aim:- Implement AND function using MADALINE with bipolar inputs and outputs.
Code:# import the module numpy
import numpy as np
# the features for the or model , here we have
# taken the possible values for combination of
# two inputs
features = np.array(
[
[-1, -1],
[-1, 1],
[1, -1],
[1, 1]
])
# labels for the or model, here the output for
# the features is taken as an array
labels = np.array([-1, 1, 1, 1])
# to print the features and the labels for
# which the model has to be trained
print(features, labels)
# initialise weights, bias , learning rate, epoch
weight = [0.5, 0.5]
bias = 0.1
learning_rate = 0.2
epoch = 10
for i in range(epoch):
# epoch is the number of the model is trained
# with the same data
print("epoch :", i+1)
# variable to check if there is no change in previous
# weight and present calculated weight
# initial error is kept as 0
sum_squared_error = 0.0
# for each of the possible input given in the features
for j in range(features.shape[0]):
GJIMT || 2022
# actual output to be obtained
actual = labels[j]
# the value of two features as given in the features
# array
x1 = features[j][0]
x2 = features[j][1]
# net unit value computation performed to obtain the
# sum of features multiplied with their weights
unit = (x1 * weight[0]) + (x2 * weight[1]) + bias
# error is computed so as to update the weights
error = actual - unit
# print statement to print the actual value , predicted
# value and the error
print("error =", error)
# summation of squared error is calculated
sum_squared_error += error * error
# updation of weights, summing up of product of learning
rate ,
# sum of squared error and feature value
weight[0] += learning_rate * error * x1
weight[1] += learning_rate * error * x2
# updation of bias, summing up of product of learning rate
and
# sum of squared error
bias += learning_rate * error
print("sum of squared error = ", sum_squared_error/4, "\n\n")
Output:-
GJIMT || 2022
GJIMT || 2022
Experiment:- 14
Aim:- Construct and test auto associative network for input vector using HEBB rule.
Code:%The MATLAB program for calculating the weight matrix is as follows
%Discrete Hopfield net
clc;
clear;
x=[1 1 1 0];
w=(2*x'–1)*(2*x–1);
for i=1:4
w (i, i)=0;
end
disp('Weight matrix');
disp(w);
Output:-
Experiment:- 15
GJIMT || 2022
Aim:- Construct and test auto associative network for input vector using outer product
rule.
Code:%Auotassociative net to store the vector
clc;
clear;
x = [1 1 –1 –1];
w=zeros (4, 4); w=x'*x;
yin=x*w;
for i=1:4
if yin(i)>0
y(i)=1;
else
y(i) = –1;
end end
disp ('Weight matrix');
disp (w);
if x == y
disp ('The vector is a Known Vector');
else
disp ('The vector is a Unknown Vector');
end
Output:-
GJIMT || 2022
Experiment:- 16
Aim:- Construct and test heteroassociative network for binary inputs and targets.
Code:# Import Python Libraries
import numpy as np
# Take two sets of patterns:
# Set A: Input Pattern
x1 = np.array([1, 1, 1, 1, 1, 1]).reshape(6, 1)
x2 = np.array([-1, -1, -1, -1, -1, -1]).reshape(6, 1)
x3 = np.array([1, 1, -1, -1, 1, 1]).reshape(6, 1)
x4 = np.array([-1, -1, 1, 1, -1, -1]).reshape(6, 1)
# Set B: Target Pattern
y1 = np.array([1, 1, 1]).reshape(3, 1)
y2 = np.array([-1, -1, -1]).reshape(3, 1)
y3 = np.array([1, -1, 1]).reshape(3, 1)
y4 = np.array([-1, 1, -1]).reshape(3, 1)
'''
print("Set A: Input Pattern, Set B: Target Pattern")
print("\nThe input for pattern 1 is")
print(x1)
print("\nThe target for pattern 1 is")
print(y1)
print("\nThe input for pattern 2 is")
print(x2)
print("\nThe target for pattern 2 is")
print(y2)
print("\nThe input for pattern 3 is")
print(x3)
print("\nThe target for pattern 3 is")
print(y3)
print("\nThe input for pattern 4 is")
print(x4)
print("\nThe target for pattern 4 is")
print(y4)
print("\n------------------------------")
'''
# Calculate weight Matrix: W
inputSet = np.concatenate((x1, x2, x3, x4), axis = 1)
targetSet = np.concatenate((y1.T, y2.T, y3.T, y4.T), axis = 0)
GJIMT || 2022
print("\nWeight matrix:")
weight = np.dot(inputSet, targetSet)
print(weight)
print("\n------------------------------")
# Testing Phase
# Test for Input Patterns: Set A
print("\nTesting for input patterns: Set A")
def testInputs(x, weight):
# Multiply the input pattern with the weight matrix
# (weight.T X x)
y = np.dot(weight.T, x)
y[y < 0] = -1
y[y >= 0] = 1
return np.array(y)
print("\nOutput of input pattern 1")
print(testInputs(x1, weight))
print("\nOutput of input pattern 2")
print(testInputs(x2, weight))
print("\nOutput of input pattern 3")
print(testInputs(x3, weight))
print("\nOutput of input pattern 4")
print(testInputs(x4, weight))
# Test for Target Patterns: Set B
print("\nTesting for target patterns: Set B")
def testTargets(y, weight):
# Multiply the target pattern with the weight matrix
# (weight X y)
x = np.dot(weight, y)
x[x <= 0] = -1
x[x > 0] = 1
return np.array(x)
print("\nOutput of target pattern 1")
print(testTargets(y1, weight))
print("\nOutput of target pattern 2")
print(testTargets(y2, weight))
print("\nOutput of target pattern 3")
print(testTargets(y3, weight))
print("\nOutput of target pattern 4")
print(testTargets(y4, weight))
Output:-
GJIMT || 2022
Experiment:- 17
GJIMT || 2022
Aim:- Create a back propagation network for a given input pattern. Perform 3 epochs of
operation.
Code:import numpy as np
def sigmoid(x):
return 1.0/(1.0 + np.exp(-x))
def sigmoid_prime(x):
return sigmoid(x)*(1.0-sigmoid(x))
def tanh(x):
return np.tanh(x)
def tanh_prime(x):
return 1.0 - x**2
class NeuralNetwork:
def __init__(self, layers, activation='tanh'):
if activation == 'sigmoid':
self.activation = sigmoid
self.activation_prime = sigmoid_prime
elif activation == 'tanh':
self.activation = tanh
self.activation_prime = tanh_prime
# Set weights
self.weights = []
# layers = [2,2,1]
# range of weight values (-1,1)
# input and hidden layers - random((2+1, 2+1)) : 3 x 3
for i in range(1, len(layers) - 1):
r = 2*np.random.random((layers[i-1] + 1, layers[i] + 1)) -1
self.weights.append(r)
# output layer - random((2+1, 1)) : 3 x 1
r = 2*np.random.random( (layers[i] + 1, layers[i+1])) - 1
self.weights.append(r)
def fit(self, X, y, learning_rate=0.2, epochs=100000):
# Add column of ones to X
# This is to add the bias unit to the input layer
ones = np.atleast_2d(np.ones(X.shape[0]))
X = np.concatenate((ones.T, X), axis=1)
for k in range(epochs):
i = np.random.randint(X.shape[0])
GJIMT || 2022
a = [X[i]]
for l in range(len(self.weights)):
dot_value = np.dot(a[l], self.weights[l])
activation = self.activation(dot_value)
a.append(activation)
# output layer
error = y[i] - a[-1]
deltas = [error * self.activation_prime(a[-1])]
# we need to begin at the second to last layer
# (a layer before the output layer)
for l in range(len(a) - 2, 0, -1):
deltas.append(deltas[1].dot(self.weights[l].T)*self.activation_prime(a[l]))
# reverse
#
[level3(output)->level2(hidden)]
>level3(output)]
deltas.reverse()
=>
[level2(hidden)-
# backpropagation
# 1. Multiply its output delta and input activation
# to get the gradient of the weight.
# 2. Subtract a ratio (percentage) of the gradient from the weight.
for i in range(len(self.weights)):
layer = np.atleast_2d(a[i])
delta = np.atleast_2d(deltas[i])
self.weights[i] += learning_rate * layer.T.dot(delta)
if k % 10000 == 0: print ('epochs:', k)
def predict(self, x):
a = np.concatenate((np.ones(1).T, np.array(x)), axis=1)
for l in range(0, len(self.weights)):
a = self.activation(np.dot(a, self.weights[l]))
return a
if __name__ == '__main__':
nn = NeuralNetwork([2,2,1])
X = np.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]])
y = np.array([0, 1, 1, 0])
nn.fit(X, y)
for e in X:
GJIMT || 2022
print(e,nn.predict(e))
Output:-
Experiment:- 18
GJIMT || 2022
Aim:- Implement Union, Intersection, Complement and Difference operations on fuzzy
sets. Also create fuzzy relation by Cartesian product of any two fuzzy sets and perform
maxmin composition on any two fuzzy relations.
Fuzzy Sets:- Fuzzy refers to something that is unclear or vague . Hence, Fuzzy Set
is a Set where every key is associated with value, which is between 0 to 1 based on
the certainty .This value is often called as degree of membership. Fuzzy Set is
denoted with a Tilde Sign on top of the normal Set notation.
Operations on Fuzzy Set with Code :-
Union : Code:# Example to Demonstrate the
# Union of Two Fuzzy Sets
A = dict()
B = dict()
Y = dict()
A = {"a": 0.2, "b": 0.3, "c": 0.6, "d": 0.6}
B = {"a": 0.9, "b": 0.9, "c": 0.4, "d": 0.5}
print('The First Fuzzy Set is :', A)
print('The Second Fuzzy Set is :', B)
for A_key, B_key in zip(A, B):
A_value = A[A_key]
B_value = B[B_key]
if A_value > B_value:
Y[A_key] = A_value
else:
Y[B_key] = B_value
print('Fuzzy Set Union is :', Y)
Output:-
GJIMT || 2022
Intersection : Code:# Example to Demonstrate
# Intersection of Two Fuzzy Sets
A = dict()
B = dict()
Y = dict()
A = {"a": 0.2, "b": 0.3, "c": 0.6, "d": 0.6}
B = {"a": 0.9, "b": 0.9, "c": 0.4, "d": 0.5}
print('The First Fuzzy Set is :', A)
print('The Second Fuzzy Set is :', B)
for A_key, B_key in zip(A, B):
A_value = A[A_key]
B_value = B[B_key]
if A_value < B_value:
Y[A_key] = A_value
else:
Y[B_key] = B_value
print('Fuzzy Set Intersection is :', Y)
Output:-
Complement : Code:# Example to Demonstrate the
# Complement Between Two Fuzzy Sets
A = dict()
Y = dict()
A = {"a": 0.2, "b": 0.3, "c": 0.6, "d": 0.6}
print('The Fuzzy Set is :', A)
for A_key in A:
GJIMT || 2022
Y[A_key]= 1-A[A_key]
print('Fuzzy Set Complement is :', Y)
Output:-
Difference: Code:# Example to Demonstrate the
# Difference Between Two Fuzzy Sets
A = dict()
B = dict()
Y = dict()
A = {"a": 0.2, "b": 0.3, "c": 0.6, "d": 0.6}
B = {"a": 0.9, "b": 0.9, "c": 0.4, "d": 0.5}
print('The First Fuzzy Set is :', A)
print('The Second Fuzzy Set is :', B)
for A_key, B_key in zip(A, B):
A_value = A[A_key]
B_value = B[B_key]
B_value = 1 - B_value
if A_value < B_value:
Y[A_key] = A_value
else:
Y[B_key] = B_value
print('Fuzzy Set Difference is :', Y)
Output:-
GJIMT || 2022
Cartesian Product & MaxMin Composition: Code:def cartesian():
n = int(input("\nEnter number of elements in first set (A): "))
A = []
B = []
print("Enter elements for A:")
for i in range(0, n):
ele = float(input())
A.append(ele)
m = int(input("\nEnter number of elements in second set (B): "))
print("Enter elements for B:")
for i in range(0, m):
ele = float(input())
B.append(ele)
print("A = {"+str(A)[1:-1]+"}")
print("B = {"+str(B)[1:-1]+"}")
cart_prod = []
cart_prod = [[0 for j in range(m)]for i in range(n)]
for i in range(n):
for j in range(m):
cart_prod[i][j] = min(A[i],B[j])
print("A x B = ")
for i in range(n):
for j in range(m):
print(cart_prod[i][j],end=" ")
print("\n")
return
def minmax():
r1 = int(input("Enter number of rows of first relation (R1): "))
c1 = int(input("Enter number of columns of first relation (R1): "))
rel1=[[0 for i in range(c1)]for j in range(r1)]
print("Enter the elments for R:")
for i in range(r1):
for j in range(c1):
rel1[i][j]=float(input())
r2 = int(input("Enter number of rows of second relation (R2): "))
c2 = int(input("Enter number of columns of second relation (R2): "))
rel2=[[0 for i in range(c2)]for j in range(r2)]
print("Enter the elments for R:")
for i in range(r2):
for j in range(c2):
GJIMT || 2022
rel2[i][j]=float(input())
print("\nR1 = ")
for i in range(r1):
for j in range(c1):
print(rel1[i][j],end=" ")
print("\n")
print("\nR2 = ")
for i in range(r2):
for j in range(c2):
print(rel2[i][j],end=" ")
print("\n")
col=0
comp=[]
for i in range(r1):
comp.append([])
for j in range(c2):
l=[]
for k in range(r2):
l.append(min(rel1[i][k],rel2[k][j]))
comp[i].append(max(l))
print("\nR1 composition R2 =")
for i in range(r1):
for j in range(c2):
print(comp[i][j],end=" ")
print("\n")
return
ch=1
while ch==1:
print("MENU:\n----\n1->Cartesian
Product\n2->Minmax
Composition\n3->Exit")
op=int(input("Enter Your Choice: "))
if op==1:
cartesian()
elif op==2:
minmax()
elif op==3:
break
else:
print("Wrong Choice!")
ch=int(input("Do you wish to continue (1-Yes | 0-No): "))
print("\n")
GJIMT || 2022
Output:- Cartesian Product
Output:- MaxMin Composition
GJIMT || 2022
Experiment:- 19
Aim:- Maximize the function f(x)=x2 using GA, where x ranges form 0-25. Perform 6
iterations.
Code:-
%program for Genetic algorithm to maximize the function f(x) =sin(x)
clear all;
clc;
%x ranges from 0 to 3.14
%five bits are enough to represent x in binary representation
n=input('Enter no. of population in each iteration');
nit=input('Enter no. of iterations');
%Generate the initial population
[oldchrom]=initbp(n,5);
%The population in binary is converted to integer
FieldD=[5;0;3.14;0;0;1;1]
for i=1:nit
phen=bindecod(oldchrom,FieldD,3);% phen gives the integer value of
the
%binary population
%obtain fitness value
FitnV=sin(phen);
%apply roulette wheel selection
GJIMT || 2022
Nsel=4;
newchrix=selrws(FitnV, Nsel);
newchrom=oldchrom(newchrix,:);
%Perform Crossover
crossoverrate=1;
newchromc=recsp(newchrom,crossoverrate);%new population
crossover
%Perform mutation
vlub=0:31;
mutationrate=0.001;
newchromm=mutrandbin(newchromc,vlub,mutationrate);%new
population
%after mutation
disp('For iteration');
i
disp('Population');
oldchrom
disp('X');
phen
disp('f(X)');
FitnV
oldchrom=newchromm;
end
Output:-
after
GJIMT || 2022
-: THE END :-