Lecture 6: Multiple
Linear Regression II
Dr. Irene Vrbik
University of British Columbia Okanagan
Outline
1. Interaction
The first consideration will involving allowing predictors to
“interact” with one another (related to the marketing term
synergy, in regression Interaction)
2. Categorical Predictors
3. Interaction with Categorical Predictors
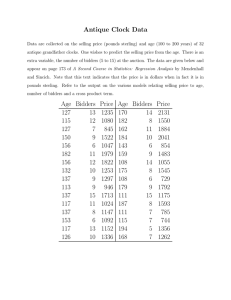
Example: Clock Auction
The data give the selling price, Price at
auction of 32 antique grandfather clocks.
Also recorded is the age of the clock (Age) and
the number of people who made a bid
(Bidders).
This data (uploaded to Canvas) is tab delimited
so it gets read into R using read.delim
1 dat <- read.delim("data/clockauction", sep="\t")
Clock Auction Data
Age
<int>
Bidders
<int>
Price
<int>
1
127
13
1235
2
115
12
1080
3
127
7
845
4
150
9
1522
5
156
6
1047
6
182
11
1979
6 rows
3D Scatter plot
Correlation
Another way that you could investigate correlation between
predictors is through the correlation matrix (see ?cor)
1 cor(dat)
Age
Bidders
Price
Age
1.0000000 -0.2537491 0.7302332
Bidders -0.2537491 1.0000000 0.3946404
Price
0.7302332 0.3946404 1.0000000
The reinforces our observation that Price seems to be
linearly related to the Age and Bidders (and that Age and
Bidders don’t have a high correlation).
SLR with Age
1 agelm <- lm(Price~Age)
2 summary(agelm)
...
Call:
lm(formula = Price ~ Age)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -191.66
263.89 -0.726
0.473
Age
10.48
1.79
5.854 2.1e-06 ***
--Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 273 on 30 degrees of freedom
Multiple R-squared: 0.5332,
Adjusted R-squared: 0.5177
F-statistic: 34.27 on 1 and 30 DF, p-value: 2.096e-06
...
SLR with Bidders
1 bidlm <- lm(Price~Bidders)
2 summary(bidlm)
...
Call:
lm(formula = Price ~ Bidders)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept)
806.40
230.68
3.496 0.00149 **
Bidders
54.64
23.23
2.352 0.02540 *
--Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 367.2 on 30 degrees of freedom
Multiple R-squared: 0.1557,
Adjusted R-squared: 0.1276
F-statistic: 5.534 on 1 and 30 DF, p-value: 0.0254
...
MLR without Interaction
1 ablm <- lm(Price~Age+Bidders); summary(ablm)
...
Call:
lm(formula = Price ~ Age + Bidders)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1336.7221
173.3561 -7.711 1.67e-08 ***
Age
12.7362
0.9024 14.114 1.60e-14 ***
Bidders
85.8151
8.7058
9.857 9.14e-11 ***
--Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 133.1 on 29 degrees of freedom
Multiple R-squared: 0.8927,
Adjusted R-squared: 0.8853
F-statistic: 120.7 on 2 and 29 DF, p-value: 8.769e-15
Fitted model:
Price = -1336.72 + Age × 12.74 + Bidders × 85.82
Interpretation of Coefficients
: For a clock with a given amount of Bidders, an increase
of 1 year in the age of the clock is associated with a $12.74
increase in the mean price of the clock.
β1
: For a clock with given age, an increase of 1 Bidder is
associated with a $85.82 increase in the mean selling price.
β2
Attention:
Notice that the specific value of age (resp. bidders) does not
affect the interpretation of β (resp. β )
1
2
Setting Bidders values
Eg. when we have 6 bidders Price is calculated:
= -1336.72 + Age × 12.74 + 6 × 85.82
= -821.8 + Age × 12.74
Eg. when we have 12 bidders Price is calculated:
= -1336.72 + Age × 12.74 + 12 × 85.82
= -306.88 + Age × 12.74
MLR Visualization (no interaction)
with 2 qualitative predictors
3D Visualization (no interaction)
trace 0
A 3D scatterplot of the clock data with the fitted additive MLR
model (no interaction) depicted as a plane. This plane is the
Interaction
Suppose that the affect of Age on Price actually depends on
how many Bidders there are.
Similarly, the affect of Bidders on Price might depend on the
Age of the clock.
We can allow the slope term for a predictor to vary based on
the value(s) of the other predictor(s) by including an
additional interaction term1
1. In marketing, this interaction term is refereed to as a synergy effect
Interaction Model
With 2 predictors
Y = β0 + β1 X1 + β2 X2 + β3 X1 X2 + ϵ
is the response variable at i
Y
Xj
is the j predictor variable
β0
is the true intercept (unknown)
βj
ϵ
th
are the true slopes or regression coefficients (unknown)
is the true error, assumed ϵ
i
∼ N (0, σ
2
)
.
MLR with Interaction
1
~
β1
More generally the slope for X ( ) is a function of X so that
the association between X and Y is no longer constant.
1
2
1
Y = β0 + β1 X1 + β2 X2 + β3 X1 X2
= β0 + β2 X2 + (β1 + β3 X2 )X1
~
~
= β0 + β1 X1
where β̃
1
= (β1 + β3 X2 )
and β̃
0
= (β0 + β2 X2 )
1. A similar argument can be made for multiplier associated with X
.
R syntax
1 # same as lm(Price~ Age + Bidders + Age*Bidders)
2 ilm <- lm(Price ~ Age*Bidders); summary(ilm)
...
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 322.7544
293.3251
1.100 0.28056
Age
0.8733
2.0197
0.432 0.66877
Bidders
-93.4099
29.7077 -3.144 0.00392 **
Age:Bidders
1.2979
0.2110
6.150 1.22e-06 ***
Residual standard error: 88.37 on 28 degrees of freedom
Multiple R-squared: 0.9544,
Adjusted R-squared: 0.9495
F-statistic: 195.2 on 3 and 28 DF, p-value: < 2.2e-16
...
hierarchical principle: if the interaction effect is significant you
should also keep the so-called main effects even if they have
non-significant p-values
Interpretation of Coefficients
Population Model
Price = β + β Age + β Bidders + β Age ⋅ Bidders
0
1
2
3
Fitted Model
Price = 322.8 + 0.9 Age -93.4 Bidders + 1.3(Age ⋅
Bidders)
β1
is the effect of Age when Bidders = 0.
Since a clock needs to have at least 1 bidder to be sold β is
meaningless by itself.
1
Better: the effect of Age is 0.9 + 1.3 ⋅ Bidders
Fitted Model with 6 bidders
̂ + β̂ 𝙰𝚐𝚎 + β̂ 𝙱𝚒𝚍𝚍𝚎𝚛𝚜 + β̂ 𝙰𝚐𝚎 ⋅ 𝙱𝚒𝚍𝚍𝚎𝚛𝚜
𝙿𝚛𝚒𝚌𝚎 = β0
1
2
3
= 322.75 + 0.87𝙰𝚐𝚎 − 93.41𝙱𝚒𝚍𝚍𝚎𝚛𝚜 + 1.3𝙰𝚐𝚎 ⋅ 𝙱𝚒𝚍𝚍𝚎𝚛𝚜
Notice now the multiplier associated with Age now depends
on the value of Bidders. Eg. Bidders = 6, Price is given:
= 322.75 + 0.87𝙰𝚐𝚎 − 93.41(6) + 1.3(𝙰𝚐𝚎 ⋅ 6)
= 322.75 + (0.87 + 1.3 ⋅ 6)𝙰𝚐𝚎 − 93.41(6)
= 322.75 + (8.66)𝙰𝚐𝚎 − 560.46
= −237.71 + (8.66)𝙰𝚐𝚎
Fitted Model with 12 bidders
̂ + β̂ 𝙰𝚐𝚎 + β̂ 𝙱𝚒𝚍𝚍𝚎𝚛𝚜 + β̂ 𝙰𝚐𝚎 ⋅ 𝙱𝚒𝚍𝚍𝚎𝚛𝚜
𝙿𝚛𝚒𝚌𝚎 = β0
1
2
3
= 322.75 + 0.87𝙰𝚐𝚎 − 93.41𝙱𝚒𝚍𝚍𝚎𝚛𝚜 + 1.3𝙰𝚐𝚎 ⋅ 𝙱𝚒𝚍𝚍𝚎𝚛𝚜
Notice now the multiplier associated with Age now depends
on the value of Bidders. Eg. Bidders = 12, Price is given:
= 322.75 + 0.87𝙰𝚐𝚎 − 93.41(12) + 1.3(𝙰𝚐𝚎 ⋅ 12)
= 322.75 + (0.87 + 1.3 ⋅ 12)𝙰𝚐𝚎 − 93.41(12)
= 322.75 + (16.45)𝙰𝚐𝚎 − 1120.92
= −798.16 + (16.45)𝙰𝚐𝚎
3D Visualization (with interaction)
trace 0
A 3D scatterplot of the clock data with the fitted MLR model
with interaction depicted by a (non-flat) surface.
Interaction Model with set Bidders
Categorical Predictors
So far we’ve assumed that our predictors are continuous
valued when we’ve fit a regression.
But there is no real problem if instead we have categorical
(i.e. qualitative) values
Let’s motivate this through an example.
Example body
This data set contains the following on 507 individuals:
21 body dimension measurements (eg. wrist and ankle girth)
Age, Weight (in kg), Height (in cm), and Gender1 .
You can find this in the gclus library as body.
1 library(gclus)
2 data(body); attach(body)
3 dim(body)
[1] 507
25
Let’s regress Weight on some of these predictors.
1. Gender was recorded as a binary variable (1 - male, 0 - female).
>head(body)
Biacrom
<dbl>
Biiliac
<dbl>
Bitro
<dbl>
ChestDp
<dbl>
1
42.9
26.0
31.5
17.7
2
43.7
28.5
33.5
16.9
3
40.1
28.2
33.3
20.9
4
44.3
29.9
34.0
18.4
5
42.5
29.9
34.0
21.5
6
43.3
27.0
31.5
19.6
6 rows | 1-5 of 26 columns
Scatterplot Weight vs Height
1
2
3
4
slr <- lm(Weight~Height)
par(mar = c(4.9, 3.9, 1, 1))
plot(Weight~Height)
abline(slr, col =4, lwd = 3)
# reduce white space around figure
Incorporating Gender
But we know more, eg. gender.
Question:
how do we
incorporate
categorical
variables
into this
model?
MLR with categorical variables
We need to create dummy variables.
A dummy, or indicator variable takes only the value 0 or 1 to
indicate the absence or presence of some categorical effect
that may be expected to shift the outcome.
This requires making one of the possible responses of the
categorical variable the reference (which means it is
assumed true in the base model), and then creating stand-in
(dummy) variables for the non-reference options.
It’s best understood through examples…
body MLR Model
The MLR model with 2 predictors will not look any different:
Y = β0 + β1 X1 + β2 X2
But now, we will consider having mixed data types:
Height (numeric)
Gender (qualitative/categorical)
If a qualitative predictor (also known as a factor) only has two
possible values (AKA levels), then incorporating it into a
regression model is very simple ….
R syntax (for mixed predictor types)
1 mlr <- lm(Weight ~ Height + factor(Gender))
Letting R know that Gender (1 = male, 0 = female) is a factor
is very important.
Failure to do this will result in R treating Gender as a number
(rather than a category).
While coding this up in R is very simple, we need to
understand that under the hood we are creating a dummy
variable for Male and using Female as our reference
variable to be used in our baseline model.
Under the hood
𝚆𝚎𝚒𝚐𝚑𝚝 = β0 + β1 𝙷𝚎𝚒𝚐𝚑𝚝 + β2 𝙼𝚊𝚕𝚎
We now have a dummy variable Male (1 = yes, 0 = no).
If the male, then Male = 1 and our model becomes:
𝚆𝚎𝚒𝚐𝚑𝚝 = β0 + β1 𝙷𝚎𝚒𝚐𝚑𝚝 + β2 (1)
If female, then Male = 0 and our model becomes:
𝚆𝚎𝚒𝚐𝚑𝚝 = β0 + β1 𝙷𝚎𝚒𝚐𝚑𝚝 + β2 (0)
= β0 + β1 𝙷𝚎𝚒𝚐𝚑𝚝
Parallel lines models
𝚆𝚎𝚒𝚐𝚑𝚝 =
β0 + β2 + β1 𝙷𝚎𝚒𝚐𝚑𝚝,
{β
0
+ β1 𝙷𝚎𝚒𝚐𝚑𝚝,
for males
for females
This is sometimes referred to as the parallel lines (or parallel
slopes) model.
An parallel slopes models include one numeric and one
categorical explanatory variable
This model allows for different intercepts but forces a
common slope.
Plot of Parallel Slope Model
Parallel lines fit
1 summary(mlr)
...
lm(formula = Weight ~ Height + factor(Gender))
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept)
-56.94949
9.42444 -6.043 2.95e-09 ***
Height
0.71298
0.05707 12.494 < 2e-16 ***
factor(Gender)1
8.36599
1.07296
7.797 3.66e-14 ***
--Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 8.802 on 504 degrees of freedom
Multiple R-squared: 0.5668,
Adjusted R-squared: 0.5651
F-statistic: 329.7 on 2 and 504 DF, p-value: < 2.2e-16
...
Renaming levels of factor
The non-reference level is made more obvious once we give
the levels meaningful names.
1 genderFM <- factor(ifelse(Gender==0, "female", "male"))
2 (sum.out <- summary(lm(Weight ~ Height + genderFM)))
...
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -56.94949
9.42444 -6.043 2.95e-09 ***
Height
0.71298
0.05707 12.494 < 2e-16 ***
genderFMmale
8.36599
1.07296
7.797 3.66e-14 ***
--Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 8.802 on 504 degrees of freedom
Multiple R-squared: 0.5668,
Adjusted R-squared: 0.5651
F-statistic: 329.7 on 2 and 504 DF, p-value: < 2.2e-16
...
Interpreting the output
This small p-value associated with the “male” dummy
variable indicates that, after controlling for height, there is
strong statistical evidence to suggest a difference in average
weight based on gender.
It is estimated that males will tend to be 8.37 kg heavier than
females of the same height.
N.B. The level selected as the baseline category is arbitrary,
and the final predictions for each group will be the same
regardless of this choice
Overkill?
This may see like overkill seeing as how Gender was
already coded up as 0 for female and 1 for male.
However, imagine if Gender instead was grouped as: male,
female or other.
In this case, we would need pick a reference level and create
two 1 dummy variables to represent other levels for this
categorical variable.
1. we will always need to set up one less dummy than the number of possible options,
i.e. levels, for the category, i.e. factor.
Gender with >2 Levels
Choosing Female1 as our reference level requires us to make a
dummy variable for Male and a dummy variable for Other.
𝚆𝚎𝚒𝚐𝚑𝚝 = β0 + β1 𝙷𝚎𝚒𝚐𝚑𝚝 + β2 𝙼𝚊𝚕𝚎 + β3 𝙾𝚝𝚑𝚎𝚛
We now have two dummy variables
𝙼𝚊𝚕𝚎 =
1
{0
if male
otherwise
𝙾𝚝𝚑𝚎𝚛 =
1
{0
if Other
otherwise
1. We could have just as easily made Male or Other our reference level (here’s how)
When the individual identifies as a male we have Male = 1,
Other = 0 and so our model becomes
𝚆𝚎𝚒𝚐𝚑𝚝 = β0 + β2 + β1 𝙷𝚎𝚒𝚐𝚑𝚝
When the individual identifies as a female (reference level) we
have Male = 0, Other = 0 and so our model becomes
𝚆𝚎𝚒𝚐𝚑𝚝 = β0 + β1 𝙷𝚎𝚒𝚐𝚑𝚝
When the individual identifies as Other we have Male = 0,
Other = 1 and so our model becomes
𝚆𝚎𝚒𝚐𝚑𝚝 = β0 + β3 + β1 𝙷𝚎𝚒𝚐𝚑𝚝
Parallel Lines with >2 Levels
As before, we have parallel lines1 (one line for each level in our
Gender factor)
⎧ β0 + β2 + β1 𝙷𝚎𝚒𝚐𝚑𝚝,
⎪
𝚆𝚎𝚒𝚐𝚑𝚝 = ⎨ β0 + β3 + β1 𝙷𝚎𝚒𝚐𝚑𝚝,
⎪
⎩ β0 + β1 𝙷𝚎𝚒𝚐𝚑𝚝,
for males
for other
for females
β2
describes the shift from Females (our reference) to Males
β3
describes the shift from Females (our reference) to Other
1. Depending on the sign of the coefficient, the parallel line for the non-reference level
may appear above or below the reference level.
Interaction with Mixed
Predictors
We can include interactions with mixed-type predictors as well.
𝚆𝚎𝚒𝚐𝚑𝚝 = β0 + β1 𝙷𝚎𝚒𝚐𝚑𝚝 + β2 𝙼𝚊𝚕𝚎 + β3 (𝙷𝚎𝚒𝚐𝚑𝚝 × 𝙼𝚊𝚕𝚎)
Now for males (Male =1) we have:
Weight = β0 + β1 (Height) + β2 (1)
+ β3 (Height × 1)
= (β0 + β2 ) + (β1 + β3 )(Height)
For female (Male = 0) we have:
Weight = β0 + β1 (Height) + β2 (0)
+ β3 (Height × 0)
= β0 + β1 × Height
We see that they have different intercepts and slopes.
Non-parallel lines
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# fit the model w/ interaction
intlm <- lm(Weight ~ Height*Gender
# store coeffiecents
icoefs <- intlm$coefficients
# Plot ------par(mar = c(4.9, 3.9, 1, 1))
plot(Weight~Height, col=Gender+1)
legend("topleft",col=c(2,1),pch=1,
legend=c("Male","Female"))
# plot the line for males
abline(a = icoefs[1]+ icoefs[3],
b = icoefs[2] + icoefs[4],
col=2, lwd=2)
# plot the line for female
abline(a = icoefs[1],
b= icoefs[2], lwd=2)
Interaction Model: Height*Gender
1 intlm <- lm(Weight ~ Height*genderFM); summary(intlm)
...
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept)
-43.81929
13.77877 -3.180 0.00156 **
Height
0.63334
0.08351
7.584 1.63e-13 ***
genderFMmale
-17.13407
19.56250 -0.876 0.38152
Height:genderFMmale
0.14923
0.11431
1.305 0.19233
--Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 8.795 on 503 degrees of freedom
Multiple R-squared: 0.5682,
Adjusted R-squared: 0.5657
F-statistic: 220.7 on 3 and 503 DF, p-value: < 2.2e-16
...
Issues to look out for
1. Non-linear relationships
2. Correlation of error terms
3. Non-constant variance of error terms
4. Outliers/Influential observations (high-leverage points)
5. Collinearity of predictors
Some of these topics will be covered in Lab 3 (read more in
ISLR 3.3.3, Lab 3.6 and [1][2])
Non-linearity Examples
Suppose we have a case where the response has a nonlinear relationship with the predictor(s).
For example, what if there’s a quadratic relationship?
We can extend the linear model in a very simple way to
accommodate non-linear relationships, using polynomial
regression.
Polynomial Regression
Easy. Fit a model of the form
Y = β0 + β1 X + β2 X
2
+ ϵ
Basically, if we square (or otherwise transform) the original
predictor, we can still fit a “linear” model for the response.
In line with the hierarchical principle, if you keep X in your
model, you should also keep X .
2
Though it’s important to keep in mind the change in
interpretation for β and β , for example
1
2
Example: Quadratic Simulation
We simulate 30 values from the following model where ϵ is
standard normally distributed.
Y = 15 + 2.3x − 1.5x
2
+ ϵ
Example: SLR fit
1 summary(linmod)
...
Call:
lm(formula = y ~ x)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 13.3206
0.3592 37.081 < 2e-16 ***
x
1.7866
0.3248
5.501 7.06e-06 ***
--Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.967 on 28 degrees of freedom
Multiple R-squared: 0.5194,
Adjusted R-squared: 0.5023
F-statistic: 30.26 on 1 and 28 DF, p-value: 7.059e-06
...
1 summary(quadmod)
...
Call:
lm(formula = y ~ x + x2)
Coefficients:
Estimate Std. Error t value
(Intercept) 15.3556
0.2509
61.20
x
2.2773
0.1529
14.89
x2
-1.6702
0.1578 -10.59
--Signif. codes: 0 '***' 0.001 '**' 0.01
Pr(>|t|)
< 2e-16 ***
1.54e-14 ***
4.14e-11 ***
'*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.8829 on 27 degrees of freedom
Multiple R-squared: 0.9067,
Adjusted R-squared: 0.8998
F-statistic: 131.2 on 2 and 27 DF, p-value: 1.244e-14
While it is clear from the fitted line that the simple linear
regression (SLR) model is too simple, we can do some
Regression Model Diagnostics to verify.
Diagnostic Plots
1. Residuals vs Fitted: checks for linearity. A “good” plot will
have a red horizontal line, without distinct patterns.
2. Normal Q-Q: checks if residuals are normally distributed. It’s
“good” if points follow the straight dashed line.
3. Scale-Location: checks the equal variance of the residuals.
“Good” to see horizontal line with equally spread points.
4. Residuals vs Leverage: identifies influential points1.
1. extreme values that might influence the regression results when included or excluded
from the analysis.
Example: SLR Residuals
1 plot(linmod)
Example: Quadratic Fit
1 summary(quadmod)
...
Call:
lm(formula = y ~ x + x2)
Coefficients:
Estimate Std. Error t value
(Intercept) 15.3556
0.2509
61.20
x
2.2773
0.1529
14.89
x2
-1.6702
0.1578 -10.59
--Signif. codes: 0 '***' 0.001 '**' 0.01
Pr(>|t|)
< 2e-16 ***
1.54e-14 ***
4.14e-11 ***
'*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.8829 on 27 degrees of freedom
Multiple R-squared: 0.9067,
Adjusted R-squared: 0.8998
F-statistic: 131.2 on 2 and 27 DF, p-value: 1.244e-14
Example: Quadratic Residuals
1 plot(quadmod)
Example: Cars
1 library(ISLR)
2 scar <- lm(mpg~horsepower,data=Auto); plot(scar)
1 pcar <- lm(mpg~horsepower+ I(horsepower^2),data=Auto); plot(pcar)
Exemplary Residual Plot
1 xx <- runif(500); eps <- rnorm(500); yy = 8 + 6*xx + eps
2 simfit <- lm(yy~xx); plot(simfit)
Non-parametric model
In this context, lm() assumed a linear functional form for
f (X)
What about a nonparametric alternative?
Let’s return to one of the simplest and best-known nonparametric methods, K-nearest neighbors, but this time lets’
use it for regression rather than classification.
You can probably guess what this method looks like from
based on our first discussions on KNN classification, but let’s
spell it out …
KNN Regression
Given positive integer K (chosen by user) and observation x :
0
1. Identify the K closest points to x in training data. Call this
set N
0
0
2. Estimate f (x
0)
using
̂ x ) =
f (
0
1
K ∑
yi
i∈N0
See Ch 7 of Campbell, T., Timbers, T., Lee, M. (2022). Data
Science: A First Introduction. United States: CRC Press.
K = 20
Visualization 1
Visualization 2
K=5
K = 5 Visualization
K=1
Conclusion
Small values of K are more flexible
produce low bias but high variance
At K = 1 the prediction in a given region is entirely
dependent on just one observation.
In contrast, large values of K are “smoother” with less steps
less variance (changing one observation has a smaller effect)
more bias (smoothing masks some of the structure in f (X))
Again we see the bias-variance trade off in action!