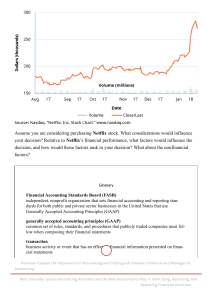
Single-Sample t test Statistical test that compares a sample mean to a population mean when the population standard deviation (σ) is not known. ▪ If population standard deviation (σ) is given, do a z-test. ▪ If sample standard deviation (s) is given (not population standard deviation) or can be calculated, do a t-test. Example: Dr. Farshad’s reaction time study Do adults with attention deficit hyperactivity disorder (ADHD) differ in reaction time from the general population? Reaction time test for adults in the US, μ = 200 milliseconds (msec) Obtained a random sample of 141 adults diagnosed with ADHD from ADHD treatment centers in Illinois Reaction time for the sample (M = 220, s = 27) Example: Number of minutes of Netflix viewing per day Do people in PSY 305 differ in number of minutes of Netflix viewing per day compared to the general population? ▪ Netflix released company data that suggested the average subscriber views 93 minutes of content each day. ▪ Let’s figure out how the mean number of minutes for our sample (the class) compares to the population mean of 93 minutes. STEP 1 - Pick a Test STEP 2 - Check the Assumptions STEP 3 - List the Hypotheses STEP 4 - Set the Decision Rule STEP 5 - Calculate the Test Statistic STEP 6 - Interpret the Results STEP 1 - Pick a Test We’re comparing mean of a sample to the mean of a population. We do not know population standard deviation, so we must choose the single-sample t test. STEP 2 – Check the Assumptions Assumption Explanation Robustness Random sample The sample is a random sample from the population. Robust if violated. Independence of observations Cases within the sample don’t influence each other. Not robust to violations Normality The dependent variable is normally distributed in the population. Robust to violations if the sample size is large. Assumptions for the Single-Sample t Test STEP 3 – List the Hypotheses ▪ What do we think will be true? ▪ Are we thinking our mean will vary in some way (either more or less) from the general population in minutes of Netflix watched per day? Two-tailed test ▪ Are we thinking we might be watching more Netflix than the general population? Or that we might be watching less Netflix than the general population? Either of these would call for a one-tailed test STEP 3 – List the Hypotheses Two-tailed, non-directional, single-sample t test ▪ Don’t know whether we might watch more or less Netflix than the general population ▪ H0: μStats Class = 93 ▪ H1: μStats Class ≠ 93 One-tailed, directional, single-sample t test ▪ We believe we watch more Netflix than the general population. ▪ H0: μStats Class ≤ 93 ▪ H1: μStats Class > 93 One-tailed, directional, single-sample t test ▪ We believe we watch less Netflix than the general population. ▪ H0: μStats Class ≥ 93 ▪ H1: μStats Class < 93 STEP 4 – Set the Decision Rule Critical Value of t ▪ Value of t used to determine whether null hypothesis is rejected or not ▪ Abbreviated tcv Three pieces of information are needed to find the tcv 1) Is the test one-tailed or two-tailed? 2) How willing are you to make a Type I error (when the researcher concludes, mistakenly, that the null hypothesis should be rejected. False positive. Conclude your results are significant when they actually occurred by chance)? -Let’s say only willing to make a Type I error 5% of the time, α = .05 3) How large is the sample size? N = 30… Degrees of freedom: the number of values in a sample that are free to vary when estimating statistical parameters. Ex: Let’s suppose you want to walk a different dog every day. N=7 Degrees of freedom: the number of values in a sample that are free to vary when estimating statistical parameters. Ex: Let’s suppose you want to walk a different dog every day. N=7 Degrees of freedom (df) = N – 1 df = 7-1 = 6 df = 6 Degrees of Freedom (df ) Number of values in a sample that are free to vary 𝑑𝑓 = 𝑁 − 1 where 𝑑𝑓 = degrees of freedom 𝑁 = sample size For our study, there are 30 participants in the sample, so degrees of freedom are calculated like this: df = 30 − 1 = 29 df = 29 STEP 4 – Set Decision Rule Netflix Example ▪ With df = 29, α = .05, two-tailed, border between 1) Two-tailed the rare and common zones is ± 2.045 2) Alpha level, α = .05 ▪ If observed value of t falls in the rare zone, null 3) N = 30, df = 29 hypothesis is rejected; one fails to reject it if the observed value falls in the common zone. Decision rules written mathematically: Setting the Decision Rule: Two-Tailed, Single-Sample t Test IF the critical value of t is ± 2.045 If t ≤ –2.045 or if t ≥ 2.045, then reject H0 If –2.045 < t < 2.045, then fail to reject H0 t STEP 5 – Calculate the Test Statistic 𝑀−𝜇 𝑡= 𝑆𝑀 where 𝑡 = 𝑡 value 𝑀 = sample mean 𝜇 = population mean or a specified value 𝑆𝑀 = estimated standard error of the mean (Equation from before, is below) 𝑆𝑀 = 𝑠 𝑁 STEP 5 – Calculate the Test Statistic 𝑆𝑀 = Calculate estimated standard error of the mean (sM) Calculate t value N = 30, s = 19.6084, M = 43.7500, μ = 93 = 𝑠 𝑁 19.6084 30 𝑀−𝜇 𝑡= 𝑆𝑀 43.7500 − 93 = 3.5800 19.6084 = 5.4772 −49.2500 = 3.5800 =3.5800 = −13.7570 =3.58 = -13.76 STEP 6 – Interpret the Results Need to answer three questions 1) Was the null hypothesis rejected? 2) How big is the effect? 3) What is the confidence interval? STEP 6 – Interpret the Results 1) Was the null hypothesis rejected? Well… which of the following statements is true? If t ≤ –2.045 or if t ≥ 2.045, then reject H0 OR If –2.045 < t < 2.045, then fail to reject H0 We should also report he results in APA format. APA format provides five pieces of information: (1) what test was done, (2) the number of cases, (3) the value of the test statistic, (4) the alpha level used, and (5) whether the null hypothesis was or wasn’t rejected. In APA format, the results would be (WE WILL FILL THIS IN DURING CLASS) t(29) = -13.76, p < .05 • The initial t says that the statistical test was a t test. • The sample size, 30, is present in disguised form. The number 29, in parentheses, is the degrees of freedom for the t test. For a singlesample t test, df = N – 1. That means N = df + 1. So, if df = 29, N = 29 + 1 = 30. • The observed t value, -13.76, is reported. This number is the value of t calculated, not the critical value of t found in the critical value of t table. Note that APA format requires the value to be reported to two decimal places, no more and no fewer. • The .05 tells that alpha was set at .05 (if it is). • The final part, p < .05, reveals that the null hypothesis was rejected. It means that the observed result (our calculated t statistic) is a rare result—it has a probability of less than .05 of occurring when the null hypothesis is true. If we stopped after answering only the first interpretation question, this is what we would write for an interpretation: There is a statistically significant difference between the mean number of minutes spent watching Netflix daily for the students in our statistics class and the number of minutes of Netflix watched in the general United States population, t(29) = -13.76, p < .05. The students in our class (M = 43.75) watch fewer minutes of Netflix than does the general public (μ = 93). STEP 6 – Interpret the Results Effect Size (d) ▪ Measure of the degree of impact of the independent variable on the dependent variable. It’s kind of like a z score—it is a standard score that allows different effects (measured by different variables in different studies) to be expressed—and compared—with a common unit of measurement. 𝑀−𝜇 𝑑= 𝑠 where 𝑑 = the effect size 𝑀 = sample mean 𝜇 = hypothesized sample mean (population mean) 𝑠 = sample standard deviation STEP 6 – Interpret the Results Netflix study M = 43.7500, μ = 93, s = 19.6084 d = -2.51 𝑀−𝜇 𝑑= 𝑠 43.7500 − 93 = 19.6084 −49.2500 = 19.6084 =-2.5117 = -2.51 Effect Sizes in the Social and Behavioral Sciences “The effect of being in this class falls in the large range, suggesting that being in this class is associated with significantly less daily Netflix viewing.” Also called coefficient of determination (r squared. r2) Also tells how much impact the IV has on the DV But is a percentage, ranging from 0% - 100% Percentage of variability in the outcome (DV) scores that is accounted for (or predicted) by the explanatory variable (IV). 2 𝑡 𝑟2 = 2 × 100 𝑡 + 𝑑𝑓 where 𝑟 2 = the percentage of variability in the outcome variable DV that is accounted for by the explanatory variable (IV) 𝑡 2 = the squared value of 𝑡 (calculated in previous step, but squared) 𝑑𝑓 = the degrees of fredom for the 𝑡 value The closer r2 is to 100%, the stronger the effect of the explanatory variable (IV) is and the less variability in the outcome variable (DV) remains to be explained by other variables. The closer r2 is to 0%, the weaker the effect of the explanatory variable (IV) and the more variability in the DV exists to be explained by other variables. For the Netflix data, these calculations would lead to the conclusion that r2 = 86.72% 𝑟2 𝑡2 = 2 × 100 𝑡 + 𝑑𝑓 −13.762 = × 100 −13.762 + 29 189.3376 = × 100 189.3376 + 29 189.3376 = × 100 218.3376 = .8672 × 100 = 86.72% “Being in this class has a large effect on one’s amount of time watching Netflix daily. In the present study, knowing whether someone is in this class explains 86.72% of the variability in daily Netflix viewing minutes.” Cohen (1988) standards for r2: • A small effect is an r2 ≈ 1%. • A medium effect is an r2 ≈ 9%. • A large effect is an r2 ≈ 25%. 𝟗𝟓%𝑪𝑰𝝁𝑫𝒊𝒇𝒇 = 𝑴 − 𝝁 ± 𝒕𝒄𝒗 × 𝑺𝑴 𝑤ℎ𝑒𝑟𝑒 95%𝐶𝐼𝜇𝐷𝑖𝑓𝑓 = 𝑡ℎ𝑒 95% 𝑐𝑜𝑛𝑓𝑖𝑑𝑒𝑛𝑐𝑒 𝑖𝑛𝑡𝑒𝑟𝑣𝑎𝑙 𝑓𝑜𝑟 𝑡ℎ𝑒 𝑑𝑖𝑓𝑓𝑒𝑟𝑒𝑛𝑐𝑒 𝑏𝑒𝑡𝑤𝑒𝑒𝑛 𝑡𝑤𝑜 𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛 𝑚𝑒𝑎𝑛𝑠 𝑀 = 𝑡ℎ𝑒 𝑠𝑎𝑚𝑝𝑙𝑒 𝑚𝑒𝑎𝑛 𝑓𝑟𝑜𝑚 𝑜𝑛𝑒 𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛 𝜇 = 𝑚𝑒𝑎𝑛 𝑓𝑜𝑟 𝑡ℎ𝑒 𝑜𝑡ℎ𝑒𝑟 𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛 𝑡𝑐𝑣 = 𝑡ℎ𝑒 𝑐𝑟𝑖𝑡𝑖𝑐𝑎𝑙 𝑣𝑎𝑙𝑢𝑒 𝑜𝑓 𝑡, 𝒕𝒘𝒐 − 𝒕𝒂𝒊𝒍𝒆𝒅, 𝛼 = .05, 𝑑𝑓 = 𝑁 − 1 𝑆𝑀 = 𝑡ℎ𝑒 𝑒𝑠𝑡𝑖𝑚𝑎𝑡𝑒𝑑 𝑠𝑡𝑎𝑛𝑑𝑎𝑟𝑑 𝑒𝑟𝑟𝑜𝑟 𝑜𝑓 𝑡ℎ𝑒 𝑚𝑒𝑎𝑛 (𝑜𝑙𝑑 𝑒𝑞𝑢𝑎𝑡𝑖𝑜𝑛) STEP 6 – Interpret the Results (calculate 95% confidence interval for difference between 2 population means) μ = 93, M = **, sM = **, tcv = 2.045 𝟗𝟓%𝑪𝑰𝝁𝑫𝒊𝒇𝒇 = 𝑴 − 𝝁 ± 𝒕𝒄𝒗 × 𝑺𝑴 𝟗𝟓%𝑪𝑰𝝁𝑫𝒊𝒇𝒇 = 𝟒𝟑. 𝟕𝟓 − 𝟗𝟑 ± 𝟐. 𝟎𝟒𝟓 × 𝟑. 𝟓𝟖𝟎𝟎 𝟗𝟓%𝑪𝑰𝝁𝑫𝒊𝒇𝒇 = −𝟒𝟗. 𝟐𝟓 ± 𝟕. 𝟑𝟐𝟏𝟏 From -56.5711 to -41.9289 From -56.57 to -41.93 The 95% confidence interval for the difference between population means ranges from -56.57 to -41.93. In APA format, this confidence interval would be reported as 95% CI [-56.57, -41.93]. Imagine a race: a person representing the average American crosses the finish line first, followed by a person representing the average adult in a stats class. How much slower (how much less Netflix viewing) is the average adult in a stats class? Confidence interval says the average adult in a stats class probably (there’s a 95% chance) trails the average American in Netflix viewing by anywhere from 41.93 to 56.57 minutes. Four points addressed in our interpretation Brief explanation of the study Present some facts, means of the sample and the population. Be selective and only report what is most relevant Explain the meaning of the results Offer some suggestions for future research, “replicate” Replicate To repeat a study, usually introducing some change in procedure to make it better Here is our full interpretation: A study compared the amount of daily Netflix viewing minutes of a sample of statistics students (M = 43.75) to the known amount of Netflix viewing minutes for the American population (μ = 93). The amount of daily Netflix viewing for statistics students was statistically significantly less than the number of minutes found in the general population [t(29) = -13.76, p < .05]. The size of the difference from the larger population probably ranges from a 41.93- to a 56.57-minute reduction in Netflix viewing. This is not a small difference—these results suggest that being in a statistics class is associated with a large level of reduction in daily Netflix viewing. If one were to replicate this study, it would be advisable to obtain a broader sample of adults in statistics classes, not just limiting it to one class at one university. This would increase the generalizability of the results.