ISE202_week2_hw_Eileen Phuong
2022-07-22
Problem 2.25
Build data set and load tidyverse library
library(rmarkdown)
library(tidyverse)
## ── Attaching packages ─────────────────────────────────────── tidyverse
1.3.1 ──
##
##
##
##
✔
✔
✔
✔
ggplot2
tibble
tidyr
readr
3.3.6
3.1.7
1.2.0
2.1.2
✔
✔
✔
✔
purrr
dplyr
stringr
forcats
0.3.4
1.0.9
1.4.0
0.5.1
## ── Conflicts ──────────────────────────────────────────
tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag()
masks stats::lag()
library(ggpubr)
x <- c(65, 81, 57, 66, 82, 82, 67, 59, 75, 70)
y <- c(64, 71, 83, 59, 65, 56, 69, 74, 82, 79)
z <- cbind(x, y)
print(z)
##
## [1,]
## [2,]
## [3,]
## [4,]
## [5,]
## [6,]
## [7,]
## [8,]
## [9,]
## [10,]
x
65
81
57
66
82
82
67
59
75
70
y
64
71
83
59
65
56
69
74
82
79
colnames(z) <- c("Type1", "Type2")
ztidy <- as_tibble(z)
is.data.frame(ztidy)
## [1] TRUE
2.25a: Test the hypothesis that the two variances are equal. Use alpha=0.05.
𝐻0 : 𝜎12 = 𝜎22 against 𝐻1 : 𝜎12 ! = 𝜎22
var.test(ztidy$Type1, ztidy$Type2,alternative = "two.sided", conf.level =
0.95)
##
##
##
##
##
##
##
##
##
##
##
F test to compare two variances
data: ztidy$Type1 and ztidy$Type2
F = 0.97822, num df = 9, denom df = 9, p-value = 0.9744
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.2429752 3.9382952
sample estimates:
ratio of variances
0.9782168
result <- var.test(ztidy$Type1, ztidy$Type2,alternative = "two.sided",
conf.level = 0.95)
names(result)
## [1] "statistic"
## [6] "null.value"
"parameter"
"p.value"
"alternative" "method"
"conf.int"
"data.name"
"estimate"
result$statistic
##
F
## 0.9782168
result$p.value
## [1] 0.9743665
2.25a: Conclusion
The P-value = 0.9744 is greater than the significant level 0.05, we fail to reject the null
hypothesis and conclude that there is no significant evidence that the two variances are
different.
2.25b: Test the hypothesis that the mean burning times are equal. Use alpha=0.05. What is
the p-value?
𝐻0 : 𝜇1 = 𝜇2 against 𝐻1 : 𝜇1 ! = 𝜇2
t.test(ztidy$Type1, ztidy$Type2, alternative = "two.sided", var.equal = TRUE)
##
## Two Sample t-test
##
## data: ztidy$Type1 and ztidy$Type2
## t = 0.048008, df = 18, p-value = 0.9622
##
##
##
##
##
##
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-8.552441 8.952441
sample estimates:
mean of x mean of y
70.4
70.2
result <- t.test(ztidy$Type1, ztidy$Type2, alternative = "two.sided",
var.equal = TRUE)
result$p.value
## [1] 0.9622388
2.25b: Conclusion
Since P-value 0.962 is greater than the significance level 0.05, we fail to reject null
hypothesis and conclude that there is no significant evidence that the two means are
different.
2.25c: Discuss the role of the normality assumption in this problem. Check the assumption of
normality for both type of flares.
type1_dist <- ggplot(data = ztidy, aes(sample = Type1))
type1_dist + stat_qq() + stat_qq_line()
type2_dist <- ggplot(data = ztidy, aes(sample = Type2))
type2_dist + stat_qq() + stat_qq_line()
shapiro.test(ztidy$Type1)
##
## Shapiro-Wilk normality test
##
## data: ztidy$Type1
## W = 0.91359, p-value = 0.3065
shapiro.test(ztidy$Type2)
##
## Shapiro-Wilk normality test
##
## data: ztidy$Type2
## W = 0.95478, p-value = 0.7251
2.25c: Conclusion
The assumption of normality and equal variances are reasonable because the p-value
for both formulations are greater than 0.05 according to the Shapiro-Wilk normality test.
Problem 2.27
Build data set and load tidyverse library
Temp95 <- c(11.176, 7.089, 8.097, 11.739, 11.291, 10.759, 6.467, 8.315)
Temp100 <- c(5.263, 6.748, 7.461, 7.015, 8.133, 7.418, 3.772, 8.963)
z <- cbind(Temp95, Temp100)
ztidy <- as_tibble(z)
is.data.frame(ztidy)
## [1] TRUE
2.27a: Is there evidence to support the claim that the higher baking temperature results in
wafers with a lower mean photoresist thickness? Use alpha=0.05
𝐻0 : 𝜇𝐿 = 𝜇𝐻 against 𝐻1 : 𝜇𝐿 > 𝜇𝐻
var.test(ztidy$Temp95, ztidy$Temp100, alternative = "two.sided", conf.level =
0.95)
##
##
##
##
##
##
##
##
##
##
##
F test to compare two variances
data: ztidy$Temp95 and ztidy$Temp100
F = 1.6381, num df = 7, denom df = 7, p-value = 0.5306
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.3279572 8.1822436
sample estimates:
ratio of variances
1.638117
result <- var.test(ztidy$Temp95, ztidy$Temp100, alternative = "two.sided",
conf.level = 0.95)
t.test(ztidy$Temp95, ztidy$Temp100, alternative = "greater", conf.level =
0.95, var.equal = TRUE)
##
##
##
##
##
##
##
##
##
##
##
Two Sample t-test
data: ztidy$Temp95 and ztidy$Temp100
t = 2.6751, df = 14, p-value = 0.009059
alternative hypothesis: true difference in means is greater than 0
95 percent confidence interval:
0.8608158
Inf
sample estimates:
mean of x mean of y
9.366625 6.846625
result <- t.test(ztidy$Temp95, ztidy$Temp100, alternative = "greater",
conf.level = 0.95, var.equal = TRUE)
names(result)
##
##
[1] "statistic"
[6] "null.value"
"parameter"
"stderr"
"p.value"
"conf.int"
"alternative" "method"
"estimate"
"data.name"
result$statistic
##
t
## 2.675111
result$p.value
## [1] 0.009058979
2.27a: Conclusion
First checking for equal variance using the F test. Since the P-value from the F-test is
0.5306 and greater than significance level 0.05, failed to reject null hypothesis and
conclude that the variances are about equal.
Set equal variance to TRUE on the two sample t-test based on the result of the F-test. The Pvalue is 0.0091 and less than the significance level 0.05, the null hypothesis is rejected
and we can conclude that higher baking temperature will likely result in lower mean
photoresist thickness.
2.27b: What is the p-value?
result$p.value
## [1] 0.009058979
2.27c: Find a 95% confidence interval on the difference in the means. Interpret the interval.
result$conf.int
## [1] 0.8608158
Inf
## attr(,"conf.level")
## [1] 0.95
2.27c: Conclusion
Since the null hypothesis value 0 is outside the bounds of confidence interval, the null
hypothesis is rejected and we can conclude that the higher baking temperature process
will result in a lower mean photoresist thickness.
2.27d: Draw dot diagrams
indata2 <- ztidy %>% pivot_longer(cols = starts_with("Temp"), names_to =
"Temperature", values_to = "thickness")
View(indata2)
ggplot(indata2, aes(x = thickness, fill = factor(Temperature))) +
geom_dotplot(stackgroups = TRUE, bindwidth = 1, binpositions = "all")
## Warning: Ignoring unknown parameters: bindwidth
## Bin width defaults to 1/30 of the range of the data. Pick better value
with `binwidth`.
2.27e: Check assumption of normality
type1_dist <- ggplot(data = ztidy, aes(sample = Temp95))
type1_dist + stat_qq() + stat_qq_line()
type2_dist <- ggplot(data = ztidy, aes(sample = Temp100))
type2_dist + stat_qq() + stat_qq_line()
shapiro.test(ztidy$Temp95)
##
## Shapiro-Wilk normality test
##
## data: ztidy$Temp95
## W = 0.87501, p-value = 0.1686
shapiro.test(ztidy$Temp100)
##
## Shapiro-Wilk normality test
##
## data: ztidy$Temp100
## W = 0.9348, p-value = 0.5607
2.27e: Conclusion
The assumption of normality are reasonable because the p-value for both processes are
greater than 0.05 according to the Shapiro-Wilk normality test.
2.27f: Find the power of this test for detecting an actual difference in means of 2.5kA
𝑆𝑝 = SQRT {[(𝑛1 - 1)𝑆12 + (𝑛2 - 1)𝑆22 ]/(𝑛1 + 𝑛2 -2)} = 1.88
where 𝑛1 and 𝑛2 = 8, 𝑆12 = 2.09956, 𝑆22 = 1.6404
library(pwr)
power.t.test(n = 8, delta = 2.5, sd = 1.88, sig.level = 0.05, alternative =
"one.sided", type = "two.sample")
##
##
Two-sample t
##
##
n =
##
delta =
##
sd =
##
sig.level =
##
power =
##
alternative =
##
## NOTE: n is number
test power calculation
8
2.5
1.88
0.05
0.811349
one.sided
in *each* group
result <- power.t.test(n = 8, delta = 2.5, sd = 1.88, sig.level = 0.05,
alternative = "one.sided", type = "two.sample")
result$power
## [1] 0.811349
2.27g: What sample size would be necessary to detect an actual difference in means of 1.5kA
with a power of at least 0.9?
power.t.test(power = 0.9, delta = 1.5, sd = 1.88, sig.level = 0.05,
alternative = "one.sided", type = "two.sample")
##
##
Two-sample t
##
##
n =
##
delta =
##
sd =
##
sig.level =
##
power =
##
alternative =
##
## NOTE: n is number
test power calculation
27.60861
1.5
1.88
0.05
0.9
one.sided
in *each* group
size <- power.t.test(power = 0.9, delta = 1.5, sd = 1.88, sig.level = 0.05,
alternative = "one.sided", type = "two.sample")
names(size)
## [1] "n"
"delta"
## [6] "alternative" "note"
"sd"
"method"
"sig.level"
"power"
size$n
## [1] 27.60861
Problem 2.30
x <- c(6.08, 6.22, 7.99, 7.44, 6.48, 7.99, 6.32, 7.60, 6.03, 7.52)
y <- c(5.73, 5.80, 8.42, 6.84, 6.43, 8.76, 6.32, 7.62, 6.59, 7.67)
dif <- x - y
View(dif)
z <- cbind(x, y, dif)
print(z)
##
## [1,]
## [2,]
## [3,]
## [4,]
## [5,]
## [6,]
## [7,]
## [8,]
## [9,]
## [10,]
x
6.08
6.22
7.99
7.44
6.48
7.99
6.32
7.60
6.03
7.52
y
5.73
5.80
8.42
6.84
6.43
8.76
6.32
7.62
6.59
7.67
dif
0.35
0.42
-0.43
0.60
0.05
-0.77
0.00
-0.02
-0.56
-0.15
colnames(z) <- c("BirthOrder1", "BirthOrder2", "Difference")
ztidy <- as_tibble(z)
is.data.frame(ztidy)
## [1] TRUE
2.30a: Is the assumption that the difference in score is normally distributed reasonable?
dif_dist <- ggplot(data = ztidy, aes(sample = Difference))
dif_dist + stat_qq() + stat_qq_line()
shapiro.test(ztidy$Difference)
##
## Shapiro-Wilk normality test
##
## data: ztidy$Difference
## W = 0.96727, p-value = 0.8645
2.30a: Conclusion
The assumption of normality is reasonable because the p-value for the difference in score
is greater than 0.05 according to the Shapiro-Wilk normality test.
2.30b: Find a 95% confidence interval on the difference in mean score. Is there any evidence
that mean score depends on birth order?
𝐻0 : 𝜇𝑑 = 0 against 𝐻1 : 𝜇𝑑 ! = 0
t.test(ztidy$BirthOrder1, ztidy$BirthOrder2, paired = TRUE, conf.level =
0.95)
##
##
##
##
##
##
##
Paired t-test
data: ztidy$BirthOrder1 and ztidy$BirthOrder2
t = -0.36577, df = 9, p-value = 0.723
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
## -0.3664148 0.2644148
## sample estimates:
## mean difference
##
-0.051
result <- t.test(ztidy$BirthOrder1, ztidy$BirthOrder2, paired = TRUE,
conf.level = 0.95)
result$conf.int
## [1] -0.3664148 0.2644148
## attr(,"conf.level")
## [1] 0.95
2.30b: Conclusion
Since the null hypothesis value, 0 is inside the bounds of confidence interval, we fail to
reject the null hypothesis and conclude that the mean scores do not depend on the birth
order.
2.30c: Test an appropriate set of hypothesis indicating that the mean score does not depend
on birth order.
result$p.value
## [1] 0.7229845
2.30c: Conclusion
Since the P-value is 0.723 is greater than the significance level 0.05, we failed to reject the
null hypothesis and conclude that the mean score does not depend on the birth order.
Problem 2.31
Kmethod <- c(1.186, 1.151, 1.322, 1.339, 1.200, 1.402, 1.365, 1.537, 1.559)
Lmethod <- c(1.061, 0.992, 1.063, 1.062, 1.065, 1.178, 1.037, 1.086, 1.052)
difference <- Kmethod - Lmethod
View(dif)
z <- cbind(Kmethod, Lmethod, difference)
print(z)
##
##
##
##
##
##
##
##
##
##
[1,]
[2,]
[3,]
[4,]
[5,]
[6,]
[7,]
[8,]
[9,]
Kmethod Lmethod difference
1.186
1.061
0.125
1.151
0.992
0.159
1.322
1.063
0.259
1.339
1.062
0.277
1.200
1.065
0.135
1.402
1.178
0.224
1.365
1.037
0.328
1.537
1.086
0.451
1.559
1.052
0.507
ztidy <- as_tibble(z)
is.data.frame(ztidy)
## [1] TRUE
2.31a: Is there any evidence to support a claim that there is a difference in mean performance
between the two methods. Use alpha=0.05.
𝐻0 : 𝜇𝐾 = 𝜇𝐿 against 𝐻1 : 𝜇𝐾 ! = 𝜇𝐿
t.test(ztidy$Kmethod, ztidy$Lmethod, paired = TRUE, conf.level = 0.95)
##
##
##
##
##
##
##
##
##
##
##
Paired t-test
data: ztidy$Kmethod and ztidy$Lmethod
t = 6.0819, df = 8, p-value = 0.0002953
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
0.1700423 0.3777355
sample estimates:
mean difference
0.2738889
result <- t.test(ztidy$Kmethod, ztidy$Lmethod, paired = TRUE, conf.level =
0.95)
result$conf.int
## [1] 0.1700423 0.3777355
## attr(,"conf.level")
## [1] 0.95
2.31a: Conclusion
Since the P-value 0.000295 is less than the significance level 0.05, the null hypothesis is
rejected and we can conclude that the two methods yield different shear strength.
2.31b: What is the P-value?
result$p.value
## [1] 0.0002952955
2.31c: What is the 95% confidence interval?
result$conf.int
## [1] 0.1700423 0.3777355
## attr(,"conf.level")
## [1] 0.95
2.31d: Investigate the normality assumption for both samples.
type1_dist <- ggplot(data = ztidy, aes(sample = Kmethod))
type1_dist + stat_qq() + stat_qq_line()
type2_dist <- ggplot(data = ztidy, aes(sample = Lmethod))
type2_dist + stat_qq() + stat_qq_line()
shapiro.test(ztidy$Kmethod)
##
## Shapiro-Wilk normality test
##
## data: ztidy$Kmethod
## W = 0.92905, p-value = 0.4724
shapiro.test(ztidy$Lmethod)
##
## Shapiro-Wilk normality test
##
## data: ztidy$Lmethod
## W = 0.84182, p-value = 0.06051
2.31d: Conclusion
The assumption of normality are reasonable because the p-value for both samples are
greater than 0.05 according to the Shapiro-Wilk normality test.
2.31e: Investigate the normality assumption for the difference in ratios for the two methods.
type1_dist <- ggplot(data = ztidy, aes(sample = difference))
type1_dist + stat_qq() + stat_qq_line()
shapiro.test(ztidy$difference)
##
## Shapiro-Wilk normality test
##
## data: ztidy$difference
## W = 0.91678, p-value = 0.3663
2.31e: Conclusion
The assumption of normality is reasonable because the p-value for the difference in ratio
is greater than 0.05 according to the Shapiro-Wilk normality test.
2.31f: Discuss the role of normality assumption in paired t-test.
A paired samples t-test assumes that the differences between the pairs should be
approximately normally distributed. This is important because if the differences between
the pairs are not normally distributed then it is not valid to use the p-value from the test to
draw conclusions.
Problem 2.34
Solution1 <- c(9.9, 9.4, 10.0, 10.3, 10.6, 10.3, 9.3, 9.8)
Solution2 <- c(10.2, 10.0, 10.7, 10.5, 10.6, 10.2, 10.4, 10.3)
difference <- Solution1 - Solution2
View(dif)
z <- cbind(Solution1, Solution2, difference)
print(z)
##
##
##
##
##
##
##
##
##
[1,]
[2,]
[3,]
[4,]
[5,]
[6,]
[7,]
[8,]
Solution1 Solution2 difference
9.9
10.2
-0.3
9.4
10.0
-0.6
10.0
10.7
-0.7
10.3
10.5
-0.2
10.6
10.6
0.0
10.3
10.2
0.1
9.3
10.4
-1.1
9.8
10.3
-0.5
ztidy <- as_tibble(z)
is.data.frame(ztidy)
## [1] TRUE
2.34a: Do the data indicate that the claim that both solution have the same mean etch rate is
valid? Use alpha=0.05 and assume equal variances.
𝐻0 : 𝜇1 = 𝜇2 against 𝐻1 : 𝜇1 ! = 𝜇2
t.test(ztidy$Solution1, ztidy$Solution2, var.equal = TRUE, conf.level = 0.95)
##
##
##
Two Sample t-test
##
##
##
##
##
##
##
##
data: ztidy$Solution1 and ztidy$Solution2
t = -2.3016, df = 14, p-value = 0.03724
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.79689302 -0.02810698
sample estimates:
mean of x mean of y
9.9500
10.3625
result <- t.test(ztidy$Solution1, ztidy$Solution2, var.equal = TRUE,
conf.level = 0.95)
result$p.value
## [1] 0.03723611
2.34a: Conclusion
Since the P-value 0.0372 is less than 0.05, we can reject the null hypothesis and conclude
that the two solutions have different mean etch rate.
2.34b: Find a 95% confidence interval on the difference in mean etch rates.
result$conf.int
## [1] -0.79689302 -0.02810698
## attr(,"conf.level")
## [1] 0.95
2.34c: Use normal probability plots to investigate the adequacy of the assumption of
normality and equal variances.
type1_dist <- ggplot(data = ztidy, aes(sample = Solution1))
type1_dist + stat_qq() + stat_qq_line()
type2_dist <- ggplot(data = ztidy, aes(sample = Solution2))
type2_dist + stat_qq() + stat_qq_line()
shapiro.test(ztidy$Solution1)
##
## Shapiro-Wilk normality test
##
## data: ztidy$Solution1
## W = 0.9549, p-value = 0.7603
shapiro.test(ztidy$Solution2)
##
## Shapiro-Wilk normality test
##
## data: ztidy$Solution2
## W = 0.9768, p-value = 0.9454
2.34c: Conclusion
The assumption of normality and equal variances are reasonable because the p-value
for the two solution samples are greater than 0.05 according to the Shapiro-Wilk normality
test. Because the slope of the two plots are about the same, equal variance are reasonable.
Problem from Wk2 slides
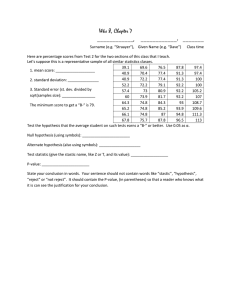
Consider the hypothesis test 𝐻0 : 𝜎12 = 𝜎22 against 𝐻1 : 𝜎12 < 𝜎22 . Suppose that the sample
sizes are 𝑛1 = 5 and 𝑛2 = 10, and that 𝑠12 = 23.2 and 𝑠22 = 28.8. Use 𝛼 = 0.05. Test the
𝜎
hypothesis and explain how the test could be conducted with a confidence interval on 𝜎1
2
𝐹0 = 𝑠12 /𝑠22 = 0.8056
𝑓1 − 𝑎𝑙𝑝ℎ𝑎, 𝑛1 − 1, 𝑛2 − 1 = 𝑓0.95 ,4 ,9 = 0.275
Fail to reject the null hypothesis since test statistic 𝐹0 = 0.8056 is greater than 𝑓0.95 ,4 ,9 =
0.275. There is no significant evidence to support that variance 1 is less than variance 2.
If the null hypothesis falls outside of the confidence interval, the null hypothesis will be
rejected. If the null hypothesis falls inside the bounds of the confidence interval, fail to rejct
the null hypothesis.