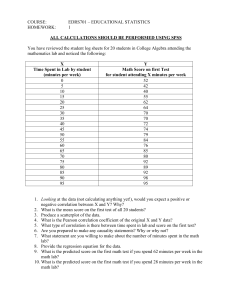
Lecture 4 ANOVA Correlation Covariance Niza Talukder ANOVA – Analysis of Variance • The statistical methodology for comparing several means is called analysis of variance, or ANOVA. • Analysis of Variance (ANOVA) is a hypothesis-testing technique used to test the equality of two or more population (or treatment) means by examining the variances of samples that are taken. • ANOVA is based on comparing the variance (or variation) between the data samples to variation within each particular sample. If the between variation is much larger than the within variation, the means of different samples will not be equal. If the between and within variations are approximately the same size, then there will be no significant difference between sample means. • Suppose we want to test the effect of five different exercises. For this, we recruit 20 men and assign one type of exercise to 4 men (5 groups). Their weights are recorded after a few weeks. We may find out whether the effect of these exercises on them is significantly different or not and this may be done by comparing the weights of the 5 groups of 4 men each. We will consider two ANOVA techniques: • One-way ANOVA: is used when there is only one independent variable or one way to classify the populations of interest, e.g. to compare cure time for three different treatments. When an independent variable is studied by having each subject only exposed to one condition, it is a between-subjects factor, and we will use a between-subjects ANOVA Assumptions of ANOVA: (i) All populations involved follow a normal distribution. (ii) All populations have the same variance (or standard deviation). (iii) The samples are randomly selected and independent of one another. • Since ANOVA assumes the populations involved follow a normal distribution, ANOVA falls into a category of hypothesis tests known as parametric tests. If the populations involved did not follow a normal distribution, an ANOVA test could not be used to examine the equality of the sample means. Instead, one would have to use a non-parametric test (or distribution-free test), which is a more general form of hypothesis testing that does not rely on distributional assumptions. • The example in the next slide is one way ANOVA test. Situation: I gave three different types of food to people taking a certain test. The observations are the test scores. I want to find out if the type of food is really affecting the scores . Is the difference really random? Or does the food type really affect the performance? - Food 1 3 2 1 Food 2 5 3 4 Food 3 5 6 7 Are the means and true population mean same? Sample mean is based on three samples. Question: If the mean of population of people taking food 1 equal to the mean of food 2. = food doesn’t make a difference ; = = = Food makes a difference If they aren’t equal then food does have some impact on how people perform on test Calculating SST- Total sum of squares • A mathematical approach to determine the dispersion of data points • Find function that best fits from the data • It has two components: SSW and SSB • Suppose you have the following three groups of data with ‘n’ observations • 1 3 2 1 2 5 3 4 3 5 6 7 First find the mean of the data SST= 30 (workout shown in class) Degrees of freedom : m×n – 1 (where n is the number of observations in each group) Then find out how much of the variation in SST comes from variation within each of these groups versus variation between the groups. Calculation SSW and SSB • Sum of Squares Within (SSW) : how much variation between each data point and their respective mean. Degrees of freedom: m (n-1) Ans = 6 Our total variation was 30. So, 6 out of 30 comes from variation within these samples • Sum of Square Between (SSB): how much variation between these samples. Degrees of freedom : m - 1 First for each group, you need to find the variation between each data point to its mean and add them up Ans = 24 SST = SSW + SSB ( for this example, we worked out manually. But for the example on slide 19, we used the following formulas) The formula for SST: ∑ or ∑ SSB = ∑ - How to test the hypothesis? Figure out what are the chances of finding a statistic this extreme? We shall come up with the F stat ANOVA uses a new (to us) distribution, and an associated new test statistic: – The F distribution – The F statistic As usual, we’ll compute F stat from the data, and compare this with F critical value , to see whether or not to reject the null hypothesis F= = 12 Reject null if F stat is less than the critical value. • The F test is used to compare two or more means. • It is used to test the hypothesis that there is (in the population from which we have drawn our 2 or more samples) (a) no difference between the two or more means • Or equivalently (b) no relationship between membership in any particular group and score on the response variable. • 3 groups of 5 subjects given 15 math questions each • Group 1 told the questions would be easy, group 2 told they would be of medium difficulty, and group 3 told they would be difficult • Factor: perceived difficulty Level 1 (easy) Level 2 (medium) Level 3 (difficult) 9 4 1 12 6 3 4 8 4 8 2 5 7 10 2 Results, and reporting them • So, it seems that there is a significant effect on math scores of how easy people have been told the problems will be. We are confident that there’s a real effect in the population, but we don’t know whether each increase in perceived difficulty produces a significant drop in performance. – Perhaps there’s only a difference between “easy” and “difficult”. – A significant F just means that at least one of our differences is significant. Covariance and Correlation Revision: Note: Dependent and Independent variable Independent variable: As the name suggests, it is a variable that stands on its own. It is not changed by another variable that you are trying to measure. For graphical illustration, it is always on the x axis Dependent variable: a variable that is changed or influenced by another factor. It is always represented in the y axis. For example: Income and Consumption are two variables. As your income increases, you tend to consume more. In this situation, your dependent variable is consumption as it is determined by how much you earn. Income stands on its own. You cannot say that the more you consume, the more you earn. Income is your independent variable. Figure 1 : Shows a positive linear relationship between economic growth and stock market returns. An increase in economic growth will lead to a corresponding increase in the stock market returns Figure 2: Negative relationship between gas production and gas prices. As the production increase/supply increases, there will be a fall in prices. Covariance - Indicates how two random variables are related to one another. Eg. Is there a linear increase in one associated with a linear increase in another? Are they moving together or in the opposite direction? Variables are positively related if they move in the same direction. Variables are inversely related if they move in opposite directions. This relationship is called covariance and denoted by = Cov (x,y) = Cov(X,Y) = E [ (X- ] Expectation is simply the long run average value. x = the independent variable y = the dependent variable n = number of data points in the sample = the mean of the independent variable x = the mean of the dependent variable y Exercise: The table below shows the rate of economic growth and the returns on S&P 500 (stock market index) Economic growth % () S & P 500 Returns % () 2.1 2.1 2.5 2.5 88 12 12 4.0 4.0 3.6 3.6 14 14 10 10 Using the covariance formula, you can determine whether economic growth and S&P 500 returns have a positive or negative relationship. Before you compute the covariance, calculate the mean of x and y. • However, the covariance is of little use in regression because it cannot assess he strength of a relationship. • It can only say if the relation between two random variables is positive or negative. Its values depends on units in which they are measured. • Ideally, we would like a pure, scale free measure. This can easily obtained by dividing covariance by product of individual standard deviations. The quantity resulting is the correlation coefficient. Correlation Correlation refers to the statistical relationship between two or more random variables. In addition to measuring if variables are positively or negatively related, correlation also indicates the degree to which variables tend to move together/ indicates the strength of the relationship between two variables. For example, you might want to find out if sugar consumption is causing heart disease. If you find a positive relation between these two variables, you might want to find out whether the extent to which sugar consumption increases heart disease is strong or weak. The measurement of correlation is called the correlation coefficient. It will always take a value between 1 and -1 = • When the correlation coefficient is 1 the variables have a perfect positive correlation. This means that if one variable moves a given amount, the second moves proportionally in the same direction. Strength of correlation increases as the correlation coefficient approaches one. • When correlation coefficient is zero, no relationship exists between the variables. If one variable moves, you can make no predictions about the movement of the other variable; they are uncorrelated. • If correlation coefficient is –1, the variables are perfectly negatively correlated (or inversely correlated) and move opposite to each other. If one variable increases, the other variable decreases proportionally. A negative correlation coefficient greater than –1 indicates a less than perfect negative correlation, with the strength of the correlation growing as the number approaches –1. • (note: in a linear relationship, a given change in the independent variable will lead to a corresponding change in the dependent variable) • Calculate the correlation coefficient using the previous data. You need to find the standard deviation for x and y. Scatter plot and correlation: A scatter plot can illustrate if two variables are correlated. Which graph shows a positive relationship between job performance and test performance? Given the following return information, what is the covariance between the return of Stock A and the return of the market index? Using the sample covariance formula, = 0.314 The answer is positive meaning that there is a positive relationship between market index and return of stock A. Both moves in the same direction. Practice finding the correlation from here. Answer would be, = 0.76