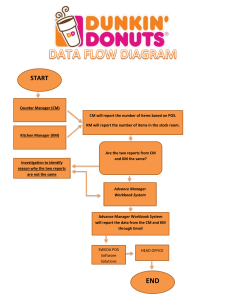
Student name: Gopal Prabath Chelikani UTA ID: 1002024881 A Pattern and POS Auto-Learning Method for Terminology Extraction from Scientific Text https://www.sciencedirect.com/science/article/pii/S2543925122000031 A lot of research papers were published day to day, it’s impossible to quickly find new words and meaning from documents, most of work are based on data, quite difficult to deal with unlabelled data. By utilizing methods based on part of speech and few initial learnable patters to obtain initial terminology tokens an pos sequences. Learnable patterns were used to obtain terminology token and pos sequences. Patterns were constructed more sentence to find pos sequence of terminology. It’s difficult for researchers to discover something by reading papers. Automatic indexing knowledge management, way of new technologies relies based on entity recognition. Results on training and testing data ,learning models with training data, scientific texts has extraction for labels.. pattern and pos autolearning method has proposed to overcome to extract sentences and terminologies. pos sequences in sentences if matched utilize particular words. Terminologies on scientific sentences is extracted. Pattern and pos auto learning method for extraction of terminology from unlabelled data in different fields. Incomparision with supervised method, unsupervised can do more extraction of terminology entities without annotations. Unsupervised method on pos sequence and sentence patterns to extract scientific text from entities. Terminologies were extracted from unlabelled scientific texts, surrounding words and pos sequence of terminologies were considered. Sentence pattern for extract target from sentence string is regular expression. Input data were taken and tools were used to get pos sequence of sentences. It is designed regular expression, terminology string from matched groups, suitable terminology tokens and pos sequence are received as output. Pos sequence is considered as extracted terminology pos sequence. New found patterns were used but not matched sentences. Sentence will move to unextracted sentence base.to generate new pattern candidate word this chosen from sentence. New patterns are generated for results and patterns to pattern base. Initial terminology for extraction loop. Terminology word is obtained is matched with patterns it must be clean-up for suitable pos sequence. Discard some token which has little valid information.pos sequence for token index are continuous, to evaluate quality and discard one. New generated sequence patterns were used as key. It generates certain sentences for percentage. If number of matched is larger than threshold. Sentence patterns and pos sequence of unlabelled data for new terminologies. Sentences for new technologies when string is input. We can pos sequence to match pos sequence for more accurate result. For the performance scientific abstracts from web were crawled, these abstracts were from different domains such as machine learning, big data. As for pre-processing NLTK split into sentences and into tokens. StanfordNLP to get pos tags and relations of cut sequences. Data consist of abstracts, tokenized sentences, pos tags and dependency relations. Tokenized sentences of abstract and pos tags. we use 54k+ sentences and their POS sequences as training data without labels and 500 sentences and their POS sequences as test data with labels. A labelled sentence consists of a token sequence and a label sequence. When the token is a terminology word, the corresponding label is 1. Otherwise, the label is 0. Manually annotate the 500 sentences in the test set to ensure the accuracy of the annotation. Precision and f1 score for metrics for comparison method with two rule based methods on dataset. For unsupervised learning methods, extraction results were full of noisy terms. Hard standard evaluation is done it is difficult to compare these unsupervised methods. If extraction result has overlap with real terminology, extracted is considered as valid result. If number of word in extracted term and term in terminology at sentence at same time exceeds product between number of words in terminology term and cover percentage comes to conclusion that extracted term is correct. For rule 1based method continuous nouns as terminology terms, and 2 choosed to filter noun and non-verb and use left word with continuous indexes in sequence. Each case has several words and forms list of words terminology is displayed in blue in each sentence. The word is extracted using the methodology and data present in the data sets were cleansed and finally the terminologies were displayed in blue color. It has good performance on method words, performance is lower when comes to professional technologies. Conclusion:For extracting terminologies from the list of scientific words, cold start method on sentence pattern and pos sequence is proposed so that this method will extract terminologies without learning on data that is labelled and senentece patterns were used to initial cold start. It has new patterns and unlabelled data on POS sequences. These patterns and pos sequences for new terminology extraction from new scientific sentences. Paper abstract sentences from knowledge of web shows that this method has good recall, precision and f1 scores on test data. This approach is for unlabelled data extraction.