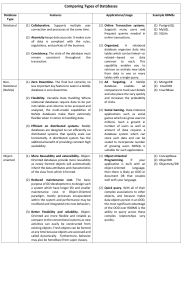
Performance Analysis of Financial Institution Operations in a NoSQL Columnar Database Felipe de Moura Rezende dos Santos Maristela Holanda University of Brasilia - UnB, Brasilia, Federal District - Brazil feliperezende86@gmail.com Abstract — The advent of Big Data has brought the need to analyse large volumes of data. The Hadoop ecosystem has been used to store and process this Big Data. Hadoop is composed of different frameworks, such as: HBase, a NoSQL column storage structure database; Hive framework to develop the data warehouse in distributed storage with SQL, used in Business Intelligence; Sqoop, to transfer data between Apache Hadoop and relational database structures; and others. The objective of this paper is to analyse the use of the Hadoop Ecosystem in a financial system to reduce the processing time that its transactions require. Results show that the Hadoop ecosystem improves the processing time in that financial database. Keywords - Big Data, HBase, Hadoop, NoSQL Columnar, Hive. I. INTRODUCTION An accounting system contains the records of the financial and economic events of the organization. It has the purpose of organizing and summarizing information that can be consulted at any time, besides the economic profile of a certain period [1]. Management accounting is a process of identifying, measuring, analysing and communicating financial information used by management to plan and control a company to ensure the appropriate use of its resources. In addition, to aid in the decision making of the company, managerial accounting serves as the basis for the control [2]. Management accounting provides necessary information for the management and development of a company. The handling of large amounts of data called Big Data is increasingly a relevant issue to consider. The efficiency of storage tools for the processing or mining of such data [3] has been the subject of much research. One of these tools is NoSQL, in structured column [4] [5] [6] [7] version, performs well for data warehousing in visualizing the results in various levels of granularity and dimensions. The columnar database performs a vertical positioning of the table and stores each column separately, presenting an additional benefit: better compaction based on type [8]. The general objective of this work is to generate management accounting reports for the financial institution Beta, using a NoSQL columnar database with frequency greater than the current one. Furthermore, a modelling in a NoSQL University of Brasilia - UnB, Brasilia, Federal District - Brazil .....................mholanda@unb.br Columnar is proposed, for storage of the values of the managerial results of the Financial Institution Beta. Finally, the performance of the process of calculation of managerial results is analysed. This paper is divided as follows: background in Section II; related works are presented in Section III; Section IV describes the implementation of the problem solution proposal; the results obtained are described in Section V; Section VI contains the conclusion and future work. II. BACKGROUND A. Not only SQL (NoSQL) Database Big data is a combination of structured, semi-structured and/or unstructured data on a large scale [9]. NoSQL does not replace relational databases, instead, these databases complement each other. In several studies, as in [10] [11] [7], one of the main characteristics of Big Data is the presence of the 4 Vs. They consist of Volume, Veracity, Velocity and Variety. Present in [12] and [13] a fifth dimension, in the case of Big Data analysis: Value. Data analysis without generating value does not offer a contribution to the organization. Ma-Lin Song et al. [14] put the 4 Vs (Volume, Veracity, Velocity, and Variety) as Big Data characteristics, but adds Valorization describing how 5 Vs add significantly to the complexity of solving relevant problems. Nayak et al. [15] describe how NoSQL can be categorized into 4 types: • Document Store Database: Document databases use a document-oriented model to store data. They store a record and its associated data in a single structure called a document. Each document contains several associated attributes and values [16]. Documents can be retrieved based on attribute values using various application programming interfaces (APIs) or query languages provided by the DBMS (Database Management System). • Graph Database: Graph databases are database management systems that have been optimized to store, query, and update structures in graphs. Graphs consist 2020 15th Iberian Conference on Information Systems and Technologies (CISTI) 24 – 27 June 2020, Seville, Spain ISBN: 978-989-54659-0-3 Authorized licensed use limited to: Universidad Nacional Autonoma De Mexico (UNAM). Downloaded on May 20,2022 at 19:56:06 UTC from IEEE Xplore. Restrictions apply. to reduce the I/O of the system; and, processing is simultaneous i.e. each column is processed by a process; of nodes and edges, where nodes act as objects and edges act as relationships between objects [17]. • Key-value Store Database: The databases belonging to this group are essentially distributed hash tables that provide at least two operations: get (key) and put (key, value). A key-value database maps data items to a key space that is used to allocate key/value pairs to computers and efficiently locate a value considering its key. These databases are designed to scale to terabytes or even petabytes, plus millions of concurrent operations adding computers horizontally. • Wide Column Store Database: Advances in information technology have led to an increasing amount of available data, creating demand for their analysis using algorithms from a variety of methodologies, e.g. statistics, clustering and forecasting. Such analysis is typically performed in the database system as it provides optimized execution and efficient scheduling of the data volume used [18]. • the databases have the same data type, similar characteristics and good compression ratio. B. HBase Similar to HDFS and MapReduce [21], HBase also adopts master-slave architecture - HMaster (master) is responsible for assigning regions to HRegionServers (slaves). An HRegionServer is responsible for managing customer requests for reading and writing. HBase uses Zookeeper, to manage the HBase cluster. SQL query language is not supported in HBase. However, there is a Hive/HBase integration project that allows SQL statements written in Hive to access HBase tables. There is also the HBql project that adds a dialect of SQL and JDBC connections to HBase. Big Data has become very important in many organizations, whether public or private [19]. However, unusual data volumes become a problem when faced with the limited capabilities of traditional systems, especially when data storage is in a distributed environment that requires the use of parallel processing, as the MapReduce paradigm. HBase, an Apache open source project, is a fault-tolerant, high-scalable, column-driven distributed system, NoSQL database built under the HDFS. It is used for readings and random-access writes on very large databases [21]. All access to the data is done through the primary key and any checking of the results of the HBase table in a MapReduce job. Parallel verification in terms of work shows that MapReduce's query response time is faster and has better overall performance. Wide Column, Family Column, or Columnar databases store data by columns and do not impose a rigid schema on user data. This means that some rows may or may not have columns of a certain type. The columnar database has a graphical representation similar to the relational database. The main difference between them is with respect to null values. Considering a use case with different attribute types, a relational database should store each null value in its respective column. Conversely, a columnar database saves only the key-value of the field if it is really needed [20]. C. Sqoop Sqoop is a method of loading data in HBase, also present in the Hadoop Ecosystem [22]. Sqoop was efficiently designed for the purpose of large-volume data transfer between Apache Hadoop and relational database structures [23]. It quickly copies external systems, including enterprise data warehousing to Hadoop. It ensures fast performance by parallelizing data transfer and using the ideal system. Sqoop supports data analysis efficiently. In addition, it even mitigates excessive loads for external systems. The row key is used to identify the column values belonging to the same tuple. The column name allows to identify the attribute of a value, it can be composed of the column family name and the column name. In fact, the column can be complex or simple. If the column name is prefixed, this means that the column name consists of the column family name (prefix) and the name of the nested column. In this case, it is called a composite attribute (it belongs to a family of columns), otherwise it is considered a simple attribute. Finally, the timestamp allows the coherence of the data to be checked. Each value receives a system time and date record for the data consistency proposition. Column-oriented databases use tables as a data model, but do not support table association. Column-oriented databases have the following characteristics [16]: • the data is stored per column, i.e. the data is stored separately for each column; • each data column is the index of the database; only the columns involving the result of the queries are accessed III. RELATED WORK Ameya Nayak et al. [15] mentions a problem with the relational data model of scalability and that its performance is degraded rapidly as data volumes increase. From 2000 some studies [24] [25] [26] demonstrate the change of these databases to a new structure, with a differential for Big Data processing. This new structure, known as NoSQL (Not Only SQL), has a horizontal scalability. This means that to add capacity, a database administrator can simply add more merchandise servers or cloud instances. The database automatically spreads the data through the servers as needed [27]. Finally, it completes content and organizational editing before formatting. Big Data is a powerful and demanding popular technology nowadays. Big Data represents rapidly growing data with variety, generation speed, and volume of information that is not used by existing analytical applications and data warehouse systems [28]. 2020 15th Iberian Conference on Information Systems and Technologies (CISTI) 24 – 27 June 2020, Seville, Spain ISBN: 978-989-54659-0-3 Authorized licensed use limited to: Universidad Nacional Autonoma De Mexico (UNAM). Downloaded on May 20,2022 at 19:56:06 UTC from IEEE Xplore. Restrictions apply. Figure 1. Proposed macro data load process in NoSQL. Rashid Zafar et al. in [29], compare two database management structures, describing existing models in NoSQL, as well as examples of DBMS. As a conclusion, they give an example of a gain for Netflix with the migration of the Oracle system to Cassandra. After the conversion, the company had a writing capacity of more than ten thousand lines per second in its database. NoSQL systems are basically used for applications requiring high-performance data reliability and run on multiple nodes connected to a cluster. A comparison between the two DBMSs is found in [30] which demonstrates a comparison involving four fundamental principles of a database: Instance, Reading, Writing and Deletion. While the NoSQL DBMS generally had optimized results, SQL DBMS did not have the same result. However, it is noted that not all the NoSQL had the same result. Therefore, one must select the correct type of NoSQL to optimize/improve storage and information processing. IV. PROJECT IMPLEMENTATION One of the major problems encountered in the current way in which the Financial Institution's management results are processed, in addition to the processing time, is the need to wait for the end of the reference month to have the value of the financial institution's realized results of operations. The main advantage of changing to a system that supports fast processing of large data is the ability to perform processing of this information on a daily basis. It allows the previous result values to be stored with a one-day lag - no waiting for the month to close. As found in the literature, for example in [6] and [31], one of the best options for processing large-data management results calculations is the storage in the NoSQL Columnar Database. Given that the Beta Financial Institution has a contract with Apache and thus has available for use the Hadoop Distributed File System - HDFS, using the Hadoop ecosystem and the columnar NoSQL HBase, these are precisely the structures that are used in the work. The proposed solution to the problem raised in Section I is the implementation of data storage with the necessary values for the calculation of the management results in columnar NoSQL, followed by the processing of this data and the calculation of the management results, with the storage of these results obtained in the environment Big Data. Each day each system generates approximately 800 MB of data. As there are 26 systems, approximately 20.8 GB of data have to be processed and stored daily for this project. For this work, all operations of all systems of the financial institution Beta were used (per policy of the financial institution, the names of the systems cannot be described in academic works, external to the institution). The data is stored in three distinct tables, each with a distinct group of information, but to meet the same attributes as in today's process, only the specific attributes of each table were captured. That is, thirteen attributes from the first table, twentyseven attributes from the second table and twenty-eight attributes from the last table. Figure 1 demonstrates the proposed processing as a new format for performing the managerial calculation of the institution's operations. The search for information in the Database of Operations and External Sources would continue in the same way, with the difference that there would be no prior calculation of these values of management results. Instead, the data would be entered into the database in columnar NoSQL environment for information processing. All operations go through the process of grouping information, as they have components generated for the same operation in both databases. The calculation of management results is performed in the Big Data environment using Pig Script and Python calculation 2020 15th Iberian Conference on Information Systems and Technologies (CISTI) 24 – 27 June 2020, Seville, Spain ISBN: 978-989-54659-0-3 Authorized licensed use limited to: Universidad Nacional Autonoma De Mexico (UNAM). Downloaded on May 20,2022 at 19:56:06 UTC from IEEE Xplore. Restrictions apply. methodologies, the results are stored in Hive for result disclosure in specific panels. One of the differences in this new processing is the absence of management result calculations in three distinct phases, as in the previous process. In this new process, the raw data are loaded in Hadoop environment and stored in HBase. After that the calculations of the managerial result of the operations are processed, still in Big Data environment. And the results are stored in a Data Warehouse so that they can be evidenced in bulletin boards. Figure 2. Proposed solution to the problem. Figure 2 presents the abstract architecture for the proposal. The proposal is divided into three main modules: • Data transfer: To perform information processing in the Big Data environment, data loading in the Hadoop environment is required. This process, called Sqoop, is performed by the structure and is already described above. A Shell Script file was created for each processing [32]. An incremental Sqoop process is performed daily where all operations that have changed in their driving state are updated (if the operation was liquidated, no longer in normal condition or was contracted on this day). An update of balances for calculating management results is performed daily, overwriting the existing values. • Processing: With data stored in a Hadoop environment, you can process management result calculations. For this procedure, there is the Pig Latin structure already described in this work and a file was created that should be executed daily after performing the Sqoop processes with increment of updated values. Some calculation methodologies cannot be executed in Pig Latin, so two Python [32] programs were created for these executions. • Storage: After all processing of the information described in the previous item, the management result data of the financial institution's credit operations should be stored in a Hive environment, excellent for Data Warehouse processes, as described in several studies already referenced in this paper. V. RESULTS During the month of July 2019, the processes for capturing data from the relational database, necessary for the management calculation. These data were also processed by Hadoop-HBase using Pig, and finally the managerial results were loaded into a Hive database. The processes were executed at different times of the day to verify the processing characteristics of the Hadoop ecosystem configured in the institution. The execution times were chosen at random so that it could be analyzed if there would be a change in performance according to the time of day. The first tests carried out were related to the data transfer process. For these tests, a shell script was created. This script describes the three Sqoop processes for sending data from the relational environment to Hadoop - HBase. The first two processes concern the operational information tables. An update of the operations is carried out only when the driving status was changed on the previous business day, since the driving status identifies the operations that are still in force at the institution. The third process, referring to the balance table, performed the daily insertion of the data available in a relational database, overwriting the values previously stored in HBase. It required a total time of 1 hour 53 minutes and 46 seconds for the full loading of the three relational databases for HBase using Sqoop. As shown in Figure 2, after carrying out the data transfers, and storing them in HBase, the command for processing the management result is passed, using Apache Pig. To calculate the total processing time of the managerial result values, the difference is calculated between the moment the process ends and the moment it starts. This process in Pig Latin performs the reading of the data stored in HBase, processes the data with some methodologies applied in Python to determine managerial results and loads the values in the Hive database. For the purpose of final performance analysis, we used the median time, and for this process, the value was 34 minutes and 13 seconds. All the processes were executed with manual commands, not being scheduled to run during quieter periods of the available servers. Figure 3 demonstrates the time result for processing the daily information. This is an average of the days processed. The time required to perform all processing and loading of the new data was 16 minutes. As a finalization of the process, a loading of the data obtained in Hive is carried out to be used as a data warehouse for a better disclosure of the values obtained. The average total operations with the results was 35.5 million. 2020 15th Iberian Conference on Information Systems and Technologies (CISTI) 24 – 27 June 2020, Seville, Spain ISBN: 978-989-54659-0-3 Authorized licensed use limited to: Universidad Nacional Autonoma De Mexico (UNAM). Downloaded on May 20,2022 at 19:56:06 UTC from IEEE Xplore. Restrictions apply. [5] [6] [7] [8] [9] Figure 3. Processing Result. VI. CONCLUSION AND FUTURE WORKS We can conclude from this study that the processing this massive data of managerial information of the operations of the financial institution represents a great improvement in the time necessary for final disclosure. This study is still in the initial stage, it does not contain the generation of all components of managerial results which are required for it to be used as generator of the tracking numbers of the operations of the financial institution. But it shows that it would be possible to continue with the insertion of these remaining values in order to have a better monitoring of managerial results. [10] [11] [12] [13] [14] [15] [16] [17] [18] Figure 4. Processing Result. [19] As future work, it would be possible to incorporate all of the necessary components for the managerial results of operations of the financial institution. In addition, new processes could be developed for the creation of specific results required by the group of analysts who will follow the presented values. [20] REFERENCES [23] [1] [2] [3] [4] Salazar, José Nicolás Albuja, and Gideon Carvalho de Benedicto. Contabilidade financeira. Cengage Learning Editores, 2004. Nikolay, Rafael, and Luiz Fernando Costa Neves. "Contabilidade gerencial como base à controladoria." Revista Eletrônica do Curso de Ciências Contábeis 5.9 (2016): 55-80. Zhang, J., Yao, X., Han, G., & Gui, Y. (2015, October). A survey of recent technologies and challenges in big data utilizations. In 2015 International Conference on Information and Communication Technology Convergence (ICTC) (pp. 497-499). IEEE. Han, J., Haihong, E., Le, G., & Du, J. (2011, October). Survey on NoSQL database. In 2011 6th international conference on pervasive computing and applications (pp. 363-366). IEEE.. [21] [22] [24] [25] [26] [27] Dehdouh, Khaled, Omar Boussaid, and Fadila Bentayeb. "Columnar NoSQL star schema benchmark." International Conference on Model and Data Engineering. Springer, Cham, 2014. Su, F., Wang, Z., Yang, S., Li, K., Lu, X., Wu, Y., & Peng, Y. (2017, April). A survey on big data analytics technologies. In International Conference on 5G for Future Wireless Networks (pp. 359-370). Springer, Cham. Siddiqa, Aisha, Ahmad Karim, and Abdullah Gani. "Big data storage technologies: a survey." Frontiers of Information Technology & Electronic Engineering 18.8 (2017): 1040-1070. Sridhar, K. T. "Modern column stores for big data processing." International Conference on Big Data Analytics. Springer, Cham, 2017. Bathla, Gourav, Rinkle Rani, and Himanshu Aggarwal. "Comparative study of NoSQL databases for big data storage." International Journal of Engineering & Technology 7.26 (2018): 83. Dehdouh, Khaled. "Building OLAP cubes from columnar NoSQL data warehouses." International Conference on Model and Data Engineering. Springer, Cham, 2016. Oussous, Ahmed, et al. "Big Data technologies: A survey." Journal of King Saud University-Computer and Information Sciences 30.4 (2018): 431-448. Chiang, Roger HL, et al. "Strategic value of big data and business analytics." (2018): 383-387. Grover, V., Chiang, R. H., Liang, T. P., & Zhang, D. (2018). Creating strategic business value from big data analytics: A research framework. Journal of Management Information Systems, 35(2), 388-423. Song, Ma-Lin, et al. "Environmental performance evaluation with big data: Theories and methods." Annals of Operations Research 270.1-2 (2018): 459-472. Nayak, Ameya, Anil Poriya, and Dikshay Poojary. "Type of NoSQL databases and its comparison with relational databases." International Journal of Applied Information Systems 5.4 (2013): 16-19. Gessert, Felix, et al. "NoSQL database systems: a survey and decision guidance." Computer Science-Research and Development 32.3-4 (2017): 353-365. Amghar, Souad, Safae Cherdal, and Salma Mouline. "Which NoSQL database for IoT Applications?." 2018 International Conference on Selected Topics in Mobile and Wireless Networking (MoWNeT). IEEE, 2018. Mattis, T., Henning, J., Rein, P., Hirschfeld, R., & Appeltauer, M. (2015, October). Columnar objects: Improving the performance of analytical applications. In 2015 ACM International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software (Onward!) (pp. 197-210). Dehdouh, Khaled. "Building OLAP cubes from columnar NoSQL data warehouses." International Conference on Model and Data Engineering. Springer, Cham, 2016. Hecht, Robin, and Stefan Jablonski. "NoSQL evaluation: A use case oriented survey." 2011 International Conference on Cloud and Service Computing. IEEE, 2011. Vora, Mehul Nalin. "Hadoop-HBase for large-scale data." Proceedings of 2011 International Conference on Computer Science and Network Technology. Vol. 1. IEEE, 2011. Vohra, Deepak. "Using apache sqoop." Pro Docker. Apress, Berkeley, CA, 2016. 151-183. Aravinth, S. S., Begam, A. H., Shanmugapriyaa, S., Sowmya, S., & Arun, E. (2015). An efficient HADOOP frameworks SQOOP and ambari for big data processing. International Journal for Innovative Research in Science and Technology, 1(10), 252-255. Sareen, Pankaj, and Parveen Kumar. "Nosql database and its comparison with sql database." International Journal of Computer Science & Communication Networks 5.5 (2015): 293-298. Dai, Jiao. "SQL to NoSQL: What to do and How." IOP Conference Series: Earth and Environmental Science. Vol. 234. No. 1. IOP Publishing, 2019. Silva, Yasin N., Isadora Almeida, and Michell Queiroz. "SQL: From traditional databases to big data." Proceedings of the 47th ACM Technical Symposium on Computing Science Education. 2016. Sareen, Pankaj, and Parveen Kumar. "Nosql database and its comparison with sql database." International Journal of Computer Science & Communication Networks 5.5 (2015): 293-298. 2020 15th Iberian Conference on Information Systems and Technologies (CISTI) 24 – 27 June 2020, Seville, Spain ISBN: 978-989-54659-0-3 Authorized licensed use limited to: Universidad Nacional Autonoma De Mexico (UNAM). Downloaded on May 20,2022 at 19:56:06 UTC from IEEE Xplore. Restrictions apply. [28] Solanke, Ganesh B., and K. Rajeswari. "SQL to NoSQL transformation system using data adapter and analytics." 2017 IEEE International Conference on Technological Innovations in Communication, Control and Automation (TICCA). IEEE, 2017. [29] Zafar, R., Yafi, E., Zuhairi, M. F., & Dao, H. (2016, May). Big data: the NoSQL and RDBMS review. In 2016 International Conference on Information and Communication Technology (ICICTM) (pp. 120-126). IEEE. [30] Li, Yishan, and Sathiamoorthy Manoharan. "A performance comparison of SQL and NoSQL databases." 2013 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing (PACRIM). IEEE, 2013. [31] Sridhar, K. T. "Modern column stores for big data processing." International Conference on Big Data Analytics. Springer, Cham, 2017. [32] https://github.com/feliperezende86/PPCA.git 2020 15th Iberian Conference on Information Systems and Technologies (CISTI) 24 – 27 June 2020, Seville, Spain ISBN: 978-989-54659-0-3 Authorized licensed use limited to: Universidad Nacional Autonoma De Mexico (UNAM). Downloaded on May 20,2022 at 19:56:06 UTC from IEEE Xplore. Restrictions apply.