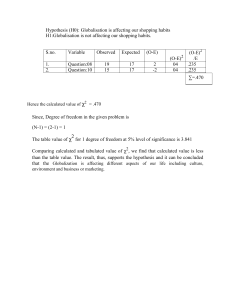
Chi Square Analysis Basics A Chi square analysis is one that is used so that we could determine if counts are true to is to compare observed values with expected values and do a type of statistical test known as a “goodness of fit” test. This type of statistical test allows us to determine if any differences between our observed measurements and our expected are simply due to chance or some other reason. Steps: 1. 2. State the null hypothesis. a. A null hypothesis is the prediction that: i. something is not present, ii. that a treatment will have no effect, or iii. that there is no difference between treatment and control. b. Another way of saying this is the hypothesis that an observed pattern of data and an expected pattern are effectively the same, differing only by chance, not because they are truly different. i. The null hypothesis state there is no difference between what we expect and what we observe. Calculate the X2 statistic, which is calculated in the following way: X2 = Σ(sum of) (O-E)2 E 1. 2. Where O is the observed (actual count) and E is the expected number (if no effect) Can find this by multiplying the total observed by expected frequencies The main thing to note about this formula is that, when all else is equal, the value of X2 increases as the difference between the observed and expected values increase. Use this data table to help organize your data. You can add or take away rows based on the categories (treatments/experimental and control groups) you have Category Observed (O) Expected (E) O-E (O-E)2 (O-E)2 E 1 (positive control group) 2 (negative control group) 3 (experimental group 1) 4 (experimental group 2) Totals 3. Find your degrees of freedom a. For this statistical test the degrees of freedom equal the number of categories minus one: degrees of freedom = number of categories –1 4. Determine the probability that the difference between the observed and expected values occurred simply by chance. a. Scan down the column to your degrees of freedom the row corresponding to the p-value requested (almost always 0.05 for standard biology) i. Note that the chi-square increases as the probability decreases. ii. If your X2 = 3.36 with 4 degrees of freedom, there is a 50% chance that your results were due to chance BUT if X2 = 11.35 with the same degrees of freedom, you have a 1% chance of results coming from chance b. If you were asked to provide the p-value: i. Estimate the probability based on degrees of freedom and closest degree of freedom in chart Example problem: In peas, smooth seeds (R) are dominant over wrinkled (r) seeds. In the P generation, a plant homozygous for smooth seeds is crossed with a plant with wrinkled seeds. The resulting F1 plants are crossed. The seeds of the observed F2 generation were: Smooth = 5474 Wrinkled = 1850 Does the data fit the predicted phenotypic ratio? 1. First fill in the observed and find your total sample size Phenotype Observed (O) Expected (E) Smooth Wrinkled Totals 2. (O-E)2 (O-E)2 E O-E (O-E)2 (O-E)2 E 5474 1850 7324 The totals for O & E should be the same Phenotype Observed (O) Smooth Wrinkled Totals O-E 5474 1850 7324 Expected (E) 7324 3. Now, multiply the Total Expected by the expected frequency of each type. a. For genetics problems, we get the expected from the Punnett Squares. So, you would need to draw a Punnett Square or have their ratios memorized! P gen= RRxrr = 100% Rr (these are the F1) F1 gen = RrxRr = 25%RR:50%Rr:25%rr (these are the F2) or 75% smooth and 25% wrinkled Phenotype Observed (O) Expected (E) (O-E)2 (O-E)2 E O-E (O-E)2 (O-E)2 E O-E (O-E)2 (O-E)2 E O-E Smooth 5474 5493 (0.75x7324) Wrinkled 1850 1831 (0.25x7324) 7324 7324 Totals 4. Now, subtract observed from expected. You can ignore signs since you will square anyway 😊 Phenotype Smooth Wrinkled Totals 5. Now square Phenotype Observed (O) 5474 1850 7324 Expected (E) 5493 1831 7324 Observed (O) 19 19 Expected (E) Smooth 5474 5493 19 361 Wrinkled 1850 1831 19 361 7324 7324 Totals 6. Now divide by expected for that row. You will end with different values here because your denominator is different for each. Phenotype Observed (O) Expected (E) O-E (O-E)2 Smooth Wrinkled Totals 7. Now add Phenotype 5474 1850 7324 Smooth Wrinkled Totals 5474 1850 7324 5. 5493 1831 7324 Observed (O) 19 19 Expected (E) 5493 1831 7324 361 361 0.0657 0.1971 (O-E)2 O-E 19 19 (O-E)2 E 361 361 (O-E)2 E 0.0657 0.1971 0.2628 Find your degrees of freedom and read in the p=0.05 column. Degrees freedom = 2 – 1 = 1 (you had two categories- smooth and wrinkled) We fail to reject our null hypothesis that there is no difference between the expected number of each phenotype and the observed number of each phenotype since our X2 = 0.2628 is less than the critical value of 3.85. If we were to estimate our p-value, we would say that there is somewhere around a 60% chance that observations came from random chance and not the experiment itself.