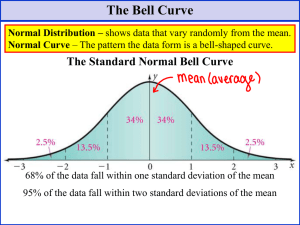
SENIOR HIGH SCHOOL STATISTICS AND PROBABILITY QUARTER 3 Module 3 – Means and Variances Module 4 – The Normal Distribution and Its Properties Name of the Learner: Grade and Section: Teacher: Richard B. Sucgang Contact number: 09106743561_________________________________________ LEARNING COMPETENCIES At the end of the lesson, learners should be able to: • • • • interprets the mean and the variance of a discrete random variable.; solves problems involving mean and variance of probability distributions.; illustrates a normal random variable and its characteristics.; identifies regions under the normal curve corresponding to different standard normal values.; • converts a normal random variable to a standard normal variable and vice versa.; • computes probabilities and percentiles using the standard normal table. LESSON 1: MEANS AND VARIANCES INTRODUCTION/MOTIVATION: Importance of Mean and Variance (and Standard Deviation) / The Chebyshev’s Inequality You may wonder why the mean and standard deviation are by far the two most important summary measures of a distribution (whether a list of data, or for probability distribution, including a probability density function). There is a mathematical result derived by a Russian mathematician named Pafnuty Chebyshev, called Chebyshev’s Inequality, that says that for a distribution, (i) at least three fourths of the distribution is within two standard deviations from the mean; (ii) at least eight ninths of the data are within three standard deviations from the mean. These bounds may be conservative though. MAIN LESSON: PROPERTIES OF MEANS AND VARIANCES In previous lessons, you were shown that adding or subtracting a constant from data shifts the mean but it does not change the variance and standard deviation. This is also the case for random variables. E( X ± c ) = E(X) ± c Var( X ± c ) = Var(X) If a teacher decides to give extra points to everyone in an exam, the average in the exam increases by the number of extra points given by the teacher, but the variability of the new increased scores stays the same. If a company (or the government) decides to double the income of its employees, this would double the average income, and increase it by four times the variability in income. (The latter is the reason why government should be careful of doubling incomes, as this would increase income inequality). Learners may have observed that multiplying or dividing data by a constant changes both the mean and the standard deviation by the same factor. Variance, being the square of standard deviation, would be affected even more, by the square of this constant. This is also the case for random variables. E( aX ) = a E(X) Var( aX ) = a2 Var(X) 1 To make it simple, consider a case of two independent random variables, X and Y. The expected value of the sum of independent random variables X and Y is the sum of the expected values: E(X + Y) = E(X) + E(Y) while the expected value of the difference of X and Y is the difference of the expected values: E(X - Y) = E(X) - E(Y) How about the variance? Explain to learners that if the random variables are independent, then there is a simple Addition Rule for variances (for a sum of random variables): Var( X + Y ) = Var(X) + Var(Y) What about the variances of a difference? Surprisingly, variance also adds up for a difference of random variables: Var( X - Y ) = Var(X) + Var(Y) Variances are added for both the sum and difference of two independent random variables because the variation in each variable contributes to the variation in each case. The variability of the differences increases as much as the variability of sums. To illustrate this notion about sums (or differences of random variables), consider a team of four swimmers that are supposed to perform 4 medley relay events and swimming 100 meters. The swimmers’ performances are independent, having the following means and standard deviations of the times (in seconds) to finish 100 meters What would be the mean and standard deviation would be for the relay team’s total time in the relay. If the team practice’s best time was 201.62 seconds, would it be likely for the team to swim faster than this during actual competition? You should be able to obtain the mean of the team’s total time in the relay as the sum of the means 45.02+50.02 +51.45 +56.38 = 203.1 seconds, with a variance equal to the sum of the variances, i.e. 0.202 + 0.262 + 0.242 + 0.222 = 0.2136, so that the standard deviation is the square root of 0.2136=0.46 seconds. The best time of 201.62 seconds is 3.2 standard deviations below the mean, thus, it would be very likely for the team to swim faster than this best time. The crucial assumption is independence of the random variables. Suppose the amount of money spent by learners for lunch is represented by the random variable X, and the amount of money the same group of learners spends on afternoon snacks is represented by variable Y. The variance of the 2 sum X + Y is not the sum of the variances, since X and Y are not independent random variables. Consider tossing a fair coin 10 times and then ask learners: What would be the number of heads expected? Likely, you will answer 5 derived from10 times one half. If you answered 5, your intuition is correct. Here’s why: Define Xi as 1 if the ith toss comes up heads, and 0 if the ith toss comes up tails, and assuming in general that the coin has a chance p of yielding heads (with p=1/2 when the coin is fair), then tell them that the probability mass function for Xi is For all values of i: i=1, up to 10 (or whatever number of tosses we make). Here the mean of Xi is while the variance of Xi is For tossing a fair coin ten times, the expected value of the number of heads is while the variance here is and thus a standard deviation of approximately 1.58 Using Chebyshev’s Inequality, we know that when tossing a fair coin ten times (and repeating this coin tossing process many, many times), at least three fourths of the time, we would have the number of heads range between 5 heads (the expected value) and, give or take, 3 heads ( 3 = 2 times the standard deviation 1.58 ). In general, when we have a sequence of independent random variables X1, X2, X3, …, Xn, with a common mean m, and a common standard deviation s, then the sum will have an expected value of (n m) and a variance of (n s 2). If we were to toss a fair coin 100 times, then expected value of the number of heads obtained is 100 (1/2)=50 , while the variance is =100 (1/2) (1/2) =25. According to Chebyshev’s Inequality, at least three fourths of the distribution of 3 the number of heads in 100 tosses of a fair coin is within 50 – 2(5) = 40 heads to 50 + 2 (5) = 60 heads. For tossing a coin n times where the probability of getting a head is p, if S is the number of heads, then E(S) = n (p) while Var (S) = n (p) (1-p). REMINDER! Variances of independent random variables are the ones that add up (not the standard deviations: variances have squared units, so the intuition here is the underlying use of the Pythagorean theorem: the square of the hypotenuse is the sum of squares of the legs). In addition, remind them that variances of independent random variables add even when we are considering differences between them. ASSESSMENT 1. A grade 12 student uses the Internet to get information on temperatures in the city where he intends to go for college. He finds information in degrees Fahrenheit. Determine the summary statistics equivalents in Celsius scale given °C =(°F-32) (5/9) 4 LESSON 2: THE NORMAL DISTRIBUTION AND ITS PROPERTIES Many continuous random variables, such as IQ scores, heights of people, or weights of M&Ms, have histograms that have bell-shaped distributions. the most important distribution in statistical science is a normal distribution, which has a "bell-shaped" curve. Explain that there are many reasons why the normal distribution is considered the most important curve in statistics. (a) Many random variables are either normally distributed or, at least, approximately normally distributed. Heights, weights, examination scores, the log of the length of life of some equipment are among a few random variables that are approximately normally distributed. Although the distributions are only approximately normal, the approximation is usually quite close. (b) It is easy for mathematical statisticians to work with the normal curve. A number of hypothesis tests and the regression model are based on the assumption that the underlying data have normal distributions. (Extra note: There are, however, other kinds of continuous distributions that are used in practice. For instance, the distribution that has been found convenient for modeling the length of life of an equipment is the Weibull distribution.) Stress that the normal distribution is a continuous distribution just like the uniform and triangular distribution. However, the left and right tails of the normal distribution extend indefinitely but come infinitely close to the x-axis. This is a picture of the normal (bell-shaped) curve The graph of the normal distribution depends on two factors: the mean m and the standard deviation σ. In fact, the mean and standard deviation characterize the whole distribution. That is, we can get areas under the normal curve given information about the mean and standard deviation. The mean determines the location of the center of the bell-shaped curve. Thus, a change in the value of the mean shifts the graph of the normal curve to the right or to the left. For symmetric distributions with a single peak, such as the normal curve, assist learners to remember that in this case: Mean = Median = Mode. The standard deviation determines the shape of the graphs (particularly, the height and width of the curve). When the standard deviation is large, the 5 normal curve is short and wide, while a small value for the standard deviation yields a skinnier and taller graph. the curve above on the left is shorter and wider than the curve on the right, because the curve on the left has a bigger standard deviation. a normal curve is symmetric about its mean and is more concentrated in the middle rather than in the tails. Aside from that, observe that normal curves differ in how spread out they are (and that the spread or variability is measured by the standard deviations). when a random variable has a normal distribution with mean m and variance σ2, we denote this as X~N(μ,σ2). Technical Note: The height of a normal curve at some value x is a formidable looking expression that depends on the mean m and standard deviations: 6 7 KEY POINTS • The normal distribution, a special continuous distribution, is extremely important in statistics because many random variables that occur in real applications have normal distributions (or approximately normal distributions). • The normal distribution, characterized by its mean m and its standard deviations., has a graph that is bell-shaped. It is also symmetric about the mean so that in consequence, the mean is the median and is also the mode (since the curve is highest at the mean). • The normal curve satisfies the Empirical Rule: (a) Approximately 68% of the area under the normal curve is within one standard deviation from the mean; (b) Approximately 95% of the area under the normal curve is within two standard deviations from the mean; and (c) nearly everything, approximately 8 99.7% of the area under the normal curve, is within three standard deviations from the mean. ASSESSMENT 1. The data below and the accompanying histogram give the weights, to the nearest hundredth of a gram, of a sample of 100 coins (each with a value of P10). The mean weight is 8.69 grams and the standard deviation s is approximately 0.055 gram. a. Compare the mean and median. b. What percentage of the data is within one standard deviation of the mean? Within two standard deviations? Within three standard deviations? c. Suppose you were to randomly select a coin from this collection. What is the chance that its weight would be within one standard from the mean? Two standard deviations? Three standard deviations? d. What percentage of the data is below the mean? e. Suppose you were to randomly select a coin from this collection. What is the chance that its weight would be below the mean? 9 LESSON 3: AREAS UNDER A STANDARD NORMAL DISTRIBUTION The Standard Normal Curve Define the standard normal distribution to be the normal distribution with a mean of 0 and a standard deviation of 1, and draw a standard normal curve: 10 the table’s rows show the whole number and tenths place of the z-score, while the table’s columns show the hundredths place, and finally, the cumulative probability Φ(z) appears in the cell of the table. For example, a section of the standard normal table is reproduced below. To find the cumulative probability of a z-score equal to -1.31, explain to students that they should cross-reference the row of the table containing -1.3 with the column containing 0.01. The table shows that the probability that a standard normal random variable will be less than -1.31 is 0.0951; that is, Φ(1.31) = P(Z ≤ -1.31) = 0.0951. Practice this table of cumulative probabilities under a standard normal curve. Assume that we have a random variable Z that has a standard normal distribution. Ask them what would be: (a) P( Z ≤ 0 ): Answer should be 0.5 since the first entry of the first line (of the second page) for the Table of values of Φ(z) reads so. (b) P( Z ≤ -1.54 ) ; As per Table of values of Φ(z), answer is 0.0618 (c) P(-1.54 ≤ Z ≤ 1.54 ) = 0.8764. Get a graph of the pertinent area of interest, and show that the area between -1.54 and 1.54 can be obtained from the difference of the area to the left of 1.54 and the area to the left of -1.54: = P( Z ≤ 1.54 ) - P( Z ≤ -1.54 ) = 0.9382 - 0.0618 (as per the table entries) = 0.8764 (d) P(Z ≥ 1.54) = 0.0618 P(Z ≥ 1.54) is an upper tail area, but the total area under the curve is 1, so P( Z ≥ 1.54 ) is the difference of 1 and the area to the left of 1.54, i.e. 11 Alternatively, P( Z ≥ 1.54 ) = P( Z ≤ - 1.54 ) = 0.0618 12 KEY POINTS • The standard normal distribution is a normal distribution with a mean of 0 and a standard deviation of 1. • Tables of the Cumulative Distribution Function of a Standard Normal Distribution can be used to generate various areas of a standard normal curve as well as percentiles of the distribution. ASSESSMENT 1. The standard normal distribution a. has a mean of zero (0) and a standard deviation of 1. b. has a mean of 1 and a variance of zero (0). c. has an area equal to 0.5. d. cannot be used to approximate discrete probability distributions. 2. If Z has a standard normal distribution, and P (0 < Z < z ) is 0.3770, then the value of z is a. 0.18 b. 0.81 c. 1.16 d. 1.47 3. True or False: The probability that a standard normal random variable, Z, falls between – 1.50 and 0.81 is 0.7242. __________ 13 4. Suppose Z has a standard normal distribution with a mean of 0 and standard deviation of 1. The probability that Z is less than 1.15 is __________ 5. Suppose Z has a standard normal distribution with a mean of zero (0) and standard deviation of 1. The probability that Z values are larger than __________ is 0.3483. 6. Suppose Z has a standard normal distribution with a mean of zero (0) and standard deviation of 1. 85% of the possible Z values are smaller than __________. HANDOUT 14 15 LESSON 10: AREAS UNDER A NORMAL DISTRIBUTION Given a normally distributed random variable: X~N(μ,σ2), we often wish to find various probabilities pertaining to where an arbitrary measurement may lie. For instance, we may want to find P(a ≤ X ≤ b), which is the probability that a random measurement X lies between a and b. Standard Scores (or Z-scores) Whatever the value of the mean and standard deviation of a normal curve, we can transform the whole normal curve into a standard normal curve (as illustrated in the following figure). 16 This entails transforming the all data in a normal curve into standard units: An observation is in standard unit (or z-score) if we see how many standard deviations it is above or below the average. That is, if x, m, and s respectively represent the observation, its mean, its standard deviation, then the standardized form (or z-score) of x is Remember that a Z-score indicates how many standard deviations a certain data element is from the mean. For instance, if examination scores in Statistics and Probability have an average of 75 and a standard deviation of 5, then an exam score of 90 has a z-score of (90-75)/5 = 3, while a score of 70 has a z-score of (70-75)/5 =-1. To interpret these z-scores, we note that 90 is 3 standard deviations above the mean (75), while 70 is one standard deviation “below’ the mean. Z scores have a very good way of making variables comparable. The Z-scores may also be used for normal random variables to transform them into standard normal random variables, and this, in turn, can help us relate probabilities for any normal distribution to areas under a standard normal curve, as the following example on the time to walk a dog illustrates. Illustration for Finding Areas Under a Normal Curve Assume that the distribution of heights of all female Grade 11 students can be modeled well by a normal curve with a mean of 1620 mm and a standard deviation of 50 mm. Further, we wish to determine (a) the proportion of female Grade 11 students shorter than 1550 mm; (b) the proportion of female Grade 11 students taller than 1650 mm; (c) the proportion of female Grade 11 students between 1600 and 1675 mm; (d) the height of a female Grade 11 student for which 10 percent of female Grade 11 students are shorter than it; (e) the height of a female Grade 11 student for which 75% of female Grade 11 students are taller than it. For computing the answer to (a) first, transform 1550 to its z-score, yielding (1550-1620)/50 =-1.4 so that we can associate the area to the left of 1550 (under a normal curve with mean 1620 and standard deviation 50) with that of the area to the left of z = -1.4 under a standard normal curve. Reading 17 from the table of Cumulative Distribution Function of a Standard Normal Curve, we find Φ(-1.4) = 0.0808, For (b), transform the height value 1650 to its standard units, (16501620)/50 = 0.6, and then note that the area to the right of z = 0.6 under the standard normal curve is the difference between the total area under a standard normal curve (100%) and the area to the right of z=0.6, Φ (0.6) = 0.7257. In consequence, the desired probability (and area) is 1- 0.7257=0.2743. For (c), learners should mention they need to firstly transform 1600 and 1675 into their respective standardized forms, namely (1600-1620)/50 = -0.4 and (1675- 1620)/50 = 1.1, and then generate the area between these two zscores as the difference between Φ (1.1) and Φ (-0.4), i.e. 0.86430.3446=0.5197. For (d), draw the figures on the board to illustrate what needs to be done: The 10th percentile of the height distribution may be obtained by firstly getting the 10th percentile of the standard normal curve, which can be read off from the table as –1.282. This means that the 10th percentile of the height distribution is 1.282 standard deviations below the mean. This required value for the height is – 1.282(50)+1620 =1555.9. Finally, for (e), suggest to learners that we want the 25th percentile as this is the value for which 75 percent of the height distribution would be above it. Similar to (d), tell students they can find the 25th percentile first of a standard normal curve (– 0675), then yield the required height as: –0.675(50)+1620 =1586.25. KEY POINTS • To obtain probabilities or percentiles under a normal curve, perform two steps: Transform the normal curve into a standard normal curve by way of “z-scores” (which involves subtracting the mean and dividing the result by the standard deviation) z = (X - μ) / σ. Then, use the tables of the Cumulative Distribution Function of a Standard Normal Distribution to obtain the required areas of a standard normal curve to find the probabilities associated with the z-scores. 18 ASSESSMENT 1. If a particular batch of data is approximately normally distributed, we would find that approximately a) 2 of every 3 observations would fall between ±1 standard deviation around the mean. b) 4 of every 5 observations would fall between ±1.28 standard deviations around the mean. c) 19 of every 20 observations would fall between ±2 standard deviations around the mean. d) All the above. For problems 2 to 4 consider the following case. The length of time it takes a Grade 11 student to play the Candy Crush computer app follows a normal distribution with a mean of 3.5 minutes and a standard deviation of 1 minute 2. The probability that a randomly selected Grade 11 student will play one game of Candy Crush in less than 3 minutes is a) 0.3551 b) 0.3085 c) 0.2674 d) 0.1915 3. The probability that a randomly-selected grade 11 student will take between 2 and 4.5 minutes to play Candy Crush is: a) 0.0919 b) 0.2255 c) 0.4938 d) 0.7745 4. The point in the distribution of times to play Candy Crush in which 75.8% of the Grade 11 students exceed when playing Candy Crush. a) 2.8 minutes b) 3.2 minutes c) 3.4 minutes d) 4.2 minutes 5. Rodrigo earned a score of 940 on a national achievement test. The mean test score was 850 with a standard deviation of 100. What proportion of students had a higher score than Rodrigo? (Assume that test scores are normally distributed.) If there were 100,000 students who took the test, how many would be expected to have a higher score than Rodrigo? 19 REFERENCES De Veau, R. D., Velleman, P. F., and Bock, D. E. (2006). Intro Stats. Pearson Ed. Inc. Workbooks in Statistics 1: 11th Edition, Institute of Statistics, UP Los Baños, College Laguna 4031 Random Variables. Khan Academy. Retrieved from https://www.khanacademy.org/math/probability/randomvariablestopic/random_variables_prob_dist/v/random-variables De Veau, R. D., Velleman, P. F., and Bock, D. E. (2006). Intro Stats. Pearson Ed. Inc. Workbooks in Statistics 1: 11th Edition, Institute of Statistics, UP Los Baños, College Laguna 4031 Probability and Statistics Module 19: Discrete Probability Distributions. (2013) Australian Mathematical Sciences Institute and Education Services Australia. Retrieved from http://www.amsi.org.au/ESA_Senior_Years/SeniorTopic4/4_md/SeniorTopic 4c.html http://www.amsi.org.au/ESA_Senior_Years/SeniorTopic4/4_md/SeniorTopic 4c.html#content_1 http://www.amsi.org.au/ESA_Senior_Years/SeniorTopic4/4_md/SeniorTopic 4c.html#content_2 http://www.amsi.org.au/ESA_Senior_Years/SeniorTopic4/4_md/SeniorTopic 4c.html#content_3 https://www.youtube.com/watch?v=qSu-Rk-6apw&feature=youtu.be Probability and Statistics Module 21: Continuous Probability Distributions. (2013) Australian Mathematical Sciences Institute and Education Services Australia. Retrieved from http://www.amsi.org.au/ESA_Senior_Years/PDF/ContProbDist4e.pdf Probability and Statistics Module 19: Discrete Probability Distributions. (2013) Australian Mathematical Sciences Institute and Education Services Australia. Retrieved from http://www.amsi.org.au/ESA_Senior_Years/SeniorTopic4/4_md/SeniorTopic 4c.html#content_3 http://www.amsi.org.au/ESA_Senior_Years/SeniorTopic4/4_md/SeniorTopic 4c.html#content_5 http://www.amsi.org.au/ESA_Senior_Years/SeniorTopic4/4_md/SeniorTopic 4c.html#content_6 [staslectures]. Mean and Expected Value of Discrete Random Variables. Retrieved from 20 https://www.opened.com/video/mean-and-expected-value-of-discreterandom-variables/116285 https://www.opened.com/video/variance-and-standard-deviation-of-discreterandom-variables/116286 https://www.opened.com/video/mean-e-x-and-variance-var-x-forcontinuous-random-variables/116287 21