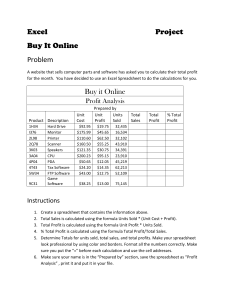
An article by Susan Eliot Using Excel for Qualitative Data Analysis I’ve been using an Excel spreadsheet to organize focus group and interview data for analysis for several years. It’s a nice compromise between the manual “cut-and-paste” method and commercial software like Atlas or NVivo. To be clear, no system—Atlas, NVivo, or Excel—can analyze the data for you, no matter how expensive or sophisticated it is. It takes a human brain to do that. But, unless you’re conducting a large, multiple investigator research study that produces a ton of data, Excel does a fine job of organizing textual data for analysis. In this article I describe a step-by-step process for how you can do that. Assumptions First, the following assumptions must be made about any qualitative study for which you plan to use this methodology: • • • • You used a rigorous data collection process. The question guide was structured and intentional. Data collection resulted in high quality data. Complete, accurate transcripts were produced. Worksheet Template Before you start entering data into Excel, your spreadsheet must be formatted in a way that eases data manipulation. Setting up the template properly will reduce frustrations often associated with trying to manage word data with Excel. I start by creating a single worksheet template that I then duplicate for each interview question. This saves me from having to recreate the spreadsheet for each question. My guidelines for developing the template are as follows: 1. Set margins to “0” and page orientation to "landscape" to maximize space for data entry. 2. Enter the title of the study at the top of the page and leave a blank line for the study question (remember, each question has its own worksheet). 3. Create columns with headings for each of the following: © Copyright. Susan Eliot. July 2011. TheListeningResource • • • PID (Participant identification number) Code Responses (as wide a column as possible without flowing over to the next sheet) You can also create separate columns for face codes such as gender, age, occupation, location, etc. Attaching face codes to each response allows you to sort the data by those parameters. For example, you may want to contrast responses made by women versus those made by men. Or you might want to look at how responses vary by age. Of course, this presupposes that you have collected face code data on each participant (through a short pre-interview survey for example) and labeled it with the corresponding PID. Once you’ve created the template, make a copy of it (within the same workbook) for each question in the study. Don’t forget to insert one question at the top of each worksheet and label each tab at the bottom accordingly. Data Entry The goal is to transfer all of the study data you've collected into the spreadsheets. Since my transcripts are in Word, I convert the document to table format (Table > Convert > Convert Text to Table) before I transfer the data to the Excel spreadsheet. Assuming there is a carriage return after each response on the transcript, each response will transfer over to a separate cell on the spreadsheet when you copy and paste. Alternatively, I’ve also used voice recognition software to “speak” the responses into cells. As I transfer responses to the Excel spreadsheet, I simultaneously add the unique PID and face codes that go with each entry. Generally each response occupies one cell, but if the response is multivalent (has more than one meaning unit per response) I split it into separate cells and copy the PID and face codes for each split response. Because I like to see entire response entries on one screen, I use “Wrap Text” to keep long entries from running across the next several sheets of the spreadsheet. Wrapping responses keeps them neat and tidy for printing too. When I’ve completed the data entry I like to print out the data set and sit in a comfy spot with a nice cup of tea to begin reviewing it. Coding and Categorizing I start the categorization by jotting down category labels that come to mind as I read and re-read responses one question at a time. These category labels can be a word or, more often, a short phrase (often verbatim from the transcript). I use a large (4” X 6”) sticky pad that I attach to the corresponding printed spreadsheets to denote the category labels as they come to mind. © Copyright. Susan Eliot. July 2011. TheListeningResource When I think I have a fairly comprehensive list of mutually exclusive category titles, I assign each a letter code (A, B, C, D, etc.) to make the categories easier to work with. This first pass through the data is only my first “best guess” of categories emerging from the data. I then use a pencil to assign one of these codes to each entry on the spreadsheets. On this first swipe at the data I always find entries that: • • • • • Don’t fit in any category Fit in more than one category Are a major subcategory of one of my categories Generate a whole new category Are the only one of their kind I make adjustments in coding categories to accommodate my new insights--collapsing categories with others that may only have one response, teasing out sub-categories or smaller categories from larger ones. It still might not be perfect the second or even third time through, but each time I move through the data, categories becomes less vague and a more precise fit with the data. Once I am satisfied that I have found an appropriate code for each response, I enter the codes into the “CODE” column on my electronic spreadsheet. Then I highlight the entire data set (make sure you include ALL columns and rows), click “Sort” (under “Data” in the top toolbar), choose the "CODE" column, and, voila, all of the data appears in separate little groups according to the codes just assigned. Now I can look at each group of responses and add, delete, change, subdivide, or collapse categories if necessary. I sort again and repeat the process as many times as necessary until I am satisfied that my categorization reflects the true essence of the data. I ask myself if this is what respondents were actually trying to collectively convey. Do their voices come through or have I imposed my own? An Example Following is a simple analysis spreadsheet for a focus group study I conducted for the University of Colorado School of Dentistry regarding dental hygiene. I interviewed flossers and non-flossers in separate groups. Participants were asked who influenced their dental habits, about flossing follow through, and how they felt about themselves when they flossed. This example includes a partial list of responses to question 4 (Who influenced you?). Notice the coding key that corresponds to the letter codes in the Code column. In this example I have not yet sorted the data by code. © Copyright. Susan Eliot. July 2011. TheListeningResource Making Comparisons If you faithfully entered face sheet and identification codes with each response, then Excel’s “Sort” function will enable you to make comparisons among subsets of your data. For example, if you entered the gender of each participant, then you will be able to compare responses of men to those of women for each question if you sort all of your data by the "gender" column. You will be able to do this for each of the face sheet codes entered. Like a kaleidoscope, the picture changes each time you re-sort. Below is a sample spreadsheet from a workplace inclusivity study I conducted for the city of Portland several years ago. During analysis I sorted data by the eight separate face codes (role, location, work group, etc.) you see in the example. (Remember, you must grab all columns and rows before hitting the Sort button). © Copyright. Susan Eliot. July 2011. TheListeningResource © Copyright. Susan Eliot. July 2011. TheListeningResource