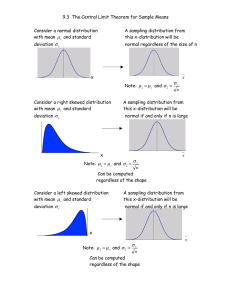
Elementary Statistics, STA 2023 Vocabulary From the Data at Hand to the World at Large (Chapters17) Inference with Means Recall that statistical inference provides methods for drawing conclusions about a population from sample data. The two most common types of statistical inference include confidence intervals (estimate margin of error) for estimating the value of population parameter and tests of significance (Five Step Method) which assess the evidence provided by data about some claim concerning a population. Both types of inference are based on the sampling distributions of statistics. In other words, both report probabilities that state what would happen if we used the inference method many times. In chapters 18-19, we studied statistical inference in relation to proportions. We’ll now study statistical inference relating to means (averages). Sampling distribution of sample means: The idea is to take as many samples as possible of size n from the population with mean and standard deviation . Then collect the means, x , from all the samples, and display the distribution of the sample means. According to the Central Limit Theorem, as the sample size n increases… …the sampling distribution model of the sample means will be: 1. normally distributed 2. the mean of the sampling distribution of sample means will equal the population mean, x 3. the standard deviation of the distribution of sampling means (standard error of the mean) will be x n . …as long as the following assumptions and conditions have been met: Randomization o SRS Condition: the sample is randomly selected 10% Condition o 10% Condition: the sample is no more than 10% of the population Sample Size Condition o Normality Condition: Histogram of data is unimodal and symmetric as follows… if n < 30, it must be very close to normal (probability plot) If population description leads to unimodality and symmetry, the condition is fine. If there is no population description, data must be present to verify (chapter 3) if n > 30, normality not necessary (if outliers are present, report results with and without the outliers) The Central Limit Theorem allows us to use normal probability calculations to answer questions about sample means from many observations even when the population distribution is not normal. Problem 17-41 If we are just describing the distribution based on the histogram, we are essentially treating that as the population. You would describe this distribution with tools used in chapter 3. The distribution is unimodal, slightly skewed, with mean of 36 inches and standard deviation of 4 inches. According to the construct of our central limit theorem, we know the sample means will be centered around 36 inches and our variability in the sample means decreases as the sample size increases. Due to the nature of the population, we see the normal behavior in the sample means earlier than the sample size condition would indicate (n>30) Problem 17-45 Randomization-Assuming the students are assigned randomly 10%-25 students seem to be 10 percent of any incoming freshman class. Sample size condition-n<30. However, since the original population was mound shape (unimodal) and only slightly skewed. This condition is probably satisfied. Though usually, this condition is scrutinized more. Since the conditions checked out, the distribution of the sample mean is normal with mean equal to the population mean (i.e. 3.4 GPA) and standard deviation equal to ̅) = 𝝈𝒚̅ = 𝟎. 𝟑𝟓/√𝟐𝟓 𝑺𝑫(𝒚 For the 68-95-99.7 Rule, we use the same rule in chapter 5 (I know you all love that rule. Just kidding!!) The rule applies the same exact way: 68 percent of the sample means are within 1 standard deviation of the mean. 95 percent of the sample means are within 2 standard deviations of the mean. 99.7 of the sample means percent are within 3 standard deviations of the mean. For this problem: 68 percent of sample means are within 3.33 and 3.47 95 percent of sample means are within 3.26 and 3.54 99.7 percent of sample means are within 3.19 and 3.61. Problem 17-46 This is yours to practice and reach out if you need help. Problem 17-49 Part A is a chapter 5 problem; we begin by calculation of z-scores for 270 and 280. 𝒛𝟏 = 𝟐𝟕𝟎 − 𝟐𝟔𝟔 𝟏𝟔 𝒛𝟐 = 𝟐𝟖𝟎 − 𝟐𝟔𝟔 𝟏𝟔 Then we use normalcdf in the following way: 𝟏 𝟕 𝒏𝒐𝒓𝒎𝒂𝒍𝒄𝒅𝒇 ( , , 𝟎, 𝟏) = 𝟎. 𝟐𝟏𝟎𝟓 𝟒 𝟖 Part B asks how many days should the longest 25% duration of pregnancies last. We would find the z-score of lowest 25% using: 𝒊𝒏𝒗𝒏𝒐𝒓𝒎(𝟎. 𝟕𝟓, 𝟎, 𝟏) = −𝟎. 𝟔𝟕𝟒𝟒 And then solve for x below: 𝟎. 𝟔𝟕𝟒𝟒 = 𝒙 − 𝟐𝟔𝟔 𝒙 ≈ 𝟐𝟕𝟕 𝒅𝒂𝒚𝒔 𝟏𝟔 Part C informs, we took a sample of size 60 from this population. We want to essentially confirm the central limit theorem through conditions. 10%-60 women is less than 10 percent of all pregnant women in any location Randomization- Assumed unless told otherwise. Sample size condition-n>30, we are good. Based on approved conditions, the following holds true: 𝝁𝒚̅ = 𝝁 = 𝟐𝟔𝟔 𝝈𝒚̅ = 𝟏𝟔/√𝟔𝟎 Part D wants to know what is the probability of a mean duration of 260 days. This is a similar problem to the earlier part in process where we found probability. However, only difference is now we want to know the probability of a sample average being a certain value. Prior to this, it was individual observations. So, the calculation looks like below: 𝒛= 𝟐𝟔𝟎 − 𝟐𝟔𝟔 = −𝟐. 𝟗𝟎𝟒𝟕 𝟏𝟔 √𝟔𝟎 Then 𝒏𝒐𝒓𝒎𝒂𝒍𝒄𝒅𝒇(−𝟏𝟎𝟎𝟎𝟎, −𝟐. 𝟗𝟎𝟒𝟕, 𝟎, 𝟏) = 𝟎. 𝟎𝟎𝟏𝟖 Problem 17-60 It is for you to practice and reach out with questions. Extra Problem Suppose we would like to know if there is actually a gallon of milk in a gallon container. Suppose for checking this industry standard, we then looked at the population and found a distribution with mean 0.99 gallons with standard deviation of 0.10 gallons. If the distribution of these containers was unimodal with a very small skew: What would be the model/distribution to approximate an individual container containing at least 0.98 gallons of milk? This is normal based on the fact that we randomly take measurements in a sufficient size. There will be instance where we are below target and above target. What would be the probability of an individual container measuring 0.98? 𝒛= 𝟎. 𝟗𝟖 − 𝟎. 𝟗𝟗 = −𝟎. 𝟏𝟎 . 𝟏𝟎 𝒏𝒐𝒓𝒎𝒂𝒍𝒄𝒅𝒇(−𝟎. 𝟏𝟎, 𝟏𝟎𝟎𝟎𝟎, 𝟎, 𝟏) = 𝟎. 𝟓𝟑𝟗𝟖 Now, suppose we take a sample of size 25, Calculate the 68-95-99.7 boundaries for such a context. The boundary for 68 percent would be (0.97, 1.01) The boundary for 95 percent would be (0.95, 1.03) The boundary for 99 percent would be (0.93, 1.05) 10%-25 gallon containers is less than 10 percent of any population/batches of gallon milk Randomization-Assumed Sample Size Condition-since n<30, we have to look back to the problem description to see if our population exhibited normal behavior. In this case it does. Since our sample mean is normally distributed, we can state that: ̅) = 𝝁𝒚̅ = 𝝁 = 𝟎. 𝟗𝟗 𝒂𝒏𝒅 𝑺𝑫(𝒚 𝝈 √𝟐𝟓 = 𝟎. 𝟎𝟐 What is the probability that a sample of size 25 has a mean weight of at least 0.96 gallons? 𝒛= 𝟎. 𝟗𝟔 − 𝟎. 𝟗𝟗 = −𝟏. 𝟓 𝟎. 𝟎𝟐 𝒏𝒐𝒓𝒎𝒂𝒍𝒄𝒅𝒇(−𝟏. 𝟓, 𝟏𝟎𝟎𝟎𝟎, 𝟎, 𝟏) = 𝟎. 𝟗𝟑𝟑𝟐