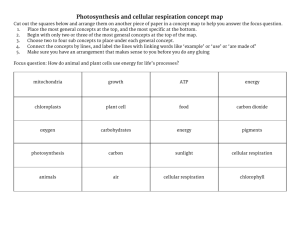
Energy Review WS 1) What are the reactants of photosynthesis? 2) What are the products of photosynthesis? 3) Write the balanced chemical equation for photosynthesis. 4) Label the chemical compounds in the formula above with the words they represent (example: H20 would be labeled water). 5) What are the 2 main reasons that it is it important for us that plants perform photosynthesis? a. b. 6) Where does all the energy in an ecosystem and food web come from? 7) What organelle in plant cells is responsible for performing photosynthesis? 8) Do animals have that organelle? Why or why not? 9) What are the reactants for Cellular Respiration? 10) What are the products of Cellular Respiration? 11) Write the balanced chemical equation for Cellular Respiration. 12) Label the chemical compounds in the formula above with the words they represent (example: H20 would be labeled water). 13) What organelle in animal cells is responsible for cellular respiration? 14) Do plants have that organelle? Why or why not? 15) Why is it important to do cellular respiration? What do we get out of it? 16) What does ATP stand for? 17) What is ATP’s Job? 18) After ATP gives energy away to a reaction what does it become? 19) How can ADP return to being ATP? 20) Draw and label the parts of ATP. Also label where the most energy is stored. 21) Draw and label the cycle between Photosynthesis and Cellular Respiration: Be sure to include the following words: Carbon Dioxide, water, glucose, oxygen, sunlight, ADP, ATP, Photosynthesis, Cellular Respiration