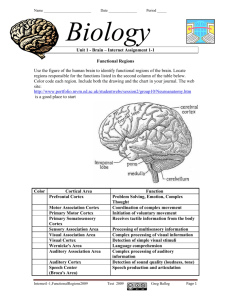
NeuroImage 17, 1300 –1305 (2002)
doi:10.1006/nimg.2002.1279
Human Cortical Dynamics Determined
by Speech Fundamental Frequency
Anna Mari Mäkelä,* ,† Paavo Alku,‡ Ville Mäkinen,* ,† Jussi Valtonen,* Patrick May,* and Hannu Tiitinen* ,†
*Apperception & Cortical Dynamics (ACD), Department of Psychology, P. O. Box 13, FIN-00014 University of Helsinki, Finland; †BioMag
Laboratory, Engineering Centre, Helsinki University Central Hospital, P. O. Box 340, FIN-00029 HUS, Finland; and ‡Laboratory
of Acoustics and Audio Signal Processing, P. O. Box 3000, FIN-02015 Helsinki University of Technology, Finland
Received April 1, 2002
Evidence for speech-specific brain processes has
been searched for through the manipulation of formant frequencies which mediate phonetic content and
which are, in evolutionary terms, relatively “new” aspects of speech. Here we used whole-head magnetoencephalography and advanced stimulus reproduction
methodology to examine the contribution of the fundamental frequency F0 and its harmonic integer multiples in cortical processing. The subjects were presented with a vowel, a frequency-matched counterpart
of the vowel lacking in phonetic contents, and a pure
tone. The F0 of the stimuli was set at that of a typical
male (i.e., 100 Hz), female (200 Hz), or infant (270 Hz)
speaker. We found that speech sounds, both with and
without phonetic content, elicited the N1m response
in human auditory cortex at a constant latency of 120
ms, whereas pure tones matching the speech sounds in
frequency, intensity, and duration gave rise to N1m
responses whose latency varied between 120 and 160
ms. Thus, it seems that the fundamental frequency F0
and its harmonics determine the temporal dynamics
of speech processing in human auditory cortex and
that speech specificity arises out of cortical sensitivity
to the complex acoustic structure determined by the
human sound production apparatus. © 2002 Elsevier
Science (USA)
INTRODUCTION
The ability to understand speech signals, despite
their vast inherent diversity, is usually taken for
granted. For example, the utterance “a,” be it spoken in
a high-pitched female voice or in a low-pitched male
voice, shouted or whispered, invariably represents the
corresponding phoneme /a/. While still requiring a neuronal-level explanation, this aspect of speech perception is referred to as phonetic invariance. Consequently, the perception of speech has been linked to
processes specific in human speech production (Liberman and Mattingly, 1989; Liberman and Whalen,
1053-8119/02 $35.00
© 2002 Elsevier Science (USA)
All rights reserved.
2000; Rizzolatti and Arbib, 1998). Moreover, it has
been suggested that the human brain carries out a
categorization process (Eimas et al., 1987) which relies
on phoneme representations shared through exposure
to the language environment (Kuhl et al., 1992; Dehaene-Lambertz, 1997). These representations, then,
enable us to detect, classify, and discriminate extremely rapidly between incoming speech stimuli from
an early age onward (Dehaene-Lambertz and Dehaene,
1994).
From the point of view of speech production, a voiced
speech signal essentially consists of phonation and articulation (Fant, 1970; Kent and Read, 1992). In phonation, the vibrating vocal folds produce a periodic
waveform, the glottal excitation. Due to this inherent
periodicity, the spectra of voiced speech sounds consist
of a fundamental frequency (F0) and its harmonic integer multiples (i.e., 2 䡠 F0, 3 䡠 F0, etc.). The F0 is
determined by the rate of the vocal fold vibration
which, in turn, is mainly governed by the size of the
vocal folds (Titze, 1994). Humans are able to vary the
F0 of speech extensively which enables changes in
voice pitch. While the vocal fold vibration rate provides
for a considerable dynamic range, the average F0 is
about 100 Hz in males, 200 Hz in females, and up to
400 Hz in infants (Kent and Read, 1992). Articulation,
then again, alters the shape and, consequently, the
resonance frequencies of the oral cavity modifying the
sound produced by the vocal folds. These resonances,
termed the formants (F1, F2, F3, etc.), are the carriers
of the phonemic information of speech. Consequently,
the main spectral components of speech are F0 and its
harmonics as well as the formant frequencies.
While previous research in humans (Kuhl et al.,
1992; Schwartz and Tallal, 1980; Studdert-Kennedy
and Shankweiler, 1970) and the monkey (Tian et al.,
2001) has gained several insights into the rapid cognitive processes involved in understanding speech, tackling the temporal as well as the spatial dynamics of the
underlying brain activity precludes, to an extent (Belin
et al., 2000; Zatorre et al., 1992), the use of slow hemo-
1300
1301
SPEECH F0 AND CORTICAL DYNAMICS
dynamic brain imaging tools. Instead, we must turn to
methodology capable of discriminating brain events
with a millisecond and millimeter resolution, namely
magneto- and electroencephalography (MEG and EEG;
Hämäläinen et al., 1993). The majority of MEG and
EEG studies on speech, however, have addressed
speech perception by focusing only on the recently
emerged phonetic aspects of speech (i.e., formant transitions in the F1–F2 space) without considering the
role of F0 in conveying the information embedded in
speech signals (Bolinger, 1989; Katz and Assmann,
2001; Patel and Balaban, 2001).
Several converging lines of investigation, nevertheless, seem to suggest that the F0 of speech should
perhaps not be overlooked. For example, by using pure
tones and pure tone complexes it has been repeatedly
shown that at frequencies below 500 Hz—in the F0
range of spoken language—the latency of the most
prominent cortical response, the auditory N1(m), typically occurring 100 ms after stimulus onset, can increase up to 150 ms as stimulus frequency is lowered
(Crottaz-Herbette and Ragot, 2000; Roberts et al.,
2000; May et al., 1999). This slowing down of information processing at those frequencies where the speech
F0 typically lies seems not only counterintuitive, but
also inefficient from an evolutionary perspective as
humans presumably used F0 for communication purposes before spoken language emerged (Liberman and
Whalen, 2000; Rizzolatti and Arbib, 1998; Corballis,
1998). Further evidence for the functional significance
of F0 can be drawn from studies which show that the
human brain is capable of deducing F0 from the spectrum of the harmonics even if it is missing (Pantev et
al., 1989; Ragot and Lepaul-Ercole, 1996). Obviously,
there must be an ecologically valid reason for these
calculations of F0 to occur, and an investigation into
this issue might help explain human pitch perception
and phenomena such as phonetic invariance.
The need to control fully the stimulus parameters
has, to date, apparently been the main justification for
using pure tones in cognitive brain research. In some
cases, the processing of speech has been approached by
studying brain activity elicited by pure tone combinations (Patel and Balaban, 2001; Crottaz-Herbette and
Ragot, 2000; Roberts et al., 2000; Ragot and LepaulErcole, 1996), while in others, speech sounds of multiple simultaneously varying parameters have been utilized (Schwartz and Tallal, 1980; Belin et al., 2000;
Zatorre et al., 1992; Vihla et al., 2000). Recent advances
in sound generation methodology (Alku et al., 1999),
however, now enable us to combine the use of ecologically valid speech stimuli with full stimulus control.
Using this methodology we recently succeeded in showing that already the presence of inherent periodicity of
voiced speech is reflected in cortical brain responses
(Alku et al., 2001).
In the present study, we set out to investigate how
fundamental frequency changes in speech are manifested in MEG recordings and, especially, in the N1m
response. More specifically, we studied the cortical
brain events elicited by speech sounds whose F0
ranged from that of a typical male speaker (i.e., 100
Hz) to that of a typical female (200 Hz) and infant (270
Hz) speaker. Using these three F0 values, the subjects
(N ⫽ 13) were presented with a vowel, a frequencymatched counterpart of the vowel with no phonetic
content (“pseudo-vowel” lacking in articulatory F1–F2
contribution), and a pure tone.
METHODS
Subjects. Thirteen volunteers (laboratory personnel and paid students, mean age 32 years, 2 females)
participated in the study with informed consent. All
were right-handed and none had a history of hearing or
neurological disorders. The study was approved by the
ethical committee of the Helsinki University Central
Hospital.
Stimulus preparation and presentation. The stimuli of the study consisted of three types of sounds:
vowels, pseudo-vowels, and pure tones (Fig. 1). In each
category, three stimuli of different fundamental frequency (F0) values were constructed. In order to produce sounds that differ only in terms of F0, we used a
novel stimulus generation methodology, semi-synthetic speech generation (Alku et al., 1999). This synthesizes a speech sound by first estimating the excitation waveform of voiced speech generated by the
fluctuation of the vocal folds—the glottal pulseform—
from a natural utterance. By using this natural excitation waveform as an input to an artificial vocal tract
modeled by a digital all-pole filter it is then possible to
synthesize highly natural sounding, yet completely
controllable speech stimuli. The stimulus production
was started by creating a Finnish /a/ vowel with its F0
representing typical male speech (F0 ⫽ 100 Hz). The
lowest four resonances of the vocal tract were adjusted
to create the following formant pattern: F1 ⫽ 800 Hz,
F2 ⫽ 1120 Hz, F3 ⫽ 1440 Hz, and F4 ⫽ 3100 Hz. By
shortening the lengths of the consecutive cycles in the
glottal excitation of this sound, it was possible to produce representatives of the same vowel by changing F0
only. With this principle, we synthesized two versions
of the vowel /a/ corresponding to female and child
speech with F0 values of 200 and 270 Hz, respectively.
The second type of stimulus, the pseudo-vowel, was
created as a composite of sinusoidals by mimicking the
spectra of the three /a/ vowels of different F0 values. In
making these signals, each tone was selected to match
precisely (both in frequency and in amplitude) the harmonic in the spectrum of the corresponding vowel. The
highest harmonic to be matched by a tone was limited
to occur halfway between the F1 and F2 of the corre-
1302
MÄKELÄ ET AL.
FIG. 1. Spectra on the three stimulus types shown with the
fundamental frequency value F0 ⫽ 270 Hz. The spectrum of the pure
tone (top) consists of only a single frequency component located at
F0. The spectrum of the pseudo-vowel (middle) comprises the F0 and
its integer multiples, the harmonics, up to the midway between the
first and second formant of the vowel spectrum (bottom). The level
difference of consecutive harmonics in the spectrum of the pseudovowel equals that in the vowel spectrum. (The bandwidth of the
sounds was 11025 Hz, but the spectra are depicted over the frequency span of 5 kHz in order to clarify differences in the structure
of lowest harmonics.)
sponding vowel /a/ in order not to make the perceptual
quality of the sound too close to that of the vowel /a/.
Finally, the third stimulus type, the pure tone, was
produced by using single frequencies corresponding to
the F0 values of 100, 200, and 270 Hz. The stimuli were
presented in separate sequences, at a constant interstimulus interval of 800 ms, with ⬎150 repetitions per
stimulus type. The sequences were presented in pseudorandom order and the presentation order was counterbalanced across subjects. The stimulus duration
was 200 ms and stimulus intensity was adjusted to 75
dB SPL.
MEG recording and data analysis. Event-related
magnetic fields were recorded using a whole-head magnetometer (Neuromag ⫺122, Neuromag Ltd., Helsinki,
Finland) while the subject, instructed not to pay attention to the auditory stimulation, sat in a reclining chair
and watched a silent movie. The stimuli were binaurally delivered through plastic tubes and ear pieces.
The evoked responses were filtered with a passband of
1–30 Hz and averaged over a period of 600 ms, includ-
ing a 100-ms prestimulus baseline. Electrodes monitoring both horizontal and vertical eye movements
were used in removing artifacts defined as the absolute
value exceeding 150 V.
The N1m response was studied with respect to possible effects in amplitude, latency, and location (data of
two subjects was rejected from further analyses due to
poor signal-to-noise ratio). The analyses were carried
out both for response waveforms and for estimated
equivalent current dipoles (ECDs). The waveform
analysis was carried out for the vector sum of the
channel pair showing the most prominent activity at
100 ms, separately in each hemisphere and for each
subject. For ECD estimation, a subset of 34 sensors
over either the left or the right temporal brain areas
were used in an unconstrained ECD fitting, with a
goodness-of-fit ⱖ70% qualifying the data for further
analyses. The ECD locations were estimated in a threedimensional coordinate system defined by the x-axis
passing through the preauricular points (positive to
the right), the y-axis passing through the nasion, and
the z-axis as the vector cross-product of the x and y unit
vectors. Statistical analyses of the data were performed using repeated measures ANOVA and Newman–Keuls post hoc tests. Finally, in order to illustrate
the spatial extent of the activated cortical areas at the
moment of the peak amplitude of the N1m response we
used the minimum current estimate method (MCE;
Uutela et al., 1999).
RESULTS
Figure 2 shows the spatial extent of cortical activation of a typical subject, illustrated with MCE, at the
moment of the N1m peak amplitude for the three stimuli and the three fundamental frequencies used. It can
be seen that all nine stimuli activated the same brain
areas in the auditory cortex of each hemisphere. The
ECD analysis further revealed that on the average, the
speech stimuli elicited somewhat stronger activity
(ECD strength 26 nAm) than the pure tones (ECD
strength 21 nAm); however, the difference was not
statistically significant (F(8, 2) ⫽ 2.42, P ⫽ ns). Neither
hemispheric lateralization (F(10, 2) ⫽ 0.140, P ⫽ ns)
nor location effects of stimulus type (F(10, 2) ⫽ 2.58,
0.31, 1.10 for x, y, and z coordinates, respectively; P ⫽
ns for all cases) were observable at this stage of auditory processing.
Figure 3 summarizes the key finding of our study:
the latency of the N1m exhibited highly systematic and
statistically significant behavior as a function of stimulus type (F(2, 16) ⫽ 40.64, P ⬍ 0.001) and frequency
(F(2, 16) ⫽ 10.76, P ⬍ 0.01), but no hemispheric distribution asymmetry (F(1, 8) ⫽ 0.67, P ⫽ ns). The
latency of the N1m elicited by the vowel and the
pseudo-vowel remained constant for all F0 values (P ⫽
ns), with the N1m always peaking at around 120 ms
1303
SPEECH F0 AND CORTICAL DYNAMICS
FIG. 2. The spatial extent of cortical activation at the moment of the N1m peak amplitude. The vowel, pseudo-vowel, and tone stimuli
elicited strong and localized activity in the supratemporal brain areas, as revealed by minimum current estimate modeling (MCE; Uutela et
al., 1999; baseline, ⫺100 – 0 ms, data detrended and 40-Hz low-pass filtered, the center values of region of interest (ROI) for the x, y, and z
coordinates are ⫺57, 9, and 51 mm in the left and 53, 7, and 51 mm in the right hemisphere). Cortical activations at the peak of the N1m
response (t ⫽ latency of the response in milliseconds) for F0 values representing infant (270 Hz), female (200 Hz), and male (100 Hz) speech
and pure tones of corresponding frequencies are depicted.
after stimulus onset. There were no latency differences
between the responses evoked by the pseudo-vowels
and the vowels with the same F0 value (P ⫽ ns).
This invariance was in striking contrast with the
latency variation of the N1m responses elicited by the
pure tones. In this case, the latency increased from 125
to 160 ms as a function of decreasing F0 (P ⬍ 0.001 for
270 vs 100 Hz and 200 vs 100 Hz and P ⬍ 0.05 for 270
vs 200 Hz). The latencies of the N1m responses evoked
by the pure tones differed significantly from those
evoked by the vowels and pseudo-vowels of the corresponding F0 values (P ⬍ 0.05 for vowel vs tone at 200
Hz; P ⬍ 0.001 for vowel vs tone and pseudo-vowel vs
tone at 100 Hz).
DISCUSSION
FIG. 3. Latency behavior of the auditory N1m. An analysis of the
temporal dynamics of the N1m revealed, both at the single-subject
level and at across-subject averages, that the human brain times its
response to auditory stimuli according to their spectral structure.
Changes in the frequency of a pure tone result in a large latency
variation of the N1m response, whose latency is shifted from 125 to
160 ms as the tone frequency is decreased from 270 to 100 Hz. When
natural speech sounds matching the pure tone frequency in their F0
are presented, this latency variation is abolished, and both the left
and the right hemispheres respond to the vowels and the pseudovowels with a constant latency of 120 ms (bars indicate the standard
error of the mean).
In conclusion, our results show that natural speech
and artificial pure tone stimuli are processed differently already in the auditory sensory areas of the human brain. Whereas pure tones activate the auditory
cortex with a latency which strongly depends on tone
frequency (Crottaz-Herbette and Ragot, 2000; Roberts
et al., 2000; May et al., 1999; Ragot and Lepaul-Ercole,
1996), natural speech sounds (with or without phonetic
content) activate the auditory cortex at a constant latency of about 120 ms. Importantly, the timing of this
activation is independent of the value of F0, that is, of
whether the speech sound is that of a typical male,
female, or infant speaker.
Thus, the categorization of sounds as speech or nonspeech takes place very rapidly in dedicated neuronal
circuits of both the left and the right temporal lobes. As
these results were obtained in a passive listening condition, it seems that this categorization process occurs
even without attentional engagement. Moreover, it can
be directly observed through the behavior of the N1m
response, without possibly distorting subtraction procedures (Vihla et al., 2000; Tiitinen et al., 1994; Näätänen et al., 1997). Furthermore, with regard to pho-
1304
MÄKELÄ ET AL.
netic invariance, the N1m latency behavior indicates
that the large variance due to changes in F0 is effectively canceled out, or filtered, via a constant-latency
brain process related to speech categorization.
As both the right and the left hemispheric responses
were of equal amplitude, our results corroborate our
previous observations (Alku et al., 2001) and suggest
that sensory analyses of constant-frequency sounds in
the unattended condition might not make use of the
hemisphere-specific processes involved in analyzing
more complex speech stimuli in various experimental
settings (Zatorre et al., 1992; 2002; Zatorre and Belin,
2001; Belin et al., 2000; Roberts et al., 2000; Shtyrov et
al., 2000; Gandour et al., 1998; Poeppel et al., 1996,
1997; Schwartz and Tallal, 1980). Furthermore, the
present observations suggest that within each hemisphere, sensory analysis of pure tones and speech
sounds takes place in the same cortical area. Whether
this area is the primary auditory cortex (the medial
portion of the Heschl’s gyri; Hari et al., 1980; Alho,
1995; Shreiner et al., 2000; Crottaz-Herbette and
Ragot, 2000) or the secondary auditory areas in the
immediate vicinity of the primary area (the anterolateral portions of the Heschl’s gyri and planum temporale; Johnsrude et al., 2000; Binder et al., 2001; Jäncke
et al., 2002) remains to be established, probably
through the combination of structural imaging, hemodynamic, and electromagnetic brain research tools
(MRI, fMRI, and MEG/EEG).
While pure tones have proven to be useful in revealing certain basic properties of the auditory cortex, such
as tonotopic (Romani et al., 1982) and amplitopic (Pantev et al., 1989) organization, the approach used in
previous research might not be suitable for helping us
to understand the speech-related skills the human
brain has developed over the evolutionary time scale.
For example, with regard to the demonstrations of
N1m latency variation for low-frequency pure tones
(Crottaz-Herbette and Ragot, 2000; Roberts et al.,
2000; May et al., 1999; Ragot and Lepaul-Ercole, 1996),
the human brain, accustomed to dealing with speechspecific F0 and F1–F2 parameter spaces, might consider “simple” sinusoids so unusual and difficult that
processing latency delays up to 50 ms (Roberts and
Poeppel, 1996) have been observed.
The two speech sounds of the present study were,
nevertheless, treated similarly by auditory cortex. This
can be attributed to the presence of the F0 and its
harmonics in both sounds. Conversely, the different
treatment given to speech sounds and pure tones can
be explained by their spectral discrepancies: As the
spectrum of high-pitched speech is characterized by a
sparse harmonic structure, a major portion of the
sound energy is located at the fundamental while the
upper harmonics are attenuated (due to the large distance between integer multiples of F0). Consequently,
there is a large spectral similarity between high-
pitched speech sounds and pure tones. However, in the
case of voices of moderate or low pitch, there is a large
spectral discrepancy between a speech sound and a
pure tone of an equal F0. A low-pitched speech sound,
in addition to containing a strong frequency component
at F0, also comprises the harmonics whose amplitudes
are close to the amplitude of F0 due to the short frequency distance between the harmonics.
To summarize, variations in F0 can be used to demonstrate that speech and nonspeech sounds are distinguished from one another at a very early stage of
cortical processing. Furthermore, as this speech-specific cortical processing can be attributed to the acoustic properties of natural speech, determined by the
anatomy and functioning of the human sound-production apparatus, it becomes obvious that speech production and perception are inseparably linked. These
properties and their conjunctions, peculiar to the species-specific ability of humans to produce and understand spoken language, should be taken into careful
consideration in future speech perception studies.
ACKNOWLEDGMENTS
This research was supported by the Academy of Finland, the
University of Helsinki, and the Jenny and Antti Wihuri Foundation.
We thank Mr. C. Bailey, Mr. S. Monto, and Prof. G. Nyman for their
help in the preparation of the manuscript.
REFERENCES
Alho, K. 1995. Cerebral Generators of Mismatch Negativity (MMN)
and its magnetic counterpart (MMNm) elicited by sound changes.
Ear Hearing 16: 38 –51.
Alku, P., Sivonen, P., Palomäki, K., and Tiitinen, H. 2001. The
periodic structure of vowel sounds is reflected in human electromagnetic brain responses. Neurosci. Lett. 298: 25–28.
Alku, P., Tiitinen, H., and Näätänen, R. 1999. A method for generating natural-sounding stimuli for cognitive brain research. Clin.
Neurophys. 110: 1329 –1333.
Belin, P., Zatorre, R. J., Lafaille, P., Ahad, P., and Pike, B. 2000.
Voice-selective areas in human auditory cortex. Nature 403: 309 –
312.
Binder, J. R., Frost, J. A., Hammeke, T. A., Bellgowan, P. S. F.,
Springer, J. A., Kaufman, J. N., and Possing, E. T. 2000. Human
temporal lobe activation by speech and nonspeech sounds. Cereb.
Cortex 10: 512–528.
Bolinger, D. 1989. Intonation and Its Uses: Melody in Grammar and
Discourse, Stanford Univ. Press, Stanford.
Corballis, M. C. 1998. Cerebral asymmetry: Motoring on. Trends
Cogn. Sci. 2: 152–157.
Crottaz-Herbette, S., and Ragot, R. 2000. Perception of complex
sounds: N1 latency codes pitch and topography codes spectra. Clin.
Neurophys. 111: 1759 –1766.
Dehaene-Lambertz, G. 1997. Electrophysiological correlates of categorical phoneme perception in adults. NeuroReport 8: 919 –924.
Dehaene-Lambertz, G., and Dehaene, S. 1994. Speed and cerebral
correlates of syllable discrimination in infants. Nature 370: 292–
295.
Eimas, P. D., Miller, J. L., and Jusczyk, P. W. 1987. In Categorical
Perception (S. Harnad, Ed.), pp. 161–188. Cambridge Univ. Press,
New York.
SPEECH F0 AND CORTICAL DYNAMICS
Fant, G. 1970. Acoustic Theory of Speech Production. Mouton, The
Hague.
Gandour, J., Wong, D., and Hutchins, G. 1998. Pitch processing in
the human brain is influenced by language experience. NeuroReport 9: 2115–2119.
Hämäläinen, M., Hari, R., Ilmoniemi, R. J., Knuutila, J., and Lounasmaa, O. V. 1993. Magnetoencephalography: Theory, instrumentation, and applications to noninvasive studies of the working
human brain. Rev. Mod. Phys. 65: 413– 497.
Hari, R., Aittoniemi, K., Järvinen, M.-L., Katila, T., and Varpula, T.
1980. Auditory evoked transient and sustained magnetic fields of
the human brain. Exp. Brain. Res. 40: 237–240.
Jäncke, L., Wüstenberg, T., Scheich, H., and Heinze, H.-J. 2002.
Phonetic perception and the temporal cortex. NeuroImage 15:
733–746.
Johnsrude, I. S., Penhune, V. B., and Zatorre, R. J. 2000. Functional
specificity in the right human auditory cortex for perceiving pitch
direction. Brain 123: 155–163.
Katz, W. F., and Assmann, P. F. 2001. Identification of children’s and
adults’ vowels: Intrinsic fundamental frequency, fundamental frequency dynamics, and presence of voicing. J. Phonetics 29: 23–51.
Kent, R. D., and Read, C. 1992. The Acoustic Analysis of Speech,
Singular, San Diego.
Kuhl, P. K., Williams, K. A., Lacerda, F., Stevens, K. N., and Lindblom, B. 1992. Linguistic experience alters phonetic perception in
infants by 6 months of age. Science 255: 606 – 608.
Liberman, A. M., and Mattingly, I. G. 1989. A specialization for
speech perception. Science 243: 489 – 494.
Liberman, A. M., and Whalen, D. H. 2000. On the relation of speech
to language. Trends Cogn. Sci. 4: 187–196.
May, P., Tiitinen, H., Ilmoniemi, R. J., Nyman, G., Taylor, J. G., and
Näätänen, R. 1999. Frequency change detection in human auditory cortex. J. Comp. Neurosci. 6: 99 –120.
Näätänen, R., Lehtokoski, A., Lennes, M., Cheour, M., Huotilainen,
M., Iivonen, A., Vainio, M., Alku, P., Ilmoniemi, R. J., Luuk, A.,
Allik, J., Sinkkonen, J., and Alho, K. 1997. Language-specific
phoneme representations revealed by electric and magnetic brain
responses. Nature 385: 432– 434.
Pantev, C., Hoke, M., Lehnertz, K., and Lütkenhöner, B. 1989. Neuromagnetic evidence of an amplitopic organization of the human
auditory cortex. Electroenceph. Clin. Neurophys. 72: 225–31.
Pantev, C., Hoke, M., Lütkenhöner, B., and Lehnertz, K. 1989. Tonotopic organization of the auditory cortex: Pitch versus frequency
representation. Science 246: 486 – 488.
Patel, A. D., and Balaban, E. 2001. Human pitch perception is
reflected in the timing of stimulus-related cortical activity. Nat.
Neurosci. 4: 839 – 844.
Poeppel, D., Phillips, C., Yellin, E., Rowley, H. A., Roberts, T. P. L.,
and Marantz, A. 1997. Processing of vowels in supratemporal
auditory cortex. Neurosci. Lett. 221: 145–148.
1305
Poeppel, D., Yellin, E., Phillips, C., Roberts, T. P. L., Rowley, H. A.,
Wexler, K., and Marantz, A. 1996. Task-induced asymmetry of the
auditory evoked M100 neuromagnetic field elicited by speech
sounds. Cogn. Brain Res. 4: 231–242.
Ragot, R., and Lepaul-Ercole, R. 1996. Brain potentials as objective
indexes of auditory pitch extraction from harmonics. NeuroReport
7: 905–909.
Rizzolatti, G., and Arbib, M. A. 1998. Language within our grasp.
TINS 21: 188 –194.
Roberts, T. P. L., Ferrari, P., Stufflebeam, S. M., and Poeppel, D.
2000. Latency of the auditory evoked neuromagnetic field components: Stimulus dependence and insights toward perception.
J. Clin. Neurophys. 17: 114 –129.
Roberts, T. P. L., and Poeppel, D. 1996. Latency of auditory evoked
M100 as a function of tone frequency. NeuroReport 7: 1138 –1140.
Romani, G. L., Williamson, S. J., Kaufman, L., and Brenner, D. 1982.
Characterization of the human auditory cortex by the neuromagnetic method. Exp. Brain Res. 47: 381–393.
Schreiner, C. E., Read, H. L., and Sutter, M. 2000. Modular organization of frequency integration in primary auditory cortex. Annu.
Rev. Neurosci. 23: 501–529.
Schwartz, J., and Tallal, P. 1980. Rate of acoustic change may
underlie hemispheric specialization for speech perception. Science
207: 1380 –1381.
Shtyrov, Y., Kujala, T., Lyytinen, H., Ilmoniemi, R. J., and Näätänen, R. 2000. Auditory cortex evoked magnetic fields and lateralization of speech processing. NeuroReport 11: 2893–2896.
Studdert-Kennedy, M., and Shankweiler, D. 1970. Hemispheric specialization for speech perception. J. Acoust. Soc. Am. 48: 579 –594.
Tian, B., Reser, D., Durham, A., Kustov, A., and Rauschecker, J. P.
2001. Functional specialization in Rhesus monkey auditory cortex.
Science 292: 290 –293.
Tiitinen, H., May, P., Reinikainen, K., and Näätänen, R. 1994. Attentive novelty detection in humans is governed by pre-attentive
sensory memory. Nature 372: 90 –92.
Titze, I. 1994. Principles of Voice Production, Prentice Hall, NJ.
Uutela, K., Hämäläinen, M., and Somersalo, E. 1999. Visualization
of magnetoencephalographic data using minimum current estimates. NeuroImage 10: 173–180.
Vihla, M., Lounasmaa, O. V., and Salmelin, R. 2000. Cortical processing of change detection: Dissociation between natural vowels
and two-frequency tones. Proc. Natl. Acad. Sci. USA 97: 10590 –
10594.
Zatorre, R. J., and Belin, P. 2001. Spectral and temporal processing
in human auditory cortex. Cereb. Cortex 11: 946 –953.
Zatorre, R. J., Belin, P., and Penhune, V. B. 2002. Structure and
function of auditory cortex: Music and speech. Trends Cogn. Sci. 6:
37– 46.
Zatorre, R. J., Evans, A. C., Meyer, E., and Gjedde, A. 1992. Lateralization of phonetic and pitch discrimination in speech processing. Science 256: 846 – 849.