H-SWD: Incorporating Hot Data Identification into Shingled Write Disks
advertisement

H-SWD: Incorporating Hot Data Identification into
Shingled Write Disks
Chung-I Lin, Dongchul Park, Weiping He and David H.C. Du
Department of Computer Science and Engineering
University of Minnesota–Twin Cities
Minneapolis, MN 55455, USA
Email: {chungli, park, weihe, du}@cs.umn.edu
Abstract—Shingled write disk (SWD) is a magnetic hard
disk drive that adopts the shingled magnetic recording (SMR)
technology to overcome the areal density limit faced in conventional hard disk drives (HDDs). The SMR design enables
SWDs to achieve two to three times higher areal density than
the HDDs can reach, but it also makes SWDs unable to support
random writes/in-place updates with no performance penalty.
In particular, a SWD needs to concern about the random
write/update interference, which indicates writing to one track
overwrites the data previously stored on the subsequent tracks.
Some research has been proposed to serve random write/update
out-of-place to alleviate the performance degradation at the cost
of bringing in the concept of garbage collection. However, none
of these studies investigate SWDs based on the garbage collection
performance.
In this paper, we propose a SWD design called Hot data
identification-based Shingled Write Disk (H-SWD). The H-SWD
adopts a window-based hot data identification to effectively
manage data in the hot bands and the cold bands such that
it can significantly reduce the garbage collection overhead while
preventing the random write/update interference. The experimental results with various realistic workloads demonstrates that
H-SWD outperforms the Indirection System. Specifically, incorporating a simple hot data identification empowers the H-SWD
design to remarkably improve garbage collection performance.
Keywords-Shingled Magnetic Recording, SMR, Shingled Write
Disk, SWD, Garbage collection, H-SWD.
I. Introduction
Digital data has grown dramatically from 281 EB (an
exbytes equals 109 GB) in 2007 to 1.8 ZB (a zettabyte
equals 1012 GB) in 2011 [1]. This digital data explosion
has stimulated the research on continuously increasing hard
disk drives (HDDs) capacity. As a result, HDDs capacity
has steadily increased over the past few decades. However,
magnetic HDDs face areal density upper limit due to the
super-paramagnetic effect [2], which is an critical challenge
in magnetic recording. The super-paramagnetic effect indicates
that magnetic grain volume should be large enough to satisfy
the media signal-to-noise ratio, write-ability, and thermal stability properties, which are the main reasons that conventional
magnetic recording fails to extend areal density more than 1
Tb/in2 [3].
HDDs are the most popular storage devices due to their
large capacity and low cost. Although NAND flash-based Solid
State Drives (SSDs) have attracted considerable attentions for
their ability to replace HDDs in many applications [4], [5], the
price is still five to ten times more expensive than HDDs and
grows enormously as storage capacity increases. In addition,
the digital data explosion demands a huge amount of storage
space. These facts ensure that HDDs still retain their own
merits against SSDs and serve as an important component
in diverse applications. Consequently, the storage capacity of
HDDs has grown continuously with the help of advanced
technologies, but they now face the areal density upper limit
due to the super-paramagnetic effect [6]. To overcome HDD
space limitation, Microwave Assisted Magnetic Recording
(MAMR) [7], Heat Assisted Magnetic Recording (HAMR) [8],
[9], [10], Bit-Patterned Media Recording (BPR) [11], [12] and
Shingled Magnetic Recording (SMR) [13], [14], [15] have
been proposed. Out of these advanced magnetic recording
technologies, SMR is the most promising method as it does not
require a significant change of the existing magnetic recording
HDD makeup and write head [16]. In particular, SMR breaks
the tie between write head width and track width to increase
track density with no impact on cost and written bits stability.
A Shingled Write Disk (SWD) is a magnetic hard disk
drive that adopts SMR technology so that it also inherits
the most critical issue of SMR: writing to a track affects
the data previously stored on the shingled tracks. This issue
results from its wider write head and the partially overlapped
track layout design. Furthermore, it makes SWDs support
only the archive/backup systems. However, users might still
be interested in purchasing SWDs for general applications if
they prefer to have much larger capacity. As a result, to both
maximize SWD benefits and broaden SWD applicability, it is
mandatory to have a proper treatment for random write/update
issue to protect data integrity. One naive method is the readmodify-write operation. As discussed in [17], this method
significantly degrades SWD performance in that every random
writes/updates might incur multiple read and write operations.
Therefore, the challenging issue is to propose a SWD design
that can support the random writes/updates under the limitation
of SMR distinct write behavior (i.e., it overwrites subsequent
shingled tracks).
To mask possible performance degradation due to the random writes/updates, current SWD designs typically adopt outof-place updates [17], [6]. Specifically, when an update is
issued, the SWD invalidates the old data blocks and writes the
updated data to other clean (i.e., free) blocks. Although doing
so prevents in-place update performance impacts, it requires
an address mapping table to store the physical block address
(PBA) and logical block address (LBA) mapping information. In particular, the out-of-place update method generates
numerous invalid data blocks on the SWD and reduces the
number of clean blocks over time. Therefore, we need a
special reclamation mechanism (so-called, garbage collection)
to reuse the invalid block. Moreover, none of the existing
works considers garbage collection (GC, hereafter) efficiency
even though it is critical to the overall SWD performance.
In this paper, we propose a SWD design called Hot data
identification-based Shingled Write Disk (H-SWD) to both
mask the random writes/updates performance penalty and improve the garbage collection efficiency. We utilize a windowbased hot data identification to distribute the data to hot bands
or cold bands accordingly. The main contributions of this paper
are as follows:
• An effective data placement policy: Effective incoming
data placement can have considerable impact on the SWD
performance. Our design is inspired by this intuition. HSWD employs a hot and cold data identification algorithm
to effectively distribute incoming data to an SWD. Thus,
it remarkably reduces valid data block movement in hot
bands.
• New garbage collection algorithms: H-SWD utilizes our
hot data identification scheme for its GC algorithm and
retains three basic GC policies. Unlike other typical GC
algorithms, H-SWD tries to reclaim not only invalid data
blocks but also valid blocks. Furthermore, we found that
there is a sharing effect among different regions of a
SWD. By employing sharing regions to serve incoming
requests, we can dynamically choose the best GC candidates with the help of our dynamic GC algorithm.
• A hot data identification for SWD: We incorporate a
simple window-based hot data identification scheme to
record information of past requests for SWD. Both our
data placement policy and GC algorithm use this hot data
identification scheme.
The remainder of this paper is organized as follows. Section II gives an overview of the magnetic recording technologies and the existing shingled write disk designs. Section III
explains the design and operations of our proposed H-SWD
design. Section IV provides a variety of our experimental
results and analyses. Section V concludes the discussion.
II. Background and Related Work
In this section, we give an overview and discuss issues
related to SMR. We also review the Indirection System, which
is proposed by Hitachi Global Storage Technologies [17].
A. Shingled Magnetic Recording
Shingled Magnetic Recording (SMR) can provide two to
three times higher areal density than traditional HDDs without
dramatically changing the makeup and the write head of
current HDD designs. As revealed in [17], [16], [6], SMR
adopts a shingled track design to increase the areal density.
track N
track N+1
Trailing Shield
track N+2
track N+3
Main
Pole
Side Shield
Track
width
Write Direction
write track
Fig. 1.
Shingled writes. Shingled writes overwrite subsequent tracks [16].
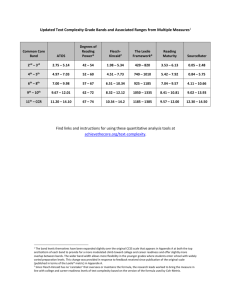
Figure 1 [16] demonstrates that writing data to N+1-th track
overwrites data stored on N+2-th and N+3-th tracks at the
same time because the write head covers multiple tracks. For
simplicity, the special writing behavior can be referred as
write interference, which is the main reason that makes SMR
performance suffer from random writes/in-place updates.
A shingled write disk (SWD) integrates traditional HDDs
with the SMR technology. As a result, it inherits the SMR
characteristics including the write interference, which limits
the applicability of SWDs. A naive method, which has been
discussed by Yuval et al. in [17], is read-modify-write operation under a multiple shingled regions layout. Although
the method can prevent the write interference; however, it
introduces a possibly higher performance overhead and creates
a trade-off between performance impacts and space overhead [17], which might worth further investigations. Rather
than serving random writes/updates in-place, out-of-place
method has been proposed [17], [16], [6]. With the insightful
design, which is analogous to SSD designs, not only the write
interference can be prevented but also performance impact
can be reduced. However, the design requires a mapping
table to store the mapping between physical block addresses
(PBAs) and logical block addresses (LBAs). A GC algorithm
is necessary since out-of-place methods create invalid blocks.
Furthermore, most of the existing SWD layouts adopt a
circular log structure to manage each region [17], [6].
Amer et al. [16] explored general issues in designing
shingled write disks and focused on how to integrate SWD
into storage systems and applications. In their paper, a SWD
is divided into log access zones (LAZs) and random access
zones (RAZs). A LAZ contains shingled tracks while a RAZ
contains single tracks. In particular, RAZs store metadata
while LAZs store other data. Zones are separated by interband gaps. Furthermore, an intra-band gap is maintained in
each zone. The authors also provided a high-level description
about hot/cold data concepts along with hierarchical circular
logs. However, they do not provide concrete GC algorithms.
B. Indirection System
III. H-SWD Design
This section describes our hot data identification-based
shingled write disk (H-SWD) design.
A. The block layout
Since shingled write disks (SWDs) cannot support random
writes/updates in-place efficiently in its own hardware level,
a data block layout in the system software level becomes
necessary. There are a few possible SWD block layouts [17],
[16], [6] including non-shingled regions (RAZs), circular log,
Fig. 2. The block layout of the H-SWD. To support random writes/updates,
the H-SWD adopts a circular log layout [16].
Address
Mapping
Garbage
Collection
Algorithm
Hot Data
Identification
H-SWD
...
Section 1
Cold Band
Cold Band
Tail Head
Hot Band
Yuval et al. [17] proposed two Indirection Systems. We
mainly review their second design as it provides more smooth
throughput. For simplicity, we refer to their second design as
the Indirection System hereafter.
The Indirection System [17] serves random writes/updates
out-of-place. It divides the entire disk space into multiple
sections. Each section is in charge of a fixed range of consecutive LBAs and contains a cache buffer and a S-Block
buffer, which are separated by an inter-band gap (to prevent
write interference between buffers). Cache buffers and S-Block
buffers all use the storage space of a SWD. Each buffer is
managed as a circular log with a head and a tail pointers.
The distance from head to tail is defined as the number of
PBAs that will be affected by the SWD write interference.
After briefly discussing the Indirection System block layout,
we review their data placement and GC algorithms as follows.
• Data placement: The Indirection System always stores an
incoming write to the head of a cache buffer. No data can be
written to any S-Block buffer directly. When a cache buffer is
filled up with valid blocks (i.e., contains no invalid block), the
Indirection System will migrate a full S-Block to a S-Block
buffer. In particular, if a S-Block contains enough invalid
blocks, it will be updated with the cached data and be moved
to the head of the S-Block buffer. Certainly, the associated
data in the cache buffer will be invalidated accordingly.
• Garbage collection algorithms: The Indirection System
proposed three GC algorithms: the cache buffer defrag, the
group destage and the S-Block buffer defrag. One of the
three GC algorithms will be invoked depending on the utilization of a cache buffer or a S-Block buffer. The details of
the Indirection System GC algorithms are in their paper [17].
Furthermore, a circular log is maintained for each buffer. If
the tail points to a valid block, a GC operation will move the
pointed block to the head position. Otherwise, the tail-pointed
block is invalid and can simply be freed without any explicit
performance overhead.
The Indirection System provided a detailed SWD design
including the block layout, the data placement policy and
the GC algorithms. However, due to its data placement and
GC algorithms, it suffers from significant GC overhead and
affects overall SWD performance. Based on this observation,
we proposed a SWD design, H-SWD, to improve SWD
performance by incorporating a hot data identification for data
placement and GC algorithms.
Intra-band Gap
...
Section 2
...
Inter-band Gap
...
Section N
Fig. 3. Logical view of H-SWD architecture. Each section works independently, which means it can be treated as multiple independent drives.
and flexible regions. Out of the existing block layout designs,
we simply adopt a circular log block layout, which is identical
to what has been proposed in [17], [16], [6]. Figure 2(a) gives
a SWD block layout with a circular log while Figure 2(b)
displays a logical view of the block layout with a circular log
for convenience. A region contains multiple shingled tracks,
which are separated by intra/inter-band gaps to prevent the
write interference. Two pointers, head and tail, are maintained
in each band. Furthermore, any incoming data is assigned to
the head, while removing data for a GC operation is launched
at the tail. Specifically, H-SWD uses fixed size bands and the
number of bands is configurable based on the entire SWD disk
space as well as the ratio of hot bands to cold bands.
B. Architecture
Figure 3 gives an overview of our H-SWD design. H-SWD
divides the entire disk space (including over-provisions) into
hot bands and cold bands. Each band consists of multiple
data tracks. We initially assign 1% over-provision to the hot
bands and the whole SWD storage capacity is served as cold
bands (identical to the Indirection System). A hot band can
be associated with multiple cold bands and this unit is called
a section. Similar to the Indirection System, a full range of
LBAs in the disk is divided into the number of sections in the
H-SWD and each section can be independently managed.
H-SWD maintains two types of guard gaps, inter-band
gap and intra-band gap, to meet the requirement of write
interference: each band is separated by a specific number of
tracks (called a guard gap), as proposed in [16], [6]. As a
result, writing to the last track in a band does not dilapidate
the data in the first track of the neighboring band. Both hot
bands and cold bands are logically managed as a circular log
with a tail and a head pointer. In addition, both pointers move
forward accordingly while satisfying the head-tail proximity
(i.e., block interference profile) requirement [17]. Each hot
band is associated with its corresponding multiple cold bands.
The main idea of H-SWD is to classify incoming data into
hot data and cold data by employing a hot data identification
scheme. Thus, a hot data identification system is one of our
main components in the architecture. Unlike the Indirection
System in which all incoming data must be stored in the cache
buffer, our H-SWD first classifies the data and assigns them
to hot/cold bands accordingly. Furthermore, since we adopt an
out-of-place update design, we need to map LBAs to PBAs
in SWDs. We assume block-level (i.e., sector-level) mapping
and the mapping table can reside in SWD or Non-Volatile
Memory (NVRAM). Lastly, GC algorithms are very important
components in a SWD design because SWD is required to
effectively reclaim invalidated data blocks to accommodate
incoming writes. This GC overhead severely affects the overall
performance.
Algorithm 1 An Intra-Band GC Algorithm
Function Intra-Band GC()
1: if (Block utilization ≥ GC THRESHOLD ) then
2: while Free space < RECLAIM THRESHOLD do
3:
if (Valid(tail)) then
4:
Move the data to the head
5:
head = head + 1
6:
else
7:
Free the block in the tail.
8:
Increase the Free space.
9:
end if
10:
tail = tail + 1
11: end while
12: end if
Algorithm 2 A Normal GC Algorithm
Function Normal GC()
C. System Algorithms
1: if (Block utilization ≥ GC THRESHOLD ) then
2: while Free space < RECLAIM THRESHOLD do
3:
if (Valid(tail)) then
4:
if (IsCold(tail)) then
5:
Move the data to a cold band.
6:
Free the block.
7:
Increase the Free space.
8:
else
9:
Move the data to the head.
10:
head = head + 1
11:
end if
12:
else
13:
Free the block in the tail.
14:
Increase the Free space.
15:
end if
16:
tail = tail + 1
17: end while
18: end if
• Hot data identification: A hot data identification is adopted
by our GC algorithm as well as the data placement policy
in H-SWD. Since the definition of hot data can be different
for different applications, we need to design our own hot and
cold data identification system instead of adopting existing
algorithms. Our scheme employs an window concept. This
window stores past LBA requests and can represent temporal
locality. If any data access displays high temporal locality,
it is highly possible that the data will be accessed again in
the near future. If any incoming data appears in this window
at least once, we define the data as hot; otherwise, they are
classified as cold data. This static scheme can be replaced with
a dynamic scheme which dynamically changes the hot data
definition based on the workload characteristics. The dynamic
scheme may be able to improve our H-SWD performance;
however, it definitely requires more resources for its learning
process.
• Data placement: One of our key ideas lies in the data
placement policy. Unlike other SWD designs, on receiving a
write request, the H-SWD first makes an attempt to classify the
incoming data into hot or cold data. If the data is identified as
hot (by using hot data appearance in the window), it is stored
at the head position a hot band. Otherwise, it is assigned to the
head in a cold band. The main objective of our incoming data
placement policy is to collect these frequently reaccessed data
(hot data) into the same band to increase the GC efficiency.
Thus, many of the data in the hot bands are expected to
be accessed again soon, which produces a higher number of
invalid data blocks in the hot bands. As a result, the number of
valid data block movements from the tail position to the head
position can be significantly reduced during the GC process.
Consequently, this simple and smart policy can dramatically
improve the GC performance.
• Garbage collection algorithms: A GC algorithm is important to the shingled magnetic recording (SMR) technology.
This reclamation process is mostly executed on hot bands due
to frequent data updates and limited space. H-SWD adopts our
hot data identification for GC and applies a different policy
to hot bands and cold bands respectively. Unlike typical GC
algorithms in other designs, H-SWD tries to reclaim not only
the invalid blocks but also the valid blocks if they become cold.
This special policy can help H-SWD to reduce unnecessary
cold block movements.
The H-SWD maintains three basic GC policies: an intraband GC, normal GC, and forced GC. These fundamental
polices are exploited by both hot bands and cold bands. The
intra-band GC reads a block in the tail position of a band
and checks if it is valid (i.e., live) or invalid (i.e., outdated).
If it is a valid block, it is moved to the head in the band.
Otherwise, it is freed. Lastly, both pointers (head and tail)
move forward by one accordingly (Algorithm 1). The normal
GC is a fundamental GC policy in the H-SWD design. This
includes the aforementioned intra-band GC and adds one more
policy: it tries to reclaim valid data blocks. In other words,
when a tail pointer reaches a valid block, the H-SWD checks
whether the corresponding data is hot or not. If the data is
identified as hot, it moves the block to the head and both the
head and tail proceed to the next position (intra-band GC).
Algorithm 3 A Forced GC Algorithm
Function Forced GC()
1: while Free space < RECLAIM THRESHOLD do
2: if (Valid(tail)) then
3:
Move the data to a cold band.
4: end if
5: Free the block.
6: Increase the Free space.
7: tail = tail + 1
8: end while
Algorithm 4 A GC Algorithm for Hot Bands
Function Hot Band GC()
1: GC THRESHOLD = 80%
2: DELAY GC THRESHOLD = 95%
3: RECLAIM THRESHOLD = 10%
4: if (Block utilization ≥ GC THRESHOLD ) then
5: if (Invalid blocks ≥ RECLAIM THRESHOLD ) then
6:
while Free space < RECLAIM THRESHOLD do
7:
Normal GC()
8:
end while
9: else
10:
if (Block utilization ≥ DELAY GC THRESHOLD ) then
11:
while Free space < RECLAIM THRESHOLD do
12:
if (Invalid blocks > 0) then
13:
Normal GC()
14:
else
15:
Forced GC()
16:
end if
17:
end while
18:
end if
19: end if
20: end if
amount of free space after a GC operation. Otherwise, it cannot
guarantee that the H-SWD will obtain the predefined amount
of free space since all valid data blocks still can be defined
as hot data during the GC process. Even though the H-SWD
could achieve a required amount of free space by executing the
normal GC, it would necessarily cause it to move some valid
blocks from the hot band to the cold band. Therefore, in this
case, the H-SWD delays this hot band GC even if the hot band
block utilization reaches or exceeds the utilization limit since
some of the hot blocks in the hot bands are likely to be updated
soon (This would increase the number of invalid blocks in the
band). If the hot blocks finally cannot meet the requirement
(in the worst case), it triggers the forced GC process.
Unlike the Indirection System, our GC algorithm obtains
multiple (initially 10% of a band size) free blocks whenever a
GC is invoked. Unlike the hot bands, cold bands have enough
spaces to accommodate the incoming data and contain (possibly) cold data; thus, in most cases, they will not frequently
invoke a GC. As a result, the cold bands perform intra-band
GC on cold bands if necessary.
IV. Experimental Results
This section provides diverse experimental results and comparative analyses.
A. Evaluation Setup
Otherwise, it moves the block from the hot band to the cold
band and frees the pointed data (Algorithm 2).
The forced GC is a more aggressive GC policy, which will
be invoked only when the H-SWD cannot prepare a specified
amount of free space even after the normal GC processes. For
instance, when a band does not contain enough invalid blocks
and all (or almost all) valid blocks retain hot data, the forced
GC is triggered as follows: the H-SWD chooses a required
number of blocks starting from the head and migrates them to
a cold band whether they are hot data or not (Algorithm 3).
However, since this is an extreme case, the H-SWD very rarely
encounters such a chance to invoke this GC in most realistic
environments. In fact, we did not observe this situation in any
of our experiments with diverse realistic workloads.
Based on these basic GC policies, the GC for hot bands invokes a normal GC and a forced GC algorithm. The hot bands
maintain both a high watermark and low watermark indicating
when to invoke and stop the algorithm respectively. Overall,
the GC policy is as follows: if a hot band block utilization
reaches 80%, the H-SWD starts to reclaim invalid blocks by
triggering a normal GC algorithm until it provides a specific
amount of free space (initially 10%). The block utilization
of a band is defined as (Valid block # + Invalid block #) /
(Valid block # + Invalid block # + Free block #). Algorithm 4
describes our main GC policy in detail for a hot band. When
a block utilization of a hot band reaches 80%, the H-SWD
invokes this GC algorithm. If the hot band retains enough
invalid blocks (10%), the H-SWD performs a normal GC
because it guarantees that the H-SWD can obtain a predefined
We choose the Financial-1 and three Microsoft research
(MSR) traces including prxy volume 0, rsrch volume 0 and web
volume 0. The Financial-1 trace is an On-line Transaction Processing (OLTP) application trace collected at the University of
Massachusetts at Amherst Storage Repository [18]. The MSR
traces were collected by the Microsoft Research Cambridge
Lab [19], where each trace demonstrates different workload
characteristics. In particular, we consider write requests since
only write requests might increase the number of invalid
blocks and trigger a GC operation. Furthermore, if a request
size is greater than 1, we will split the request into multiple
requests of size 1, as adopted in [20], [21]. For example, if
there is a request writing 7 blocks, we will split the request into
7 requests, each of which writes distinct block. The Table I
shows that the update ratio of the first 1,800K write requests
in each trace is higher than 55% (each request has been split
into size of one block).
TABLE I
Workload Characteristics (K = 1,000 Requests)
Traces
Number of writes
Write size (# of sectors)
Update %
Financial1
1,800K
1,800K
55.4%
Prxy0
1,800K
1,800K
85.6%
Rsrch0
1,800K
1,800K
84.8%
Web0
1,800K
1,800K
61.1%
The Indirection System and the H-SWD simulators have
been implemented. The underlying storage capacity contains
108 blocks (A block equals 512 bytes), which equals 51.2 GB.
Although 51.2 GB does not represent the real SWD capacity
(since current HDDs can already provide 3 TB storage space);
however, the simulations still proportionally demonstrate a
The window size for the hot data identification is 4,096
(4K) initially. The H-SWD requires this window to store the
past logical block address (LBA) information (only LBA will
be recorded). The first 4,096 requests are considered as hot
since the window does not contain enough LBA information
for identification. Then, if an incoming request appears in the
window at least once, it will be identified as hot. Otherwise, it
is cold. After the request has been identified, the oldest LBA
will be removed from and the latest LBA will be stored to the
window accordingly.
More importantly, we need to consider GC parameters
including when to start (the starting threshold, hereafter) or
when to stop (the stopping threshold, hereafter) a GC operation. We first vary the starting threshold of band utilization
from 70% to 90% and fix the stopping threshold at 10%,
which means a GC operation will stop after it free 10% of
band size. We then vary the stopping from 10% to 30% and
fix the starting threshold at 80%. In this simulation, the HSWD divides the underlying storage space into 20 sections
equally. Since the simulation results of other traces show
very similar patterns, we only demonstrate the Financial-1
trace simulation results (see Figure 4. We can observe that
there is no significant difference in block movements under
different starting thresholds. In particular, adjusting the starting
threshold only changes the occurrence of the block movement
peaks.
We assume that the H-SWD contains 20 sections. To
observe the impact on the GC overhead due to different
starting threshold, we vary the starting threshold from 70%
to 90% while fixing the stopping threshold as 10%. Figure
4 demonstrates the block movements of the four traces under
various GC starting thresholds setup. As shown in Figure 4(a),
adjusting the starting threshold only changes the occurrence
of the block movement peaks (peak, hereafter) since GC
operations are initiated at different occasions. Figure 4(b)
shows the block movements of Financial-1 trace under various
GC stopping thresholds. We observed that when the stopping
threshold increases, the peaks is higher while the number of
the peaks reduce, which fits the intuition. Furthermore, from
the SWD performance point of view, to flatten the peak is
preferred since a higher peak implies a longer delay a SWD
needs to wait for GC operations.
40
35
30
25
20
15
10
5
0
70%
80%
90%
0
2
4
6
8
10 12
Write Requests (Unit:1,500K)
Block Movement (Unit:10K)
Block Movement (Unit:10K)
SWD performance under various traces considering the ratio
of the total write size to the underlying storage capacity. The
same 2% over-provisions are provided in the H-SWD design
and distributed to the hot bands and cold bands equally (the
assignment is identical to the Indirection System). A S-block
contains 2,000 blocks, as simulated in [17]. Furthermore, we
also maintain the intra-band gaps and inter-band gaps for
guarding purpose as proposed in [16], [6]. Therefore, the block
layout of the H-SWD matches that of the Indirection System,
which saves us from comparing the space overhead between
the Indirection System and our design. For each band, one
track is assumed to serve as an intra-band gap (a track contains
500 sectors).
40
35
30
25
20
15
10
5
0
10%
20%
30%
0
2
4
6
8
10 12
Write Requests (Unit:1,500K)
(a) Varying Starting GC Thresholds (b) Varying Stopping GC Thresholds
Fig. 4. The Number of Block Movement under Various Starting and Stopping
GC Thresholds of Financial-1 Trace.
B. Performance Metrics
The GC performance is very important to the overall system
performance. We measure the number of block movements. A
block movement means that a valid block is moved a different
position in a SWD due to a GC operation, which requires a
read, a seek, and a write to finish. Furthermore, if a SWD
design requires more block movements than other designs,
it tends to suffer from performance degradation due to the
GC overhead. In this respect, the number of block movement
can be used as a good interpretation for the overall SWD
performance as well as the GC overhead. To further understand
the GC efficiency, we periodically measure the valid block
ratio every 900K write requests (K equals 1,000). We compute
a valid block ratio as follows: Valid block # / (Valid block #
+ Invalid block #).
The hot false identification counts and cold false identification counts are used to relate the window-based hot data
identification prediction accuracy to the H-SWD performance.
The false identification count means that there is a discrepancy
between the previous and the current identifications. Specifically, hot data false identification indicates that a LBA is hot
in previous identification while it becomes cold in current
identification. In this case, we view previous identification
result as a hot false identification. Cold false identification
count is obtained in the same way.
C. Results and Analysis
We discuss our experimental results in diverse aspects.
• Indirection System Performance: We first investigate
the Indirection System performance by varying the number of
sections. Each section equally shares the underlying storage
capacity (51.2 GB) and 2% over-provisions (1% for cache
buffers and 1% for S-Block buffers). For simplicity, each section contains a cache buffer and a S-Block buffer. Therefore,
the more sections we simulate, the smaller space a section
can have. Furthermore, the underlying storage is initiated as
empty. The largest-number-of-cached-blocks policy is adopted
for group destage, which is proposed in [17]. The largestnumber-of-cached-blocks policy will migrate a S-Block that
contains the largest number of cached blocks from a cache
buffer to a S-Block buffer.
Figure 5(a) demonstrates that the Financial-1 trace presents
similar GC overhead under various section configurations.
Figures 5(b), 5(c) and 5(d) demonstrate that the overall block
1e+09
1e+09
1e+08
1e+08
1e+07
1e+07
5 Sec
10 Sec
15 Sec
20 Sec
25 Sec
1e+06
100000
0
5
10
5 Sec
10 Sec
15 Sec
20 Sec
25 Sec
1e+06
100000
15
20
0
5
Block Movement
(a) Financial 1
1e+09
1e+08
1e+08
100000
0
5
10
(c) Rsrch 0
Block Movement
1e+06
100000
100000
10000
100
0
5
10
1000
100
15
20
0
5
(a) Financial 1
1e+09
1e+08
1e+08
1e+07
15
20
15
20
1e+07
IS
HSWD
1e+06
IS
HSWD
1e+06
100000
100000
10000
10000
20
10
(b) Prxy 0
1e+09
1000
0
15
IS
HSWD
10000
IS
HSWD
1000
5 Sec
10 Sec
15 Sec
20 Sec
25 Sec
100000
Write Requests (Unit:900K)
1e+07
1e+06
5
10
15
20
0
Write Requests (Unit:900K)
5
10
Write Requests (Unit:900K)
20
(d) Web 0
Fig. 6. The Number of Block Movements of Indirection System and H-SWD
under Various Traces.
1e+06
15
1e+08
1e+07
(c) Rsrch 0
1e+07
5 Sec
10 Sec
15 Sec
20 Sec
25 Sec
1e+06
1e+09
1e+08
(b) Prxy 0
1e+09
1e+07
10
1e+09
1000
Block Movement
Block Movement
movements reduce after we increase the number of sections.
The experiment results prove that a small section size can
give an upper bound to the GC operation. However, we also
observed that the block movements increase when the number
of sections increases to 25 sections. Such pattern occurs
because the size of cache buffer becomes too small to buffer
for the sections that are write-intensive.
0
5
10
15
20
Write Requests (Unit:900K)
(d) Web 0
cache buffer and only moves data from a cache buffer to a Sblock buffer when a cache buffer is full of valid blocks. some
cold data remains in cache buffers and continues to affect the
overall GC efficiency.
1.2
1.2
1
1
0.8
IS
HSWD
0.8
IS
HSWD
0.6
0.6
0.4
0.4
0.2
0.2
0
0
0
5
10
15
20
0
5
(a) Financial 1
1.2
Valid Block Ratios
• H-SWD vs. Indirection System: We compare our HSWD and the Indirection System. We use 20 sections as the
Indirection System layout since it provides a better GC performance. For fairness, the H-SWD utilizes the same sections
configuration (i.e., 20 sections). Each section contains a pair
of a hot band and a cold band, whose size are identical to the
cache buffer size and S-Block size respectively. We set 4,096
as the window size. Furthermore, a GC operation starts when
a band reaches 80% utilization and stops after it frees 10%
band size.
Figure 6 demonstrates that our H-SWD significantly reduces
the required block movements due to GC operations. Because
H-SWD selectively store data to hot bands and cold bands
based on hot data identification result, data in hot bands is
prone to be updated frequently. Although grouping hot data
into hot bands increases the GC frequency; however, H-SWD
does not introduce higher GC overhead since a SWD does not
require explicit operation to free an invalid block.
Figure 7 illustrates the valid block ratio of the Indirection
System cache buffers and H-SWD hot bands. We found that
the Indirection System has higher valid block ratio than the HSWD. Although the higher valid block ratio helps the storage
utilization; however, it also critically impacts the GC efficiency
given the fact that every valid block pointed by tail pointer
costs one block movement when performing a GC operation.
As shown in Figure 6 and 7, we can conclude that as
valid block ratio in cache buffer grows, total block movements
of the Indirection System increase dramatically. Because the
Indirection System always stores any incoming request to a
Valid Block Ratios
Fig. 5. The Number of Block Movements of Indirection System under
Various Sections and Traces.
1.2
IS
HSWD
1
10
15
20
15
20
(b) Prxy 0
IS
HSWD
1
0.8
0.8
0.6
0.6
0.4
0.4
0.2
0.2
0
0
0
5
10
15
Write Requests (Unit:900K)
(c) Rsrch 0
20
0
5
10
Write Requests (Unit:900K)
(d) Web 0
Fig. 7. Valid Block Ratio in Indirection System Cache Buffer and H-SWD
Hot Bands under Various Traces.
Figure 8 illustrates the valid block ratios of Indirection
System S-Block buffers and H-SWD cold bands. At the
beginning, both H-SWD and Indirection System provide high
valid block ratios. However, valid block ratio of Indirection
System decreases at faster speed and eventually provides
less valid block ratio than H-SWD. Note that, the reason
behind the decreasing rate of both designs is not the same.
As for Indirection System, the decreasing rate results from
group destage selection which only considers S-Block filling
ratio without using hot/cold data concept. Thus, some SBlocks being moved to S-Block buffer might still experience
frequent updates, which lead valid block ratio to decrease. As
350000
35000
2K
4K
8K
16K
300000
Block Movement
for H-SWD, the decreasing trend is due to cold data false
identification. Nevertheless, to perform a GC operation on a
band with low valid block ratio is preferred (even though GC
frequency might be increased) since invalid block can be easily
be freed without performance penalty.
250000
25000
200000
20000
150000
15000
100000
10000
50000
5000
0
1
IS
HSWD
0.8
0.6
0.4
0.4
0.2
0.2
0
5
10
15
20
0
5
(a) Financial 1
Valid Block Ratios
1
15
1
0.6
0.4
0.4
0.2
0.2
0
5
10
15
Write Requests (Unit:900K)
(c) Rsrch 0
20
5
10
15
20
15
20
(b) Prxy 0
25000
2K
4K
8K
16K
25000
20000
20000
15000
15000
10000
10000
5000
0
0
0
5
10
15
20
0
Write Requests (Unit:900K)
5
10
Write Requests (Unit:900K)
(c) Rsrch 0
(d) Web 0
Fig. 9. The Number of Block Movements of H-SWD under Various Window
Size and Traces.
0
0
0
30000
IS
HSWD
0.8
0.6
20
5000
20
(b) Prxy 0
IS
HSWD
0.8
10
15
2K
4K
8K
16K
30000
0
0
10
35000
Block Movement
0.6
5
(a) Financial 1
IS
HSWD
0
5
10
15
20
Write Requests (Unit:900K)
(d) Web 0
Fig. 8. Valid Block Ratio in Indirection System S-block Buffer and H-SWD
Cold Band Under Various Traces.
• Impact of Window Size: Another important factor to
investigate is the window size of hot data identification. Figure
9 shows that the number of block movements of the HSWD under various window size configurations and traces.
As shown in Figure 9, the number of block movement grows
as we increase the window size. Intuitively, a larger window
size implies more requests will be considered as hot. Since
the number of block movements under the current simulation
setup is dominated by hot band GC operations, the H-SWD
will introduce a higher GC overhead under larger window
size configuration. Therefore, to better understand the impact
due to different window size, we make use of hot data false
identification count and cold data false identification count.
Figure 10 and Figure 11 plot hot data and cold false
identification counts respectively. In Prxy 0 and Rsrch 0 traces,
both hot data and cold data identification counts reduce as
we increase the window size. However, in Web 0 trace, the
window size of 4K provides a better identification accuracy
than the other configurations. This is because Web 0 trace
contains more random write requests than the other traces. In
particular, only slight difference can be observed in Financial
1 trace. More importantly, we can observe hot data and cold
data false identification peaks since there are transitions in
these traces (accessing different LBA range).
From Figure 9 and Figure 10, we observed that a hot data
false identification peak usually causes a hot block movement
peak in the later write request unit. This is because our HSWD GC algorithm starts to clean old hot data (now becomes
cold due to access transition) from hot bands to cold bands.
Based on this observation, we conclude that when cold band
GC starts to dominate block movements, a larger window size
Hot False Identification Counts
0.8
0
0
160000
140000
120000
100000
80000
60000
40000
20000
0
80000
70000
60000
50000
40000
30000
20000
10000
0
2K
4K
8K
16K
0
5
10
15
20
2K
4K
8K
16K
0
5
(a) Financial 1
Hot False Identification Counts
Valid Block Ratios
1
2K
4K
8K
16K
30000
90000
80000
70000
60000
50000
40000
30000
20000
10000
0
80000
70000
60000
50000
40000
30000
20000
10000
0
2K
4K
8K
16K
0
5
10
15
Write Requests (Unit:900K)
(c) Rsrch 0
10
15
20
15
20
(b) Prxy 0
20
2K
4K
8K
16K
0
5
10
Write Requests (Unit:900K)
(d) Web 0
Fig. 10. Hot Data False Identification Counts under Various Window Size
and Traces.
setup gives better overall SWD performance since a better
identification accuracy can be provided (except for traces
containing frequent write access transitions).
• Sharing Effect: Recall that, each section is in charge
of a fixed range of LBAs so that each section can be viewed
as an independent device. This design may be able to have
a skewed data distribution to each section unless a mapping
scheme has a judicious load balancing algorithm. Based on
this observation, it might be beneficial if we can break the
association between hot bands and cold bands in each section
as such layout is more flexible than original section layout.
Therefore, we group hot bands into a hot band pool and cold
bands into a cold band pool. As a result, there is no section
concept in this band sharing layout although this design still
needs to cope with the physical layout. For simplicity, we refer
this band sharing layout H-SWD to as pool-based H-SWD.
With the help of this band sharing layout, we only need
Cold False Identification Counts
160000
140000
120000
100000
80000
60000
40000
20000
0
80000
70000
60000
50000
40000
30000
20000
10000
0
2K
4K
8K
16K
0
5
10
15
20
0
5
Cold False Identification Counts
(a) Financial 1
90000
80000
70000
60000
50000
40000
30000
20000
10000
0
5
10
80000
70000
60000
50000
40000
30000
20000
10000
0
15
Write Requests (Unit:900K)
(c) Rsrch 0
10
15
20
(b) Prxy 0
2K
4K
8K
16K
0
Algorithm 5 A Pool-based GC Algorithm
Function Pool-based GC()
2K
4K
8K
16K
20
1:
2:
3:
4:
5:
6:
7:
8:
9:
tempi = taili , where i is band ID
while Free space < RECLAIM THRESHOLD do
Choose one band with the smallest distance value (Di )
Free the (Di + 1) numbers of blocks in Bandi from the taili
Free space = Free space + (Di + 1)
Move taili towards (Di + 1) position
Update the distance (Di ) value accordingly
end while
taili = tempi
2K
4K
8K
16K
0
5
10
15
20
Write Requests (Unit:900K)
(d) Web 0
Fig. 11. Cold Data False Identification Counts under Various Window Size
and Traces.
to switch the write head to the next band when the current
band is full while in section-based layout the incoming requests might belong to different sections (Recall that, we only
consider write requests). Furthermore, the pool-based H-SWD
enables us to design a more intelligent GC algorithm that can
choose the best GC candidate and further reduce the required
block movement. We then briefly discuss our insightful GC
algorithm particularly used for the pool-based H-SWD.
Algorithm 5 describes the overall processes of this GC
algorithm. The new GC algorithm minimizes the required
valid block movement by carefully choosing a victim band.
To make the best candidate decision, we use a distance of
the first invalid block from its tail position in a band. The
overall process is as follows: we assume there is a predefined
number (assuming M) of free blocks for cleaning (i.e., free
space requirement). Suppose that the hot band GC is invoked,
and our pool-based H-SWD first chooses one band with the
smallest distance from the tail to its first invalid block, and then
it cleans all the consecutive blocks between them to other hot
or cold bands accordingly. Assuming the distance is K and
the number of hot blocks within this range is H, this cleaning
process produces K − H + 1 numbers of free blocks in the hot
band pool and also creates K − H + 1 valid blocks in the cold
band pool. The cold band pool GC is analogous to the hot
band pool GC. The tail pointer moves forward accordingly,
which is similar to three GC algorithms in H-SWD.
Now, it examines all distance values for each band including
the just cleaned band and again chooses the best one (i.e.,
with a smallest distance value, assuming L). Then it reclaims
these L + 1 numbers of consecutive blocks and moves valid
data to the hot or cold band respectively. Lastly, it moves
the tail pointer to the position of its initial position plus L +
1. Theses processes are iterated until it reaches the total M
numbers of free blocks. This GC algorithm enables our poolbased H-SWD to minimize data block movement. Different
options might exist. For example, we can clean a band that has
the highest GC efficiency (i.e., the largest number of invalid
blocks). However, we observed that this algorithm triggers a
much higher number of valid block movements compared to
our proposed GC algorithm since, in general, there still exist
many valid blocks.
Figure 12 demonstrates an example of how our new GC
algorithm operates. As shown in Figure 12. We assume that
a distance value of each band is denoted by Di , where i is
a band ID, and the required space for GC is 10 free blocks.
First, it chooses Band 2 since the distance (here, D2 = 0) of
the first invalid block from the tail is the smallest (D1 = 4,
D2 = 0, D3 = 3, D4 = 1, and D5 = 4), which corresponds
to step 1 in Figure 12 (a). Then, it starts to clean 1 block
and can obtain 1 free block. Next, it moves its tail pointer to
position 1. After all these processes, the band sharing H-SWD
proceeds the next iteration: First, it selects Band 4 ((D1 = 4,
D2 = 4, D3 = 3, D4 = 1, D5 = 4). Second, it cleans and
obtains 2 free blocks (as of now, it has obtained a total of
3 free blocks). Third, it moves its head from position 0 to
position 2. Similarly, once it finally reaches 10 free blocks,
our GC stops.
We finally compare the GC overhead of the pool-based HSWD and the H-SWD designs. Figure 13 shows that the poolbased H-SWD further reduces the required number of block
movement as well as flattens the block movement peaks. This
further improvement can be attributed to our dynamic GC
algorithm, which helps the pool-based H-SWD dynamically
choose the best candidate in each GC process.
V. Conclusion
In this paper, we proposed a Shingled Write Disk (SWD) design named Hot data identification-based Shingled Write Disk
(H-SWD). Unlike other SWD designs that do not control initial
incoming data placement, the H-SWD judiciously assigns the
incoming data into the hot bands or cold bands with the help
of window-based hot data identification . Therefore, the hot
data (likely to be updated soon) can be collected to the hot
bands, while the cold data are stored in the cold bands from the
beginning. This effective data placement policy increases the
garbage collection (GC) efficiency so that it can significantly
reduce the GC overheads.
Furthermore, we extended the H-SWD to the pool-based
H-SWD by grouping hot bands into a hot band pool and
cold bands into a cold band pool. We developed a dynamic
GC algorithm, which dynamically chooses one of the best
candidates (i.e., a band) to perform a GC operation to improve
Band 1
Tail
Pointer
v
v
v
v
i
v
v
i
v
v
Band 2
Band 3
Band 4
Band 5
i
v
v
v
v
i
v
v
v
v
v
v
v
i
i
v
v
i
v
v
v
i
v
v
i
v
v
v
v
i
v
v
v
v
i
v
v
i
v
v
1
4
2
3
References
(a) During GC process
Band 1
Tail
Pointer
Band 2
Band 3
Band 4
Band 5
F
F
F
F
F
F
F
F
F
F
v
v
v
v
i
v
v
i
v
v
v
v
v
v
i
v
v
i
v
v
v
v
v
v
i
v
v
v
v
i
v
v
i
v
v
v
v
v
v
i
(b) After GC process
Fig. 12. New GC Algorithm for Pool-based H-SWD. Here, I, V, and F
stand for Invalid, Valid, and Free blocks respectively. Numbers in Figure (a)
represent a GC process sequence.
Block Movement
1e+06
100000
HSWD
Pool
100000
10000
10000
1000
1000
HSWD
Pool
100
100
0
5
10
15
20
0
5
(a) Financial 1
100000
Block Movement
10
15
20
15
20
(b) Prxy 0
100000
HSWD
Pool
HSWD
Pool
10000
10000
1000
100
1000
0
5
10
15
20
0
Write Requests (Unit:900K)
(c) Rsrch 0
5
10
Write Requests (Unit:900K)
(d) Web 0
Fig. 13. The Number of Block Movements of Pool-based H-SWD and HSWD under Various Traces.
the GC performance further. Our experiments demonstrate
that both our designs outperform the Indirection System by
reducing the required number of block movements.
Acknowledgment
We would like to thank Dr. Yuval Cassuto (formerly in
Hitachi GST and a primary author of Indirection System) for
his many pieces of valuable advices. This work is partially
support by NSF awards: IIP-1127829, IIP-0934396, and CNS1115471.
[1] Y. Shiroishi, K. Fukuda, I. Tagawa, H. Iwasaki, S. Takenoiri, H. Tanaka,
H. Mutoh, and N. Yoshikawa, “Future Options for HDD Storage,” IEEE
Transactions on Magnetics, vol. 45, no. 10, pp. 3816–3822, 2009.
[2] R. Wood, “The Feasibility of Magnetic Recording at 1 Terabit per Square
Inch ,” IEEE Transactions on Magnetics, vol. 36, no. 1, pp. 36–42, 2000.
[3] K. S. Chan, R. Radhakrishnan, K. Eason, M. R. Elidrissi, J. J. Miles,
B. Vasic, and A. R. Krishnan, “Channel models and detectors for
two-dimensional magnetic recording,” IEEE Transactions on Magnetics,
vol. 46, no. 3, pp. 804–811, 2010.
[4] A. Caulfield, L. Grupp, and S. Swanson, “Gordon: using flash memory
to build fast, power-efficient clusters for data-intensive applications,” in
ASPLOS, 2009.
[5] D. Park, B. Debnath, and D. Du, “CFTL: A Convertible Flash Translation Layer Adaptive to Data Access Patterns,” in SIGMETRICS. New
York, NY, USA: ACM, 2010.
[6] A. Amer, J. Holliday, D. D. Long, E. Miller, J.-F. Paris, and T. Schwarz,
“Data Management and Layout for Shingled Magnetic Recording,” IEEE
Transactions on Magnetics, vol. 47, no. 10, pp. 3691–3697, 2011.
[7] J.-G. Zhu, X. Zhu, and Y. Tang, “Microwave Assisted Magnetic Recording,” IEEE Transactions on Magnetics, vol. 44, no. 1, pp. 125–131, 2008.
[8] M. Kryder, E. Gage, T. McDaniel, W. Challener, R. Rottmayer, J. Ganping, H. Yiao-Tee, and M. Erden, “Heat assisted magnetic recording,”
in Proceedings of the IEEE: Advances in Magnetic Data Storage
Technologies, 2008, pp. 1810–1835.
[9] W. A. Challenger, C. Peng, A. Itagi, D. Karns, Y. Peng, X. Yang, X. Zhu,
N. Gokemeijer, Y. Hsia, G. Yu, R. E. Rottmayer, M. Seigler, and E. C.
Gage, “The road to HAMR,” in Proceedings of Asia-Pacific Magnetic
Recording Conference (APMCR), 2009.
[10] R. E. Rottmeyer, S. Batra, D. Buechel, W. A. Challener, J. Hohlfeld,
Y. Kubota, L. Li, B. Lu, C. Mihalcea, K. Mountfiled, K. Pelhos,
P. Chubing, T. Rausch, M. A. Seigler, D. Weller, , and Y. Xiaomin,
“Heat-assisted magnetic recording,” IEEE Transactions on Magnetics,
vol. 42, no. 10, pp. 2417–2421, 2006.
[11] E. Dobisz, Z. Bandic, T. Wu, and T. Albrecht, “Patterned media:
nanofabrication challenges of future disk drives,” in Proceedings of
the IEEE: Advances in Magnetic Data Storage Technologies, 2008, pp.
1836–1846.
[12] A. Kikitsu, Y. Kamata, M. Sakurai, and K. Naito, “Recent progress of
patterned media,” IEEE Transactions on Magnetics, vol. 43, no. 9, pp.
3685–3688, 2007.
[13] I. Tagawa and M. Williams, “High density data-storage using shingledwrite,” in Proceedings of the IEEE International Magnetics Conference
(INTERMAG), 2009.
[14] P. Kasiraj, R. New, J. de Souza, and M. Williams, “System and method
for writing data to dedicated bands of a hard disk drive,” US patent
7490212, February 2009.
[15] G. Gibson and M. Polte, “Directions for shingled-write and two dimensional magnetic recording system architectures: synergies with solidstate disks,” Carnegie Mellon University Parallel Data Lab Technical
Report, CMU-PDL-09-104, 2009.
[16] A. Amer, D. D. E. Long, E. L. Miller, J.-F. Paris, and S. J. T. Schwarz,
“Design issues for a shingled write disk system,” in Proceedings of the
2010 IEEE 26th Symposium on Mass Storage Systems and Technologies
(MSST), 2010.
[17] Y. Cassuto, M. A. A. Sanvido, C. Guyot, D. R. Hall, and Z. Z. Bandic,
“Indirection systems for shingled-recording disk drives,” in Proceedings
of the 2010 IEEE 26th Symposium on Mass Storage Systems and
Technologies (MSST), 2010.
[18] “University of Massachusetts Amhesrst Storage Traces,” http://traces.cs.
umass.edu/index.php/Storage/Storage.
[19] “SNIA IOTTA Repository: MSR Cambridge Block I/O Traces,” http:
//iotta.snia.org/traces/list/BlockIO.
[20] D. Park, B. Debnath, Y. Nam, D. Du, Y. Kim, and Y. Kim, “HotDataTrap: A Sampling-based Hot Data Identification Scheme for Flash
Memory,” in Proceedings of the 27th ACM Symposium on Applied
Computing (SAC ’12), March 2012, pp. 759 – 767.
[21] D. Park and D. Du, “Hot Data Identification for Flash-based Storage
Systems using Multiple Bloom Filters,” in Proceedings of the 27th IEEE
Symposium on Mass Storage Systems and Technologies (MSST), May
2011, pp. 1 – 11.