Introduction to the Practice of Statistics
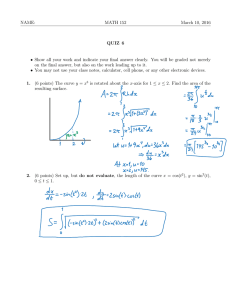
advertisement

Introduction to the Practice of Statistics
Fifth Edition
Moore, McCabe
Section 1.3 Homework Answers
1.80 If you ask a computer to generate "random numbers between 0 and 1, you uniform will get
observations from a uniform distribution. Figure 1.35 graphs the distribution density curve for a
uniform distribution. Use areas under this density curve to answer the following questions. Define the
random variable X to be the value that is generated by the computer.
X
0
1
Figure 1.35 The density curve of a uniform distribution, for exercise 1.80.
(a) Why is the total area under this curve equal to 1? Since the figure is a defined as a density curve,
then by definition it has a total area of 1 square unit. The area represents 100% of the population
(b) What proportion of the observations lie above 0.75?
To answer this question we need only to find the area above the curve corresponding to X > 0.75.
P(X > 0.75) = Height of yellow rectangle(width of yellow rectangle)
= (1)(1 – 0.75)
= 0.25
Keep in mind that because the author chose a uniform
X
0.75 1
distribution with endpoints 0 and 1, it is easy to see what the proportion
should be without much thought. Make sure you learn the real lesson here, that in order to calculate
proportions with density curves, the area underneath the curve is directly related to the corresponding
proportion.
0
(c) What proportion of the observations lie between 0.25 and 0.75?
We need to calculate P(0.25 < X < 0.75).
P(0.25 < X < 0.75) = 1(0.75 – 0.25)
= 0.5
0 0.25 0.75 1
X
1.81 Many random number generators allow users to specify the range of the random numbers to be
produced. Suppose that you specify that the outcomes are to be distributed uniformly between 0 and 2.
Then the density curve of the outcomes has constant height between 0 and 2, and height 0 elsewhere.
Let the random variable Y be the value generated by the computer.
(a) What is the height of the density curve between 0 and 2? Draw a graph of the density curve. The
height of the density curve is ½, 0.5. Why? Because, a density curve, must have an area equal to 1
square unit. If you look at the dimensions of the rectangle we get ½ (2) = 1 square unit.
½
Y
2
0
(b) Use your graph from (a) and the fact that areas under the curve are proportions of outcomes to find
the proportion of outcomes that are less than 1.
It is very easy to see that the area is one, but to be complete I will run through the calculation.
½
2
1
0
P(Y < 1) = ½ (1 – 0)
Y
= 0.5
(c) Find the proportion of outcomes that lie between 0.5 and 1.3.
½
0
0.5
1.3
2
P(0.5 < Y < 1.3) = ½ (1.3 – 0.5)
= 0.4
Y
2
1. 82 What are the mean and the median of the uniform distribution from problem 1.80 (Figure 1.35)?
What are the quartiles?
Since this is a symmetric distribution, the median and the mean are the same value, the halfway point.
Thus the mean is 0.5 as well as the median.
To calculate the mean of any uniform distribution take the average of the two endpoints: (0 + 1)/2 = 0.5
Again, since the boundaries of the figure are 0 and 1, it is easy to see the position of the quartiles: Q1 =
0.25 and Q3 = 0.75. Now while it is easy to see the quartile values, it is also easy to confuse what it is I
am looking at. It just happens that the value of X also corresponds to the area it represents when we
consider the frequency to the left of the number. That is,
P(X < 0.25) = P(X < Q1) = 0.25 (area not value of X)
1
P(X < 0.75) = P(X < Q3) = 0.75 (area not value of X)
0 0.25 0.75 1
Q1 Q3
X
If you are unsure what the above notation means or how it is related to the
picture on the left, see me quickly.
1.83 Figure 1.36 displays three density curves, each with three points marked on the axis. At which of
these points on each curve do the mean and the median fall?
ABC
(a)
A B C
(b)
A B C
(c)
In order to analyze these curves correctly, one needs to remember that for a density curve the median is
the value that splits the area above exactly in half (the median is the point the cuts the ordered set of
numbers in half); the mean is “pulled” by outliers.
Thus for picture (a) The median appear to be B, which then makes the mean C.
For picture (b), since we have a symmetric graph, the mean and median are represented by A.
Lastly, for picture (c), the median appears to be B and thus, the mean is A, which is “pulled” by outliers.
1.84 The length of human pregnancies from conception to birth varies according to a distribution that is
approximately normal with mean 266 and standard deviation 16 days. Draw a density curve for this
distribution on which the mean and standard deviation are correctly related.
Let the random variable X denote the length of human pregnancies.
µ−3 σ
218
µ−2 σ
234
µ−σ
µ
250 266
µ+σ
282
µ+2 σ
298
µ+3 σ
314
µ+4
X
0.75
1.89 The height of women aged 20 to 29 are approximately normal with mean 64 inches and standard
deviation 2.7 inches. Men the same age have mean height 69.3 inches with standard deviation 2.8
inches. What are the z-scores for a woman 6 feet tall and a man 6 feet tall? What information do the
z-scores give that the actual heights do not?
Women: {µ = 64 inches, σ = 2.7 inches} Men:{µ = 69.3 inches, σ = 2.8 inches}
Man: z =
72 - 69.3
≈ 0.9643
2.8
Woman: z =
72 - 64.0
≈ 2.9630
2.7
I can see that the six-foot tall woman is, among her peers, very tall, an extremely unusual height. (z =
2.9630). While the man is at six feet is above average but not as far away from the norm as the woman.
1.93 Using either Table A or your calculator or software, find the proportion of observations from a
standard normal distribution that satisfies each of the following statements. In each case, sketch a
standard normal curve and shade the area under the curve that is the answer to the question.
(a) Z ≤ -2 (this is a cumulative proportion) If I looked this value up on a table then, I need to realize
that -2, implies that my accuracy will be -2.00. So I look up -2 on the column with the z-value
and the first column gives you the rest of the accuracy 0.00. P(Z ≤ -2) = 0.0228.
−3.0
−2.0
−1.0
0.0
1.0
2.0
3.0
Z4.
Standard Normal Probabilities
z
0.00
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
-3.4
0.0003
0.0003
0.0003
0.0003
0.0003
0.0003
0.0003
0.0003
0.0003
0.0002
-3.3
0.0005
0.0005
0.0005
0.0004
0.0004
0.0004
0.0004
0.0004
0.0004
0.0003
-3.2
0.0007
0.0007
0.0006
0.0006
0.0006
0.0006
0.0006
0.0005
0.0005
0.0005
-3.1
0.0010
0.0009
0.0009
0.0009
0.0008
0.0008
0.0008
0.0008
0.0007
0.0007
-3
0.0013
0.0013
0.0013
0.0012
0.0012
0.0011
0.0011
0.0011
0.0010
0.0010
-2.9
0.0019
0.0018
0.0018
0.0017
0.0016
0.0016
0.0015
0.0015
0.0014
0.0014
-2.8
0.0026
0.0025
0.0024
0.0023
0.0023
0.0022
0.0021
0.0021
0.0020
0.0019
-2.7
0.0035
0.0034
0.0033
0.0032
0.0031
0.0030
0.0029
0.0028
0.0027
0.0026
-2.6
0.0047
0.0045
0.0044
0.0043
0.0041
0.0040
0.0039
0.0038
0.0037
0.0036
-2.5
0.0062
0.0060
0.0059
0.0057
0.0055
0.0054
0.0052
0.0051
0.0049
0.0048
-2.4
0.0082
0.0080
0.0078
0.0075
0.0073
0.0071
0.0069
0.0068
0.0066
0.0064
-2.3
0.0107
0.0104
0.0102
0.0099
0.0096
0.0094
0.0091
0.0089
0.0087
0.0084
-2.2
0.0139
0.0136
0.0132
0.0129
0.0125
0.0122
0.0119
0.0116
0.0113
0.0110
-2.1
-2
0.0179
0.0174
0.0170
0.0166
0.0162
0.0158
0.0154
0.0150
0.0146
0.0143
0.0228
0.0222
0.0217
0.0212
0.0207
0.0202
0.0197
0.0192
0.0188
0.0183
-1.9
0.0287
0.0281
0.0274
0.0268
0.0262
0.0256
0.0250
0.0244
0.0239
0.0233
If I used Excel, the command would be =Normsdist(-2); this of course provides more accuracy in the
result than the table.
(b) Z ≥ -2 What you need to keep in mind when looking up values on the table, is what area the
table provides versus what you want. I want P(Z ≥ -2). The area underneath the whole curve is
Thus, P(Z ≥ -2) = 1 - P(Z ≤ -2)
= 1 - 0.0228.
= 0.09772
Notice if I looked up Z = 2 on the table this is the associated
value.
On Excel the command is =1 – normsdist(-2)
−3.0
P(Z > 1.67) = 1 – P(Z < 1.67)
= 1 – 0.9525
= 0.04750
On Excel the command would be = 1 – normsdist(1.67)
−2.0
−1.0
0.0
1.0
2.0
3.0
Z 4.
(c) Z > 1.67
−3 .0
−2 .0
−1 .0
0 .0
1 .0
2 .0
3 .0
Z
4.
Standard Normal Probabilities
z
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
1.2
1.3
1.4
1.5
1.6
1.7
0.00
0.5000
0.5398
0.5793
0.6179
0.6554
0.6915
0.7257
0.7580
0.7881
0.8159
0.8413
0.8643
0.8849
0.9032
0.9192
0.9332
0.9452
0.9554
0.01
0.5040
0.5438
0.5832
0.6217
0.6591
0.6950
0.7291
0.7611
0.7910
0.8186
0.8438
0.8665
0.8869
0.9049
0.9207
0.9345
0.9463
0.9564
0.02
0.5080
0.5478
0.5871
0.6255
0.6628
0.6985
0.7324
0.7642
0.7939
0.8212
0.8461
0.8686
0.8888
0.9066
0.9222
0.9357
0.9474
0.9573
0.03
0.5120
0.5517
0.5910
0.6293
0.6664
0.7019
0.7357
0.7673
0.7967
0.8238
0.8485
0.8708
0.8907
0.9082
0.9236
0.9370
0.9484
0.9582
0.04
0.5160
0.5557
0.5948
0.6331
0.6700
0.7054
0.7389
0.7704
0.7995
0.8264
0.8508
0.8729
0.8925
0.9099
0.9251
0.9382
0.9495
0.9591
0.05
0.5199
0.5596
0.5987
0.6368
0.6736
0.7088
0.7422
0.7734
0.8023
0.8289
0.8531
0.8749
0.8944
0.9115
0.9265
0.9394
0.9505
0.9599
0.06
0.5239
0.5636
0.6026
0.6406
0.6772
0.7123
0.7454
0.7764
0.8051
0.8315
0.8554
0.8770
0.8962
0.9131
0.9279
0.9406
0.9515
0.9608
0.07
0.5279
0.5675
0.6064
0.6443
0.6808
0.7157
0.7486
0.7794
0.8078
0.8340
0.8577
0.8790
0.8980
0.9147
0.9292
0.9418
0.9525
0.9616
0.08
0.5319
0.5714
0.6103
0.6480
0.6844
0.7190
0.7517
0.7823
0.8106
0.8365
0.8599
0.8810
0.8997
0.9162
0.9306
0.9429
0.9535
0.9625
0.09
0.5359
0.5753
0.6141
0.6517
0.6879
0.7224
0.7549
0.7852
0.8133
0.8389
0.8621
0.8830
0.9015
0.9177
0.9319
0.9441
0.9545
0.9633
(d) -2 < Z < 1.67
To get this result I will use the previous information. I
could look it up on the tables but it would most likely be
the information I already have.
Here is one way.
−3.0
−2.0
−1.0
0.0
1.0
2.0
3.0 Z 4.
P(-2 < Z < 1.67) = 0.9525 – 0.0228
The 0.9525 I got from problem (c). I note that P(Z > -1.67) = P(Z < 1.67). Now I need to subtract
that little portion to the leftof –2, mainly the area 0.0228.
Another way.
P(-2 < Z < 1.67) = 1 – (0.0228 + (1 – 0.9525)) Here I am using the fact that the entire area is one. I
then calculate the two missing end points either directly or by another calculation. Subtract from
one and I have the area I want.
Using Excel = normsdist(1.67) – normsdist(-2).
1.94 Find the value of z of a standard normal variable Z that satisfies each of the following conditions.
(If you use Table A, report the value of z that comes closest to satisfying the condition). In each
case, sketch a standard normal curve with your value of z marked on the axis.
0.4
(a) 20% of the observations fall below z.
0.3
If I use table A, I find that P(Z < -0.84) = .2005 which is close to the
0.2000.
Using software like Excel, I get z ≈ –0.84162
(=normsinv(0.2)).
−3.0
desired
0.2
0.1
−2.0
−1.0
1.0
2.0
3.0
−0.1
Z 4.
-0.84
(b) 30% of the observations fall above z.
If I look at the table I see that P(Z > 0.52) = 0.3015
and P(Z > 0.53) = 0.2981. The value I want is about halfway
between the two. So a good approximation of z is the
average of 0.52 and 0.53 which is 0.525.
−3.0
0.4
0.3
0.2
0.1
−2.0
−1.0
1.0
−0.1
0.525
2.0
3.0
4.
Z
Using software like Excel, I get z ≈ 0.5244; I entered =normsinv(0.7).
1.97 The Wechsler Adult Intelligence Scale (WAIS) is the most common “IQ test.” The scale of
scores is set separately for each age group and is approximately normal mean with mean 100 and
standard deviation 15. The organization MENSA which calls itself “the high IQ society,” requires a
WAIS score of 130 or higher for membership. What percent of adults would qualify for membership?
Let the random variable X denote the WAIS score. We want to calculate P(X > 130). I notice that
the value 130 is 2 standard deviations from the mean; by the 68-95-99.7 rule then, P(X > 130) = 2.5%.
Notice if I use the tables or a computer by finding
the z-score I will not get 2.5%.
Z = 2 for X = 130.
Using Excel, I type in =normsdist(2) and I get
0.97725, which is the area to the right.
So P(X > 130) = 1 –0.97725
= 0.2275 less than 2.5% which is just an approximation.
The TI-83 command is normalcdf(2,10)
1.99 Jacob scores 16 on the ACT. Emily scores 670 on the SAT. Assuming that both tests measure the
same thing, who has the highest score?
SAT: µ = 1026 σ = 209 ACT: µ = 20.8 σ = 4.8
Emily: z =
670 − 1026
209
= -1.70
Jacob: z =
16 − 20.8
4.8
= -1
The z-scores tells us how far away each value is away from their respective means. So Emily is 1.7
standard deviations below the mean, and Jacob is only one standard deviation below the mean. Since
Emily is much further below the mean than Jacob, Jacob has the higher score.
1.102 Reports on a student’s ACT or SAT usually give the percentile as well as the actual score. The
percentile is just the cumulative proportion stated as percent: the percent of all scores that were lower
than this one. Tonya scores 1318 on the SAT. What is the percentile?
Let’s see so far we have the words percentage, relative frequency, percentile, and soon to come
probability. All are calculated exactly the same, but how we view it is slightly different, thus the name
change. Basically I need to calculate the area to the left of 1318, for this normal distribution.
µ = 1026 σ = 209
Let the random variable X denote an SAT score.
The area above represents the frequency of the
numbers found on the X-axis, (i.e. how often
would I encounter a value less than 1318 for
example).
P(X < 1318)
The z-score for 1318 is
≈ 0.9188
1318 - 1026
≈1.3971
209
If I use Excel I would enter = normsdist(1.3971) which results in 0.9188
P(X < 1318) = 0.9188 which ranks Tonya very high, almost at the 92 percentile.
If I were to use the table then instead of interpolating(the correct thing to do) to make it easier I will
round (which does not give me as good of an approximation as interpolating, whatever that means).
My z-score is then z = 1.40
P(Z < 1.40) =0.9192 which essentially says the same thing as the other result, Tonya is almost at the
92nd percentile.
1.103 Reports on a student’s ACT or SAT usually give the percentile as well as the actual score. The
percentile is just the cumulative proportion stated as percent: the percent of all scores that were lower
than this one. Jacob scores 16 on the ACT. What is his percentile?
Since I know the distribution is normal ( a very important fact) then I will turn the value in question to a
z-score, so I can look up the frequency on Table A, or input it into software such as Excel and get the
required frequency.
Z =
16 − 20.8
4.8
= -1 Using the 68-95-99.7 rule I calculate that P(Z < -1) ≈ 16%. Using table A, P(Z < -1) = 15.87%.
1.111 Middle-aged men are more susceptible to high cholesterol than the young women of Exercise
1.110. The blood cholesterol levels of men aged 55 to 64 are approximately normal with mean 222
mg/dl and standard deviation 37 mg/dl. What percent of these men have high cholesterol (levels above
240 mg/dl)? What percent have borderline high cholesterol (between 200 and 240 mg/dl)?
In order to do well in statistics, one needs to understand what information is available to them. This will
be specially true in later chapters. So let us start good habits now.
What is known? The distribution is normal (Knowing the distribution type is tremendously important).
Do I know the parameters for the normal distribution? Yes, µ = 222 mg/dl and σ = 37 mg/dl.
What do I want to know? How often I will see a value that is above 240 mg/dl, for one question and the
other how often will I get a value between 200 mg/dl and 240 mg/dl.
Since I know the distribution type and have all the necessary information I will find my z-scores so I can
correlate the z-scores to the requested frequencies by looking on a table or using the computer.
Let the random variable X denote the blood cholesterol levels.
240 − 222
P(X > 240 mg/dl) = P Z >
37
≈ P(Z > 0.49)
≈ 0.3121 We would expect a reading above 240mg/dl about 31% of the time.
240 − 222
200 − 222
P(200 < X < 240 ) = P Z <
– PZ <
37
37
≈ P(Z < 0.49) – P(Z < -0.59)
≈ 0.6879 – 0.2776
≈ 0.4103 We would expect a reading between 200mg/dl and 240 mg/dl about 41%
of the time.