Time Series Frequency Domain
advertisement

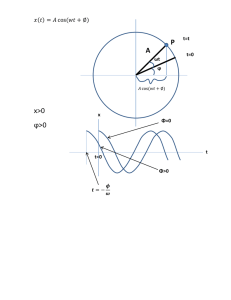
Time Series Frequency Domain Warning: this section has depleted my mathematical typsetting resources. Those who want the best explanation possible are advised to also read the book, which gives the mathematical equations in a less ambiguous font. Observations are made at discrete, equally spaced intervals, i.e. t = 1,2,3,...etc Rather than thinking of the time-series as processes as we did before, think of them as sums of cosine waves: X(t) = sum Rj cos(wj t + thetaj) + Zt where w is really an omega, and Zt is white noise. For a very simple time-series: X(t) = R cos(wt + theta) + Zt R is the amplitude---how high/low the curve goes on the y-axis w is the frequency -- how quickly the curve oscillates; the number of radians per unit of time. theta is the phase -- shifts the curve up and down the x-axis. Other related concepts: f = w/2pi = # of cycles per unit time If we think of t as continuous, then this is just a plot of the cosine function. But we don’t make continuous observations, we see only t = 0,1,2,3,etc. (Note: the following discussion is easier with a picture, which unfortunately I can’t reproduce here too easily.) Note that it is important that your observations be at the right frequency. If your time observations are only once per cycle (once every 2pi radians), you will observe a flat line. In fact, if you observe only twice per cycle, you will see a flat line (remember that the observations are evenly spaced.) If you make, say, 3 observations per cycle, you will eventually see different values, but it will take a long time for you to see the all possible values. This suggests that there is a certain minimum frequency at which you must sample if you want to observe a particular wave. More disturbing, since we don’t know ahead of time what the frequency is, it means that we will never be able to tell if we’re missing a wave oscillating at a much higher frequency. In fact, the rule is that if you sample every t units of time, the fastest wave you can observe is the one with w = 1pi (that oscillates with 1 radian per unit of time; in other words, that goes through 1/4 of its cycle in each time interval.) This corresponds to a frequency of 1/2 a cycle per unit of time. Or look at it like this; to see a complete wave, you must see the peak and the trough. This means you must sample at 0 radians and at 1 radian. This frequency is called the Nyquist frequency. Hence, if we sample every 1 second, the fastest wave we can see is the one that oscillates 1 radian per second. If we sample yearly, the fastest we can observe is the one that cycles one radian per year. When planning a study, this plays a role in the following sense. If you sampled air temperature every day at noon, then you would be able to model day-to-day cycles, but you could not model cycles that occured within the day. Common sense. If the process depends on frequencies faster than the Nyquist frequency, then we get an effect called aliasing. This means that these higher frequencies appear -- to us -- to be caused by slower waves. Essentially, we are “out of sync” of the process. Again, the book has some nice illustrations. A trig identify is behind this: for k, t integers, cos(wt + k*pi t) = (1) cos(wt) if k is an even integer (2) cos(pi - w)t if k is odd So for example, if the omega = 3/2 *pi , meaning the wave goes through 1.5 rads per unit of time, then cos(3/2 pi t) = cos(pi/2 t + 1*pi t) = cos(pi - pi/2) (using the identify with omega = pi/2 and k = 1) = cos(pi/2 t). Hence, we can’t distinguish between cos(3pi/2 t) and cos(pi/2 t). We can “tease out” the phase by using this identify: cos(wt + theta) = cos(wt) cos(theta) - sin(wt)sin(theta). Since X(t) = sum Rcos(wjt + theta j) +Zt, applying this identity, let aj = Rj cos theta j bj = - Rj sin theta j X(t) = sum aj Cos(wj t) + bj sin(wjt) + Zt. So we need to estimate the a’s, and b’s and w’s. Note: we’re going to flip back and forth between these two representations: the one in terms of R and thetas versus the one with a’s and b’s. Just as there is a fastest observable wave, there is also a slowest observable. This would be the wave that completes just a single cycle during our study period. Assuming observations are at equal spaced intervals which we label 1,2,...N, then this wave is the one that goes through 2pi radians in N units of time, and therefore the frequency is omega = 2pi/N. Put it all together, and it means that there are only a certain number of frequencies which we’ll be able to estimate. From slowest to fastest: 2pi/N, 4pi/N, 6pi/N,...,pi which are equal to 1*2pi/N, 2*2pi/N,....,(N/2)*2pi/N These frequencies can be represented by wp where p = 1,.2,...N/2. (Assuming N even.) In other words, half as many as we have data points. We now might model the data as a sum of these terms: ap cos(wp t) + bp sin(wp t) for each value of p above. Each term in this model is called the “pth harmonic.” Given this, one straight-foward strategy for estimating the a’s and b’s might be as follows: Fix a frequency, wp. For that frequency, apply the least squares criteria to find the a and b that best fit the data. With much algebra and trig, (and a little bit of calculus), one can find nice formulas for these parameters. I won’t reproduce them here, though, but they are essentially averages of the data, weighted by either cos(wp t) or sin(wp t). We can do this for each one of the N/2 frequencies. But note that we will then have “over fit” the data. At each frequency, we fit two parameters (a and b), and since there are N/2 frequencies that are fittable, we have N/2 * 2 = N paramters. This means that there is no “error” in the fit; no residuals. This is fine if you want to perfectly fit the observations, but our model allows for some “white noise” -- random deviations from the model. Including white noise in the model allows us to use the model to make predictions about the future. Put slightly differently, the problem with overfitting is you’re never sure if certain frequencies are included in the model soley because of abberations in this particular data set; you can’t be certain they’ll be there again if you recollect the data. So we can’t fit the function for every frequency; we must therefore choose some frequencies. But how to choose? Clearly we want only the “most important” frequencies, and one means of assessing importance is to look at the percentage of variation explained by including a particular frequency in the fit. Think of it like this: if we fit only the mean, that is we modelled the process as a straight line about the central value (estimated by the average of all of the data points), there would be considerable deviation from this line. In fact, one could estimate the variance as the average squared deviation from the average value. We could then ask how much of the variation would be cut down if we were to include in the model the estimate for one particular frequency. This overall variance could then be partitioned into two parts: the first is the amount of variation that was “explained by” (or removed by) the new model, and the “noise” that is still left unexplained. Turns out that with just a little bit of algebra, we can write out the amount explained by each of the p harmonics. It also turns out that this variation is equal to (R2p)/2 for p = 1,...,N-1 a2(N/2) for p = N/2 where Rp = sqrt(ap 2 + bp 2). This means that by estimating the a’s and b’s, and then converting them back to R’s, we have a quick way of seeing how much variation was explained by each component, and hence how important each frequency is.