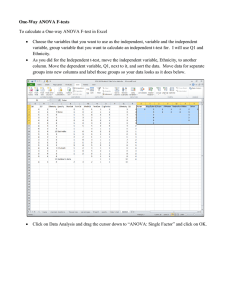
1 Combined Experiments as Split Plots Repeat experiment at
advertisement

Combined Experiments as Split Plots Repeat experiment at several times Repeat experiment at several locations Measure same experiment several times (repeated measures) Advantages 1. Assess performance over wide range of conditions, eg climate, soil 2. Assess consistency of performance 3. Better basis for practical recommendations 4. Can have larger number of reps Cautions 1. Variance may not be homogeneous over time and location 2. Time is systematic in order - measurements can not be randomized to times 3. Errors are not independent in repeated measures. Successive measurements on the same experimental unit are correlated. Common uses 1. Variety trials 2. Comparing results from different labs or experiment stations, eg monitoring food processing at several plants Analysis 1. As split plot, even though experiment may be installed at CRD, RCBD or Latin square 2. Very different variance components with measurements over space and time. Must be partitioned from variance for individual treatments Repeated Experiments at Different Locations and/or Times For repeated experiments a separate randomization is done at each time or location Time or location is the main plot e.g. 4 Treatments Tested at 3 Different Hospitals 10 Patients per Treatment at each Hospital ANOVA for 1 Hospital Combined ANOVA Source df Source df Total 39 Total 119 Treatment 3 Hospital 2 Patient within Trt (Error) 36 Rep within Hospital 27 Treatment 3 1 Treatment x Hospital 6 Error 81 Repeated Measures For repeated measures the experiment is not re-randomized between measurements Time is in the split plot ie time is nested in treatment e.g. 3 Pig Feeds 4 Blocks (Breeds) Growth Measured Weekly for 5 Weeks ANOVA for 1 Week Combined ANOVA for 5 Weeks Source df Source df Total 11 Total 59 Feed 2 Feed 2 Block 3 Block 3 Error 6 Error a 6 Week 4 Feed x Week 8 Error b 36 Example: Randomized Complete Block Design Experiment with: 4 Varieties of white clover 3 Blocks 4 Harvests V1 V4 V3 V2 Block 1 V4 V2 V1 V3 Block 2 V2 V3 V4 V1 Block 3 Harvested (cut) 4 times a year 2 ANOVA for 1 cutting Combined analysis for 4 harvests Source df Source df Total 11 Total 47 Blk 2 Blk 2 Var 3 Var 3 Error 6 Err A 6 Cutting 3 CxV 9 Err B 24 Alfalfa Variety Trial (from Little and Hills) RCBD with 4 Varieties, 5 Blocks, 4 Harvests. Data are tons/acre alfalfa Blocks Variety Harvest 1 2 3 4 5 Total Mean 1 1 2.69 2.40 3.23 2.87 3.27 14.46 2.89 2 1 2.87 3.05 3.09 2.90 2.98 14.89 2.98 3 1 3.12 3.27 3.41 3.48 3.19 16.47 3.29 4 1 3.23 3.23 3.16 3.01 3.05 15.68 3.14 Totals 11.91 11.95 12.89 12.26 12.49 61.50 1 2 2.74 1.91 3.47 2.87 3.43 14.42 2.88 2 2 2.50 2.90 3.23 2.98 3.05 14.66 2.93 3 2 2.92 2.63 3.67 2.90 3.25 15.37 3.07 4 2 3.50 2.89 3.39 2.90 3.16 15.84 3.17 Totals 11.66 10.33 13.76 11.65 12.89 60.29 1 2 3 4 5 Variety Harvest Total Mean 1 3 1.67 1.22 2.29 2.18 2.30 9.66 1.93 2 3 1.47 1.85 2.03 1.82 1.51 8.68 1.74 3 3 1.67 1.42 2.81 1.51 1.76 9.17 1.83 4 3 2.60 1.92 2.36 1.92 2.14 10.94 2.19 3 Totals 7.41 6.41 9.49 7.43 7.71 38.45 1 4 1.92 1.45 1.63 1.60 1.96 8.56 1.71 2 4 2.00 2.03 1.71 1.60 1.96 9.30 1.86 3 4 2.03 1.96 1.85 1.82 2.40 10.06 2.01 4 4 2.07 1.89 1.92 1.82 1.78 9.48 1.90 Totals 8.02 7.33 7.11 6.84 8.10 37.40 Variety by Block Totals Block Variety 1 2 3 4 5 Total Mean 1 9.02 6.98 10.62 9.52 10.96 47.10 9.42 2 8.84 9.83 10.06 9.30 9.50 47.53 9.51 3 9.74 9.28 11.74 9.71 10.60 51.07 10.21 4 11.40 9.93 10.83 9.65 10.13 51.94 10.39 Totals 39.00 36.02 43.25 38.18 41.19 197.64 ANOVA for each Alfalfa Harvest Harvest 1 MS Harvest 2 SS MS Harvest 3 Source df SS Total 19 1.180 Blocks 4 0.165 0.041 1.725 0.431 1.256 0.314 0.311 0.078 Variety 3 0.473 0.158 0.255 0.085 0.566 0.189 0.230 0.077 12vs34 1 0.392 0.392* 0.227 0.227 0.157 0.157 0.141 0.141* 1vs2 1 0.019 0.019 0.006 0.006 0.096 0.096 0.055 0.055 3vs4 1 0.062 0.062 0.022 0.022 0.313 0.313 0.034 0.034 Error 12 0.542 0.045 1.125 0.094 1.479 0.123 0.297 0.025 3.105 SS MS Harvest 4 3.302 4 SS MS 0.838 Test for Homogeneity of Variance Compare Error variances or MS Error F test for 2 variances larger variance in the numerator smaller variance in the denominator compared to tabular values in the standard F table use the df associated with each of the variances Bartlett's test for more than 2 variances uses a Chi-square test for homogeneity of variance Example comparing MS Error for each alfalfa harvest. Coded si2* si Log coded si22 Harvest df 1 12 0.0452 4.52 0.656 2 12 0.0937 9.37 0.972 3 12 0.1233 12.33 1.091 4 12 0.0247 2.47 0.393 Total 28.69 Mean 28.69/4 = 7.1725 Log of mean 3.112 0.856 *Values coded to avoid negative logs by multiplying Column 3 by 100. For low df, must be adjusted by dividing by a correction factor, C. 5 The adj value exceeds the value at the 0.05 probability, so the null hypothesis is rejected there is a significant difference among the variances of the 4 harvests Harvests can be combined into a single ANOVA only with caution. ANOVA is considered to be “robust”, i.e., not too seriously affected by small departures from homogeneity of variances. ANOVA for Combined Alfalfa Harvests Source df SS MS F F.05 F.01 Total 79 34.8690 Main plot (19) 5.0769 Block 4 1.9386 0.4846 Variety 3 0.9014 0.3005 1.61 3.49 5.95 1+2vs3+4 1 0.8778 0.8778 4.71 4.75 9.33 1 vs 2 1 0.0046 0.0046 3 vs 4 1 0.0189 0.0189 Error a 12 2.2369 0.1864 Harvest 3(1) 26.4452 8.8151 4.49* 8.53* Var x Har 9(3) 0.6217 0.0690 3.24* 5.29* Error b 48(16) 2.7252 0.0568 155.2 1.21 *df in parenthesis are divided by df harvest. F test is for adjusted df. Repeated Measures - a better approach Calculate a growth curve for each plot, animal or experimental unit. Compare the curves (intercept, linear and quadratic coefficients) to determine treatment effects. 6 7