Tom Borchert ECEN 5523 11/30/2005 NSL Analysis Discussion In

Tom Borchert
ECEN 5523
11/30/2005
NSL Analysis Discussion
In order to decide what tree calculations I needed, I thought about what information I would need when generating the output. This discussion is supposed to be about the analysis and not about the output of the translator, but unless the more complicated parts of the output are discussed many of the tree computations won’t make much sense.
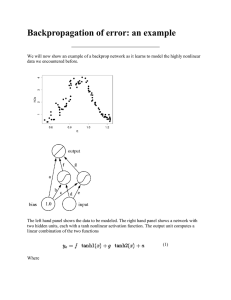
I realized that the code for one of the major components of the neural net – the weights between the layers – would be very difficult to generate using my current AST. It would be difficult because these weights are never explicitly declared in the input, but are implicit in the ACTIVATION_UPDATE value specified for each layer. So if the specification for layer C includes the line:
ACTIVATION_UPDATE: SUM(A) + SUM(B); then I need to create weights between layers A and C and between layers B and C. In order to create these weights I need to know how many nodes are in each of these layers, which may depend on the model parameters specified on the command line.
In my old AST, the ACTIVATION_UPDATE value was stored as a PTG node in a definition table just like other identifiers, and so when I need to update the weights I would simply grab the value of that key and output it into the code. However, in order to generate the code that defines and allocates the arrays for the weights, I need to walk though the ACTIVATION_UPDATE expression in every layer, which means I can’t treat it as just another identifier. So I changed my AST so that the ACTIVATION_UPDATE,
WEIGHTS_UPDATE, WEIGHTS_INIT and NODES values are explicit in the network and layer declarations. Also, a definition for ACTIVATION_UPDATE is now required in every layer, instead of before when it could be defined for the entire network and then overridden for certain layers.
The code to declare and allocate the weight arrays is in the Expr ::= VarUse rule because that is the only place I could easily access both the layer containing the expression and the layer referenced by the expression.
Instead of referencing a layer by name in the ACTIVATION_UDPATE statement, the user can reference previous layer in the source text by writing:
ACTIVATION_UPDATE: SUM(PREV);
So, the def. table key for PREV needs to always reference the previous layer in the source text. I created a chain to make sure the layers are evaluated in textual order, and before the chain exits a layer it sets the appropriate properties for the PREV key.
The user can specify a function from an external file by using the following statements in the global declarations area: function1 : “file.h”; function2 : “file.h”;
These functions would then available for use in any of the layer calculations. A property
Included is used to make sure each file is included only once at the beginning of the output code.
In order to use a function or identifier in a calculation it must first be declared. I used the standard name analysis roles to handle this requirement.
Some identifiers denote network layers and some denote values, and these two types need to be treated differently in many of the calculations. I couldn’t make different tree symbols for the two uses, however, because there is no way to know which identifier is which type while parsing the source text – it can only be determined after name analysis has been performed. The IsLayer property is used to flag whether an identifier is a layer or a scalar value.