ALGORITHMS AND ARCHITECTURES FOR NANOELECTRONIC
advertisement

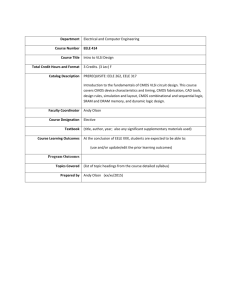
Microelectronics Advanced Research Initiative (MEL-ARI) ANSWERS ALGORITHMS AND ARCHITECTURES FOR NANOELECTRONIC COMPUTERS: 2 M. Forshaw, D. Berzon Technical Report July 1998 - July 1999 University College London Image Processing Group Department of Physics and Astronomy Gower St. London WC1E 6BT 1 1 Introduction In the first report in this series [1] we presented an introductory review of the problems associated with predicting what algorithms and computer architectures might be needed for the time, perhaps 10 or 15 years hence, when conventional CMOS technology reaches its limits. The report concluded that signal propagation delays and device errors would be extremely important in determining the performance of future systems, irrespective of their constituent devices, architecture and algorithm. The present report continues this theme. Almost all existing computers use binary digital logic, and this is likely to continue long into the future. We therefore believed it important to concentrate initially on digital circuits and architectures, before moving on to consider probabilistic or analogue circuits. We chose a memory-adder combination as a representative example of such circuits. The CMOS signal propagation model which was outlined in [1] was found to be too simplistic, and we therefore developed a more refined circuit model which could be tested using HSPICE. We felt that it was necessary to develop the CMOS model for three reasons. First, it provided training in using HSPICE. Second, it provided better values for CMOS performance, which could then be used as a benchmark to compare with the newer nanoelectronic circuits. Finally, the HSPICE memory model will be used as a basis for developing the RTD and SET circuit models. Section 2 of this report is therefore devoted to describing the memoryadder model and its HSPICE implementation in CMOS. The implementation of the model in RTDs and SETs is then discussed. After developing the HSPICE CMOS model, and because the RTD and SET models were still being developed during the period January-June 1999, we then concentrated on a QCA memory-adder model. A full theoretical description of QCA devices is still extremely difficult, and so a greatly simplified binary logic model was used. This was based in part on analyses presented by the originators of the QCA concept, and partly on previous in-house work carried out at UCL. The simplified model is internally consistent, but it relies on assumptions that have not yet been experimentally verified, and it is therefore probably optimistic in its performance estimates. It also completely ignores background charge effects, which are likely to seriously affect the operation of QCAs. The analysis is therefore probably doubly optimistic in its performance estimates. Section 2.5 describes the QCA memory-adder model and section 3 compares the performance of the CMOS and QCA memory-adder circuits. In order to provide a basis for comparison the memory-adder circuits are assumed to be completely error-free. This is impossible, as all real systems are subject to an enormous variety of defects, both in manufacturing and in operation. Section 4 contains a preliminary description of some of the error sources which may be important in affecting the ultimate performance of systems using QCAs, SETs, RTDs, and of course CMOS. 2 2 Memory to adder signal distribution 2.1 Introduction The maximum operational frequency of a computational architecture is determined by the signal distribution along some critical data path. In conventional microprocessors this critical path is invariably register to register arithmetic [2] but with large on-chip cache memories, memory access may prove the limiting factor. In order to assess the relative operational speeds of RTDs, SETs, QCAs and CMOS it is beneficial to analyse the potential signal delay through such a data path. We set up a benchmark architecture that we have modelled in CMOS and simulated with HSPICE in order to determine the conventional limits on operational frequency. This architecture has been implemented in QCAs to give comparative performance results and will be implemented in RTDs and SETs in the near future. This will provide a quantitative measure of the performance of different devices, at least for conventional microprocessor architectures. (LWord)1/2 Units SRAM Cell (Nword)1/2 C ll Memory Block Lword Blocks Latch Log2(Lword) CMOS CLA or.. Adder QCA Ripple Carry Adder Lword Full Adders Figure 1: Schematic layout of the memory-adder model. The benchmark structure chosen is shown in figure 1. Two integer words of length Lword are collected successively from memory, added together and then returned to memory. The memory consists of SRAM blocks, each containing Nword bits. There are Lword blocks laid out in a square, each representing one bit of the integer word, so that extracting a word from the memory involves each of the blocks being accessed in parallel. The word is collected in a latch at the base of the memory and then sent to the adder. The reverse process occurs for writing the final answer back to memory. 3 The actual nature of the SRAM cells and the type of adder used will depend on the device architecture chosen. For example the CMOS implementation uses a binary lookahead adder tree, whereas the inherent micro-pipelining of the QCA architecture makes a ripple carry adder more appropriate. We ignore all details of address generation and the latch itself is not modelled. The model is extremely crude in that it does not represent an optimised system in any of the device implementations. For example a realistic CMOS register would be multi-ported [3] and a QCA memory implementation may well involve shift registers rather than SRAM cells [4]. However using this simplified system across the device architectures has two major advantages. Firstly, the dependence of signal delay against Lword and Nword can be evaluated without changing the structure of the system. Secondly, the system can be implemented and simulated in each of the device architectures using sub-circuits that have already been designed and tested. It should also be noted that this layout of memory and addition circuitry is only really valid for Nword > 100. Below this figure, the implementation becomes unwieldy and other design layouts will be more efficient. 2.2 CMOS implementation. To develop a benchmark against which to test the nano-device structures we implemented the above structure in CMOS and then simulated it using HSPICE [5]. The system is split into two delay paths; the first represents the time taken from the WORD line of an SRAM cell going high to the output signal arriving at the latch, the second is the time taken to add the two words together. An idealised implementation of the system would split the process into four clock phases; one for the collection of each of the two words, one for the addition and one for the return of the result to the latch. Therefore, each of the two delay paths modelled would have to be contained within a single clock phase and the maximum of the two delays determines the maximum clock frequency for the system. In order for HSPICE to simulate the two delay paths, a set of MOSFET models are required. These give parameters with which HSPICE calculates device delay, input and output resistance, capacitance and voltage transfer function. For the most part they are semi-empirical and are available for specific commercial MOSFET technologies. For our purposes it was necessary that the MOSFET models were scalable with device size and could represent reasonable results for technologies that have not yet been developed. The MOSFET models used were those developed by G. McFarland [6] in order to investigate the effect of CMOS minimum feature size on cache delay. The models use values of the various HSPICE parameters for 0.55µm technology and then scale them in terms of the minimum feature size (λ). The models as published are valid for 0.55µm > λ > 0.10 µm. In order to model the delays for sub 100nm technology it was necessary to alter one of the scaling rules. When McFarland’s original scaling rules were used, the delays increased as λ was reduced from 0.10µm to 0.05µm, which represented a reversal of the trend for 0.55µm > λ > 0.10µm. This was due mainly to the scaling of the threshold voltage (VTO), which at 0.55µm represented nearly half of the supply voltage (Vdd). In order to extend the validity of the models we changed the threshold voltage dependence so that it represented a constant proportion of Vdd. This had the effect of reducing the device delays systematically by a small fraction, but maintaining the delay vs. technology trend for all values of λ. Both scaling rules are consistent with experimental results and estimates produced by other authors (e.g. [7], [8]). In addition to the MOSFET models, McFarland’s paper [6] also included scalable interconnect models, consisting of lumped RC transmission lines with R and C calculated analytically on the basis of λ. These were used in our simulations without alteration. 4 BIT Pre-charge To Vdd BIT_b WORD Active SRAM cell C A SRAM ×N½word / 6 B SRAM ½ ×N word / 3 MUX ½ ×N word / 6 SRAM ½ ×N word / 3 MUX ½ ×N word / 3 SRAM ½ ×N word / 6 MUX ½ ×N word / 3 SETSEN To ADDER MUX ½ ×N word / 6 SA_OUT Active MUX Sense Amplifier A = lumped model of series bit-line: N½word SRAM cells + interconnecting wires B = lumped model of multiplexer: N ½word MUX units + interconnecting wires C = lumped wire model: Length = N½word × SRAM cell width × (Lword – 1) Figure 2: Circuit diagram for the CMOS memory system as simulated in HSPICE. 2.2.1 Memory to adder signal. Figure 2 gives a schematic of the circuit implemented in HSPICE to model the path from the SRAM cell to the latch. The SRAM system is similar to the one presented in [6]. The SRAM is a six transistor cell (shown in figure 3) and when the WORD line goes high it begins to discharge the BIT or BIT_b line depending on the bit value stored inside. The line that is discharged has a distributed R and C due to the interconnecting wires, and a parasitic capacitance due to the inactive SRAM cells. This load on the active SRAM cell is implemented using the lumped model represented by Block A of figure 2. Here the interconnecting wires are modelled using a lumped RC circuit and the parasitic SRAM cells are lumped by multiplying the channel widths by the factors shown. This lumping enables the values of Nword to be altered without any changes to the HSPICE net list. The length of the SRAM line is taken as √Nword × length of an SRAM cell. The BIT line signals are fed directly into a sense amplifier, again using the design from [6] (figure 3). When the differential on the BIT lines has reached a trigger value (set at 0.04 Vdd as in [6]) the SETSEN signal goes high and the sense amplifier is isolated from the SRAM cells. It then amplifies the differential to Vdd and this triggers the output inverters. The SETSEN signal and WORD signal are implemented so that they both have a rise time of 10ps which is independent of λ. The SETSEN signal was implemented using an isolated RC circuit and a voltage dependent voltage source. 5 SRAM WORD SETSEN Generate Gate WORD Sense Amplifier C B A A + B.C A SET Pass gate SETSEN B C SET_B Figure 3: CMOS layouts for the major components of the memory and adder implementations. The sense amplifier and SRAM line select the required bit from a column. The column output is then selected using a multiplexer line. Each multiplex unit is a simple CMOS pass gate as shown in figure 3. The multiplexer line uses a lumped model similar to the SRAM line (Block B figure 2) and the active multiplexer is triggered by a SET signal at the same time that the WORD line goes high. The length of the multiplexer line is taken as √Nword × width of an SRAM cell, where the value for √Nword is rounded down. This has the effect of making the SRAM blocks slightly longer than they are wide. The multiplexer delay could be reduced by using tri-state buffers instead of pass gates, but for the sake of simplicity the entire line is effectively driven by the output inverter of the SRAM cell (which is made wider to reduce the delay). An additional inverter terminates the multiplexer line. The final output signal is transmitted to the adder using a further interconnect wire (block C in figure 2). The longest delay will be that from the SRAM blocks on the top row of the memory, and as such the length of this wire is set to √Nword × SRAM width ×√Lword -1. A final inverter represents the input to the latch. The delay is measured as the time between the WORD line signal reaching Vdd/2 to the input to the terminator buffer reaching the same value. This delay ignores the time for the loading of the WORD line and also the pre-charge circuitry. However these would give negligible increases to the delay and are difficult to model without details of the addressing mechanism. The simulations were performed with a sweep over values of Nword between 10 and 100,000 in logarithmic steps. The simulations were repeated for Lword =32, 64 and 128 and with minimum feature sizes ranging from 0.25µm to 0.05µm 2.2.2 Adder. For the CMOS implementation of the adder section we decided to use a Carry Lookahead Adder [9]. We chose a binary lookahead tree as a compromise between delay optimisation and ease of implementation. Although other types of adder (e.g. Ling adders) can achieve greater speed, their implementation is dependent on the value of Lword. The binary lookahead tree performs the add in 2.log2(Lword) logic levels and can be easily scaled. The other advantage of a CLA is that it has a relatively well defined critical delay path. Figure 4 shows the schematic layout of a 16 bit binary lookahead adder. Addition of another logic level would double Lword. The logic in the top layer collects the two words to be added, and the local propagate and generate signals are created with using the following relations: (1) g i = ai bi p i = ai + bi where ai and bi are the i’th bits of the two words to be added. The values of p and g propagate downwards through the tree, and at each logic block the values are combined using the following expressions: (2) Gi ,k = G j +1,k + Pj +1, k Gi , j Pi , k = Pj +1,k Pi , j 6 15 14 13 12 11 10 9 8 7 6 5 4 3 2 S0 b0 1 0 a0 Generate and Propagate signals Carry signals C0 Gj+1,k Pj+1,k A B C GENERATE GATE Gi,k Gi,j Cj+1 GENERATE GATE Pi,j A B C Ci Pi,k Ci Figure 4: A schematic diagram of a Binary Lookahead Tree. The contents of the individual logic blocks are shown in the inset. As an illustrative example, the right hand logic block in level 2, which has inputs from bits 0 and 1, performs the following calculation: (3) G0 ,1 = g1 + p1 g 0 p0 ,1 = p1 p0 Once the values of P and G have propagated to the bottom, the carry values (ci) are calculated by propagating back up the tree, where at each logic level the following calculation is performed: c j +1i = Gij + Pij ci (4) The value of cj+1 is fed into the logic block directly above, and the value of ci is fanned out at the input and sent to the adjacent logic block on the next level up. The layout is such that the required values for Gij and Pij are already available to the block from the downward path. The logical layout of each block is shown in the inset in figure 4. The block contains two generate logic gates (the layout for which is shown in figure 3), one of which calculates the Gi,k values on the downward path and one to calculate the cj+1 value on the upward path. The block also contains an AND gate, to calculate the Pi,k values. Rather than directly fanning out the ci value, a buffer stage is added. This makes the simulation of the upward path easier, as explained below. At conventional CMOS device sizes, the delay due to the adder can be approximated as the gate delay multiplied by the number of logic levels. However at sub-micron feature sizes, the interconnect delay becomes important. The lateral interconnects double in length with each logic level, and therefore the critical delay path is that of the generate signal for bit 0 propagating to the bottom level. The HSPICE circuit used to model the downward delay path for an adder of Lword bits adder is shown in figure 5. 7 Bottom logic block Vdd GEN ×Lword/2 A B C ×2 A B C A B C 0 .... GEN GEN Lumped interconnect wire Length = width of a logic block Figure 5: Schematic of the downward critical path in the Carry Lookahead adder, as implemented in Hspice. The AND gate in the first stage represents the creation of g0. We ignore vertical interconnects and model the lateral interconnects as a lumped wire model with the length set to be the same as the width of one of the logic blocks (we take a reasonable value for the block width to be 50λ). The next generate gate represents the creation of G1,0 and the other inputs are set up so that the g0 signal toggles the gate. This process is repeated down the adder, with the lengths of the interconnects doubling at each level. In the final gate the generate signal is combined with C0 (here taken as 0) to start the upward path. Modelling the upward path is complicated by the initial fanout at each stage of ci. The addition of the buffer separates the connections to each stage, which would otherwise necessitate the modelling of the entire adder. There are effectively two critical paths for upward propagation. The first follows the output signal from the bottom generate gate directly up to the most significant bit, and the other follows the same signal laterally to the least significant bit. The first path contains no lateral interconnects and contains only the delay through the generate gates, while the second has generate gates only as capacitive load. We assume throughout that the C0 value is available at the beginning of the addition. The relative values of the two paths will depend entirely on the size of the buffers used to drive each wire. × Log2(Lword) – 1 Bottom logic block AB C AB C AB C GEN GEN .... GEN Path 1 × Log2(Lword) – 1 Path 2 .... ×2 ×Lword/4 A B C GEN Figure 6: Schematic of the upward critical paths in the Carry Lookahead adder, as implemented in HSpice. The relative importance of the two paths on delay is dependent on the size of the buffers. 8 Figure 6 shows the two critical paths. Simulations of this circuit showed that the first path had the shorter delay except for very large buffers (eg for a 128bit adder the two delays were comparable when the PMOS transistor in the buffer had a width 21×the minimum feature size). We decided to keep the buffer size constant with respect to Lword and took a reasonable value for the width/length ratio of the PMOS transistor as 4. The HSPICE simulation measured both delays and then output the maximum of the two. The simulations combined the downward path with both upward paths to produce a result for the maximum adder delay. The simulations were performed for Lword=32, 64 and 128, and for feature sizes between 0.25µm and 0.05µm. Figure 7: The maximum clock frequency for the memory – adder system as a function of Nword. The solid lines represent current technology and the dashed lines represent projected, sub micron CMOS. 2.3 Results. The results from the two simulations were combined to produce value for the maximum operational frequency of the memory-adder system against Nword and Lword. Figure 7 shows the clock frequency against Nword for Lword=32, 64 and 128 and for minimum feature sizes of 0.55µm and 0.05µm. The frequency curves reach a maximum for low values of Nword, this being the region in which the adder delay (which is constant over Nword) becomes greater than the memory access delay. The results are in reasonable agreement with the clock rates for existing microprocessors (e.g. [10]), and with predictions for denser technologies (e.g. [11]). We remind the reader that the model has not been optimised, and assumes the use of aluminium tracks and standard oxide dielectric materials. The use of graded driver sizes and track widths would improve the performance by perhaps 30% [11], with the use of copper tracks and exotic dielectrics providing a similar increase [11][7]. 9 2.4 RTD and SET models. The H-SPICE model of the memory→adder→memory system laid out above has been presented as a CMOS implementation. However many of design and layout features are not specific to CMOS and the next step will be to implement the memory→adder→memory system in RTDs, SETs and QCA’s. The next section describes an initial investigation of a QCA implementation, which would not suitable for SPICE simulation since QCA circuits do not involve currents, voltages or interconnects. However the implementations of RTD’s and SET’s are most likely to be directly adaptable into the models presented above. We have obtained HSPICE netlists for an RTD NAND gate circuit, which use HFET models and voltage dependent voltage sources to simulate the resonant tunnelling components. Christian Pacha of UNIDO has produced a design for a pipelined ripple carry adder which we can use to implement the adder section, however as yet these models are not scalable. The SRAM cells may be more complicated to implement, as there are no simple designs as yet for SRAM cells using only RTDs. There are however many examples of mixed RTD/MOSFET designs, for example by Seabaugh et al. [12] and these could be implemented initially to get a foothold on the comparative performance of such systems. The situation with SETs is more long term. Currently the work being performed in Delft is focussed on low level simulations of simple SET structures. However work is underway to attempt to model SET devices in SPICE, and this will provide the starting point for an implementation of our system. 2.5 QCA implementation The CMOS results give a benchmark against which we can compare the performance of circuits based on nano architectures. Here we make an initial attempt to implement the memory-to-adder system using QCAs. QCAs rely on the ground state of a quantum system to perform logical computation, and therefore time-dependent circuits, such as SRAM, require clocked QCA logic. As yet there is no simulator available for clocked QCA logic which can incorporate a full implementation of this system. The QCA results have therefore been developed using a simple analytical model. Although the theory of adiabatically clocked QCAs is well developed [14], there remains a level of uncertainty as to the size of clock regions that can be implemented. The argument rests on the question of whether QCA clock regions can behave as a coherent system. In the worst case, the input lines to Figure 8: The two circuit elements used to implement the memory – adder model in QCAs. The left hand SRAM cell design is by T.J. Fountain [13] and the full adder on the right is by C. S. Lent [14] 10 logic gates have to be equal in length, requiring low level micro-pipelining and high spatial redundancy (cf. The SQUARES architecture [4]). Work is being performed by Geza Toth at the University of Notre Dame, Indiana, to clear up this question, but pending its publication we will assume that coherence is not a problem. There are currently only a limited number of functional QCA circuit designs in the literature, and so we have implemented the system using these circuits rather than design an optimised system from scratch. The two circuit designs used are: • • A 1 bit addressable SRAM cell – designed by T. J. Fountain [13] An adiabatically clocked full adder – designed by Lent et al [14] The implementation of these two elements into the memory-adder system requires a few changes of approach. Firstly we explicitly model the address decoding, as this will have a significant dependence on Nword. Addresses are carried as a pipelined binary string to each of the SRAM units, and are decoded and distributed within the unit by circuitry at the unit’s corner. Secondly the addition is performed by a simple ripple carry adder, which comprises a serial string of full adders. A carry lookahead adder would be inappropriate, due to the micro-pipelined nature of QCA data flow. The QCA circuitry is micro-pipelined using the adiabatic clocking scheme laid out in [14]. The number of phase regions the data have to cross will therefore govern the time for signal propagation. This contrasts with the CMOS implementation, where the memory access and addition can each be performed within a single clock. The length of a clock transition will depend on the largest value for the number of cells in a clock region and on the intrinsic switching time for a QCA cell, as shown by Lent et al [14]. It can be inferred from their treatment that, for an adiabatically clocked binary wire, the clock transition time necessary to allow a signal to propagate across the phase region is given by: 1.16 Tswitch × N cells ×K where Tswitch is the intrinsic switching time of the QCA cell, Ncells is the number of cells in the binary wire, and K is a factor necessary to allow for adiabatic evolution of the system. However it is not known whether this relation holds for a more general circuit and what value for Ncells should be chosen. The two limiting cases are where the value for Ncells is taken as the longest path in a region, or where it is taken as the total number of cells in the region. The memory cell and adder designs are shown in figure 8. All of the control signals for the SRAM block require four clock transitions to cross a memory cell, and the addition process requires three clock transitions. The largest clock region is the second phase of the memory design (indicated in figure 8 by the region shaded in white) and so the two limiting choices for Ncells are 32 (longest path) or 120 (total no. cells). It is helpful to approximate the relationship of the clock transition time with Ncells as linear. The value taken for K depends on the acceptable level of non-adiabaticity in the system (η). We chose a value of η = 10-4, which gives K=3.51. The intrinsic switching times are as follows: Solid state cell (inter-dot separation 20nm, inter-cell separation 60nm): Macro molecular cell (inter-dot separation 2nm, inter-cell separation 6nm): Tswitch = 2ps Tswitch = 0.02ps and possible values for the clock transition length (tclock) are shown in table 1. Table 1: Clock transition length for QCA architectures. Ncells Solid state cells Macro-molecular cells 32 120 240 ps 900 ps 2.4 ps 9.0 ps The addition process requires the following stages: 1 This factor was extrapolated from Lent et al [14] who performed time dependent simulations of a simple majority gate with two active cells. Because the two systems are not directly comparable, the factor may be optimistic. 11 1. The addresses of the two numbers are sent to the memory units. 2. The addresses are decoded and the relevant signals are distributed to the column select, row select, data input and write enable lines of the array. 3. These signals propagate through the array to the addressed cells. 4. The data out values propagate back to the array edges. 5. Each of the data out lines propagates to a latch. 6. Steps 1-5 are repeated for the second word. 7. The two words, held in the latch are added. 8. The latched answers are propagated to the data inputs of the memory units, synchronously with the write address. 9. The write address is decoded and the signals distributed. 10. The signals propagate through the arrays and the answer is written into the memory. Initially, we need to calculate the number of clock phases required for each section, and then translate this into operational frequency. For each of the stages above we assume the worst case access, i.e. the maximum propagation distance. We first take the optimistic case where Ncells is 32. In this case a binary wire in one phase can hold up to 32 cells, which is also the width of a memory cell. 1. The address is assumed to be held as a log2Nword bit number, and since the adiabatic clocking scheme can hold one bit of information in four clock phases, the signal length is 4log2Nword. If the signal is assumed to arrive from the lower left hand edge of the memory system shown in figure 1, it must propagate past 2(Lword1/2-1)Nword1/2 memory cells, and thus the total number of clocks needed for the propagation is: (2 ) Lw − 2 N + 4log 2 N here we have abbreviated Lword to Lw and Nword to N 2. The address decoding time is dependent on the nature of the coding and decoding mechanism. We have not designed a mechanism, so we will include a parameter ndecode. We assume the decoding is performed at the corner of the unit, so the worst case access will require Nword1/2 clocks to distribute the signals to the Row/Column lines, giving a time of n decode + Nword1/2. 3/4.These steps require a total of 8Nword1/2 cycles. 5. From the organisation of the cache and memory cell we may assume that the signal can travel directly down, which gives a further factor of (Lword1/2 -1)N1/2. 6. Repetition brings the total to: (6 ) Lw + 12 N + 8 log2 N + 2ndecode 7. Ignoring register access time, the addition requires 3 cycles for each consecutive add, plus the time needed for the signals to propagate between each adder. Since each of the adders is 17 cells wide and the memory cells are 32 wide, the total add time can be expressed as: (5) (32 ) L w N − 17 Lw + 3Lw 32 8/9.The write address propagation will be the limiting factor, so there is another factor as in 1-3: (2 ) Lw + 3 N + 4 log 2 N + ndecode 10. This is a final factor of: 4Nword1/2 The equation for the maximum operating frequency of this system becomes: 12 Fmax = 1 ( ) nclocks , where : ( ) 32 L w N − 17 Lw + 3ndecode nclocks = Tclock 8 Lw + 14 N + 12 log 2 N + 3Lw + 32 (6) Maximum operational frequency of QCA memory to adder using Ncells=32 1.00E+09 32 bit 64bit 128 bit Operation speed / ops 1.00E+08 1.00E+07 1.00E+06 32 bit 64bit 128 bit 1.00E+05 100 1000 10000 } MacroMolecular QCAs } Solid State QCAs 100000 No. Words Memory Figure 9: An analytical plot of the maximum operational frequency of QCA memory to adder implementation. Ncells is set to 32. Figure 9 shows the maximum operational frequency, in operations per second, against the number of words in memory. We have left the value of ndecode as 0 to show the most optimistic delays. Increasing ndecode has the effect of flattening the lines at low Nword. As can be seen, all six lines are approximately straight on the log/log scale, representing a relationship of operational speed ≈ (Nword) 0.4. Doubling Nword decreases the speed by a factor of 0.75. The speed results are compared with CMOS in the next section. For the case when Ncells = 120 the form of the equation changes slightly. This is because a binary wire can now stretch across four memory cells. The relation now becomes: Fmax = 1 ( nclocks ( ) , where: ) (7) 32 L w N − 17 Lw + 3Lw + 3ndecode nclock = Tclock 8 Lw + 43 N 4 + 12 log 2 N + 120 The graph for Ncells = 120 is very similar in form to figure 9, with all of the speed values decreased by a factor of 1.5 – 3, depending on the value of Nword (again ndecode = 0). 3 Comparison of results Using the results obtained above, we can now make an initial estimation of the comparative performance of the QCA and CMOS architectures In order to ensure a comparison of like with like, we have divided the CMOS frequency by four, as the full (read-read-add-write) operation requires four clocks. Figure 11 displays the results for 64-bit processes, with the more optimistic QCA results (for Ncells = 32) being used. 13 Operational frequency for 64 bit CMOS and QCAs 1.000E+09 0.05µm CMOS operational frequency / operations per second 0.25µm CMOS 1.000E+08 Macro -molecular QCAs 1.000E+07 Solid state QCAs 1.000E+06 1.000E+05 100 1000 10000 100000 Nw ord Figure 10: A comparative plot of the QCA and CMOS operational frequencies. Lword is set at 64 The conclusions for QCAs are quite alarming. In the layout that we have developed, the frequency at which solid state QCAs can perform the calculation are between one and two magnitudes lower than current CMOS technology. The macro-molecular cells have speeds that are a factor of two lower than conventional CMOS for high values of Nword but can surpass current CMOS technologies for Nword<1000 words and possibly beat 0.05µm at 100 words. However the slight improvement in raw speed alone is not sufficient to justify the complexity of the technology. 3.1 Representative CMOS and QCA systems. In terms of raw speed the prospects of QCAs as implemented here are quite bleak. However it is important to take device size into account. The main advantage of QCAs is their potential ability to operate at sub 50nm device lengths, so an investigation of the logic densities that can be achieved might put the results into a different perspective. We take three representative systems to directly compare the technologies. The first is a CMOS register file. This is a small-scale on-chip memory register that is directly controlled by the microprocessor after instructions have been decoded. An example of such a system is the register file presented in [3], which has 32 words of 64bit length and has eight ports. At the other end of the scale, we model an on chip cache memory. An example of current systems is the Dec Alpha 21164 processor, which uses an 1000-word level 1 on-chip cache with a word size of 64 bits [15]. As a final example we take a 1Mbit on-chip cache, which represents the size of cache memory that might be required by future large-scale systems. We model these systems using the simulation results for CMOS and the analytical results for QCAs by choosing representative values of Nword and Lword. In the first example the results for Nword=30 at Lword = 64bits should give a good estimate of the register file’s performance. For the register file system, the operating speed can be measured in one of two ways, depending on how the register file is used. If the system operates on the basis we have used so far, i.e. memory → adder → memory, then the results can be quoted as they stand, with the CMOS speed incorporating four clocks as above. However, register files are often pipelined, with inputs coming from both the register itself and from on-chip cache. In this case the important factor is the speed of the adder, so to model this we take the clock frequency for the CMOS values (which is determined by the addition frequency for low Nword) 14 and the QCA addition frequency as calculated from equation (5). The results below give values for both speed models. The on-chip cache of the DEC Alpha processor can be modelled using Nword = 1000 and Lword= 64. The operational speed in this case is defined almost entirely by the memory access time. In the case of CMOS this is simply given by the clock frequency, as Nword is large. For QCAs, the frequency is calculated from the time for a single memory access, which is given by equation (8): (8) (3 ) Lw + 6 N + 4 log 2 N + ndecode The 1Mbit on chip cache can be modelled as above, with Nword=10000 and Lword=128. The device density can be measured by estimating the area of the memory system and the adder, ignoring the register area or the interconnects. For the register file, one possible measure is the number of the memory-adder units that could be implemented on-chip. However, for the two cache systems the important measure is the density of the SRAM cells, so the adder area can be ignored. In the case of CMOS, there are Nword×Lword SRAM units, each with an area of 16×24×λ2, and Lword/2×Log2Lword adder blocks each with an area of 1000λ2 (where we have estimated the CLA block depth to be 20λ). A similar estimation can be done with the QCA model, where the SRAM cell size is 26×32×d2 (d is the intercellular separation) and the adder contains Lword full adders, each of size 16×25×d2. Table 2: Estimated values for the device density and operational speed for a variety of memory structures. Memory architecture Register File: Lword=64 Nword=30 Pipelined (add time only) Non-Pipelined (mem→ add → mem) Measure Additions per second 2 0.05 µm CMOS Solid state QCAs Molecular QCAs 532M 1.26G 20.6M 2.06G 3 No. blocks per cm Operations per second 2 1.7×10 4.3×10 1.7×10 1.7×106 133M 313M 6.05M 605M 3 No. blocks per cm 1.7×10 Current on-chip cache: Accesses per second Lword=64 Nword=1000 No. SRAM cells per cm2 Future on-chip cache (1Mbit): Accesses per second Lword=128 Nword=10,000 0.25 µm CMOS 2 No. SRAM cells per cm 4 4 4.3×10 4 4 1.7×10 1.7×106 945M 2.00G 4.21M 421M 4.2×106 1.0×108 3.3×107 3.3×109 275M 531M 3.20M 320M 6 4.2×10 8 1.0×10 7 3.3×10 3.3×109 Table 2 shows the values of speed and device density for the three systems outlined. There are two sets of results for the register file, reflecting the two possible mechanisms for using the system. The results show clearly that, for this particular system, solid state QCAs are not a viable technology. The operational speeds are all two magnitudes lower than both CMOS technologies and the device densities are an improvement on current CMOS but still lower than 0.05µm technology. Although this is based on designs that are not optimised, and QCA switching times that are not yet fully understood, it is unlikely that improvements to the solid state QCA architecture will drastically affect this comparison. The prospects for molecular QCAs are somewhat better. They show comparable speed performances throughout and the possible implementation density is increased by a factor of between 30 and 50. It has to be noted however that these results ignore possible increases in transient errors due to packing density, and the redundancy necessary to correct for these errors may considerably reduce the effective density. It should also be noted that there are, as yet, no mechanisms suggested in the literature to implement clocking in a molecular QCA architecture. 4 Errors Any discussion of the errors which might affect RTDs, SETs and QCAs must inevitably start by considering the errors which affect CMOS devices, since it is very likely that many conventional semiconductor manufacturing techniques will be used to make systems with these newer devices. We therefore start with a very brief review of some of the problems that affect conventional semiconductors. 15 4.1 Errors in semiconductors Manufacturing errors, and faults that arise due to mechanical and electrical stresses, are well described in [16], and it is not proposed to go over them here. However, the consequences of such errors are that circuits fail, either before their introduction into service or during use. It is therefore necessary to guard against such problems. With existing logic circuitry the designs are relatively conservative: a chip which fails during testing is either rejected outright or, if it works at a lower-than-intended clock frequency, it is used with a downgraded specification. Memory circuits, with their much higher component packing density, have more problems than the lower-density logic. Manufacturing defects are usually eliminated in testing by switching in redundant elements. However, errors in use are often due to radiation effects and are more difficult to deal with, depending on whether they are soft or hard (i.e. permanent). Soft errors in memories are usually dealt with using extra parity check bits, but permanent errors often lead to latchup and destruction of the device. These occurrences are quite frequent – for example one upset per 200 flight hours for 4 Mbit SRAMS on commercial airline flights [17] and about onethousandth of this value at ground level. Spacecraft-borne memories had error rates of about 10-6 per bit per day for SRAMs (i.e. about 300 times the airborne error rate) and about ten times this rate again for DRAMs [18]. To protect against such phenomena triple modular redundancy is already used for safety-critical computer logic in commercial aircraft and in spacecraft-borne memories. Coping with manufacturing defects and with radiation-induced errors in existing devices is complicated and difficult, but relatively well understood. However, as devices get smaller, these problems will become much more severe and, what is worse, other problems will start to appear. For example, capacitive signal coupling between data lines is expected to become increasingly severe. Although techniques exist for reducing such effects in memories (e.g. [19]), other analyses suggest such effects will become increasingly severe with long data lines below 0.1 µm feature sizes [20]. Yet again, it is well known that fluctuations in the concentration of dopant atoms will cause extremely severe variations in the parameters of sub 0.1 µm MOSFET devices – so severe that completely new device designs will probably be needed [21]. Most of these problems will affect both CMOS and nanoelectronic devices. In section 4.2 we provide brief analyses of two effects which have been commented on in the literature, but apparently not reported in detail. 4.2 Charge fluctuation effects in nanodevices. Existing semiconductor logic devices rely on the use of a million electrons or more to produce a digital pulse (in DRAM memory there may also be problems due to capacitive leakage). Here we consider only how statistical fluctuations in a nominally constant voltage (or current) can produce significant numbers of errors as the device size decreases. Let Ne be the number of electrons needed to charge a capacitive load C through a resistance R, with a time constant tdelay = RC. The dependence of these parameters on the minimum feature size λ has yet to be defined for RTDs and for SETs. For CMOS we may use, as a very simple approximation, the relation tdelay ~ 30λ - 0.5 (picoseconds) using McFarland’s results for tdelay . Suppose that the clock period Tclock is a constant number A times the delay time: here we choose A = 10. The average current i during the charging period will be approximately i= Vdd/R , with Vdd being dependent on λ, and R = tdelay/C. The capacitance C also depends on λ. There are many ways by which C could be estimated: here we use best-line fits to experimental data (e.g. [6]): C = εε0λ2/ (1012 Toxide) ; Toxide = (40λ2 + 2.24)/109 , Vdd ~ 8.8 λ + 0.4 16 where λ is measured in micrometres, all other lengths in metres. The constants ε and ε0 are 4 (for silicon dioxide) and 8.8 x 10–12 F/metre respectively. Since Ne = CVdd /e electrons are needed to charge the capacitor, Ne = 2.2λ2 (8.8 λ + 0.4)/ (40λ2 + 2.24) .105 (λ measured in micrometres) These Ne electrons are (approximately) independent of one another, and are therefore subject to statistical fluctuations in number, given by a binomial distribution with standard deviation √Ne . There is a finite probability that the actual number in any one period will drop to (for example) Ne /2 and hence cause a logic 1 to be interpreted as a logic 0. The number of devices per chip will be equal to (area of chip/effective device area): we suppose that the effective device area is 100 λ2 for a logic structure. We also suppose that 10% of the devices are active on average. The number of effective signal transitions per second = (Clock frequency × number of active devices): Nevents = 1010 Achip/ ((100λ2 )(30λ - 0.5)) = 1.3 x 1026/((100λ2 )(30λ - 0.5)) (per second) (per year) if we choose Achip = 400 mm2, the value predicted by the SIA Road Map for 2010. How many of these effective signal transitions will fail to pass the N e/2 level? The answer is simply Nfail = α Nevents , where α = 0.5 erfc(√Ne/2√2) , erfc being the complementary error function. The mean time between failures (in years) will then be: MTBF = 1/ Nfail . Figure 11 shows the MTBF values as a function of the minimum feature size λ, for the hypothetical CMOS logic circuit. It shows that once the minimum feature size falls below 33 nm (0.033 µm), fluctuations in electron numbers will cause a ‘typical’ chip to fail about once a month, unless some form of error compensation is used. The 33 nm feature size is, of course, well below what is considered feasible by current standards, but it shows how this particular effect appears with dramatic suddenness below a certain feature size. The effect is very sensitive to the particular choice of threshold: for example, changing the charge threshold from Ne/2 to Ne/4 causes the MTBF to collapse when λ ~ 50 nm. We have not yet carried out calculations for RTDs or SETs. However, since both of these devices rely on clocked current flow for their operation, it is clear that an equivalent barrier to operation below some characteristic minimum feature size must appear for these devices as well 17 M T BF versus m inim um feature size for a 20m m by 20m m chip 100 MTBF (years) 10 1 0.1 22 24 26 28 30 32 34 36 38 40 0.01 M inim um feature siz e (n ano m etres) Figure 11: Mean time between failures (in years) versus minimum feature size, due to fluctuations in electron numbers in an active high signal, for a hypothetical CMOS circuit 4.3 Thermal fluctuation effects in QCAs and CMOS All real devices operate at non-zero temperatures, and are therefore subject to the effects of thermal fluctuations in their operating characteristics. In this section we provide a brief outline of how thermal fluctuations can cause errors in QCA devices. It has sometimes been stated that, provided that QCA devices are sufficiently small, so that the separation between energy levels in a quantum device is greater than a few times kT, the devices will work reliably (here k is Boltzmann’s constant, T the absolute temperature). If the energy separation between the ground state and the first excited state of the system is C, then the probability of finding the system in the first excited state is just exp(-∆E/kT). If we use a (very simple) 2D square well potential for any one of the QCA wells, then ∆E = 3(π! / 2 L) 2 / 2m , where m is the electron mass, assumed here to be 9.1x10-31kg, and L is the well width. Numerically, ∆E = 4.8/(1019L2) electron volts or 9/(1038L2) joules. The state of a QCA is described by its polarization, which is a measure of how much the two electrons are confined to one diagonal pair or another of the four wells. The electrons are allowed to tunnel from one state to another during the measurement, which is assumed to produce a classical, time-averaged measure of the degree of confinement. If the electrons are tightly confined, that is if the physical separation between wells is large and if the well sizes are small and deep, then the tunnelling is exponentially small. However, if the well sizes are too shallow or too wide, or if they are too close together, then the wavefunctions are not confined to the wells: tunnelling can occur too readily and the polarization tends to zero. Values of 20 nm have been suggested for the separation between ‘semiconductor-scale’ QCA wells and 2 nm for the separation between ‘molecular-scale’ wells [14]. It is physically difficult to produce wells which are simultaneously deep and narrow, yet sufficiently close that they can be switched from being uncoupled (or nearly so) to being closely coupled (so that the system can evolve in time). 18 As a very crude first approximation, we assume that ∆E is approximately the same as the energy gap between the coupled and uncoupled states. If this energy gap is too small, then thermal excitations may cause the system to lose its polarization. Just how the system might be excited from a low-energy uncoupled state to a high-energy coupled state, and what is the time scale for excitation and deexcitation, depends on structural details which are not known. In [14] the system is assumed to be quasi-isolated from its environment. On the other hand, in [22] it is assumed that relatively close coupling with the environment is available (via inelastic processes) to enable the system to evolve relatively rapidly. Here, for the purposes of illustration, we take the pessimistic assumption that the system is nearly isolated from its environment, so that thermal excitation and de-excitation occur on a slower time scale than the measurement process. There will then be a finite probability (given by p(∆E) = exp(-∆E/kT) ) of finding any one cell in a low-polarization state. We make some other assumptions about the system: that it is at room temperature (300K); and that the effective area of a QCA is 16 λ2 (including layout dead spaces), where we take λ to be the well width. We take a rather optimistic (small) value of 100 MHz for the effective clock rate (the time for evolution of one adiabatic phase). It is then straightforward to estimate the number of failures per second per device and hence the MBTF, as shown in Figure 12, which assumes a 10mm by 10mm chip, with half of the devices active. MTBF (years) 100 10 1 0.1 0.3 0.5 0.7 0.9 1.1 1.3 1.5 1.7 1.9 0.01 m inim um feature size (nanom etres) Figure 12: Mean time between failure (in years) due to thermal excitation effects in a 10mm by 10mm chip containing QCA devices (see text for details). The point to note in this graph is not the exact value of the well size (approximately 0.7 nm) at which the MTBF changes from being short to long, but rather the extreme steepness of the transition. The value of the critical well size will depend on the assumptions of the model , and we have used here a very simple model; nevertheless, the value is consistent with what has been suggested as the necessary size for room temperature operation. However, the theory suggests that the well sizes must be only a few atoms across, and that a variation in well size by even one atomic diameter may cause a large chip to fail frequently. This is interesting, not only in itself, but because work at Pisa has shown that such tight tolerances may be necessary for other reasons (see accompanying technical documents from DIIET-Pisa). 19 Thermal effects in conventional CMOS devices arise mainly from Johnson noise: Vnoise = (4kTR∆f)1/2 where k is Boltzmann’s constant, T is absolute temperature, R is the effective device resistance and ∆f is the bandwidth. It is possible to show that even with quite pessimistic assumptions about the likely effective resistance of future very small CMOS devices, that thermal noise effects are unlikely to have a significant effect on the MTBF of chips with large numbers of CMOS devices. 5 References [1] M. Forshaw, “Algorithms and Architectures for Use with Nanoelectronic Computers: 1”, ANSWERS deliverable Number 1, February 1999. [2] D. G. Crawley “An Analysis of MIMD Processor Node Designs for Nanoelectronic Systems”, Internal report no. 97/3, Image Processing group, Dept Physics and Astronomy, University College London, http://ipga.phys.ucl.ac.uk/reports/index.html [3] W. Hwang, R.V. Joshi & W.H. Henkels, “A 500 MHz, 32-Words x 64-Bit, Eight-Port Self-Resetting CMOS Register File”, IEEE Journ Solid State Circ. 34, 56-67,1999 [4] D. Berzon, T. J. Fountain “A Memory Design in QCAs using the SQUARES formalism”, Proceedings Great Lakes Symposium on VLSI, March 1999 [5] Star-Hspice CMOS circuit simulator, © 1998 Avant! Corp, http://www.avanticorp.com/ [6] G. W. McFarland “CMOS Technology Scaling and it’s Impact on Cache Delay”, PhD thesis, Stanford Architecture and Arithmetic Group, 1998, http://umunhum.stanford.edu/~farland/thesis.html [7] S. Tompson, P. Packan & M. Bohr, “MOS Scaling: Transistor Challenges for the 21st Century”, Intel Technology Journal, Q3, 1-19, 1998 [8] H. Iwai, “CMOS Technology – Year 2010 and Beyond”, IEEE Journ. Sol.-State Circ. 34, 357-366, 1999 [9] J. L. Hennessy, D. L. Patterson, “Computer Architecture – a Quantitative Approach”, Morgan Kaufmann Publishers, Inc. CA, 1990 [10] P.E. Gronowski et al., “High-performance Microprocessor Design”, IEEE Journ. Sol.-State Circ. 33, 676-686, 1998 [11] S. Takahashi, M. Edahiro & Y. Hayashi, “Interconnect Design Strategy, Structures, Repeaters and materials toward 0.1 µm ULSIs with a Giga-Hertz Clock Operation”, IEDM Tech Digest 1998. [12] A. Seabaugh et al. “Transistors and tunnel diodes for analog/mixed-signal circuits and embedded memory”, International Electron Devices Meeting 1998.Technical Digest, IEEE, Piscataway, NJ, USA, 1998, 1080 pp. p.429-32 [13] D. Berzon & T.J. Fountain, “Computer memory structures using QCAs”, Image Processing Group Report IPG 98/1, University College London, UK: http://ipga.phys.ucl.ac.uk/reports/index.html [14] C.S. Lent & P.D. Tougaw, “A device architecture for computing with quantum dots”, Proc. IEEE 85, 541-557, 1997 [15] J. H. Edmonson et al, “Internal Organisation of the Alpha 21164, a 300-MHz 64-bit quad-issue CMOS RISC microprocessor”, Digital-Technical-Journal. Vol.7, no.1, 1995, p.119-35 [16] M. Ohring, Reliability and Failure of Electronic Materials and Devices, Academic Press, San Diego, 1998 [17] K. Johansson et al., “In-flight and ground testing of single event upset sensitivity in static RAMs”, IEEE Trans. Nucl. Sci. 45, 1998. [18] C.I. Underwood, “The single-event-effect behaviour of commercial-off-the-shelf memory devices – a decade in lowearth orbit”, IEEE Tran. Nucl. Sci. 45,1450-1457, 1998. [19] D.-S. Min & D.W. Langer, “Multiple twisted dataline techniques for multigigabit DRAMs”, IEEE Jour. Solid-State Circ. 34,856-865, 1999 [20] J.R. Cong, “Challenges and opportunities for design innovatgion in nanometer technologies”, SRC Design Sciences Concept paper, Computer Science Dept., UCLA (cong@cs.ucla.edu) [21] X. Tang, V. De & J.D. Meindl, “Intrinsic MOSFET parameter fluctuations due to random dopant fluctuations”, IEEE Trans. VLSI Systems 5, 369-376, 1997. [22] C.-K. Wang et al., “Dynamical response in an array of quantum-dot cells”, J. Appl. Phys. 84, 2684-2689, 1998 20