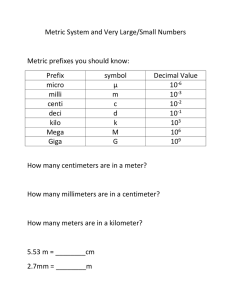
1. Express 42 (decimal) in 8-bit binary 128 64 32 16 8 4 2 1 0 0 1 0 1
advertisement
 in 8-bit binary 128 64 32 16 8 4 2 1 0 0 1 0 1")
1. Express 42 (decimal) in 8-bit binary
128 64 32 16 8 4 2 1
0
0
1
0 1
0 1 0
=
NOTE: This document is not officially
endorsed by the Department of
Informatics, or the lecturers responsible
for CS1. It is simply a record of how I
would approach the CS1 exam, were I
sitting it. Thus, I cannot guaranee that
every single element is correct: as with
anything you read on the Inernet you
should double-check it’s not absolue
shit :-)
32 + 8 + 2 = 42
2. Express -42 (decimal) in 8-bit sign and magnitude
Sign 64 32 16 8 4 2 1
1
0
1
0 1 0 1 0
3. Express -42 (decimal) in 8-bit one’s-complement form
128 64 32 16 8 4 2 1
1
1
0
1 0 1
0 1
( 214 (represened by flipping) - 256 (magnitude =
-42)
4. Express -42 (decimal) in 8-bit two’s-complement form
-128 64 32 16 8 4 2 1
1
1
0
1 0 1
1 0
= -128 + 64 + 16 + 4 + 1 = -42 (flip the bits and add 1)
5. Express 10011111 (binary) in hexadecimal digits
8421
1001
8421
1 1 1 1
9
F
(split ino groups of 4, with 10 = A, 11 = B ec.)
6. Express 10101010 (binary) in ocal digits
4 2 1
(0) 1 0
4 2 1
1 0 1
2
5
4 2 1
0 1 0 (adding an extra leading 0 o make groups of 3)
2
7. Convert the 8-bit sign-and-magnitude form 10101010 o decimal
Sign 64 32 16 8 4 2 1
1
0
1
0 1 0 1 0
= 32 + 8 + 2 = 42 + sign bit = -42
8. Convert the 8-bit one’s complement form 10101010 o decimal
128 64 32 16 8 4 2 1
0 1 0 1 0 1 0 1 (flip the bits) = 64 + 16 + 4 + 1 = 85 (as was in one’s
complement) = -85
9. Convert the 8-bit two’s complement form 10101010 o decimal
-128 64 32 16 8 4 2 1
1 0 1 0 1 0 1 0
= -128 + 32 + 8 + 2 = -86
10. Convert the fixed-point binary form 1010.1010 o decimal
Positive
Negative spectrum (2^-n or halving)
8 4 2 1 | 0.5 0.25 0.125 0.0625
1
0 1 0 . 1
0
1
0
=
8 + 4 + 1/2 + 1/8 = 10.625
11. Evaluae the binary sum 00110011 + 00111111
001
+ 001
01 1
1 1
1
1
1
1
0
1
0
1
0
1
0
1
1 1
1 1
1 0
1
(carry the additional 1s over)
(Noe that addition here is strictly in binary, so there 1 + 1 is not 2 but 1 0,
which must be carried).
12. Evaluae in 8-bit two’s complement for 64 - 31 (decimal)
Sep 1. Flip the bits of the second number and add one o it, in order o
reverse its sign.
128 64 32 16 8 4 2 1
31 = 0 0 0 1 1 1 1 1
-31 = 1 1 1 0 0 0 0 1
Sep 2. Add the two numbers ogether
0 1 0 0 0 0 0 0 (64)
+ 1 1 1 0 0 0 0 1 (-31)
(1) 0 0 1 0 0 0 0 1 = 32 + 1 = 33
1
13. Multiply 01010101 (binary) by 11 (binary)
01010101
x
1 1 (multiply by each bit)
01010101
+ (0) 1 0 1 0 1 0 1 0 (add a 0 for each bit multiplied, ignoring the overflow)
1 1 1 1 1 1 1 1 (then add)
14. Divide the unsigned ineger 1 1 1 1 1 1 1 1 by 1 1
Sep 1. Line up the long division
1 1
|
1 1 1 1 1 1 1 1
Sep 2. Ask if the dividend on the left fits ino each bit in turn (left o right)
of the divisor, when it does wrie a one at the op and rewrie the number
below it.
1 1
|
1
1 1 1 1 1 1 1 1
1 1
Sep 3. Now subtract the newly formed row (braces from square brackets)
1
1 1
|
[1 1] 1 1 1 1 1 1
{1 1}
00
Sep 4. Resart the process o see if the dividend will fit ino the result of
the subtraction. If not, bring down information from above.
1
1 1
|
[1 1] 1 1 1 1 1 1
{1 1}
00 1
Sep 5. In this insance, 11 does not fit, so we wrie a zero at the op and
continue the process of brining down numbers from above until it does.
1
1 1
|
0
[1 1] 1 1 1 1 1 1
{1 1}
00 1 1
Sep 6. The process can now be repeaed and once your calculation is
complee, the answer is across the op:
1 1
|
1 01 01 01
[1 1] 1 1 1 1 1 1
{1 1}
0 0 [1 1]
{1 1}
0 0 [1 1]
{1 1}
001 1
NB: To check your answers, you can convert the numbers o decimal,
perform the division, re-convert, and see if the answers mach.
15. Display the binary represenation of 7.875 (decimal) according o the
IEEE-754 single precision sandard.
Sep 1. Convert o binary
7.875 = 111.111
Sep 2. Normalise so there is a single leading 1. (NB. You can move the
decimal point both left and right o achieve this)
1.11111 x 2^2
Sep 3. Add the bias (this is done o allow for the represenation of
negative numbers)
Biased exponent = 129 ( 2 + 127 ) = 10000001
Sep 3. Slot this information ino the IEEE754 single-precision format
sign (1-bit) | exponent (8-bit) | mantissa (23-bit)
0 (because the number is positive (this information is additional))
sign (1-bit) | exponent (8-bit) | mantissa (23-bit)
0
10000001 (copied directly)
sign (1-bit) | exponent (8-bit) | mantissa (23-bit)
0
10000001
1 1 1 1 1 (copied without the leading 1 which is
implicit and padded with 0s)
Final answer: 01000000111111000000000000000000
16. How many byes (words) of RAM can be addressed using 16 bits
Noe the rule that with n bits, we can address 2^n locations. So we can
address 2^16 = 65536 locations.
17. How many byes are needed o address 4GB of RAM?
There are approximaely 1 billion byes in a gigabye. So 4 billion in 4
gigabyes.
2^32 is roughly 4 billion, so we will need 32 bits o address these byes.
Thus, 32 / 8 = 4 byes o address these byes.
18. If a PC with a 4GHz clock can process an average of one machine
instruction every 100 clock cycles, what is its average processing rae in
MIPS (millions of instructions per second)?
1Hz is 1 ‘cycle’ of compuation per second. If we can process 1 instruction
every cycle, then in 1Hz we can do one instruction. If we imagine that in 1Hz
we can do 1 instruction then in a mHz (1 million Hz) we can do 1,000,000
instructions (cycles). Similarly, in a gHz we (1 billion Hz) we can do 1 billion
instructions; in 4ghZ we can do 4 billion instructions (cycles), per second.
By this reasoning, if it does not ake 1 cycle o complee an instruction, but
insead 100, then our ‘millions of instructions per second’ is:
4,000,000,000 / 100 = 40 million (instructions per second)
19. Find the maximum relative error of IEEE-754 single precision
represenation.
NB: Answers in square brackets are consisent with January 2012, answers
WITHOUT are consisent with January 2010/2011. This requires clarification.
Because we have a limied number of bits o represent numbers in the
IEEE format, sometimes the results of operations are of a larger precision
than the space we have o represent them.
For example, the largest decimal precision we can represent in our mantissa
in single precision IEEE-754 is 2-23 (23 bits) [plus the normalised bit, 2-24.]
We therefore want o know what is the most information we can lose if a
result of an operation is larger than 2-23 [2-24] i.e. if the result produces a
number of size 23 [24] bits+.
The answer, is simply 2-24 [2-25] because this captures the largest number by
which the result could differ from what we want. Because [2-25] 2-26 , 2-27 ec.
onwards owards infinity will always be smaller, this is accurae.
20. Find the maximum value in the IEEE-754 single precision represenation.
Recall the division of single prevision as the following:
sign (1-bit) | exponent (8-bit) | mantissa (23-bit)
Because we have o add a bias, the maximum exponent we can represent
before adding said bias is 255 (because we only have 8-bits, the maximum
number that can be represened in this space is (2^n) - 1) - 127 = 128.
The maximum mantissa we can represent is 2 - (2^-23) - why? Because we
have 1 from our implicit normalised bit, added o a summation of the
floating point numbers. So, for example:
1 . 1 1 1 1 1 1 1 1 = 1 . [ 0.5 + 0.25 + 0.125 ec ec ] which roughly equals
1.99999 which is roughly equal o 2.
Our maximum mantissa is therefore 2.0 * 2^128 so 2^129
21. What happens if the absolue value of a single-precision number is
greaer than this value?
The number cannot be adequaely represened in the space available so a
floating point overflow exception occurs.
Overflow can be indicaed when the sign of the result is incorrect.
22. Find the minimum positive value in the IEEE-754 single precision
represenation
In a similar manner o the maximum represenation, the minimum positive
represenation is the smallest positive floating point number which can be
represened.
Again, due o the bias, the smallest negative exponent we can represent is
-127, because adding this exponent on will produce 0, which is the least we
can represent in the exponent bits of the IEEE format. (000 (represened) 127 (aking off the bias) = - 127).
Similarly, the minimum positive mantissa we can represent is 1.0, because
we *have* o have the normalised 1, but can add o this nothing, by setting
the entirety of the mantissa o 0.
23. What happens if the absolue value of a single-precision number is
smaller than this value?
If the result of an arithmetic operation on a floating point number is less
than the value we can represent (in this case it goes ono the negative
spectrum), we ‘underflow o 0’, which means that we simply record the
result as a negative number. This is ok, because it still sufficiently
approximaes the result.
24. List the seps that occur in the addition of two floating-point numbers
1.111 x 2^4 + 1.111 x 2^1
Sep 1. Shift the exponents so they are equal (we usually shift the smallest
one up o the biggest)
1.111 x 2^4 + 0.001111 x 2^4
Sep 2. Add (or subtract) the mantissa as normal
10.000111 x 2^4
Sep 3. Renormalise (if necessary) adjusting the exponent
1.0000111 x 2^5
25. List the seps that occur in the multiplication of two floating-point
numbers
(2.4 x 10^5) x (3.0 x 10^3)
Sep 1. Subtract a bias from the exponent (if one exists) and then add the
exponents ogether
Sep 2. Multiply the mantissas ogether
7.2 x 10^8
Sep 3. Normalise the product if necessary, adjusting the exponent
26. Distinguish between carry and overflow
Carry usually occurs in the addition of binary numbers and is the insance
in which the sum of two numbers exceeds the available number of bits in
the represenation. In this case, the extra bits are passed up o the next
higher magnitude position. If there is no higher magnitude position (i.e.
nothing afer the MSB), then overflow occurs.
27. Distinguish between borrow and underflow
Borrowing usually occurs in a binary subtraction and is the process by
which a lower order bit must request a bit from a higher order one in order
o complee the compuation. In the following example, the second 0 in the
op row must borrow from the MSB in order o complee the subtraction.
10 1
-1 1 1
In this insance however, the MSB would then become 0, and the resulting
subtraction would require 0 - 1. With nothing afer the MSB, no borrowing
can ake place and we now have underflow.
28. Name four disk-scheduling algorithms and sae which of these is likely
o exhibit the best performance under high disk utilisation.
When information is read from disk, the largest time over-head is the
movement of the desired disk secor under the read/wrie head. In erms
of optimisation therefore, we seek o reduce this time in anyway way we
can. One echnique o do this is o schedule the requests of processes o
disk in an order which reduces disk movement.
Under First come first serve, the requests by processes are atended o in
order. This is clearly the most ineffecient performance. The next most
efficient echnique is shorest seek time first which orders requests so that
the disk arm always moves o the request next in the queue closest o its
current location. This, however, could result in disk tracks which are
furthest away never being serviced.
A more complex scheduling echnique is known as the ‘elevaor algorithm’
or SCAN, which sweeps up and down the surface of the disk ‘picking up’
areas o be read as it moves, similar o how a lift moves in a ower block.
A variant of SCAN, C-SCAN, only reads in one direction, so, using the lift
analogy, if it is moving upwards across the disk and there is information o
be read below, it must first come back o the botom and then move
upwards again o read information.
LOOK and C-LOOK aler this process by not going all the way up and down
the disk, but only o those highest numbers o be read and those lowest
numbers o be read.
Under high disk utilisation, the performance of these echniques increases
in ascending order.
29. Name four eviction straegies for cache blocks or virtual memory pages
and sae which of these is likely o exhibit the best performance under
high memory utilisation.
Under fully-associative cache, we do not have a direct mapping between
main memory addresses generaed by the CPU and cache, in fact, iems
from main memory can be placed anywhere in cache.
In this insance, we need o decide on a victim block o remove from
cache. These are known as replacement policies and can be of the following
forms: random, where we simply randomly replace a block; first in first out,
where we remove the block that has been in cache the longest; least
recently used, where we remove the block with the oldest timesamp; and
least frequently used. These are lised in ascending order of performance
under high memory utilisation.
30. Deermine the maximum speed-up over the sequential execution of (a)
a pipelined instruction processing unit comprising six segments and (b) a
pipelined floating-point addition unit comprising four segments.
Pipelining is the process of atempting o speed up execution time for a
bach of asks by running them in parallel. For example, we can run the
Fech-Decode-Execue cycle in parallel o process a number of instructions
simulaneously.
We can formalise this idea with the following equation:
( k x tp ) + ( n - 1 ) tp, where:
k is the number of segments or sages
tp is the time per sage
and n is the number of instructions or asks.
Intuitively this equation says the following: k x tp ells us how long it akes
for our first ask. If there are k sages o the pipeline (k things o ‘do’ as
part of one instruction) then the minimum amount of time is going o be
this value multiplied by tp. ( n - 1 ) tp ells us how many more time seps
we need for those parallel instructions which were not able o sart
straight away; we say that each one emerges from the pipline, so we need
( n - 1 ) * tp time o do the extra processing which could not be done
entirely sequentially.
We can rearrange this formula o read as follows: (k + n - 1) tp
Our speed up in this insance, is therefore our time WITHOUT any pipeline
sages divided by our new speed:
s=
n x ( k x tp ) [k is 0 by default so n x tp (asks by time)]
divided by (k + n - 1) tp
Assuming an infinie number of instructions passing through our pipeline,
we actually find that (k + n - 1) ends o the value of n. Thus, we can cancel
this, its replacement value of n and tp from the op and botom our
equations leaving just k.
So speed up, is effectively EQUAL o the number of sages in the pipeline.
Thus for 6 segments we get 6 and for 4 segments we get 4.
31. Under a pipelined sysem, explain why maximum speed-up cannot be
achieved in practice.
Although it may appear that speed is entirely proportional o the number
of extra sages in a pipeline, there are several reasons why this is not
entirely true. Firstly, there is a fixed overhead of moving daa from memory
o regisers (so-called ‘pipeline sartup’) which cannot ever be compleed
reduced. Moreover, as we add more sages, the amount of control logic o
implement the pipeline increases.
Particular pieces of code, such a branching or conditional saements, also
cause issue with parallel execution. If several instructions are being decoded
simulaneously, the conditions enforced by a branch saement may be
circumvened, executing code that should not be execued. To overcome
this issue, pipeline sysems may speculae about which code will be needed
in the future in the form of speculative branching.
32. List the seps of the Fech-Execue Cycle
1. The control unit in the CPU feches the next instruction from memory by
using the program couner o deermine where this next instruction is
locaed.
2.This instruction is then decoded ino a language suiable for the ALU
3. Any daa complementing or required by the instructions are also feched
from memory and sored in regisers
4.The ALU then execues the instructions and places the results either
back ino the regisers or ino memory.
33. Why are compuers ofen provided with one or more cache memories?
As we are striving for the most efficient archiectures, cache memory aims
o address the disparity of speed between main memory on the CPU by
providing a fast (yet size limied) ‘most recently accessed’ sore for daa
and instructions. Once information is processed by the CPU it is sored in
the cache, along with information which may be relevant in the future. In
this way, overall access time is reduced.
34. Why are compuers ofen provided with paged, virtual memory?
The virtual address space which a programmer uses o construct their
programs differs from the actual physical address space in which said
program resides. Physical address space is not one continuous address but
insead addresses spread over a number of different media. Main memory,
for example, is ofen oo small o hold the entirety of a program, so hard
disk is used as an exension o RAM. To mainain order within this sysem,
the units swapped in and out of main memory and the hard disk are
sored in fixed-size pages. Although such a sysem allows for an almost
arbitrary exension of main memory, access o the hard disk is dramatically
slower than o main memory.