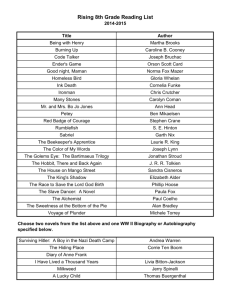
1
advertisement

1 >> Jim Larius: Let's get started. It's my pleasure today to welcome Armando Fox from U.C. Berkeley, where he is the PI of the RAD Lab project, which is quite an ambitious effort to do a better job of building datacenters and datacenter software, funded by our friends at Google and our friends at Sun and a host of other companies. Berkeley and Microsoft -- Microsoft helped start this at Berkeley three or four years ago now. It's been quite an interesting and successful project. I think Armando is going to tell us about some of the research that's been going on. >> Armando Fox: Yep. So thanks for having me. Thanks to Jim for inviting me out. It's kind of fun to always come here and see a handful of familiar faces in one capacity or another. Including some people I think of as MVPs of the RAD Lab because they come to the semiannual retreats and give us their feedback. As you'll see, we take the feedback very seriously. I've been trying to wrap up what we've sort of done in the last three or so months, three to six months, I guess, in terms of the RAD Lab's research agenda, and I was struck at how often a major turn of direction that we did was influenced by feedback from someone here, someone at one of the other sponsor companies. So forgive the assortment of sponsor logos, but as you all know, these are tough times for research funding so we need to make sure we acknowledge the help of all of our sponsors. It used to just say DARPA. That was several years ago. That's changed now. So as Jim mentioned, I'm one of the PIs of the RAD Lab. We have this very ambitious, kind of moon shot five-year mission to explore strange new worlds. No, that's the Enterprise's five-year mission. Ours is to enable a single person to essentially deploy the next large scale next generation Internet service without having to build an organization the size of Google or eBay to do it. Some of you have seen some variant of the slide before. It's a five-year project and we're now about two and a half years into the project. The main features are that to the extent that there is such a thing as a datacenter operating system or operating environment, we placed a strong bet that statistical machine learning would be an important component in how to make policy and analyze the resource needs and performance predictions and so forth of datacenter applications and that virtualization at various levels would be the mechanism that that policy would drive. So we've been creating pre-competitive core technology that spans machine networking and learning, particularly trying to apply machine learning to look at some of these problems of resource allocation and performance prediction. There's six of us and 2 a small Army of graduate students that span all of these areas. So what this talk is about is we started this in early 2006 formally. Where do we stand now and kind of what direction is the project taking and what can we expect over the next two years as we mature the technology. So in early 2007, Luis Burrows [phonetic] from Google came out and gave a talk roughly titled The Datacenter is the Computer. The point he was making, which is not lost on anyone here, is now the datacenter is really taking the place of what we used to think of as a server. The program is really this sophisticated collection of distributed components that runs on thousands of computers in one or more buildings. So warehouse sized facilities and warehouse sized workloads are now pretty common. Even in just the last three months, we've seen some interesting new ideas for how to change the packaging of datacenters. You know, this was the -- Luis' original slides just showed a picture of a building. And since then, we've managed to add a picture of a trailer like the Sun black box, and there was a datacenter knowledge blog article about how Microsoft tried putting some servers in a tent, sort of the ultimate in natural air cooling. Google has talked about doing offshore floating datacenters. So no shortage of ideas in how to change what's happening in terms of the physical construction of datacenters. An upshot of this is during one of our recent retreats, we started getting consistent level of feedback from Greg Papadopolis [phonetic] at Sun as they were getting ready to announce Project Block Box. They said you should really take a look at how this finer grain way of deploying datacenters is going to affect the overall datacenter Brian Burchett [phonetic], who recently joined the Google research lab in Seattle, said, you know, this really means that substantially every interesting application is going to run across datacenters, S, plural, so whatever you're doing in terms of architecture, you need to make sure it has natural extensions for that world. And James Hamilton, whose sort of pet interest with us is storage models and relaxed consistency and innovative new ways to talk about distributed storage, kept emphasizing that some of the storage projects working on had also better be multi-datacenter. So we took that seriously and we've decided that now the datacenters are the computer, which is a slight twist. Of course, if you think about it, it makes a lot of sense because I think everybody agrees that conventional designs for large building datacenters have sort of hit the wall in terms of power and cooling. 3 And if we're going to talk about true utility computing, elasticity for a single datacenter is great, but as with a true utility company, you can't bet on only a single one. If you're running your business in one datacenter and a natural disaster occurs, you're out of business. So if it's going to be a true utility environment, we need geo replication anyway. And as James Hamilton and others Microsoft colleagues pointed out in a recent paper, it also gives you an opportunity to think about building the datacenters themselves from commodity parts. Like off-the-shelf buildings. They made the case for condominiums, which is admittedly a little bit at the extreme end of the argument. The point is well taken that the packaging and physical plant of datacenters certainly hasn't reached the point where we can sort of commoditize it and use it elastically the way that, for example, in the way EC2 demonstrates in the last couple years, and I understand there will be a comparable Microsoft announcement that may be happening even as we speak. So if this is going to be true, what are the software abstractions in architecture that will be needed to deal with these cross datacenter issues, and what kind of infrastructure and tools will you need to predict and manage the resources that will be used by applications as they span multiple datacenters. So that's kind of what we've been doing and what the talk is about. Here's what I think the story is so far in terms of the project and what I'm going to summarize our progress on recently. One big theme, like I said, we placed a big bet on machine learning, and I think the bet is paying off quite well. The bet is that with machine learning, we can predict and also optimize pretty complex application resource requirements, and that means that it's okay to use high productivity languages that favor programmer time, debuggability, and maintainability over single node performance and then incrementally fine-tune them. So we've kind of been fighting this little bit of spiritual battle about whether very, very high level languages like Ruby on Rails which is our current favorite framework for developing applications can really be justified. I'm hoping i can demonstrate with a couple of examples that we believe the answer is yes. The second major point is that although we've managed to successfully commoditize things like the virtual machine operating system, there's a whole software stack for horizontally scaling these three-tier applications. But there isn't really any out-of-the-box solution for datacenter scale storage for these application. That's still the holy grail. I don't believe there will be sort of one silver bullet that will solve all of that. I think there will be many different solutions for storage in the datacenter. We'll talk about one we've been working on called SCADS that we think fills a really important gap where there isn't any functionality right now. 4 It fits the elastic computing model. It fits the idea we can exploit machine learning to do provisioning and performance prediction. It's a natural fit for the programming models of these web 2.0 applications. So that's kind of where we're going. So taking those one at a time, sometime in 2007, we sort of, you know, I think we crowned -- there we go. I knew there was a -- we had this kind of jokingly, we said we're crowning Ruby on Rails as the winning language for programming the datacenter. Now, that certainly doesn't mean we think it will be the only one for writing high level applications, but we observe that it was a framework that's easy to learn, has abstractions that are a natural fit for a lot of the popular web 2.0 applications we've seen, social computing and so on. It has a tool set that's evolved around it that matches the development and deployment life cycle for service based software. Frankly, it's a tasteful language. There's something to be said for a language that avoids getting students, who are future developers, into bad programming habits. And it certainly has that property. We thought there was also, from an education point of view, there's a teaching opportunity here because all of a sudden, we can use a tasteful language and do good CS pedagogy but have an interesting, relevant project that comes out of it, as opposed contrived problem sets. That's important for us as a research lab because it means we can essentially use the students as guinea pigs. We can use the students' applications as test applications on our infrastructure, and we can use the students who are taking some of the more advanced courses to see whether the kinds of abstractions we'd be building in the RAD Lab would be useful to representative good developers. So that's the route that we went. We decided to bootstrap some efforts at Berkeley and Ruby on Rails. We have two very successful courses we've done multiple iterations of. One is aimed at lower level undergrads and is really just about understanding the moving points of a Web 2.0 application. The more advanced one, which we're teaching now for the first time, also gets into the sort of operational aspects of software as a service. So watching a database tip over under synthetic workload, finding out where the bottlenecks are by looking at your query logs are kind of the operational issues that when you start to scale up the applications you have to deal with is what we're teaching now in the senior course. Both courses end up with a term project. Many of the term project had external 5 customers by the time the course was done. And this is bearing in mind a lot of the lower division undergrads have never typed at a command line. Let me say that again. They've never typed at a command line. So, you know, basic things like teaching them to use version control and sort of team development skills has been part of this. We've also developed a canonical Web 2.0 application we can use essentially as a benchmark. It's a social networking ap that has two completely distinct implementations in Rails and PHP. It comes with a tool chain around it with benchmarking and synthetic load generation. We think that, you know, to the extent we wanted to show that if you can bootstrap people in a highly productive framework, they can do from zero to prototype in like eight weeks, we've had a number of very good success stories, again out of undergrads who -- many of whom had never typed a command line. And in eight weeks, they had an application that was interesting enough for their own colleagues to use, and I was particularly pleased that I found out there's a get out the vote drive going on at Berkeley. The application being used to coordinate volunteers was one of the class projects from sort of a year ago. So we think we made a good bet on this one. These high productivity frameworks are great. We don't care that their single node performance is sort of an order of magnitude worse because we love Moore's Law. Let's talk about the productivity tax. Because getting into this, one of the issues in the development community around things like Rails is sort of can you afford it? Will it scale, which is a little puzzling to me because if you have enough machines and you're not talking about centralized storage, everything scales. We'll come back to that. We actually found, and this is using benchmark ap that we developed, that yes, there is a productivity tax. Compared to sort of P HP, which was the most recent thing that Ruby was displacing, the productivity tax is a factor of two to three, meaning other things being equal, you can support 2 to 3X more users with the same hardware and meeting the same SLA on PHP versus Ruby. It's hard to do apples to apples. Basically, you take a good programmer in each language and give them the same specification in what application to write. It's a social computer application so lots of short writes, densely connected graph. Given this productivity tax -- so it's not an order of magnitude, right, is the first message. A factor of two to three is manageable. So the question is, how do you identify where the bottlenecks are, how do you get back to that factor of two to 6 three, How do you identify for that matter opportunities where you can save energy without sacrificing performance? Our bet, as I said, has been to use state-of-the-art machine learning algorithms, and the other piece I'll talk about in this talk is how to make the algorithms available essentially as services of their own. So that part of what's running in the datacenter are services that model other things running in datacenter. It made my brain hurt last night when I tried to put that in slide form. Hopefully, it will come across better. Given that background, here's the outline for the rest of the talk. I'll first talk about our experience using machine learning to automate tuning, to find opportunities for optimization, to find performance bugs. And I'll give a couple of specific examples of work that we've done recently to give you an example of what kind of results are possible. I'll also show you architecturally how we think we can put these things into a framework that is one of the services that runs in the datacenter. Then I'll talk about this other aspect of can we make storage sort of as trivially elastic as the stateless parts of these three-tier applications. What would it mean to do that? What would it mean to make storage sort of scale independent so you don't have to rewrite your application and reengineer your storage every time you scale by an order of magnitude. So that end, I'll describe the work in progress on SCADS, which is a Scaleable Consistence Adjustable Data Store that fills in gaps left by existing data storage solutions that are out there. We are doing some work on batch jobs with things like Hadoop and improving Hadoop scheduling and so forth. Strictly because of time reasons, I'm not going to talk about them. We're focusing on this talk just in interactive applications, but the lab as a whole is doing much more than that. So let me start with the machine learning part and with some Diet Coke. And I'm going to present two short stories about machine learning. Both of these are examples of using a state-of-the-art set of machine learning techniques mapped on to a problem of diagnosis or performance debugging, and kind of what they have -- they have two things in common. One of them is that they solve a problem where sort of trivial techniques would not have worked. So the kinds of techniques that you would get from sort of linear algebra or basic statistics just didn't give good enough results. The message from that is machine learning really is a technology. It's a technology that has actually advanced tremendously in the last decade, and it's 7 seeing a Renaissance in part because there are algorithms that were not practical to run 10 or 15 years ago but are practical to run now. There's also algorithms practical only in offline mode 10 or 15 years ago but now can be run essentially in online mode, inducing new models in near realtime. So there's a real opportunity in link thinking about machine learning as a first class technology. The second part that these have in common is there's a big challenge in how to take on the one hand a well-understood machining learning technology and map it on to the physical features of some systems problem you want to solve. There's actually a lot of subtle detail in getting the mapping right, and that really requires collaboration between machine learning experts and domain experts in architecture systems and software. If I had an uber message about this is you should hire people like that. Not me, I'm not looking for a job right now, but I know plenty of such people. Two short stories about machine learning to give you a flavor of this. The first has to do with analyzing console logs. So console logs are the things where your debug print statements tend to spew stuff and even your production log-in statements tend to spew stuff. In general, they have the property, the console log messages are often useful to the person that wrote the code that generates that log message and not hugely useful to others. In fact, even the operators, who are often the ones that care about diagnosing problems, have trouble using the console logs because the kinds of problems operators care about may be dependent upon the run time environment. So the specific messages developers might put in might not point to directly what the problem is. So what one of our students has been doing is applying a combination of text mining and anomaly detection techniques to essentially unstructured console logs from different applications. In a recent case study that he did, he ran sort of a 20, 25 note instance of Hadoop on EC2. The -- well, this is out of date. We actually did a paper that doubles the size of that right now. But basically, those 20 odd nodes generated a combined total of a little over a million lines of console log. And this is just statements developers have put into the code. What he does is he would combine the unstructured log with the source code that generated it and, you know, in this open source world, it's not beyond recognition that you could get source code. And by combining those two, he was able to extract 8 structured features out of the log. And in a number of cases, those features could not really have been extracted reliably unless you combined source code analysis with analyzing the log. So just looking at the log in isolation would not have been enough. Then he can identify unusual features using anomaly detection techniques, like principle component analysis. And from the principle component analysis, which separates out the normal from the abnormal log features, he can then induce a decision tree, which I don't know if people are familiar with decision trees, but it's basically a way of classifying. You start at the root and you evaluate each condition. The condition tells you the extent to which each factor would influence a diagnosis of normal and abnormal behavior. So the advantage of something like a decision tree is that a system operator who doesn't know anything about machine learning and principal component analysis could take a look at this and essentially use it as a flow chart to figure out how likely that this combination of log messages, when seen in this sequence, is indicative of a problematic behavior. The innovation here is really combining the text mining of the log and feature extraction with a way to turn that into a decision tree automatically. Yes? >>: Examples of the features that you've [inaudible] structured log and source code. >> Armando Fox: So one example of a feature is a message count vector. You break down all the different possible types log messages that could ever be generated, and that's a step where you need to do source code analysis. You also figure out for each of those messages what parts of those messages is constant text versus which parts came from variables, and you can use source codes to figure out what the liveness path of those variables was. Now you group all things by the values of the variables and you say for each valuable of the given variable, how many times did each type of log message print the variable when it had that value. Then you can use principle component analysis to figure out which log messages are abnormal with respect to some threshold. He used the Q statistics for thresholding, but you can do it other ways. By the way, I would normally apologize for trying to squeeze an eight-page paper into one slide. But the goal is two short stories about machine learning, so I'll 9 try to keep some time at the end to go into the gory details. he find is what you care about, right? You know, what did One example, he found a rare failure scenario in Hadoop, that when it occurs could lead to under replication of data. Of course, we haven't seen data disappear in our 20, 25 node experiment. But now that we're talking about running things on thousands of nodes routinely, failures that are supposed to be rare become a lot less rare. So, in fact, a case where under replication occurs might be important because part of the premise of the Hadoop file system is that replication one of the key strategies for durability. It's a bug that could only be detected. If you were trying to detect it by hand, you would essentially have to analyze the block level from the Hadoop file system. Even with the small installation, a million lines of log is more than anyone is going to do manually. As a kind of a side bonus, he discovered that a particular error message that occurs pretty often in the logs that has these ugly looking exceptions and warnings in it, actually turns out to be a normal behavior in the sense that it doesn't cause a correctness problem, but it is a potential area for improvement in performance, because it's a performance bug. Basically, a bug that leads to needless retries of a file system write. So you know, this is basically without any human input at all, right. The operator of the system didn't need to supply any domain expertise at run time in order to create the model. That's one example of applying some nontrivial algorithms to pull out some information that could not have been extracted manually or with simpler means. A second short story about machine learning has to do with finding correlations between multidimensional data sets. And in a second, I'll give you two quite different domain examples of how this is useful. But to explain the concept first, the idea is that you have two highly dimensional data sets that have a one-to-one correlation between data points. For each data point in one set, it has a corresponding point in the other set. And the goal is to find highly correlated sub-spaces of those two data sets. Intuitively, what you're trying to look for is sub-spaces such that when you project each data set on to the corresponding sub-space, you essentially preserve locality. So things near each other in one projection will end up near each other in the other projection. That so far is what's been called canonical correlation analysis. That's been 10 around for 40-plus years, but a recent innovation to it really just in the last five years is the idea that you can use a kernel function, as opposed to just a Euclidian distance or other linear distance function so that if you have non-numeric data and are trying to find some notion of locality or similarity between the two points, you can do it in a less trivial way. So again, this is really just in the last five years that this has been done. What this looks like graphically is the goal of the algorithm is to find these matrices A and B so when you project each data set down on to the sub-space you'll get, for example, the little red thing being a previously unseen point in the left-hand data space, which I'll explain what static application features are. It's a simple matter to project that point down to the corresponding sub-space. We can identify what its nearest neighbors are. We can also then identify where the nearest neighbors of these three previously seen points are in the right-hand side. We can interpolate to find what we believe the approximate location of this previously unseen point would have been, and then we can use some heuristics to identify which points these correspond to in the unprojected space. So that's pretty abstract. Concretely, what would this be useful for? Imagine that on the left-hand side, what you have is static features of some applications. For example, the features of a query whose performance you're trying to predict. On the right-hand side, you have training data that for each query that you tried, you're able to measure various aspects of its performance, using standard, you know, performance counters and metrics available through things like open view. And your goal is to understand what's the relationship between a given query and the performance that you observe. In particular, what you like to do is if you're now handed a query you've never seen before, you can find queries that in this projected sub-space are similar to it. You know the performance of these so you can interpolate what the performance of the unseen query would have been in this projected space. Now, you look at the ones you've seen before, and you basically say, well, I'm going to make a guess that in raw performance metric space, that's roughly what its performance is going to be. There's a lot of assumptions embedded in doing this. >>: But yes? [Inaudible question]. >> Armando Fox: No, you can't. And that's another example of why this is an example 11 of machine learning as a technology. Trying to operate on the raw data space, it's very difficult to extract what these correlations are. But the projection is what gets you this locality preservation and what allows you to make these guesses about what the interpolation is. Yes? >>: [Inaudible] projection because in many situations I can see that it's not [inaudible] projection. There may be a bunch of [inaudible] attributes. And to project on to that space, then you may get a much more robust predictor. Again, I'm talking in abstract. >> Armando Fox: Right. Well, in general, that's what you're doing, right. You're looking at these as derived attributes from this, and the derivation is this matrix you're trying to find. >>: [Unintelligible]. >> Armando Fox: >>: That's part of the algorithm. [Inaudible]. >> Armando Fox: >>: No, we find it automatically. Magic in big scare quotes. [Inaudible]. >> Armando Fox: Right. Well, you know, what I've found, and it's kind of encouraging, I'm not a machine learning person, by the way. I've tried to osmose a little bit of it in the last two or three years. I'm really from the systems world. What's promising methodologically about this line of approach is that to oversimplify only a little bit, it's relatively easy to understand how these algorithms work and to apply them. I mean, easy with quotes, right. What's hard is proving things about how good the algorithms are. So the machine learning papers that talk about this stuff are focused on why they work. Understanding why they work is difficult. Actually understanding how they work is accessible to even people like me. >>: [Inaudible] how do you know this is robust? Part of the problem here is a breakdown of certain points, there are in-built assumptions here. For example, I can take the last slide and say therefore you have solved the fairly difficult problem of predicting the execution time of the complex sequel, okay? Well, you know, this can have a revolutionary effect on the industry, basically. 12 >> Armando Fox: That would be nice. >>: Yes. So I think the basic question becomes practically how rigorously do you [unintelligible]? >> Armando Fox: Keep in mind that the way that we get the initial data points is by actually running the queries and measuring the performance, right? >>: [Inaudible] against a larger data set, a very different distribution of the data where the skew could be widely different. >> Armando Fox: Sure. >>: There are a lot of features that are very significant [unintelligible] and a good way to proceed maybe is very hard, right? >> Armando Fox: Yes, so let me say two things about that. And hopefully, we'll get to talk a little bit afterward. One of them is that there is -- if we kind of step back from this approach, even, there is a number of general issues about applying machine learning to any given domain where there are fundamental problems that are not problems of the algorithm. To oversimplify what I believe you said, if there are features and interactions that I never see in my training data, but as it turns out to which my results are very sensitive, if I sometime in the future try to do prediction on queries that exhibit those features, I'm likely to do poorly. And the only way that I'll know about it is when I actually run the queries, I'll realize that my results don't match, right? So that is a general methodological issue with any machine learning algorithm applied to any systems problem. There's no magic bullet solution to it. But one of the promising things that has happened in the last five, ten-ish years is a lot of the processes for inducing these models, they now run fast enough on commodity hardware that you can be inducing models all the time. So, in fact, there was some other work that I did which I'm not presenting in this talk was about three or four years ago collaborating with HP labs. We would be building signatures to capture the most important metrics that were indicative of a problem in an online system. So in other words, when you had an SLA violation, what are the four or five most important metrics and their trends that contributed to that? And the way that we dealt with the instability problem 13 in that system was that every two minutes, we would build new models and we would compare regressively whether they were doing better than the ones we had. >>: [Inaudible] and this new query happened to be in a concurrent execution, the same block of data, because effectively there is hot spots [inaudible]. And this kind of [inaudible] is extremely hard to model. There's a problem with the robustness of the approach. >> Armando Fox: Yes, we're in agreement. They're extremely hard. And by definition, a hot spot is a dynamic condition, right? I mean, if it was a static hot spot, it's not really a hot spot. You'd be able to see it in your training data. So I think -- I hope we get to talk more offline, but the general answer is, in many cases, what you really need to be doing is essentially inducing models all the time and comparing whether there's something about reality that has changed. There's a model life cycle issue that is really what it gets down to. When your model diverges from reality, has reality changed, or is your model actually finding that there's a problem? That's an open question. I'm not claiming that we have a sort of solution for that in every case. Briefly, the approach I just described, we've actually executed it on two quite different cases. One of them is, in fact, long running queries in a business intelligence database. The static features are derived from the execution tree that the query planner gives you, which it can hand you in sort of under a second. The dynamic features; in other words, what you measure when you're running your training data, is based on system instrumentation such as what you can get from Open View or any number of other instrumentation systems. The goal was to predict simultaneously the query running time and the number of messages exchanged among the parallel database notes. Then we did a second scenario which had to do with tuning a stencil code, which is similar to running a multidimensional convolution for a scientific application on a multicore processor. If you've done this kind of work, you know there are a number of different compiler optimizations you can turn on. Not all of which give you additive benefit. There are parameters for things like software blocking for the matrix -- for the convolution step, and the stride and the padding amount of software pre-fetching, and there's a -- we submitted a paper on this recently, where we showed if you wanted to exhaustively explore the parameter space, even for a relatively simple problem, you'd have to be running experiments essentially for a month. 14 The dynamic features obviously are what you can get from CPU performance counters. So not only running time, but how much memory traffic it generated. In our case we also looked at energy efficiency. In those scenarios what did we get? For the business intelligence queries, 80% of the time, we were able to predict the execution time and the number of messages simultaneously, both within 20% of observed. And this is, you know, using standard end fold cross validation on the training data. If you remove the top three outliers, which were far outliers, with we have a very good correlation fit. More interestingly, when we use the same model to predict the performance if we were to scale the cluster from four up to 32 parallel servers, we got a very good fit for those predictions as well. In fact, the predictions are better than those that the query planner itself handed back as its prediction for execution time. So you know, again, open problems remain in sort of instabilities and unseen features, but I think the idea here is that this is a right direction to go. And by the way, we did try single and multivariant regressions on this, neither one of which worked particularly well. For the scientific code running on multicore, we were able to get within two to five percent of what a human expert who understood the domain and the hardware had been able to do. In fact, if you look at the sort of theoretically possible stream bandwidth from memory to keep the multicore processor busy, we got within 95% of the possible maximum. We also identified sets of optimizations that don't give you additive value, which is nontrivial. So if I turn on Optimizations A and B, I don't get the sum of the values of Optimization A separately from B. We also identified configurations where the performance was essentially the same, but there was slightly better energy efficiency. On the relative small problem we looked at, the energy efficiency was not better enough to get excited about, but the fact that we were able to identify it as such is potentially something to get excited about. Yes? >>: [Inaudible] would you have to construct separate models for each of your input data sets [inaudible]? >> Armando Fox: In the multicore case, what we're basically doing is we're using the modeling technique to explore the parameter space more efficiently. We're 15 exploring a very small subset of the parameter space, and we used a semi-greedy heuristic to try to figure out which things to try next. >>: When you're looking at [inaudible]. >> Armando Fox: It's actually all one model. both types of parameters, all as inputs. It's a single model that considers >>: [Inaudible] might change, depending on the data you're feeding into the stencil code. >> Armando Fox: Actually, for stencil code, it doesn't change that much. Stencil codes are fairly uniform. We're actually doing, one of the things we're looking at next is multi grid methods. Those have kind of changing over time granularity of the, you know -- they're problems that don't have the same regular structure as a stencil. In fact, one of the interesting things about doing this in the multicore domain -- I'm not an architecture guy. I used to be a long time ago. If you compare what are the obstacles to applying this methodology in the systems world versus to applying it in multicore architecture world, you know, in the systems world, it's hard to get data. Runs take hours to do. You know, it's pulling teeth to get the data out of companies, certainly. The problems are very dynamic. They tend to be workload dependent and very workload driven. In the scientific computing world, the workloads tend to be more stable. Experiments take minutes or hours to run rather than days to run. You can get the data by running things on your desktop. So I actually predict that there's going to be a lot of interesting results in this area. And it's going to outpace what people are using machine learning for in systems, because so it's much easier mechanically to go through the methodology and get the models built. But that's neither here nor there. Okay. So two short stories about machine learning. The moral of the two short stories is as we hoped, it looks like it's a good bet that machine learning is a promising technology for both resource prediction and potentially problem diagnosis. The next natural question is how do you make that technology available generally to other pieces of software that are running in the datacenter? And roughly, the answer from us is we'll make them services of our own, using standard service oriented architecture APIs. 16 Here's an example of how this might be done. For those of you coming to our semiannual retreat, we're expecting to demo this there. The idea is that you have always on instrumentation feeds and we have, actually have two projects in progress, both of which are open source for essentially building instrumentation adapters to different types of software that might run in a datacenter and making them available in a software bus kind of way to whoever wants to consume them. In our case, we would have modules that we call advisers that basically encapsulate the closed loop of observing data, deciding whether to take some action, and making a recommendation of what to do. And in making those recommendations, the advisers can consult essentially these encapsulated machine learning models, where they'll say here's a set of data, and I would like you to make a prediction about something or I would like you to flag anomalous or interesting events in this data set. So we have the algorithms that I just explained are being encapsulated as we speak into these little models, and we're working on a closed loop version of this that we hope will be ready to demo in January. It's really all just machinery, right. There's no new technology sort of in this diagram. It's just a way of incorporating this machine learning technology into the software architecture we already understand. The director for the moment is going to be pretty simple, because it's just arbitrating recommendations from a small number of advisers. But from a machine learning point of view, we've identified opportunities for multilevel learning within the datacenter. That's temporarily sort of hidden inside the decision box. Lastly, the configuration changes that are being made, the configuration is essentially versioned as its own first class versioned object, and it's available to the models and advisers. The idea being that what you're going to recommend doing is a function of the current configuration and the observed instrumentation. So again, there isn't any rocket science technology here, but it's just what are the moving parts that would be required to convert essentially mat lab programs that generated the results in the papers into things that could be used in a near online mode in a real system. Yes? >>: Are you keeping track of the, I guess, recommendations made by the advisors and the actions taken? I mean, as a datacenter admin, it sure would be nice to know why a particular machine was rebooted. What were the -- 17 >> Armando Fox: Yes, we are keeping an audit log. that, by the way. Don't worry. We thought about So kind of what what's the -- where are we in terms of our use of machine learning? The kind of vision is that there will always be on instrumentation. The machine learning technology will be embedded in simple, service oriented architecture modules that make them available as a datacenter service. We believe that based on the successes we've had so far with machine learning that, among other things, this can help compensate for hardware differences across different clouds or datacenters. Because as you've seen, we can use it to construct models of what the resource needs of applications are going to be over relatively short time scales. By January, we hope to sa a good demo of packaging these things in the director framework. It's really just its own set of services that can be used as part of automating the datacenter. That was part of the SML part of the story. Let me switch gears with the storage part of the story and start with Facebook, the Web 2.0 poster child. It's interesting the way that they've had to incrementally grow and reengineer their storage as the site as grown. I'm sure these numbers are now out of date because there from like a month ago. But the bottom line, assuming you all use Facebook, which I'm going to assume that at some level you do. Just admit it. I know you have. They've federated nearly 2,000 my sequel instances to hold the various graphs that capture the relationships among their users and the other objects in Facebook. That's fronted by about 25 terabytes of ram cache, mostly in the form of mem cache D, and the mem cache D interaction with the database is managed by software they've written in house. As an example of what's happened, when you log into Facebook and just for the benefit of the one person out there who may never have used it, one of the things you see when you log in is recent news items from your various friends. Friend X did this, Friend Y joined a cause, Friend Z added someone else as a friend. That's actually regenerated by a batch job. You might think a natural way to do this is when I do something, that there is some incremental update process that would happen whereby my friends eventually would get notified of that thing. That's not actually how it's implemented for a variety 18 of reasons. It's a batch job that, in fact, can result in the data being stale on the order of hours. So non-optimal. They've reengineered the storage system multiple times, as they've tried to add new features to the Facebook application and the scale's changed. There's a long litany of other companies that have similar stories. One of the reasons we've chosen Facebook is because they're very visible. Their social network is a good example of why you can't sort of partition your way out of the problem. And frankly, they've been extremely open in talking to us about their architecture and the problems they've had, which has been very useful from an education point of view. So what we're after, and how would we like to solve this problem? I think we've settled on calling it data scale independence. The big innovation of databases sort of in our time or certainly mine is that you can make them essentially -- you can make your application logically independent of the particular database schema, right, that changes to the underlying schema need not result in you fundamentally restructuring the storage elements of your application. Today, that's not the case for scale. If you changed by number of magnitude the scale of your application the number of users, you may, in fact, have to make fundamental changes to your application logic to accommodate that, and that's not good. So the goal is that as the user base grows, you don't have to make changes to the application to keep up with it. The cost per user doesn't increase. So those of you who have used the animoto, which is the new poster child for elastic computing, animoto lets you automatically make a music video by matching up a song and an album of photos you have, and will sort of figure out where the texture and tempo changes are in the song, and stitch together your media to make a video for you. This is the day they created a Facebook version of their ap, and they started signing up 35,000 people per hour that day. That's a good growth spike, right? And the request latency doesn't increase as the number of users scales up, and you can do dynamic scaling both up and down. That's the case for scaling up. The case for scaling down is that a lot of sites that are medium sized have enough diurnal variation you'd be leaving money on the table by not undeploying, especially now that cloud computing makes it possible to do at a fine grain, there's every motivation to undeploy resources that you're not using. So being able to scale down as well as up, which I think is kind of a new thing that 19 we didn't take as seriously before fine grain cloud computing, is part of data scale independence. So what are the functional requirements for this data scale independence? Interactive performance. That's kind of a given. As I've said, we are working on batch applications as well. For the focus of this talk, interactive performance means when I do a query, I expect results in web realtime, so a couple of seconds. The really missing piece, we think, is a data model that naturally supports the richer data structures that are used by these social and Web 2.0 applications. There are examples out there now of very highly scaleable data storage but whose data model is pretty simplistic. So big table, Amazon S3 and Dynamo. Cassandra, which is essentially an open source clone of Big Table, which we're using as part of this project. But none of them really support more than key value or key value plus column family addressing, and that's not the data model that the application writer needs to work with. These application writers are doing graphs of connected entities. They're writing applications that are short write intensive. You know, you can tag things or poke your friends or whatever. So you can't shard your way off out of the problem because the graph doesn't partition terribly well, and you can't cache you way out of the problem because the write workload won't permit it. Scaling up and down, we already said. Support for multiple data Centers is sort of a point of departure for us now. This is not need but tolerate. This is once you paint yourself into a corner with relational storage, you ask where you can relax the asset guarantees in order to get scaleability and availability. The classic answer is you can do it by relaxing consistency. In fact, Facebook is sort of an existence proof that these aps will tolerate relaxed consistency, even if they'd rather not. Now, they wouldn't want it to be hours before a change is visible to all of your friends, but minutes is conceivably okay. Now, there's been a question for some time as to whether a developer can use this effectively. In other words, are developers confused by a data model that does not give you this guarantee that once I commit a write, it's really committed for everybody. Our view is that developers could use it if the consistency was something they got to specify in advance and could quantify. And if we could use simple things like 20 session guarantees on the client side to give the developer a model that makes sense to them. In other words, if I do a write, it may take a while for my friends to see the write, but if I now do a readback of that thing, I'll see the thing I just wrote. In fact, a number of the problems with other relaxed consistency approaches have been that they don't give you even the simple session guarantees. So S 3, for example, doesn't necessarily guarantee this. So SCADS is a project we've been working on for several months that attempts to address these needs. For interactive performance, we rely on a performance safe query language that can say no. In other words, you can only essentially do queries for which you have precomputed indices. If you try to add functionality to your application that can't be satisfied with the existing indices, then you have to change the schema in order to do it. A data model that matches social computing. SCADS uses a number of indices to give you the ability to put together object graphs. As I'll show in a second, the updates to multiple indices that occur as the result of a single write are managed by separate priority queues, and this gives you a way to talk about relaxed consistency. Scaling up and down, we believe we will be able to use machine learning to induce models on the fly of how SCADS is working so that as we observe more and more queries, we can actually do a reasonable job predicting the resource needs of these queries, and we can scale up and down as needed in response to that. And because one of the goals of SCADS is declarative specification of relaxed consistency, we believe that gives a natural extension to talking about multiple datacenters. In fact, Facebook's current architecture uses multiple datacenters, but their relaxed consistency has been engineered into the mainline logic of the application, because there's no way to do it in terms of my sequel and mem cache D layers they've been using. Yeah? >>: To this -and how my data session what extent does your declarative approach -- maybe we'll talk about but to what extent is it dependent on how you choose to partition you data you choose to direct users to locations. Depending upon how I partition or users requests get served, you may or may not be able to guarantee that consistency you're talking about. >> Armando Fox: Right. So the short answer to your question is if there are cases where there's a consistency guarantee that is incompatible with the availability desire, then the developer will have had to specify which one is going to win. In 21 other words, will you serve stale data, or will you just return an error and say no? Now, as far as the extent to which you are -- the performance depends on the way that data happens on laid out and how many replicas you have for something that is about to become hot, that's exactly the case where we're betting that we can adapt the machine learning approaches from the first half of the talk to actually make those decisions in close enough to realtime that we can essentially say we need to be adding a certain amount of capacity, let's say, over the next few minutes. Or we have capacity that's been observed to be idle or idle enough that we can start consolidating again. So the answer is that yes, it's obviously sensitive to how your data is partitioned and replicated, but we hope we can keep up with that in a few minutes lag granularity so that we can actually make adjustments to that on the fly. >>: [Inaudible]. >> Armando Fox: >>: That's okay. You can dynamically, in some sense, replicate and de-replicate data? >> Armando Fox: We are, in fact, part of -- so originally, we were -- we didn't know how we were going to build that ourselves with graduate student resources. But if you're familiar with Cassandra, Cassandra actually allows us to outsource some of that. Cassandra gives you a big table like API and actually handles replication itself, and you can do replication changes online. You can replicate and de-replicate online. And I think you can do a limited amount of repartitioning online as well. We're hoping that some of the machinery for doing that will be handled by Cassandra. The policy for how to deploy that machinery will come being able to induce models that successfully tell us what we actually -- you know, the number of replicas, let's say, we need, for a given chunk of the data set. That's the outline of the approach. This is in the process of being built, so the answer to this question may change over the next three months. So what do we mean by performance safe queries will support a sequel-like, probably some sort of sequel query language, augmented with cardinality constraints so that you can always make sure that you can return the answer to any query essentially in constant time, or in time that doesn't scale with the number of users. 22 So we have multiple indices, depending on which queries you want to do. You can only ask query for which there is an existing index. So you don't have an option of allowing a query to just run slow. And the indices are materialized offline. That means if you want to add a feature to your application that would require a query for which you have no current index, you have to build that index offline before you deploy that feature in your application. Queries are limited to a constant number of operations that will scan a contiguous range of one or more tables on a machine. If you're trying to add a new query or new application feature, you already know what the -- I'll give you an example of what a consistency constraint might look like on the next slide, but given the specified constraints and the existing indices, would you be able to support that query under those -- with high availability under that consistency guarantee. If the answer is no, then you need to come up with additional indices so that you can do it in constant time. A consistency specification might look something like the following, where I'll specify an obvious thing like a read SLA over some percentile of the requests. I might want to specify what the staleness window is. And as far as conflicting writes, I could have a policy like last write wins, or I could ask for writes to be merged. And I'd like to have a session guarantee to read my own writes. So even if writes take some finite time to propagate, I don't have a confusing model of not being able to read back what I believe I just wrote. Now, I think the question that was raised is what if it turns out at run time that you can't have all of these things at the same time. For example, if there's a transient network partition, you have to choose between delivering the stale data or just saying no. If you don't have sufficient resources to meet the SLA, again, you might have to return stale data from another partition. So in any of these cases, the idea is that the developer would prioritize whether returning something, even if it was stale, would be more important, or whether it's preferable to just return an error. You know, in some sense, whenever you do an availability/consistency trade-off, you always find yourself having to have the contingency case, where what if you can't -- if you can't meet the trade-off that you specified, which one do you say is going to win? Yeah? >>: [Inaudible] I may not have any idea of what I can actually achieve. So is the model I cannot specify the ideal world and something breaks and I back up and I say oh, maybe. 23 >> Armando Fox: That's a good question. I think what the model will end up being is, as we start to get a little bit of experience with the observed performance of the system, you could -- as a developer, you could go through a very short iterative process where just using the models that are in the online running system, you say I want to do the following queries. And basically, the answer would be, well, this update type that you want to do is going to lead to all these other cascading updates, and you need to essentially rank order which ones are more important. If you do that, I'll tell you what the worst case bound is by the time the last one will happen. It will be a little bit like rank choice voting. Now, I think the question you're getting to is how much knowledge do we need to give the developer, and what form would the knowledge take before they can write down any kind of consistency policy in terms that they understand. To be perfectly honest, we don't know the answer to that yes. Initially, the developers will be the students who are building the systems. So they'll just know. There's an interesting open question is how do you know what's a realistic starting point to ask for. And if what you're asking for can't be met, what hints does the application give you back to tell you where you have to relax? And we don't know the answer to that yet. >>: Can the system tell me what things, what to change about my system in order to meet these guarantees? It's one thing to say no, you can't do it. What would be more useful is to say you can't do it now, but if you do XYZ, then you can achieve ->> Armando Fox: Right. So again, the honest answer is we don't know. What I can tell you we would try, which is in the earlier part of the talk when we were talking about mining console logs, we made this distinction between these black box models that just tell you normal/abnormal, versus inducing something like a decision tree that tells you why something is normal or abnormal. You can interrogate how it made the chose. The hope is to be able to apply some process like that to the models that we induce for this. And hopefully, that would be able to tell you, you know, here's the point at which I decided you couldn't do it, right, and here's the reason why. But I'd be lying if I said that we had a better handle on it than that right now. We don't. Yeah? >>: [Unintelligible]. 24 >> Armando Fox: Basically, just choosing -- limiting how many results could possibly be returned from any given query. So if it's a query that could possibly return an unbounded number of results, you'll be hard limited to the first K result, where K is probably a deployment time constant. You can always ask for the subsequent K results sometime after that. >>: [Unintelligible] but in order to produce that one number, I need to look at, you know, a humongous number of outputs. >> Armando Fox: >>: So the -- [Inaudible] can be much lower. >> Armando Fox: That's why the only queries that you are allowed to ask are ones for which you have already materialized an index to make it a lookup with bounded range. What that means is if you do an update that could cause a change in the hypothetical index -- well, actually, let me get to the -- I think the next slide may answer your question. If it doesn't, we'll come back to it. So the way that updates are handled in this world is quite different, right. If you're not allowed to essentially do arbitrary scans to perform a query, right, which is exactly what we're trying to avoid, then the alternative is that every time an update occurs that might affect multiple other queries that they each have their own index, you now have to incrementally propagate changes to all indices. That's a fundamental difference in this approach versus what I think you described is that every time we do a query that could result in cascading updates, we essentially queue those cascading updates as asynchronous tasks. And each node that has a set of updates performed has them ordered in a priority queue. The priorities queues, priorities are based on how important each one of those things is in terms of the developer's consistency specification. So relatively unimportant operations; in other words, ones for which I can tolerate much, much weaker consistency, I could wait minutes for the updates to happen will actually float to the bottom of the priority queues. And priority queues is what the modeling is based on. So every answer is precomputed. Any answer that might be affected by an update is incrementally recomputed. Unfortunately, I'm not going to have time to do a SCADS architecture walk through. One of the features is every time you do an update, 25 there's an observer that figures out which index functions have to be rerun to incrementally update some other index that is affected by what you just do. So we have this -- the work queue is what we do the modeling around. >>: [Unintelligible]. >> Armando Fox: >>: Yes. [Unintelligible]. >> Armando Fox: Taking away the beauty of sequel, but we are replacing it with the beauty of scale independence. So ->>: [Inaudible]. >> Armando Fox: In an ideal world, we'd like to have both, right. But I think what we've kind of -- the lesson that's been learned the hard way over the years is it's very difficult, as you get to larger and larger scale, to preserve all the beauty. We had to pick which beauty we wanted. You're absolutely correct. In doing that, you could argue, you know, to take a devil's advocate position, we're undoing a lot of sequel in masking those operations from us, right. Whereas sequel will essentially declaratively -- you can declaratively say what you want and someone else figures out to do it, we're going back to a scenario where the sequence necessary to do an update becomes significant. That's the most effective way to expose this to the developer so they will understand the impact of saying this is more important than this. It means that there's a priority queue where this thing is going to get done first. The modeling tells us is it quantifies how long it will take things to get done. Under different workload conditions, the same priority queue could have very different performance models associated with it. As the developer, you don't really know what that's going to be. All you can say is the relative importance of different things. And our job is to the try to keep the system in a stable operating state by using the model to deploy more machines as needed. Okay. So obviously, from the point of view of what do you do about datacenters, with an S plural, if you really have a model where you're talking about relaxed consistency to propagate updates across different indices, in some sense, dealing with cross-datacenter data storage becomes a special case of that. 26 In fact, this is how Facebook works now, except they've had to sort of build their own ad hoc solution around it, because they didn't have anything off the shelf to start from. I mentioned that in order to keep this sort of tractable to developers, we can present session guarantees such as read your own writes or monotonic reads only. Those things can be implemented largely on the client side. It's actually Bill Beloski [phonetic] who came up with the needed improvement that I think will make the programming model tractable for mere mortals. Yes >>: You said a single update [unintelligible]. >> Armando Fox: Right. >>: Does that mean -- if we take Facebook for example where I change my status and all my friends are supposed to see it, one way of doing that is to basically fan the thing out in right time. I fan out the status change to my friends' news feeds. >> Armando Fox: Right. >>: Are you saying another way of doing it is basically to just update my status, and then when a friend logs in and updates the news feed, they basically pull the feed? >> Armando Fox: We're saying to do it the first way, that you do it eagerly, but depending on how important the developer has said that this operation is, it may be that the updates associated with doing that are not prioritized particularly high in the priority queues. So it may actually take a while to do. Now, I think if you're concerned about the 0 of 1 part, this is actually true of Facebook now, except it's really 0 of 5,000. They have a hard limit on how many friends you have. They have hard limits in a number of other applications. Things like causes, they limit the number of invitations you can send out per day and stuff. They have hard wired things built in all over the place. I think over time, we may be able to do better than saying any given operation triggers a constant number of writes. I think what we may get to is if you do 0 of N operations, you'll get 0 of N rights, which is actually not the same thing. So O of N operations applies O of N writes means you can have a few groups that a lot of people are interested in, and you could have a few people who are interested in a lot of groups. But you can't have a lot of people all interested in at lot of groups. But that's far future. 27 Okay. Actually, we're doing okay on time. So I'm getting ready to wrap up anyhow. Well, I won't have time to go through a detailed example, but the idea is if you wanted to support in constant time queries like who are my friends, who are their friends, and which of my friends have birthdays coming up soon, you essentially have to maintain separate indices to answer each of these questions. And if I add a friend, then potentially all of these indices have to change. If I change my birthday, a subset of the indices would have to change. And those are the discrete operations that go into the priority queues. So in the interest of time, I'm not going to go into the example in any detail. Yeah, because I want to leave more time for discussion, actually. We're implementing this over Cassandra, which is an open source clone of Big Table that's been developed by Facebook and put in the -- into Apache incubator by them. We expect to have the indexing system and simple modeling of Cassandra doing reads and writes all ready by January, and we are deploying it as a service on EC2. We got a bunch of Amazon funding money to do that, which is very nice. We also plan, I think more interestingly, to address the question of can developers understand and use this model. And one way that we're going to do that is by seeding it to our undergraduates in these very successful courses that we've done. Those of you familiar with Ruby on Rails are probably familiar with active record, which is the object relational mapping layer that it provides. Basically, that layer allows you to talk about hierarchical relations among collections of things. And there's a natural syntax for annotating those relationships with, for example, things like consistency guarantees. So our goal is to have a near API drop and replacement at the source level for active record that would replace the sequel mapping layer that's built into Rails with a SCADS mapping layer but provide very similar APIs. By the way, this is, I think we realized in the last few months, a non-obvious benefit of using something like Rails, which is strictly higher level in terms of its data abstraction model than PHP. In PHP, you have to write your own sequel queries, for the most part. There are various libraries out there that you can use, but the idiom for PHP applications is that you figure out your schema, and you figure out what your queries are going to be. Whereas the common practice for Rails is you figure out what your object graph is, and Rails actually takes care of the schema. The most common way it does 28 that is by using drawing tables and conventional sequel things, but there's nothing saying you couldn't rip out that layer and replace it with a different layer that still lets you express the object graphs, but implemented over a completely different data store. So, in fact, we're hoping to seed this undergrads in the next iteration of this course, which is going to be next fall. So, you know, in terms of where do we see SCADS going, one of the things that we got early on from our Microsoft colleagues is understanding who your developer persona is. We've decided that the development target for a lot of these are Elvises, you know, people who are, they're good programmers. They're not necessarily Stallmans of the world but they have domain knowledge. They're competent in sort of the current programming tools. And our stand-in for Elvis is undergrads and our Ruby on Rails courses. Whether these developers can understand and use this relaxed consistency data model and API, well, we're going to hopefully by next fall be able to give them the APIs and have them use it in their class projects instead of using my sequel, which is what they're using now. And because we have funding money from EC2, we can actually deploy quite large scale version of these applications, even if it means driving them with synthetic workload, to evaluate, in fact, whether or not at scale we can make that variable consistency mechanism truly work. That's kind of where SCADS is going. So let me kind of sum up with another picture of the datacenter and where these different technologies have figured into it. Scale independent data storage, this is kind of, in our view, one of the big missing pieces that you cannot just take off the shelf. If you want to scale the horizontal scaling part of your ap, the stateless part, you can take that off the shelf with virtual machines, with a lamp stack or your favorite other stack. You can take HA proxy for load balancing off the shelf, mem cache D off. Everything is off the shelf, but storage is still really elusive. There's no off-the-shelf really scaleable storage that is as elastic as the rest of the application, and SCADS is hopefully intended to fix that. The director is a way of making machine learning technology available as a service so that we have the opportunity of systematically applying it to do things like resource prediction in these very complex aps. And the hope is that just as it has been part of understanding how to scale the simple parts of the ap, it will be able to tell us how to scale SCADS, which is the more complicated part of the ap. And we'll stick with using these very high productivity, high level languages and frameworks, not just because we believe that with machine learning we can identify 29 where that productivity tax goes, but also because by keeping the developer at that higher level, I think it gives us the opportunity to play around with alternative data models. I think SCADS is one of a number of different data models that are going to be prominent in large scale applications. You know, we sort of look forward to seeing what the other ones are, but I think the hidden benefit that we didn't see of these very high level languages is to the extent that they insulate application developers from the details of the data model, that actually makes it easier for us as researchers to experiment down in that space and still have it be useful to developers, right, where they might actually be able to apply their existing skills and not have to rewrite their entire ap from scratch, which is what's been happening in practice with these deployed applications. Yes? >>: So -- >> Armando Fox: I hope you're in one of my afternoon meetings, by the way. asking all these great questions. You're >>: No, I'm not, so I'll try and get in my questions now. So the underlying model for SCADS seems to be that data is always stored persistently. Might be a little bit out of date, but it's always stored persistently. You could also -- I mean, the missing bit here seems to be data that is cached. I might have a semantic in my data that says I have five datacenters. In three of them I have data stored persistently, but in two of them all I have is a cache. That might be some annotation I might want to put on my data. >> Armando Fox: So you're talking about garden variety caching where you expire things on demand, and you can always regenerate them? That's what you're talking about >>: Yes, you can -- seems like things like that is missing from SCADS right few. Did you consciously reject the notion of caching? >> Armando Fox: >>: Reject is such a strong word. [Inaudible]. >> Armando Fox: To keep the project in scope, no, we did choose to owe omit it from SCADS for two reasons. One of them is we really want to focus on does this plan for doing variable consistency, is it really going to work. So part of it really 30 is to keep the project scoped. The other part is that, you know, again, as a currently a Rails programmer, I've done some PHP. I've done whatever the flavor of the month has been for the last few years. The framework actually has framework level abstractions for caching that operate on framework level objects. So, for example, Rails has abstractions for page caching, caching of fragment of a page, caching the result of a particular query, and it's actually got a very well-developed set of abstractions for dealing with that. And you can use mem cache D, you can cache in disk files, you can cache in ram. So in some sense, putting caching in SCADS, given the way we want to deploy it, probably would have been redundant. And all of the caching features in Rails are independent of the underlying data storer. They're based on the abstractions at the framework level. So that's the practical reason we did it. >>: [Inaudible] relationship between the caches in Rails and your persistent data in order to get a full view of really what your consistency semantics are? >> Armando Fox: We'll see to what extent that turns out to be the case. Basically, as long as each copy of the Rails application is essentially -- so if you've got 100 copies of the ap server, and SCADS is behind them, but each copy of the ap server essentially believes it's managing its own caching, and if you can make reasonable assumptions about affinity with cookies and stuff, I think the caching that's built in with Rails will get us most of the way there. I think in the long-term, you're probably right. I think any storage framework at this level will have to at least make some caching decisions visible to the application stack. For the moment, we think we can probably get away without doing that and hopefully still be able to demonstrate something interesting about the data model. But in the long-term, I think a more practical point of view, you're right. I think officially, yeah, I think officially that's it. In the event that people want to actually read more details about any of the stuff I talked about, I think these are all of the papers that were -- all of the slides and graphs and things came from one of these five papers. And then in case I missed any, I have my home page up here. But that's kind of all I officially have. The questions have been so good, I hope we still have more time for those. So thanks. You all are great, and let's talk about more stuff. [Applause] 31 >> Armando Fox: Clap for yourselves, you're a great audience. Go ahead. >>: So when we talked about kind of replicating and de-replicating data, you mentioned that you were working on basically machine learning models that figured out [inaudible], right? Now, how long-term are those models? Because you could imagine that depending upon the amount of data being replicated, it might make sense to just leave data around, even if it's not being used for a number of days. Even if I have a kind of daily pattern of usage that varies, I might not want to take the hit of at peak time, replicate a bunch of servers, take the overhead of dealing with consistency issues. >> Armando Fox: Right. I can probably generify your question a little bit by saying very often there are essentially stable patterns over longer time periods. If you knew what they were, you don't really need machine learning to do that, right. If you know what your stable pattern is going to be, you have some component of your provisioning that's just going to make sure that you hit your stable pattern, and then you use machine learning to deal with the unexpected variation. Right? >>: [Inaudible] between, in some sense, kind of having a bunch of idle servers; i.e., not using up all the CPU, versus other trails like using network bandwidth to replicate data that you only need for a certain amount of time, right? So there are multiple resources that you need to trade off. Just looking at CPU utilization seems like kind of a subset of the space. >> Armando Fox: Right, well, and I'm not claiming that's the only thing you're looking at. In general, there's many dimensions of trade-offs one could make. I think the thing that is going to force the issue on that is that, you know, Amazon is the first sort of widely buzzed consumer version of cloud computing that seems to have had some impact, has actually put a price on those trade-offs. You know exactly what it costs per gigabyte of network bandwidth, per CPU hour, per everything. But we don't have a plan yet for saying how we're going to co-optimize all those things. Hopefully, if we can just get the simple case working initially, like in the next six months, I think we'll have made a step in the right direction. Yeah? >>: [Inaudible]. >> Armando Fox: Are you in one of my afternoon meetings? 32 >>: No. >> Armando Fox: Okay, too bad. >>: [Inaudible] use for any operational system. Used for a variety of other aps like for redaction and whatnot. But [inaudible] resource management and so on. Are you aware of operation systems? This is more for my information. >> Armando Fox: Am I -- well, I would guess, okay, so I'll give you two answers. I would guess that that's probably happening at Google, but no one will actually tell us that. I suspect more of their machine learning is really put into the functionality of the applications, but I know they have used at least some machine learning techniques even in an offline sense to analyze performance bugs and things like that. Also, you know, kind of closer to home, we've been working -- through Microsoft silicon valley, we've been working with the Microsoft instant messenger team, and we have actually used some machine learning to help them find what may be performance bottlenecks in IM during their stress testing. So an answer soon might be it's being used by some Microsoft properties. That would be all to the good, we assume. >>: [Inaudible] you know, what happens in a [unintelligible], let's say, you know, I am [unintelligible] one specific thing, this likely to be much more [unintelligible]. Let's say you hard writing off simple DV or simple similar data services or generate platform, you know, the problem there is that there are going to be marketable consumers of this, and the assumption of the steady state requests more justification there. So you use your director to take ->> Armando Fox: We're exactly not assuming steady state. >>: No, we're not, but that's the issue of robustness becomes much more critical, because you're making important decisions, getting something, building an index, and some of us [unintelligible] yes, you can back up, but there's a price. So it almost becomes a key issue, and that's really what was my, you know, [unintelligible]. >> Armando Fox: As I said, I think philosophically, we're in agreement. There will always be unforeseen cases; and yes, you are trusting a machinery whose robustness may not be fully tested. There's no guarantee -- 33 >>: There's no one ap running against it. That's a critical difference from a bunch of successful scenarios where machine learning has been illustrated for us. >> Armando Fox: That's true. But at the same time, I would say that's even true now in production systems where machine learning is not used. So, you know, Amazon -- Werner gave this key note at the cloud computing thing where they know their diurnal variation to such a fine degree that they use that as their main indicator of whether something might be wrong with the site. So basically, if the order rate goes outside of a predefined envelope by more than a threshold amount, it's a very likely signal. And they have extremely detailed models of this. You don't need machine learning to make those models. They had incidents where they thought their service went down, but it did not because of essentially external conditions they had never modeled before. >>: [Unintelligible] for them application of machine learning too is just fine. When you're doing online intervention to move around with subsets, that's where, you know, I have concerns. I have no know concerns if they're using these kind of models to detect possible cases where, you know, [unintelligible] out of the loop. Resource management directed by machine in complement, that's where -- again, I'm not saying that's not possible. I'm saying ->> Armando Fox: I know, it's a legitimate risk. There's a bunch of other work we have done that I didn't talk about at all that has to do with combining machine learning results with visualization. So that as the operators see this is what the algorithm found, here's what it would have done and summarized in kind of one picture. The hope would be that over time the operators can either correct its mistakes or at least come to trust that when it's put in control, it will do the right thing. I think that's a necessary but not sufficient condition. But I don't know what the end game of that is. I think you're right. Philosophically, we're in agreement. Yes? >>: [Inaudible] model online in a realtime, do you allow for addition or distraction of features on the fly? >> Armando Fox: Not so far, but we haven't ruled it out. We just hadn't thought of it until just now when you said it. No. Was there something specific that made you ask that? 34 >>: [Inaudible] unforeseen impact of features that, you know, in the first model were not actually identified. >> Armando Fox: So I guess it depends on what you mean by considering new features. The kind of template for most of these methods is you have a candidate set of features that you can extract, and then you have one or more feature selection steps where you end up deciding which ones are going to be included in your model. Now, certainly, it's the case when you're building models online, the set of features selected at any given time that will become important in the model, it's probably going to be different, you know, depending on what the external conditions are, but we haven't thought about any approaches where -- we haven't thought about any approaches where you would add new candidate features online. I guess to me, that would be like you're going to come up with a new modeling technique. And when you deploy that new modeling technique, it will include new candidate features you hadn't used before. But I guess for some reason, I didn't think of that as an online thing, but I guess it could be. >>: [Inaudible]. >> Armando Fox: Well, part of the goal of the plug-in architecture with the director is to be able to add them relatively fast. You know, fast meaning you've qualified them offline, right, and now they're ready to go into the production system. So at least we would have the machinery in place that would hopefully let you do that. But we haven't thought of doing it ourselves yet. >> Jim Larius: >> Armando Fox: [Applause] Okay. Let's thank Armando. Thank you, guys. What a very interactive audience.