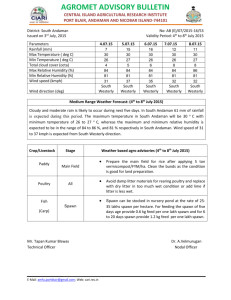
CS 240A: Shared Memory & Multicore Programming with Cilk++
advertisement

CS 240A: Shared Memory &
Multicore Programming with Cilk++
•
•
•
•
Multicore and NUMA architectures
Multithreaded Programming
Cilk++ as a concurrency platform
Work and Span
Thanks to Charles E. Leiserson for some of these slides
1
Multicore Architecture
Memory
I/O
Network
$
$
core
core
…
$
core
Chip Multiprocessor (CMP)
2
cc-NUMA Architectures
AMD 8-way Opteron Server (neumann@cs.ucsb.edu)
A processor
(CMP) with
2/4 cores
Memory
bank local to
a processor
Point-to-point
interconnect
3
cc-NUMA Architectures
∙
∙
∙
∙
No Front Side Bus
Integrated memory controller
On-die interconnect among CMPs
Main memory is physically distributed
among CMPs (i.e. each piece of memory
has an affinity to a CMP)
∙ NUMA: Non-uniform memory access.
For multi-socket servers only
Your desktop is safe (well, for now at least)
Triton nodes are not NUMA either
4
Desktop Multicores Today
This is your AMD Barcelona or Intel Core i7 !
On-die
interconnect
Private
cache: Cache
coherence is
required
5
Multithreaded Programming
∙ POSIX Threads (Pthreads) is a set of
threading interfaces developed by the IEEE
∙ “Assembly language” of shared memory
programming
∙ Programmer has to manually:
Create and terminate threads
Wait for threads to complete
Manage interaction between threads using
mutexes, condition variables, etc.
6
Concurrency Platforms
• Programming directly on PThreads is
painful and error-prone.
• With PThreads, you either sacrifice memory
usage or load-balance among processors
• A concurrency platform provides linguistic
support and handles load balancing.
• Examples:
• Threading Building Blocks (TBB)
• OpenMP
• Cilk++
7
Cilk vs PThreads
How will the following code execute in
PThreads? In Cilk?
for (i=1; i<1000000000; i++) {
spawn-or-fork foo(i);
}
sync-or-join;
What if foo contains code that waits (e.g., spins) on
a variable being set by another instance of foo?
They have different liveness properties:
∙ Cilk threads are spawned lazily, “may” parallelism
∙ PThreads are spawned eagerly, “must” parallelism
8
Cilk vs OpenMP
∙ Cilk++ guarantees space bounds
On P processors, Cilk++ uses no more than P
times the stack space of a serial execution.
∙ Cilk++ has a solution for global variables
(called “reducers” / “hyperobjects”)
∙ Cilk++ has nested parallelism that works
and provides guaranteed speed-up.
Indeed, cilk scheduler is provably optimal.
∙ Cilk++ has a race detector (cilkscreen) for
debugging and software release.
∙ Keep in mind that platform comparisons
are (always will be) subject to debate
9
Complexity Measures
TP = execution time on P processors
T1 = work
T∞ = span*
WORK LAW
∙TP ≥T1/P
SPAN LAW
∙TP ≥ T∞
*Also called critical-path length
or computational depth.
10
Series Composition
A
B
Work: T1(A∪B) = T1(A) + T1(B)
Span: T∞(A∪B) = T∞(A) +T∞(B)
11
Parallel Composition
A
B
Work: T1(A∪B) = T1(A) + T1(B)
Span: T∞(A∪B) = max{T∞(A), T∞(B)}
12
Speedup
Def. T1/TP = speedup on P processors.
If T1/TP = (P), we have linear speedup,
= P, we have perfect linear speedup,
> P, we have superlinear speedup,
which is not possible in this performance
model, because of the Work Law TP ≥ T1/P.
13
Scheduling
A strand is a sequence of
instructions that doesn’t contain
any parallel constructs
∙Cilk++ allows the
programmer to express
potential parallelism in
an application.
∙The Cilk++ scheduler
maps strands onto
processors dynamically
at runtime.
∙Since on-line
schedulers are
complicated, we’ll
explore the ideas with
an off-line scheduler.
Memory
I/O
Network
$
P
P
$
P
…
$
P
14
Greedy Scheduling
IDEA: Do as much as possible on every step.
Definition: A strand is ready
if all its predecessors have
executed.
15
Greedy Scheduling
IDEA: Do as much as possible on every step.
Definition: A strand is ready
if all its predecessors have
executed.
P=3
Complete step
∙ ≥ P strands ready.
∙ Run any P.
16
Greedy Scheduling
IDEA: Do as much as possible on every step.
Definition: A strand is ready
if all its predecessors have
executed.
P=3
Complete step
∙ ≥ P strands ready.
∙ Run any P.
Incomplete step
∙ < P strands ready.
∙ Run all of them.
17
Analysis of Greedy
Theorem : Any greedy scheduler achieves
TP T1/P + T∞.
Proof.
P=3
∙ # complete steps T1/P,
since each complete step
performs P work.
∙ # incomplete steps T∞,
since each incomplete step
reduces the span of the
unexecuted dag by 1. ■
18
Optimality of Greedy
Corollary. Any greedy scheduler achieves
within a factor of 2 of optimal.
Proof. Let TP* be the execution time
produced by the optimal scheduler.
Since TP* ≥ max{T1/P, T∞} by the Work and
Span Laws, we have
TP ≤ T1/P + T∞
≤ 2⋅max{T1/P, T∞}
≤ 2TP* . ■
19
Linear Speedup
Corollary. Any greedy scheduler
achieves near-perfect linear
speedup whenever P ≪ T1/T∞.
Proof. Since P ≪ T1/T∞ is equivalent
to T∞ ≪ T1/P, the Greedy Scheduling
Theorem gives us
TP ≤ T1/P + T∞
≈ T1/P .
Thus, the speedup is T1/TP ≈ P. ■
Definition. The quantity T1/PT∞ is
called the parallel slackness.
20
Cilk++ Runtime System
Each worker (processor) maintains a work deque of
ready strands, and it manipulates the bottom of the
deque like a stack
spawn
call
call
call
spawn
call
spawn
call
spawn
call
spawn
call
P
P
P
Call!
P
21
Cilk++ Runtime System
Each worker (processor) maintains a work deque of
ready strands, and it manipulates the bottom of the
deque like a stack
spawn
call
call
call
spawn
spawn
call
spawn
call
spawn
call
spawn
call
P
P
Spawn!
P
P
22
Cilk++ Runtime System
Each worker (processor) maintains a work deque of
ready strands, and it manipulates the bottom of the
deque like a stack
spawn
call
call
call
spawn
spawn
P
spawn
call
Spawn!
P
spawn
call
spawn
call
call
P
spawn
call
spawn
Call!
Spawn!
P
23
Cilk++ Runtime System
Each worker (processor) maintains a work deque of
ready strands, and it manipulates the bottom of the
deque like a stack
spawn
call
call
call
spawn
spawn
P
spawn
spawn
call
call
spawn
call
Return! call
P
P
spawn
call
spawn
P
24
Cilk++ Runtime System
Each worker (processor) maintains a work deque of
ready strands, and it manipulates the bottom of the
deque like a stack
spawn
call
call
call
spawn
spawn
P
spawn
spawn
call
spawn
call
Return! call
P
P
spawn
call
spawn
P
25
Cilk++ Runtime System
Each worker (processor) maintains a work deque of
ready strands, and it manipulates the bottom of the
deque like a stack
spawn
call
call
call
spawn
spawn
P
spawn
call
spawn
call
Steal! call
P
P
spawn
call
spawn
P
When a worker runs out of work, it steals
from the top of a random victim’s deque.
26
Cilk++ Runtime System
Each worker (processor) maintains a work deque of
ready strands, and it manipulates the bottom of the
deque like a stack
spawn
call
call
call
spawn
spawn
P
spawn
call
spawn
call
Steal! call
P
P
spawn
call
spawn
P
When a worker runs out of work, it steals
from the top of a random victim’s deque.
27
Cilk++ Runtime System
Each worker (processor) maintains a work deque of
ready strands, and it manipulates the bottom of the
deque like a stack
spawn
call
call
call
spawn
spawn
P
P
spawn
call
spawn
call
call
spawn
call
spawn
P
P
When a worker runs out of work, it steals
from the top of a random victim’s deque.
28
Cilk++ Runtime System
Each worker (processor) maintains a work deque of
ready strands, and it manipulates the bottom of the
deque like a stack
spawn
call
call
call
spawn
spawn
P
spawn
call
spawn
P
spawn
call
Spawn! call
P
spawn
call
spawn
P
When a worker runs out of work, it steals
from the top of a random victim’s deque.
29
Cilk++ Runtime System
Each worker (processor) maintains a work deque of
ready strands, and it manipulates the bottom of the
deque like a stack
spawn
call
call
call
spawn
spawn
P
spawn
call
spawn
P
spawn
call
call
P
spawn
call
spawn
P
When a worker runs out of work, it steals
from the top of a random victim’s deque.
30
Cilk++ Runtime System
Each worker (processor) maintains a work deque of
ready strands, and it manipulates the bottom of the
deque like a stack
spawn
call
call
call
spawn
spawn
P
spawn
call
spawn
P
spawn
call
call
P
spawn
call
spawn
P
Theorem: With sufficient parallelism, workers
steal infrequently linear speed-up.
31
Great, how do we program it?
∙ Cilk++ is a faithful extension of C++
∙ Often use divide-and-conquer
∙ Three (really two) hints to the compiler:
cilk_spawn: this function can run in parallel
with the caller
cilk_sync: all spawned children must return
before execution can continue
cilk_for: all iterations of this loop can run in
parallel
Compiler translates cilk_for into cilk_spawn &
cilk_sync under the covers
32
Nested Parallelism
Example: Quicksort
The named child
function may execute
in parallel with the
parent caller.
template <typename T>
void qsort(T begin, T end) {
if (begin != end) {
T middle = partition(
begin,
end,
bind2nd( less<typename iterator_traits<T>::value_type>(),
*begin )
);
cilk_spawn qsort(begin, middle);
qsort(max(begin + 1, middle), end);
cilk_sync;
}
}
Control cannot pass this
point until all spawned
children have returned.
33
Cilk++ Loops
Example: Matrix transpose
cilk_for (int i=1; i<n; ++i) {
cilk_for (int j=0; j<i; ++j) {
B[i][j] = A[j][i];
}
}
∙ A cilk_for loop’s iterations execute in
parallel.
∙ The index must be declared in the loop
initializer.
∙ The end condition is evaluated exactly
once at the beginning of the loop.
∙ Loop increments should be a const value
34
Serial Correctness
The serialization is the
int fib (int n) {
if (n<2) return (n);
code with
the Cilk++
Cilk++
else {
int x,y;
Compiler
keywords
replaced by
x = cilk_spawn fib(n-1);
y = fib(n-2);
Conventional
cilk_sync;
null
or
C++
keywords.
Compiler
return (x+y);
}
}
Cilk++ source
int fib (int n) {
if (n<2) return (n);
else {
int x,y;
x = fib(n-1);
y = fib(n-2);
return (x+y);
}
Serialization
}
Serial correctness can
Conventional
be debugged
and Tests
Regression
verified by running the
multithreaded
code on a
Reliable Singlesingle processor.
Threaded Code
Linker
Binary
Cilk++ Runtime
Library
35
Serialization
How to seamlessly switch between serial
c++ and parallel cilk++ programs?
#ifdef CILKPAR
#include <cilk.h>
#else
#define cilk_for for
#define cilk_main main
#define cilk_spawn
#define cilk_sync
#endif
Add to the
beginning of
your program
Compile !
cilk++ -DCILKPAR –O2 –o parallel.exe main.cpp
g++ –O2 –o serial.exe main.cpp
36
Parallel Correctness
int fib (int n) {
if (n<2) return (n);
else {
int x,y;
x = cilk_spawn fib(n-1);
y = fib(n-2);
cilk_sync;
return (x+y);
}
}
Cilk++ source
Cilk++
Compiler
Conventional
Compiler
Linker
Binary
Parallel correctness can be debugged
and verified with the Cilkscreen race
detector, which guarantees to find
inconsistencies with the serial code
Cilkscreen
Race Detector
Parallel
Regression Tests
Reliable MultiThreaded Code
37
Race Bugs
Definition. A determinacy race occurs when
two logically parallel instructions access the
same memory location and at least one of
the instructions performs a write.
Example
A
B
C
D
int x = 0;
cilk_for(int i=0, i<2, ++i) {
x++;
}
assert(x == 2);
A
int x = 0;
B
x++;
x++;
C
assert(x == 2);
D
Dependency Graph
38
Race Bugs
Definition. A determinacy race occurs when
two logically parallel instructions access the
same memory location and at least one of
the instructions performs a write.
1
x = 0;
A
int x = 0;
B
x++;
x++;
assert(x == 2);
C
2
r1 = x;
4
r2 = x;
3
r1++;
5
r2++;
7
x = r1;
6
x = r2;
D
8
assert(x == 2);
39
Types of Races
Suppose that instruction A and instruction B
both access a location x, and suppose that
A∥B (A is parallel to B).
A
read
read
write
write
B
read
write
read
write
Race Type
none
read race
read race
write race
Two sections of code are independent if they
have no determinacy races between them.
40
Avoiding Races
All the iterations of a cilk_for should be
independent.
Between a cilk_spawn and the corresponding
cilk_sync, the code of the spawned child should
be independent of the code of the parent, including
code executed by additional spawned or called
children.
Ex.
cilk_spawn qsort(begin, middle);
qsort(max(begin + 1, middle), end);
cilk_sync;
Note: The arguments to a spawned function are
evaluated in the parent before the spawn occurs.
41
Cilk++ Reducers
∙ Hyperobjects: reducers, holders, splitters
∙ Primarily designed as a solution to global
variables, but has broader application
int result = 0;
cilk_for (size_t i = 0; i < N; ++i) {
result += MyFunc(i);
}
Data race !
#include <reducer_opadd.h>
…
cilk::hyperobject<cilk::reducer_opadd<int> > result;
cilk_for (size_t i = 0; i < N; ++i) {
result() += MyFunc(i);
}
This uses one of the predefined
reducers, but you can also write
your own reducer easily
Race free !
42
Hyperobjects under the covers
∙ A reducer hyperobject<T> includes an
associative binary operator ⊗ and an
identity element.
∙ Cilk++ runtime system gives each thread
a private view of the global variable
∙ When threads synchronize, their private
views are combined with ⊗
43
Cilkscreen
∙ Cilkscreen runs off the binary executable:
Compile your program with –fcilkscreen
Go to the directory with your executable and say
cilkscreen your_program [options]
Cilkscreen prints info about any races it detects
∙ Cilkscreen guarantees to report a race if there
exists a parallel execution that could produce
results different from the serial execution.
∙ It runs about 20 times slower than singlethreaded real-time.
44
Parallelism
Because the Span Law dictates
that TP ≥ T∞, the maximum
possible speedup given T1
and T∞ is
T1/T∞ = parallelism
= the average
amount of work
per step along
the span.
45
Three Tips on Parallelism
1. Minimize span to maximize parallelism. Try to
generate 10 times more parallelism than
processors for near-perfect linear speedup.
2. If you have plenty of parallelism, try to trade
some if it off for reduced work overheads.
3. Use divide-and-conquer recursion or parallel
loops rather than spawning one small thing off
after another.
Do this:
cilk_for (int i=0; i<n; ++i) {
foo(i);
}
Not this:
for (int i=0; i<n; ++i) {
cilk_spawn foo(i);
}
cilk_sync;
46
Three Tips on Overheads
1. Make sure that work/#spawns is not too small.
• Coarsen by using function calls and inlining near
the leaves of recursion rather than spawning.
2. Parallelize outer loops if you can, not inner loops
(otherwise, you’ll have high burdened parallelism,
which includes runtime and scheduling overhead).
If you must parallelize an inner loop, coarsen it, but
not too much.
• 500 iterations should be plenty coarse for even
the most meager loop. Fewer iterations should
suffice for “fatter” loops.
3. Use reducers only in sufficiently fat loops.
47