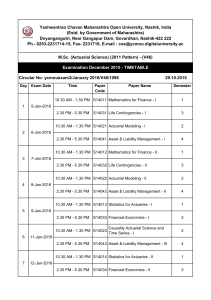
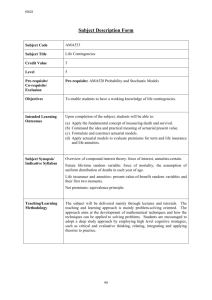
Data Quality: GIRO Working Party Paper & Methods to Detect Data Glitches
advertisement

Data Quality: GIRO Working Party Paper & Methods to Detect Data Glitches CAS Annual Meeting Louise Francis Francis Analytics and Actuarial Data Mining, Inc. www.data-mines.com Louise.francis@data-mines.com 1 Objectives Review GIRO Data Quality Working Party Paper Discuss Data Quality in Predictive Modeling Focus on a key part of data preparation: Exploratory data analysis 2 GIRO Working Party Paper Literature Review Horror Stories Survey Experiment Actions Concluding Remarks 3 Insurance Data Management Association The IDMA is an American organisation which promotes professionalism in the Data Management discipline through education, certification and discussion forums The IDMA web site: • • • Suggests publications on data quality, Describes a data certification model, and Contains Data Management Value Propositions which document the value to various insurance industry stakeholders of investing in data quality http://www.idma.org 4 Horror Stories – Non-Insurance Heart-and-Lung Transplant – wrong blood type Bombing of Chinese Embassy in Belgrade Mars Orbiter – confusion between imperial and metric units Fidelity Mutual Fund – withdrawal of dividend Porter County, Illinois – Tax Bill and Budget Shortfall 5 Horror Stories – Rating/Pricing Examples faced by ISO: Exposure recorded in units of $10,000 instead of $1,000 Large insurer reporting personal auto data as miscellaneous and hence missed from ratemaking calculations One company reporting all its Florida property losses as fire (including hurricane years) Mismatched coding for policy and claims data 6 Horror Stories - Katrina US Weather models underestimated costs Katrina by approx. 50% (Westfall, 2005) 2004 RMS study highlighted exposure data that was: Out-of-date Incomplete Mis-coded Many flood victims had no flood insurance after being told by agents that they were not in flood risk areas. 7 Data Quality Survey of Actuaries Purpose: Assess the impact of data quality issues on the work of general insurance actuaries 2 questions: percentage of time spent on data quality issues proportion of projects adversely affected by such issues 8 Results - Percentage of Time Employer No. Mean Median Min Max Insurer/Reinsure r 17 26.4% 25.0% 5.0% 50.0% Consultancy 13 27.1% 25.0% 7.5% 60.0% Other 8 23.4% 12.5% 2.0% 75.0% All 38 26.0% 25.0% 2.0% 75.0% 9 Results - Percentage of Projects Employer No Mean Median Min Max Insurer/Reinsure r 15 27.9% 20.0% 5.0% 60.0% Consultancy 13 43.3% 35.0% 10.0% 100.0% Other 8 22.6% 20.0% 1.0% 50.0% All 36 32.3% 30.0% 1.0% 100.0% 10 Survey Conclusions Data quality issues have a significant impact on the work of general insurance actuaries about a quarter of their time is spent on such issues about a third of projects are adversely affected The impact varies widely between different actuaries, even those working in similar organisations Limited evidence to suggest that the impact is more significant for consultants 11 Hypothesis Uncertainty of actuarial estimates of ultimate incurred losses based on poor data is significantly greater than that of good data 12 Data Quality Experiment Examine the impact of incomplete and/or erroneous data on actuarial estimate of ultimate losses and the loss reserves Use real data with simulated limitations and/or errors and observe the potential error in the actuarial estimates 13 Data Used in Experiment Real data for primary private passenger bodily injury liability business for a single nofault state Eighteen (18) accident years of fully developed data; thus, true ultimate losses are known 14 Actuarial Methods Used Paid chain ladder models Incurred chain ladder models Frequency-severity models Inverse power curve for tail factors No judgment used in applying methods 15 Completeness of Data Experiments Vary size of the sample; that is, 1) 2) 3) All years Use only 7 accident years Use only last 3 diagonals 16 Data Error Experiments Simulated data quality issues 1. 2. 3. 4. 5. 6. Misclassification of losses by accident year Early years not available Late processing of financial information Paid losses replaced by crude estimates Overstatements followed by corrections in following period Definition of reported claims changed 17 Measure Impact of Data Quality • • Compare Estimated to Actual Ultimates Use Bootstrapping to evaluate effect of difference samples on results 18 Results – Experiment 1 More data generally reduces the volatility of the estimation errors 19 Results – Experiment 2 Extreme volatility, especially those based on paid data Actuaries ability to recognise and account for data quality issues is critical Actuarial adjustments to the data may never fully correct for data quality issues 20 Results – Bootstrapping Less dispersion in results for error free data Standard deviation of estimated ultimate losses greater for the modified data (data with errors) Confirms original hypothesis 21 Conclusions Resulting from Experiment Greater accuracy and less variability in actuarial estimates when: Quality data used Greater number of accident years used Data quality issues can erode or even reverse the gains of increased volumes of data: If errors are significant, more data may worsen estimates due to the propagation of errors for certain projection methods Significant uncertainty in results when: Data is incomplete Data has errors 22 Predictive Modeling & Exploratory Data Analysis 23 Modeling Process Business Understanding 2 Data Understanding Deployment 0 Complex Model Artifact Data Preparation Evaluation Modeling 24 Data Preprocessing Data sets Select Data Rational for inclusion Clean Data Data Cleaning Report Construct Data Data Attributes Integrate Data Merged records Generate records Format Data 25 Exploratory Data Analysis Typically the first step in analyzing data Makes heavy use of graphical techniques Also makes use of simple descriptive statistics Purpose Find outliers (and errors) Explore structure of the data 26 Example Data Private passenger auto Some variables are: Age Gender Marital status Zip code Earned premium Number of claims Incurred losses Paid losses 27 Some Methods for Numeric Data Visual Histograms Box and Whisker Plots Stem and Leaf Plots Statistical Descriptive statistics Data spheres 28 Histograms Can do them in Microsoft Excel 29 Histograms of Age Variable Varying Window Size 20 80 15 60 10 40 5 20 0 0 16 33 51 Age 68 85 16 23 30 37 44 51 57 64 71 78 85 Age 40 30 20 10 0 16 24 31 39 47 54 62 70 77 85 Age 30 Formula for Window Width h 3.5 1 3 N standard deviation N=sample size h =window width 31 Example of Suspicious Value 25,000 Frequency 20,000 15,000 10,000 5,000 0 600 900 1200 License Year 1500 1800 32 Box and Whisker Plot 80 Normally Distributed Age 60 Outliers 40 +1.5*midspread 20 75th Percentile 0 median -20 25th Percentile 33 Plot of Heavy Tailed Data Paid Losses 110000 90000 Paid Loss 70000 50000 30000 10000 -10000 34 Heavy Tailed Data – Log Scale 107 106 Paid Loss 105 104 103 102 101 35 600 Frequency Box and Whisker Example 1,000 800 400 200 0 96 92 90 88 86 84 82 80 78 76 74 72 70 68 66 64 62 60 58 56 54 52 50 48 46 44 42 40 38 36 34 32 30 28 26 24 22 20 18 16 Age 36 Descriptive Statistics Analysis ToolPak Statistic Mean Standard Error Median Mode Standard Deviation Sample Variance Kurtosis Skewness Range Minimum Maximum Sum Count Largest(2) Smallest(2) Policyholder Age 36.9 0.1 35.0 32.0 13.2 174.4 0.5 0.7 84 16 100 1114357 30226 100 16 37 Descriptive Statistics License Year has minimum and maximums that are impossible N License Year 30,250 Valid N 30,250 Minimum 490 Maximum 2,049 Mean 1,990 Std. Deviation 16.3 38 Data Spheres: The Mahalanobis Distance Statistic 1 MD ( x μ) ' Σ ( x μ) x is a vector of variables μ is a vector of means Σ is a variance-covariance matrix 39 MD (x μ) ' Σ 1 (x μ) Screening Many Variables at Once Plot of Longitude and Latitude of zip codes in data Examination of outliers indicated drivers in Ca and PR even though policies only in one mid-Atlantic state 40 Records With Unusual Values Flagged Mahalanobis Percentile of Policy ID Depth Mahalanobis 22244 59 100 6159 60 100 22997 65 100 5412 61 100 30577 72 100 28319 8,490 100 27815 55 100 16158 24 100 4908 25 100 28790 24 100 Age 27 22 NA 17 43 30 44 82 56 82 License Number Number Model Incurred Year of Cars of Drivers Year Loss 1997 3 6 1994 4,456 2001 2 6 1993 0 NA 2 1 1954 0 2003 3 6 1994 0 1979 3 1 1952 0 490 1 1 1987 0 1976 -1 0 1959 0 1938 1 1 1989 61,187 1997 4 4 2003 35,697 2039 1 1 1985 27,769 41 Categorical Data: Data Cubes 42 Categorical Data Data Cubes Usually frequency tables Search for missing values coded as blanks Gender F M Total Frequency 5,054 13,032 17,198 35,284 Percent 14.3 36.9 48.7 100 43 Categorical Data Table highlights inconsistent coding of marital status Marital Status Frequency 1 2 4 D M S Total 5,053 2,043 9,657 2 4 2,971 15,554 35,284 Percent 14.3 5.8 27.4 0 0 8.4 44.1 100 44 Screening for Missing Data BUSINESS TYPE Age License Year 35,284 35,284 30,242 30,250 0 0 5,042 5,034 25 27.00 1,986.00 Percentiles 50 35.00 1,996.00 75 45.00 2,000.00 N Valid Gender Missing 45 Blanks as Missing Frequency Valid Percent Valid Percent Cumulative Percent 5,054 14.3 14.3 14.3 F 13,032 36.9 36.9 51.3 M 17,198 48.7 48.7 100.0 Total 35,284 100.0 100.0 46 Conclusions Anecdotal horror stories illustrate possible dramatic impact of data quality problems Data quality survey suggests data quality issues have a significant cost on actualial work Data Quality Working Party urges actuaries to become data quality advocated within their organizations Techniques from Exploratory Data Analysis can be used to detect data glitches 47 Library for Getting Started Dasu and Johnson, Exploratory Data Mining and Data Cleaning, Wiley, 2003 Francis, L.A., “Dancing with Dirty Data: Methods for Exploring and Cleaning Data”, CAS Winter Forum, March 2005, www.casact.org The Data Quality Working Party Paper will be Posted on the GIRO web site in about nine months 48