Experimental Design
An Experimental Design is a plan for the assignment
of the treatments to the plots in the experiment
Designs differ primarily in the way the plots are
grouped before the treatments are applied
– How much restriction is imposed on the random
assignment of treatments to the plots
A
B
D
A
A
B
D
C
C
D
B
C
C
D
B
A
B
A
D
C
B
A
D
C
Why do I need a design?
To provide an estimate of experimental error
To increase precision (blocking)
To provide information needed to perform tests
of significance and construct interval estimates
To facilitate the application of treatments -
particularly cultural operations
Factors to be Considered
Physical and topographic features
Soil variability
Number and nature of treatments
Experimental material (crop, animal, pathogen, etc.)
Duration of the experiment
Machinery to be used
Size of the difference to be detected
Significance level to be used
Experimental resources
Cost (money, time, personnel)
Cardinal Rule:
Choose the simplest
experimental design
that will give the
required precision
within the limits of the
available resources
Completely Randomized Design (CRD)
Simplest and least restrictive
Every plot is equally likely to be assigned to any
treatment
A
B
D
A
C
D
B
C
B
A
D
C
Advantages of a CRD
Flexibility
– Any number of treatments and any number of
replications
– Don’t have to have the same number of replications
per treatment (but more efficient if you do)
Simple statistical analysis
– Even if you have unequal replication
Missing plots do not complicate the analysis
Maximum error degrees of freedom
Disadvantage of CRD
Low precision if the plots are not uniform
A
B
D
A
C
D
B
C
B
A
D
C
Uses for the CRD
If the experimental site is relatively uniform
If a large fraction of the plots may not respond or
may be lost
If the number of plots is limited
Design Construction
No restriction on the assignment of treatments to the
plots
Each treatment is equally likely to be assigned to any
plot
Should use some sort of mechanical procedure to
prevent personal bias
Assignment of random numbers may be by:
– lot (draw a number )
– computer assignment
– using a random number table
Random Assignment by Lot
We have an experiment to test three varieties:
the top line from Oregon, Washington, and Idaho
to find which grows best in our area ----- t=3, r=4
A1
A
5
A
2
3
4
6
7
8
A
9 10 11 12
15
12
6
Random Assignment by Computer (Excel)
In Excel, type 1 in cell A1, 2 in
A2. Block cells A1 and A2. Use
the ‘fill handle’ to drag down
through A12 - or through the
number of total plots in your
experiment.
In cell B1, type = RAND(); copy
cell B1 and paste to cells B2
through B12 - or Bn.
Block cells B1 - B12 or Bn, Copy;
From Edit menu choose Paste
special and select values
(otherwise the values of the
random numbers will continue to
change)
Random numbers in Excel (cont’d.)
Sort columns A and B
(A1..B12) by column
B
Assign the first
treatment to the first r
(4) cells in column C,
the second treatment
to the second r (4)
cells, etc.
Re-sort columns A B
C by A if desired.
(A1..C12)
The Statistical Analysis
Partitions the total variation in the data into components
associated with sources of variation
– For a Completely Randomized Design (CRD)
• Treatments --- Error
– For a Randomized Complete Block Design (RBD)
• Treatments --- Blocks --- Error
Provides an estimate of experimental error (s2)
n
s2
2
(Y
Y)
i
i1
n 1
– Used to construct interval estimates and significance tests
Provides a way to test the significance of variance sources
Analysis of Variance (ANOVA)
Assumptions
The error terms are…
randomly, independently, and normally distributed,
with a mean of zero and a common variance.
The main effects are additive
Linear additive model for a Completely Randomized Design (CRD)
mean
Yij = + i + ij
observation
random error
treatment effect
The CRD Analysis
We can:
Estimate the treatment means
Estimate the standard error of a treatment mean
Test the significance of differences among the
treatment means
SiSj Yij=Y..
What?
i represents the treatment number (varies from 1 to t=3)
j represents the replication number (varies from 1 to r=4)
S is the symbol for summation
Treatment (i)
1
1
1
1
2
2
2
2
3
3
3
3
Replication (j)
1
2
3
4
1
2
3
4
1
2
3
4
Observation (Yij)
47.9
50.6
43.5
42.6
62.8
50.9
61.8
49.1
66.4
60.6
64.0
64.0
C
P
K
47.9
62.5
66.4
50.6
50.9
60.6
43.5
61.8
64.0
42.6
49.1
64.0
The CRD Analysis - How To:
Set up a table of observations and compute the
treatment means and deviations
Yij
Y Y..
, where N ri
N
Yi . j Yij
Yi
ri
ri
Ti (Yi Y)
grand mean
mean of the i-th treatment
deviation of the i-th treatment
mean from the grand mean
The CRD Analysis, cont’d.
Separate sources of variation
– Variation between treatments
– Variation within treatments (error)
Compute degrees of freedom (df)
– 1 less than the number of observations
– total df = N-1
– treatment df = t-1
– error df = N-t or t(r-1) if each treatment has the same r
Skeleton ANOVA for CRD
Source
Total
df
N-1
Treatments
t-1
Within treatments
(Error)
N-t
SS
MS
F
P >F
The CRD Analysis, cont’d.
Compute Sums of Squares
– Total
– Treatment
– Error SSE = SSTot - SST
SST r Y Y
SSTot i j Yij Y
2
2
i i
i
SSE i j Yij Yi
Compute Mean Squares
– Treatment
MST = SST / (t-1)
– Error
MSE = SSE / (N-t)
Calculate F statistic for treatments
– FT = MST/MSE
2
Using the ANOVA
Use FT to judge whether treatment means differ significantly
– If FT is greater than F in the table, then differences are significant
MSE = s2 or the sample estimate of the experimental error
– Used to compute standard errors and interval estimates
– Standard Error of a treatment mean
MSE
SY
r
– Standard Error of the difference between two means
1 1
SYi Yi MSE
ri ri
Numerical Example
A set of on-farm demonstration plots were located
throughout an agricultural district. A single plot was
located within a lentil field on each of 20 farms in the
district.
Each plot was fertilized and treated to control weevils
and weeds.
A portion of each plot was harvested for yield and the
farms were classified by soil type.
A CRD analysis was used to see if there were yield
differences due to soil type.
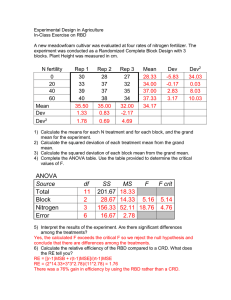
Table of Observations, Means, and Deviations
1
2
3
5
42.2
28.4
18.8
41.5
33.0
34.9
28.0
19.5
36.3
26.0
29.7
22.8
13.1
31.7
30.6
18.5
10.1
31.0
19.4
Mean
4
35.600
ri
3
Dev
8.415
Dev2
70.812
23.420
5
28.2
15.375
29.867
5
3
-11.810
6.555
2.682
14.175 139.476
42.968
7.191
-3.765
4
33.740
Mean
27.185
20
ANOVA Table
Source
df
Total
19
1,439.2055
4
1,077.6313
269.4078
15
361.5742
24.1049
Soil Type
Error
SS
MS
Fcritical(α=0.05; 4,15 df) = 3.06
** Significant at the 1% level
F
11.18**
Formulae and Computations
Coefficient of Variation
MSE
24.1049
CV
100
100 18.1%
Y
27.18
Standard Error of a Mean
s Y MSE r i 24.1049 3 2.83
Confidence Interval Estimate of a Mean (soil type 4)
L i Y i t MSE r i 33.74 2.131 24.1049 5 33.74 4.69
Formulae for Mean Comparisons
Standard Error of the Difference between Two Means
(for soils 1 and 2)
1 1
1 1
s Y Y MSE 24.1049 3.58
1
2
3 5
r1 r2
Test statistic with N-t df
12.18
Y
1 Y2
t
3.40
MSE(1 / r1 1 / r2 ) 3.58
Mean Yields and Standard Errors
Soil Type
Mean Yield
1
35.60
2
23.42
3
15.38
4
33.74
5
29.87
Replications
3
5
4
5
3
Standard error
2.83
2.20
2.45
2.20
2.83
CV = 18.1%
95% confidence interval estimate for soil type 4 = 33.74 4.69
Standard error of difference between 1 and 2 = 3.58
Report of Analysis
Analysis of yield data indicates highly significant
differences in yield among the five soil types
Soil type 1 produces the highest yield of lentil seed,
though not significantly different from type 4
Soil type 3 is clearly inferior to the others
1
4
5
2
3
 0
0