Classification.. continued
advertisement

Classification.. continued
Prediction and Classification
• Last week we discussed the classification
problem..
– Used the Naïve Bayes Method
• Today..we will dive into more details..
• But first how do we evaluate classifier
Abstract Binary Classification Problem
• Given n data samples{(x , y )}n where xi is a
i i
i=1
data vector and yi is label {-1,1}.
• Aim is to learn a function f : X ® Y
• Such that f is “accurate” on unseen data.
• [ill-specified as defined]
Algorithms to Learn Classifier
• We can use an algorithm A to learn the function f:
X Y
• Then we write f as fA
• One example of A is Naïve Bayes.
• Other examples {Logistic Regression, Neural
Networks, Support Vector Machines, Decision
Trees, Random Forests,….}
Training vs. Test Data
• In practice to take care of the “unseen”
part…we split the data into training and test
sets
• We learn fA on the training set using an
algorithm A
• The learned function fA is then evaluated on
the test set.
Example
• Suppose we learn a function F on training set.
• Our test set consists of four data points (z1,1),(z2,1),(z3,1),(z4,-1).
• We apply F on the four data points (without labels) and
we get F(z1)=1, F(z2)=1,F(z3)=-1 and F(z4) = -1.
• Then F correctly classified z1 and z4 but incorrectly
classified z2 and z3.
Confusion Matrix
Label 1 is called Positive, Label -1 is called Negative
Let the number of test samples be N
Actual Label (1)
Actual Label (-1)
Predicted Label (1)
True Positive (N1)
False Positive (N2)
Predicted Label (-1)
False Negatives (N3)
True Negatives (N4)
N = N1 + N2 + N3 + N4.
False Positive Rate (FPR) = N2/(N2+N4)
True Positive Rate (TPR) = N1/(N1+N3)
False Negative Rate (FNR) = N3/(N1+N3)
True Negative Rate (TNR) = N4/(N4+N2)
Accuracy = (N1+N4)/(N1+N2+N3+N4)
Precision = N1/(N1+N2)
Recall = N1/(N1+N3)
Example
Actual Label (1)
Actual Label (-1)
Predicted Label (1)
10
3
Predicted Label (-1)
2
20
TPR = 5/6; TNR = 20/23; FPR = 3/23; FNR = 2/12;
Accuracy = 30/35
Precision = 10/13 and Recall = 10/12
ROC (Receiver Operating
Characteristic) Curves
• Generally a learning algorithm A will return a
real number…but what we want is a label {1
or -1}
• We can apply a threshold..T
A
0.7
0.6
0.5
0.2
0.1
0.09
0.08
0.02
0.01
T=0.1
1
1
1
1
1
-1
-1
-1
-1
True
Label
1
1
-1
-1
1
1
-1
-1
-1
A
0.7
0.6
0.5
0.2
0.1
0.09
0.08
0.02
0.01
T=0.2
1
1
1
1
-1
-1
-1
-1
-1
True
Label
1
1
-1
-1
1
1
-1
-1
-1
TPR = 3/4
FPR = 2/5
TPR = 2/4
FPR = 2/5
ROC Curve
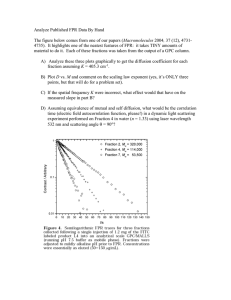
• An ROC Curve is the plot where the x-axis is
FPR, the y-axis is the TPR and for each
threshold t, the point on the plot represents
the pair (FPR(t), TPR(t))
• Lets Look at the Wikipedia ROC Entry
Discussion..
• If F: Symptoms {Disease, No-Disease}
– Higher Recall or Precision ?
– What is the relative cost of a mis-diagnosis (and
which way)
• If F: Banner Ad {Click, No-Click}
– Higher Precision means more revenue?
Random Variables
• A r.v. is a numerical quantity associated with events in
an experiment.
• Suppose we roll two dice. Let X = k be the sum of the
two faces.
• X can take values ranging from {2….12}.
• P(X=12) = 1/36. Why ?
– Event associated with X=12 is {(6,6)}
• P(X=7) = 6/36 = 1/6
– Associated Event: {(1,6),(6,1),(2,5),(5,2),(3,4),(4,3)}
Random Variable
• A random variable X can take values in a set
which is:
– discrete and finite.
• Lets toss a coin and X = 1 if it’s a head and X=0 if it’s a tail. X
is random variable
– discrete and infinite (countable)
• Let X be the number of accidents in Sydney in a day.. Then X
= 0,1,2,…..
– Infinite (uncountable)
• Let X be the height of a Sydney-sider.
– X = 150, 150.11,150.112,……
Random Variable Properties
• Let X be a discrete valued random variable
taking values in a set S.
å P(X = s) =1
sÎS
The Expected (average) Value of X, E(X) is
E(X) = å sP(X = s)
sÎS
• The Variance is Var(X) = E[(X - E(X))2 ]
Examples
• Let X be a random variable which takes values
1 with probability p and 0 with probability 1-p.
Then
E(X) = 0.(1- p)+1.p = p
Var(X) = (0 - p)2 (1- p) + (1- p)2 p
Var(X) = p 2 (1- p) + (1- p)2 p
Var(X) = p(1- p)[ p +1- p] = p(1- p)
Examples
• Let X be a random variable which denotes the
number of “spam emails” in a batch of n emails.
Assuming the probability of spam email is p.
• X={0,1,2,3,4,5}
X is a r.v. which follows a binomial distribution with
parameters (n,p)… X ~ Binomial(n,p)
– E(X) = np ; Var(X) = np(1-p)
Examples
• Let X be a random variable which denotes the
number of tcp packets that arrive in a unit
time. Then X can be modeled to follow a
Poisson distribution..
-l
e x
P(X = k) =
k!
• E(X) = Var(X) = λ
k
Continuous Distribution
• Ofcourse the most common continuous
distribution is the Normal/Gaussian
distribution… denoted
•
1
P(a <= X <= b) =
2ps
b
òe
a
-
1
2s
2
(
xm
)
2
dx
How to use r.v. for classification
• To use r.v. in classification…we have to make an
assumption.
– For example..Sepal Length follows a Normal Distribution.
– Is this a good/reasonable assumption.
• Then we use data to estimate the parameters of the
distribution..
– The parameters of a Normal distribution are the mean and
the variance (square of standard deviation).
– For the moment we can just use Matlab/program to do
that…
– Once we have the parameters we can use the distribution
to estimate the “probability” of Sepal Length taking a new
value..
Fitting Distributions..Examples
• 0,1,0,1,0,0
– Assume data from a Binomial distribution with 6 trials and 2 successes
• In Matlab:>> binofit(2,6) = 0.3333
• 10,20,5,3,3,100
–
–
–
–
Assume data is from a Poisson distribution
X=[10 20 5 3 3 100];
Poissfit(X);
Ans: 23.50
• What is happening ? We are just taking sample averages. The more
data we have the more reliable these estimates become..
• Suppose we take Sepal Length…data vector x
>> [mean,std] = normfit(x);
>> ans: mean = 5.8, std=0.81
Return to the Iris Example
• We will redo the Iris Classification
Example..but now will use “continuous” values
for the attributes…