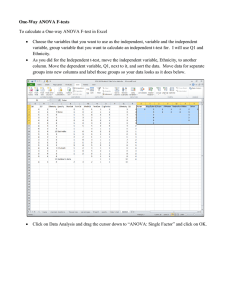
Introduction to Statistical Considerations in Experimental Research Dr. Richy Hetherington
advertisement

Introduction to Statistical Considerations in Experimental Research Dr. Richy Hetherington and Dr. Kim Pearce Introductions Today’s Session • Run a live Experiment • Discussion of considerations when setting up experiments • Analyse the results of our experiments with thoughts on what to look out for when analysing data • The best help for you Solving Problems Open the sheet and see what you make of the problems Simpson’s Paradox “Are people good intuitive statisticians? … …expert colleagues, like us, greatly exaggerated the likelihood that the original result of an experiment would be successfully replicated even with a small sample. They also gave very poor advice to a fictitious graduate student about the number of observations she needed to collect. Even statisticians were not good intuitive statisticians.” The Experiment Does perception of time relate to organisation and timeliness? Personality Types • http://bigthink.com/ideafeed/differentpersonalities-experience-time-differently An Experiment “The action of trying anything, or putting it to proof; a test, trial” Oxford English Dictionary My Life as a Turkey Book Illumination in the Flatwoods Joe Hutto Take Home Messages • Leave no stone unturned (use all possible sources of information) • Training to help (workshops throughout the year): Non-Medline Library Databases Robust search Methodologies for Literature Review Systematic Review Alerting Services Medline • Think about what is coming next Planning Your Experiments Take home message . Don’t believe everything you read & Introduction to Critical Appraisal (online) Academic Integrity and Plagiarism Use non-rigorous experiments but be prepared to repeat them with rigour Take home message. Get as much help as is available in setting up your experiments (shy bairns get nowt!) Make every result count Take home message . Set up your experiments so all eventualities are interesting Results can be meaningful and interesting without being statistically significant Also reporting non-significant findings avoids others from needlessly repeating that experiment Subject Selection and Randomisation • Make sure the sample you take is representative of what you are testing • Samples should be made randomly to avoid bias e.g. are you a representative sample of the population. What would I do if everyone had turned up early? Replication • Combining datasets from separate experiments is difficult • Datasets can be treated as replicates if all other variables are the same or weighted • Analysis of replicates indicate the amount of variation in a result Controls • Controls should give you internal validity • Take as much care with controls as with samples • Each experiment requires its own control Why have small sample sizes Animal experimentation Non-Human Primates often n=1 Very rare conditions the population is small Get a statisticians help now • “To call in the statistician after the experiment is done may be no more than asking him to perform a post-mortem examination: he may be able to say what the experiment died of.” Dr. R. A. Fisher ca1938 Type A (early birds) versus Type B (laid back) A (Early) vs B (Laid back) The independent 2 sample t-test (Parametric Test) • Subjects (units) are usually randomly assigned to two groups. One of the groups undergoes experimental manipulation (e.g. has a treatment applied), the other group is the control. • In many examples, however, two groups are compared where membership is ‘fixed’ e.g. males vs females, left vs right handed, early vs laid back etc. • We are testing if the two population means are equal. • The 2 sample t-test statistic makes use of 1. the difference between the (average) value of the A and B groups, 2. the (pooled) standard deviation, and 3. the size of the A and B groups. (We do not have to have equal numbers in our groups) • We compare the value of the statistic to a statistical distribution. The significance of the statistic is obtained and is expressed by a ‘p value’. • When p value is < 0.05 we say that the statistic is statistically significant i.e. in this case, there is evidence that the A group is different to the B group (in the population). Result using the data available • Do groups A and B differ? • p value=? • Let’s look at the data on a plot. The Boxplot Boxplot for the data today Using smaller samples • 5 people from A and 5 people from B were randomly chosen and the 2 sample t-test was again carried out. • Is there evidence that the A group is different to the B group (in the population)? • As the group size is small, there is a reduced chance of observing a difference between the A and B groups when we conduct the test. What is the power of these tests? • We would like our test to have high power which means that the test will detect a difference when it truly exists. • The power of the test is influenced by different things including sample size. • The lower sample size of our 2nd test (using 5 people from groups A and B) means that the test’s power has been reduced. Power of Our tests Test 1 (large sample sizes). Power = Test 2 (5 from A, 5 from B). Power= What influences the power of a test? 1. As variation in the sample increases, power decreases. 2. As the difference we care about decreases, power decreases. 3. As sample size decreases, power decreases. Prospective Power Analysis (used before collecting data) • Finding a sample size to detect an effect size we care about at a specific power. • Usually need to specify: Alpha level Variance (from literature or pilot data) Statistical power Effect size we care about* *Effect size could be, for example, the difference between the means Retrospective Power Analysis (after test has been done on collected data): controversial! • Finding the power of the test that you have performed to detect “an effect size”. • Usually need to specify: Alpha level Variance (from data) Sample Size Effect size Retrospective Power Analysis • You could: calculate power based on effect size you observe in your data: not recommended…… Power calculated in this way is related to the p value of the test and both are dependent on the observed effect size. - Non significant test tends to have low power; - Significant test tends to have high power. Retrospective Power Analysis • Calculate power based on effect size you care about. Less controversial. For example, say we get a non significant test…we can work out the power that your test has to detect an effect size that you care about. If test has a low power to detect this effect size then you can do something about it (e.g. collect more data) to increase the power, then continue to evaluate the same problem; if test has high power to detect this effect size, then you may conclude that there is no meaningful difference (effect) and refrain from collecting additional data. Suggested that you also report 95% confidence interval for power (as variance is estimated from sample data). • Which effect size should I choose? Look at a range of effect sizes. • Can also use ‘reverse power analysis’ : determine effect size detectable with a certain power…question could be ‘what effect size am I able to detect with my data at power 0.8?’ Retrospective Power Analysis • Calculate confidence intervals about the effect size calculated from your data –recommended. For example, if dealing with differences between means, we can be 95% confident that the true difference between the means (in the population) lie within this interval. If a zero is contained within the 95% confidence interval, this means there is no evidence to suggest that there is a difference between means. • We ask ourselves : does the ‘difference we care about’ lie in this interval? • Confidence intervals ‘quantify our uncertainty’. What is the confidence interval for our study? Let’s see how I did the power calculation! Retrospective Power Analysis • References • Hoenig, J.M. and Heisey, D.M. (2001). The abuse of power: The pervasive fallacy of power calculations for data analysis. The American Statistician 55, 19--24. • Thomas, L. (1997). Retrospective power analysis. Conservation Biology 11, 276-280. • Lenth, R.V. (2001). Some Practical Guidelines for Effective Sample Size Determination. The American Statistician, 55, No. 3, 187-193. Independent Samples Group 1 Group 2 More than 2 independent groups: 1-way Analysis of Variance (ANOVA) • We are testing if population means are equal when there are 3+ groups. • 1-way ANOVA is also called a ‘completely randomised’ experiment. • Subjects are regarded as being homogeneous ‘units’; even so, the subjects are assigned to the experimental groups at random to reduce the risk of any (unknown) variation influencing the experiment. More than 2 groups: 1-way Analysis of Variance (ANOVA) Hypothetical experimental set-up. Say a treatment 1 is learning method 1; treatment 2 is leaning method 2: Control Treatment 1 Treatment 2 • Each group is comprised of different subjects. • A measurement is recorded for each subject (in the above, say, “test score”). • Although not necessary, it is usually a good idea to have the same number of subjects in each treatment group. Adding a 2nd Factor: 2-Way ANOVA Alertness Fresh Tired Drug Placebo Drug A Drug B 10 people 10 people 10 people 10 people 10 people 10 people • In a 2 –way ANOVA we have 2 factors. Experiments such as this with two or more crossed factors are called factorial experiments. • There are n replicates per treatment combination (here 10 replicates). There are 10 different people per treatment combination. • The subjects (units) are considered homogeneous above & these units are randomly assigned to the 6 experimental conditions (combinations) • Here the 2 factors are ‘alertness’ and ‘drug’ type – by testing, we can establish if there are differences between (i) levels of alertness and (ii) levels of drug and (iii) establish if there is a alertness x drug interaction. 2-Way ANOVA: What is meant by an interaction? • There is a significant interaction. • The lines on the plot are non-parallel. • The difference in (mean) driving performance between fresh and tired subjects depends on which treatment (drug) they have received. • If an interaction is significant you must be careful interpreting the main effects....here, the effect of being fresh or tired is dependent on which level of drug you are considering. 1-way ANOVA - revisited • What do you think are its disadvantages? 1-way ANOVA - revisited • What are its disadvantages? 1. We may get differences between treatment groups occurring not just because the treatments are having different effects, but also because the groups of people tested are different (due to IQ levels, age, experience etc) i.e. there is a lot of noise which can cloud the result 2. It uses a lot of subjects Paired Samples Group 1 Group 2 Repeated Measures • • Each subject has a measure taken at each level of the treatment factor. In the example below, ‘learning method’ is the factor. It is called a ‘withinsubjects’ factor. 1 Learning Method 2 3 Note this is a simple example! There are many other more complex designs. Repeated Measures • Disadvantages: • Practice Effect: say if you had to learn 3 similar lists. The first list was learned under a control condition, then the second under method A, then the third under method B. An improvement under method A, for example, may be a practice effect – the more lists one learns, the better one gets at learning lists. • Carry over effect: Recall of items in a list is prone to interference from items in previous lists. • Order Effect (dependent on sequence of conditions). If we moved from method A to control condition, it would be almost impossible for the subject to cease to use method A on demand. Repeated Measures Counterbalancing • Remedy by “counterbalancing”.....the order of presentation of the levels making up the repeated measures factor is varied from subject to subject. It is hoped that carry over effects and order effects will balance out. • Counter balancing makes little sense in some situations e.g. it would make little sense to have the control condition coming last in the above example. Repeated Measures • Instead of the effects of different treatments being studied for a set of subjects, we may look at the effect of something over time. • For example: • does IQ change when we compare a set of subjects at age 12, age 13, age 14 and age 15? • A set of subjects learns a list of 50 words and are given 3 trials; the number of words recalled correctly per trail is recorded. We can test if the subjects learn as a function of practice. When do you need a 1-2-1 statistical session? • When: 1. You do not know what sample size is required to get a reliable result 2. You need to check that your proposed design is appropriate for a statistical test 3. When you have some idea of how to analyse your data but you need to double check and/or get further advice on appropriate methods 4. You need some suitable study references Statistics 1-2-1 Sessions • The statistics 1-2-1 sessions are only 1 hour long • They are NOT: 1. Meant as a means of regular intensive statistical tuition 2. Provided to solve a list of all of your statistical problems 3. Provided to have a statistician do your analysis for you 4. Provided to correct your results 5. A means to have a statistician interpret results and write your conclusions PLEASE send a detailed description of your query at least 2 days before the session. PLEASE avoid bringing queries/papers to the session which have not previously been seen by the statistician. Statistics –The Way Forward • Think Ahead!: what are the potential problems? Drop out? Missing Values? • Use your supervisor • Read some statistics books that feature the types of tests you need (manuals written to accompany statistical packages are good) • There are some good worked examples on youtube (e.g. how2stats) • Don’t gather your data, THEN try and fit a statistical test to a messy data set....you are going to run into problems. E.g. missing values, unequal replicates etc. It could make your analysis much more difficult than it should have been. ...and you may have to learn advanced techniques. • Please don’t leave the statistics until the last minute. • The analysis can be VERY time consuming and the writing of associated conclusions has to be spot on! Analysis Software • There are many statistics packages available. • MINITAB & SPSS are the most widely used & among the most straightforward to learn (Minitab has a good help facility) • The ISS (computing service) provides support to users. • Other packages (e.g. SAS) may be used in various schools. • Excel is not recommended as a piece of analysis software. So what is right for you? • Refresher in stats – – ISRU very basic stats (45 minutes) – ISRU basic stats (3 hours) clinical / pure science • • • • • • • Overview of Stats packages SPSS beginners and Advanced Getting stated with SAS MatLab Introduction to Applied Health Research Methods One to one stats is useful for anyone at the right time Maths aid by appointment (ncl.ac.uk/students/mathsaid/support/book.htm) • Applied Statistics (ICM students) Important messages reminder • Statistical Support is available for your needs • Get advice at the right time • Keep it simple • Don’t underestimate what information is relevant • Set up your tests to get noteworthy results • p < 0.05 is not everything