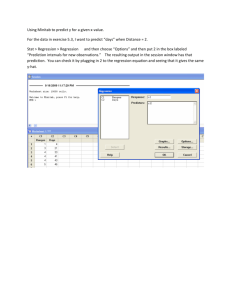
Introduction
advertisement

252y0541 5/7/05 Introduction What is a significant difference or a statistical test? Many of you seem to have no idea what a statistical test is. We have been doing them every day. For example, look at question 5b) in Part II. b. Of the campaigns that took 0 – 2 months 7 were ineffective. Of the campaigns that took more than two months, 8 were ineffective. Is the fraction that were ineffective in the first category below the fraction in the second category? (5) Any answer to this question should show that you are aware of the warning in the beginning of Part II. Show your work! State H 0 and H1 where applicable. Use a significance level of 5% unless noted otherwise. Do not answer questions without citing appropriate statistical tests – That is, explain your hypotheses and what values from what table were used to test them. In other words, if all you do here is compute some proportions and tell me that they are different, you are wasting both our time. A statistical test is required. If you don’t know what I mean by a (significant) difference between two fractions or proportions either 1) quit right now or 2) review the course material including the answer to 5b) until you do. I haven’t looked at this exam since it was given and I may have missed some corrections. 1 252y0541 5/7/05 ECO252 QBA2 Final EXAM May 4, 2005 Name and Class hour:____KEY________________ I. (25+ points) Do all the following. Note that answers without reasons receive no credit. Most answers require a statistical test, that is, stating or implying a hypothesis and showing why it is true or false by citing a table value or a p-value. If you haven’t done it lately, take a fast look at ECO 252 - Things That You Should Never Do on a Statistics Exam (or Anywhere Else) The next 12 pages contain computer output. This comes from a data set on the text CD-ROM called Auto2002. There are 121 observations. The dependent variable is MPG (miles per gallon). The columns in the data set are: Name The make and model SUV ‘Yes’ if it’s an SUV, ‘No’ if not. Drive Type All wheel, front wheel, rear wheel or four wheel. Horsepower An independent variable Fuel Type Premium or regular MPG The dependent variable Length In inches – an independent variable Width In inches – an independent variable Weight In pounds – an independent variable Cargo Volume Square feet – an independent variable Turning Circle Feet – an independent variable. I added the following SUV_D A dummy variable based on ‘SUV’, 1 for an SUV, otherwise zero. Fuel_D A dummy variable based on ‘Fuel Type’, 1 for a Premium fuel., otherwise zero SUVwt An interaction variable, the product of ‘SUV_D’ and ‘Weight’ SUVtc An interaction variable, the product of ‘SUV_D’ and ‘Turning Circle’ HPsq Horsepower Squared. AWD_D A dummy variable based on ‘Drive Type’, 1 for all wheel drive, otherwise zero FWD_D A dummy variable based on ‘Drive Type’, 1 for front wheel drive, otherwise zero RWD_D A dummy variable based on ‘Drive Type’, 1 for rear wheel drive, otherwise zero SUV_L An interaction variable, the product of ‘SUV_D’ and ‘Length’ Questions are included with the regressions and thus cannot be in order of difficulty. It’s probably a good idea to look over the questions and explanations before you do anything. ————— 4/28/2005 6:18:32 PM ———————————————————— Welcome to Minitab, press F1 for help. Results for: 252x0504-4.MTW MTB > Stepwise 'MPG' 'Horsepower' 'Length' 'Width' 'Weight' 'Cargo Volume' & CONT> 'Turning Circle' 'SUV_D' 'Fuel_D' 'SUVwt' 'HPsq' 'AWD_D' & CONT> 'FWD_D' 'RWD_D' 'SUV_L'; SUBC> AEnter 0.15; SUBC> ARemove 0.15; SUBC> Best 0; SUBC> Constant. Because I had relatively little idea of what to do, I ran a stepwise regression. You probably have not seen one of these before, but they are relatively easy to read. Note that it dropped 2 observations so that the results will not be quite the same as I got later. The first numbered column represents the single independent variable that seems to have the most explanatory effect on MPG, The equation reads MPG = 38.31 – 15.34 Weight The fact that Weight 2 252y0541 5/7/05 entered first with a negative coefficient should surprise no one. At the bottom appears s e , R 2 , R 2 and the C p statistic mentioned in your text. The value of the t-ratio and its p-value appear below the coefficient. Stepwise Regression: MPG versus Horsepower, Length, ... Alpha-to-Enter: 0.15 Alpha-to-Remove: 0.15 Response is MPG on 14 predictors, with N = 119 N(cases with missing observations) = 2 N(all cases) = 121 Step Constant Weight T-Value P-Value 1 38.31 2 36.75 3 41.59 4 50.06 5 50.15 6 59.00 -0.00491 -15.34 0.000 -0.00436 -11.87 0.000 -0.00578 -12.82 0.000 -0.00495 -9.31 0.000 -0.00424 -6.74 0.000 -0.00339 -5.61 0.000 -1.72 -2.84 0.005 -33.71 -4.99 0.000 -35.29 -5.36 0.000 -35.12 -5.40 0.000 -18.68 -2.71 0.008 0.180 4.75 0.000 0.185 5.04 0.000 0.182 5.01 0.000 0.088 2.26 0.026 -0.285 -2.79 0.006 -0.292 -2.90 0.004 -0.255 -2.75 0.007 -0.0124 -2.01 0.046 -0.1619 -5.04 0.000 SUV_D T-Value P-Value SUV_L T-Value P-Value Turning Circle T-Value P-Value Horsepower T-Value P-Value HPsq T-Value P-Value S R-Sq R-Sq(adj) Mallows C-p 0.00040 4.73 0.000 2.50 66.78 66.50 71.5 2.43 68.94 68.40 61.4 2.23 74.04 73.36 34.8 2.17 75.70 74.85 27.4 2.14 76.55 75.51 24.7 1.96 80.45 79.41 4.8 More? (Yes, No, Subcommand, or Help) SUBC> y I’m greedy, so while I was surprised that Minitab had found six explanatory (independent) variables that actually seemed to affect miles per gallon I wanted more. For the first time ever (for me), Minitab found another variable 3 252y0541 5/7/05 Step Constant 7 58.50 Weight T-Value P-Value -0.00342 -5.74 0.000 SUV_D T-Value P-Value -19.0 -2.79 0.006 SUV_L T-Value P-Value 0.090 2.36 0.020 Turning Circle T-Value P-Value -0.210 -2.24 0.027 Horsepower T-Value P-Value -0.175 -5.43 0.000 HPsq T-Value P-Value 0.00042 5.03 0.000 Fuel_D T-Value P-Value 0.92 2.11 0.037 S R-Sq R-Sq(adj) Mallows C-p 1.93 81.21 80.02 2.5 More? (Yes, No, Subcommand, or Help) SUBC> y No variables entered or removed More? (Yes, No, Subcommand, or Help) SUBC> n Because I was worried about Collinearity, I had the computer do a table of correlations between all the independent variables. The table is triangular since the correlation between, say, Length and Horsepower is going to be the same as the correlation between Horsepower and Length. So, for example, the correlation between Horsepower and Length is .648 and the p-value of zero below it evaluates the null hypothesis that the correlation is insignificant. The explanation of Predicted R2 that appears below the correlation table was a new one on me, but could help you in comparing the regressions. 4 252y0541 5/7/05 MTB > Correlation 'Horsepower' 'Length' 'Width' 'Weight' 'Cargo Volume' & CONT> 'Turning Circle' 'SUV_D' 'Fuel_D' 'SUVwt' 'SUVtc' 'HPsq' 'AWD_D' & CONT> 'FWD_D' 'RWD_D' 'SUV_L'. Correlations: Horsepower, Length, Width, Weight, Cargo Volume, ... Horsepower 0.648 0.000 Length Width 0.660 0.000 0.825 0.000 Weight 0.673 0.000 0.634 0.000 0.780 0.000 Cargo Volume 0.296 0.001 0.395 0.000 0.546 0.000 0.716 0.000 Turning Circ 0.497 0.000 0.750 0.000 0.658 0.000 0.650 0.000 SUV_D 0.160 0.080 -0.102 0.265 0.180 0.049 0.535 0.000 Fuel_D 0.321 0.000 -0.013 0.886 -0.042 0.645 0.057 0.540 SUVwt 0.182 0.045 -0.077 0.403 0.206 0.023 0.562 0.000 SUVtc 0.185 0.042 -0.062 0.502 0.211 0.020 0.577 0.000 HPsq 0.989 0.000 0.632 0.000 0.645 0.000 0.668 0.000 AWD_D 0.059 0.523 -0.118 0.199 -0.037 0.691 0.065 0.483 FWD_D -0.370 0.000 -0.001 0.994 -0.163 0.076 -0.453 0.000 RWD_D 0.334 0.000 0.070 0.445 0.151 0.101 0.351 0.000 SUV_L 0.197 0.030 -0.053 0.564 0.219 0.016 0.582 0.000 Cargo Volume 0.486 0.000 Turning Circ SUV_D Fuel_D 0.459 0.000 0.139 0.127 -0.245 0.007 -0.069 0.456 -0.147 0.110 SUVwt 0.473 0.000 0.161 0.078 0.999 0.000 -0.141 0.125 SUVtc 0.484 0.000 0.196 0.031 0.996 0.000 -0.142 0.121 Length Turning Circ SUV_D Fuel_D Width Weight 5 252y0541 5/7/05 HPsq 0.289 0.001 0.480 0.000 0.173 0.058 0.296 0.001 AWD_D 0.021 0.823 -0.068 0.461 0.185 0.043 0.218 0.017 FWD_D -0.165 0.071 -0.027 0.771 -0.517 0.000 -0.280 0.002 RWD_D 0.108 0.239 0.015 0.874 0.364 0.000 0.098 0.288 SUV_L 0.487 0.000 0.181 0.047 0.996 0.000 -0.145 0.114 SUVwt 0.998 0.000 SUVtc HPsq AWD_D HPsq 0.198 0.030 0.200 0.028 AWD_D 0.184 0.044 0.174 0.057 0.040 0.667 FWD_D -0.522 0.000 -0.526 0.000 -0.369 0.000 -0.366 0.000 RWD_D 0.367 0.000 0.374 0.000 0.347 0.000 -0.137 0.135 SUV_L 0.999 0.000 0.998 0.000 0.215 0.018 0.176 0.054 FWD_D -0.810 0.000 RWD_D -0.529 0.000 0.381 0.000 SUVtc RWD_D SUV_L Cell Contents: Pearson correlation P-Value PRESS Assesses your model's predictive ability. In general, the smaller the prediction sum of squares (PRESS) value, the better the model's predictive ability. PRESS is used to calculate the predicted R2. PRESS, similar to the error sum of squares (SSE), is the sum of squares of the prediction error. PRESS differs from SSE in that each fitted value, i, for PRESS is obtained by deleting the ith observation from the data set, estimating the regression equation from the remaining n - 1 observations, then using the fitted regression function to obtain the predicted value for the ith observation. Predicted R2 Similar to R2. Predicted R2 indicates how well the model predicts responses for new observations, 2 whereas R indicates how well the model fits your data. Predicted R2 can prevent overfitting the model and is more useful than adjusted R2 for comparing models because it is calculated with observations not included in model calculation. Predicted R2 is between 0 and 1 and is calculated from the PRESS statistic. Larger values of predicted R 2 suggest models of greater predictive ability. 6 252y0541 5/7/05 So now it’s time to get serious. My first regression was based on what I had learned from the stepwise regression. The only one of the variables that I left out from the stepwise regression was FUEL_D. 1. Look at the results of Regression 1. But don’t forget what has gone before. a. What does the Analysis of variance show us? Why? (1) b. What suggests that the relation of MPG to one of the variables is nonlinear? (1) c. What does the equation suggest that the difference is between an extra inch on an SUV and a non_SUV? (1) d. Why did I leave out FUEL_D (2) e. Which coefficients are not significant? Why? (2) f. What do the values of the VIFs tell us? (2) MTB > Regress 'MPG' 6 'Weight' 'SUV_D' 'SUV_L' 'Turning Circle' CONT> 'Horsepower' 'HPsq'; SUBC> Constant; SUBC> Brief 2. & MTB > Regress 'MPG' 6 'Weight' 'SUV_D' 'SUV_L' 'Turning Circle' CONT> 'Horsepower' 'HPsq'; SUBC> GNormalplot; SUBC> NoDGraphs; SUBC> RType 1; SUBC> Constant; SUBC> VIF; SUBC> Press; SUBC> Brief 2. & Regression Analysis: MPG versus Weight, SUV_D, ... (Regression 1) The regression equation is MPG = 63.1 - 0.00303 Weight - 14.8 SUV_D + 0.0653 SUV_L - 0.264 Turning Circle - 0.213 Horsepower + 0.000522 HPsq Predictor Constant Weight SUV_D SUV_L Turning Circle Horsepower HPsq Coef 63.105 -0.0030345 -14.812 0.06527 -0.2639 -0.21251 0.00052249 SE Coef 3.978 0.0006859 7.957 0.04478 0.1050 0.03575 0.00009459 T 15.86 -4.42 -1.86 1.46 -2.51 -5.94 5.52 P 0.000 0.000 0.065 0.148 0.013 0.000 0.000 VIF 5.6 282.1 307.9 2.0 63.5 61.3 S = 2.27485 R-Sq = 77.5% R-Sq(adj) = 76.4% PRESS = 752.906 R-Sq(pred) = 71.34% Analysis of Variance Source DF SS Regression 6 2037.34 Residual Error 114 589.95 Total 120 2627.29 Source Weight SUV_D SUV_L Turning Circle Horsepower HPsq DF 1 1 1 1 1 1 MS 339.56 5.17 F 65.62 P 0.000 Seq SS 1605.19 47.29 132.83 52.31 41.83 157.89 Unusual Observations Obs Weight MPG Fit 16 5590 13.000 15.361 34 7270 10.000 6.856 40 5590 13.000 15.361 62 4065 19.000 14.633 SE Fit 1.137 1.461 1.137 0.654 Residual -2.361 3.144 -2.361 4.367 St Resid -1.20 X 1.80 X -1.20 X 2.00R 7 252y0541 5/7/05 108 111 114 115 2150 2750 2935 2940 38.000 41.000 41.000 24.000 30.489 33.473 29.806 29.791 0.632 1.133 0.777 0.778 7.511 7.527 11.194 -5.791 3.44R 3.82RX 5.24R -2.71R R denotes an observation with a large standardized residual. X denotes an observation whose X value gives it large influence. 2. Look at the results of Regression 2. But don’t forget what has gone before. a. What variable did I drop? Why? (2) b. Are there any coefficients that have a sign that you would not expect? Why? (1) c. A Chevrolet Suburban is an SUV with rear wheel drive and 285 horsepower, that takes Regular fuel, has a length of 219 inches, a width of 79 inches, a weight of 5590 pounds, a cargo volume of 77.0 square feet and a turning circle of 46 Feet (!!! Maybe it was inches?). What miles per gallon does the equation predict? What would it be if the vehicle was not classified as an SUV? (3) d. Why do I like this regression better than the previous one? (2) [17] MTB > Regress 'MPG' 5 'Weight' 'SUV_D' CONT> 'HPsq'; SUBC> GNormalplot; SUBC> NoDGraphs; SUBC> RType 1; SUBC> Constant; SUBC> VIF; SUBC> Press; SUBC> Brief 2. 'Turning Circle' 'Horsepower' Regression Analysis: MPG versus Weight, SUV_D, ... & (Regression 2) The regression equation is MPG = 63.1 - 0.00250 Weight - 3.25 SUV_D - 0.250 Turning Circle - 0.239 Horsepower + 0.000593 HPsq Predictor Constant Weight SUV_D Turning Circle Horsepower HPsq Coef 63.137 -0.0025020 -3.2492 -0.2501 -0.23928 0.00059313 SE Coef 3.998 0.0005834 0.6272 0.1051 0.03082 0.00008163 T 15.79 -4.29 -5.18 -2.38 -7.76 7.27 P 0.000 0.000 0.000 0.019 0.000 0.000 VIF 4.0 1.7 1.9 46.7 45.2 S = 2.28595 R-Sq = 77.1% R-Sq(adj) = 76.1% PRESS = 744.047 R-Sq(pred) = 71.68% Analysis of Variance Source DF SS Regression 5 2026.35 Residual Error 115 600.94 Total 120 2627.29 Source Weight SUV_D Turning Circle Horsepower HPsq DF 1 1 1 1 1 MS 405.27 5.23 F 77.56 P 0.000 Seq SS 1605.19 47.29 46.32 51.65 275.90 Unusual Observations Obs 16 34 40 108 Weight 5590 7270 5590 2150 MPG 13.000 10.000 13.000 38.000 Fit 14.381 5.945 14.381 30.081 SE Fit 0.921 1.328 0.921 0.570 Residual -1.381 4.055 -1.381 7.919 St Resid -0.66 X 2.18RX -0.66 X 3.58R 8 252y0541 5/7/05 111 114 115 2750 2935 2940 41.000 41.000 24.000 33.910 30.060 30.047 1.098 0.761 0.762 7.090 10.940 -6.047 3.54RX 5.08R -2.81R R denotes an observation with a large standardized residual. X denotes an observation whose X value gives it large influence. Because I wanted to look at the effect of the three drive variables on MPG, I ran another stepwise regression. The first part of this is identical to the last stepwise regression, but after the 6 th regression, I forced out SUV_L and forced in AWD_D, FWD_D and RWD_D. Because I had to make the regressions comparable, I threw an observation with an anomalous drive variable out and redid my two regressions as Regressions 3 and 4. I then added in all the drive variables as a package in Regression 5. MTB > Stepwise 'MPG' 'Horsepower' 'Length' 'Width' 'Weight' 'Cargo Volume' & CONT> 'Turning Circle' 'SUV_D' 'Fuel_D' 'SUVwt' 'HPsq' 'AWD_D' & CONT> 'FWD_D' 'RWD_D' 'SUV_L'; SUBC> AEnter 0.15; SUBC> ARemove 0.15; SUBC> Best 0; SUBC> Constant. Stepwise Regression: MPG versus Horsepower, Length, ... Alpha-to-Enter: 0.15 Alpha-to-Remove: 0.15 Response is MPG on 14 predictors, with N = 119 N(cases with missing observations) = 2 N(all cases) = 121 Step Constant Weight T-Value P-Value 1 38.31 2 36.75 3 41.59 4 50.06 5 50.15 6 59.00 -0.00491 -15.34 0.000 -0.00436 -11.87 0.000 -0.00578 -12.82 0.000 -0.00495 -9.31 0.000 -0.00424 -6.74 0.000 -0.00339 -5.61 0.000 -1.72 -2.84 0.005 -33.71 -4.99 0.000 -35.29 -5.36 0.000 -35.12 -5.40 0.000 -18.68 -2.71 0.008 0.180 4.75 0.000 0.185 5.04 0.000 0.182 5.01 0.000 0.088 2.26 0.026 -0.285 -2.79 0.006 -0.292 -2.90 0.004 -0.255 -2.75 0.007 -0.0124 -2.01 0.046 -0.1619 -5.04 0.000 SUV_D T-Value P-Value SUV_L T-Value P-Value Turning Circle T-Value P-Value Horsepower T-Value P-Value HPsq T-Value P-Value S R-Sq R-Sq(adj) Mallows C-p 0.00040 4.73 0.000 2.50 66.78 66.50 71.5 2.43 68.94 68.40 61.4 2.23 74.04 73.36 34.8 2.17 75.70 74.85 27.4 2.14 76.55 75.51 24.7 1.96 80.45 79.41 4.8 More? (Yes, No, Subcommand, or Help) SUBC> remove 'SUV_L'. Step 7 8 9 9 252y0541 5/7/05 Constant 59.15 59.00 58.50 Weight T-Value P-Value -0.00267 -5.10 0.000 -0.00339 -5.61 0.000 -0.00342 -5.74 0.000 SUV_D T-Value P-Value -3.13 -5.51 0.000 -18.68 -2.71 0.008 -18.95 -2.79 0.006 0.088 2.26 0.026 0.090 2.36 0.020 SUV_L T-Value P-Value Turning Circle T-Value P-Value -0.236 -2.51 0.013 -0.255 -2.75 0.007 -0.210 -2.24 0.027 Horsepower T-Value P-Value -0.199 -7.09 0.000 -0.162 -5.04 0.000 -0.175 -5.43 0.000 0.00050 6.75 0.000 0.00040 4.73 0.000 0.00042 5.03 0.000 HPsq T-Value P-Value Fuel_D T-Value P-Value S R-Sq R-Sq(adj) Mallows C-p 0.92 2.11 0.037 2.00 79.56 78.66 7.8 1.96 80.45 79.41 4.8 1.93 81.21 80.02 2.5 More? (Yes, No, Subcommand, or Help) SUBC> enter 'AWD_D' 'FWD_D' 'RWD_D'. Step Constant 10 60.14 11 59.11 12 58.50 13 58.50 Weight T-Value P-Value -0.00355 -5.75 0.000 -0.00346 -5.72 0.000 -0.00344 -5.72 0.000 -0.00342 -5.74 0.000 SUV_D T-Value P-Value -19.5 -2.82 0.006 -19.1 -2.77 0.007 -18.8 -2.74 0.007 -19.0 -2.79 0.006 SUV_L T-Value P-Value 0.092 2.37 0.020 0.090 2.32 0.022 0.089 2.30 0.023 0.090 2.36 0.020 Turning Circle T-Value P-Value -0.207 -2.10 0.038 -0.205 -2.09 0.039 -0.202 -2.07 0.041 -0.210 -2.24 0.027 Horsepower T-Value P-Value -0.175 -5.33 0.000 -0.177 -5.42 0.000 -0.176 -5.41 0.000 -0.175 -5.43 0.000 0.00042 4.98 0.000 0.00043 5.04 0.000 0.00042 5.02 0.000 0.00042 5.03 0.000 HPsq T-Value P-Value 10 252y0541 5/7/05 Fuel_D T-Value P-Value 0.73 1.49 0.139 0.80 1.66 0.099 0.87 1.92 0.057 AWD_D T-Value P-Value -1.1 -0.76 0.451 FWD_D T-Value P-Value -1.36 -0.98 0.331 -0.51 -0.62 0.535 -0.17 -0.32 0.752 RWD_D T-Value P-Value -1.23 -0.93 0.353 -0.42 -0.55 0.586 S R-Sq R-Sq(adj) Mallows C-p 1.95 81.37 79.65 7.6 1.95 81.27 79.73 6.1 0.92 2.11 0.037 1.94 81.22 79.86 4.4 1.93 81.21 80.02 2.5 More? (Yes, No, Subcommand, or Help) SUBC> no Results for: 252x0504-41.MTW MTB > WSave "C:\Documents and Settings\rbove\My Documents\Minitab\252x050441.MTW"; SUBC> Replace. Saving file as: 'C:\Documents and Settings\rbove\My Documents\Minitab\252x0504-41.MTW' MTB > erase c21 MTB > Regress 'MPG' 6 'Weight' 'SUV_D' 'SUV_L' 'Turning Circle' & CONT> 'Horsepower' 'HPsq' ; SUBC> GNormalplot; SUBC> NoDGraphs; SUBC> RType 1; SUBC> Constant; SUBC> VIF; SUBC> Press; SUBC> Brief 2. Regression Analysis: MPG versus Weight, SUV_D, ... (Regression 3) The regression equation is MPG = 64.4 - 0.00284 Weight - 15.8 SUV_D + 0.0694 SUV_L - 0.305 Turning Circle - 0.214 Horsepower + 0.000524 HPsq Predictor Constant Weight SUV_D SUV_L Turning Circle Horsepower HPsq Coef 64.364 -0.0028431 -15.843 0.06943 -0.3045 -0.21444 0.00052386 SE Coef 3.973 0.0006832 7.867 0.04423 0.1055 0.03528 0.00009332 T 16.20 -4.16 -2.01 1.57 -2.89 -6.08 5.61 P 0.000 0.000 0.046 0.119 0.005 0.000 0.000 VIF 5.7 276.4 301.7 2.0 63.1 61.0 S = 2.24427 R-Sq = 78.3% R-Sq(adj) = 77.2% PRESS = 725.963 R-Sq(pred) = 72.34% Analysis of Variance Source DF SS Regression 6 2055.21 Residual Error 113 569.15 Total 119 2624.37 Source DF MS 342.54 5.04 F 68.01 P 0.000 Seq SS 11 252y0541 5/7/05 Weight SUV_D SUV_L Turning Circle Horsepower HPsq 1 1 1 1 1 1 Unusual Observations Obs Weight MPG 16 5590 13.000 34 7270 10.000 36 2715 24.000 40 5590 13.000 107 2150 38.000 110 2750 41.000 113 2935 41.000 114 2940 24.000 1602.61 49.58 135.39 61.04 47.88 158.71 Fit 15.259 6.907 28.432 15.259 30.543 33.747 30.000 29.985 SE Fit 1.123 1.442 0.493 1.123 0.624 1.126 0.772 0.774 Residual -2.259 3.093 -4.432 -2.259 7.457 7.253 11.000 -5.985 St Resid -1.16 X 1.80 X -2.02R -1.16 X 3.46R 3.74RX 5.22R -2.84R R denotes an observation with a large standardized residual. X denotes an observation whose X value gives it large influence. MTB > Regress 'MPG' 5 'Weight' 'SUV_D' CONT> 'HPsq' ; SUBC> GNormalplot; SUBC> NoDGraphs; SUBC> RType 1; SUBC> Constant; SUBC> VIF; SUBC> Press; SUBC> Brief 2. 'Turning Circle' 'Horsepower' Regression Analysis: MPG versus Weight, SUV_D, ... & (Regression 4) The regression equation is MPG = 64.4 - 0.00228 Weight - 3.53 SUV_D - 0.288 Turning Circle - 0.243 Horsepower + 0.000599 HPsq Predictor Constant Weight SUV_D Turning Circle Horsepower HPsq Coef 64.352 -0.0022848 -3.5330 -0.2884 -0.24278 0.00059879 SE Coef 3.999 0.0005871 0.6366 0.1057 0.03051 0.00008071 T 16.09 -3.89 -5.55 -2.73 -7.96 7.42 P 0.000 0.000 0.000 0.007 0.000 0.000 VIF 4.2 1.8 2.0 46.6 45.0 S = 2.25865 R-Sq = 77.8% R-Sq(adj) = 76.9% PRESS = 720.507 R-Sq(pred) = 72.55% Analysis of Variance Source DF SS Regression 5 2042.80 Residual Error 114 581.57 Total 119 2624.37 Source Weight SUV_D Turning Circle Horsepower HPsq DF 1 1 1 1 1 MS 408.56 5.10 F 80.09 P 0.000 Seq SS 1602.61 49.58 52.45 57.33 280.82 Unusual Observations Obs Weight MPG Fit 16 5590 13.000 14.223 34 7270 10.000 5.938 40 5590 13.000 14.223 107 2150 38.000 30.108 SE Fit 0.914 1.312 0.914 0.563 Residual -1.223 4.062 -1.223 7.892 St Resid -0.59 X 2.21RX -0.59 X 3.61R 12 252y0541 5/7/05 110 113 114 2750 2935 2940 41.000 41.000 24.000 34.201 30.262 30.251 1.095 0.759 0.760 6.799 10.738 -6.251 3.44RX 5.05R -2.94R R denotes an observation with a large standardized residual. X denotes an observation whose X value gives it large influence. Look at the results of Regression 5 and Regression 4. But don’t forget what has gone before. a. Do an F test to see if Regression 5 is better than Regression 4. If you can include the results from my forcing variables in the last stepwise regression. (6) b. Should I have included another dummy variable to represent 4-wheel drive? Why? (2) c. Are there any coefficients in Regression 5 that have a sign that you would not expect? Why? (1) d. A Chevrolet Suburban is an SUV with rear wheel drive and 285 horsepower, that takes Regular fuel, has a length of 219 inches, a width of 79 inches, a weight of 5590 pounds, a cargo volume of 77.0 square feet and a turning circle of 46 Feet (!!! Maybe it was inches?). How do the predictions for MPG in Equations 2 and 4 differ in percentage terms? (3) [29] Why do I like this regression better than the pr 3. MTB > Regress 'MPG' 8 'Weight' 'SUV_D' 'Turning Circle' 'Horsepower' CONT> 'HPsq' 'AWD_D' 'FWD_D' 'RWD_D'; SUBC> GNormalplot; SUBC> NoDGraphs; SUBC> RType 1; SUBC> Constant; SUBC> VIF; SUBC> Press; SUBC> Brief 2. Regression Analysis: MPG versus Weight, SUV_D, ... & (Regression 5) The regression equation is MPG = 66.4 - 0.00248 Weight - 3.83 SUV_D - 0.254 Turning Circle - 0.251 Horsepower + 0.000618 HPsq - 1.21 AWD_D - 2.10 FWD_D - 1.70 RWD_D Predictor Constant Weight SUV_D Turning Circle Horsepower HPsq AWD_D FWD_D RWD_D Coef 66.435 -0.0024795 -3.8302 -0.2541 -0.25082 0.00061833 -1.213 -2.103 -1.697 SE Coef 4.400 0.0006077 0.6814 0.1116 0.03122 0.00008244 1.620 1.490 1.434 T 15.10 -4.08 -5.62 -2.28 -8.03 7.50 -0.75 -1.41 -1.18 P 0.000 0.000 0.000 0.025 0.000 0.000 0.455 0.161 0.239 VIF 4.4 2.0 2.2 48.6 46.7 3.4 11.2 8.6 S = 2.26416 R-Sq = 78.3% R-Sq(adj) = 76.8% PRESS = 727.840 R-Sq(pred) = 72.27% Analysis of Variance Source DF SS Regression 8 2055.33 Residual Error 111 569.03 Total 119 2624.37 Source Weight SUV_D Turning Circle Horsepower HPsq AWD_D DF 1 1 1 1 1 1 MS 256.92 5.13 F 50.12 P 0.000 Seq SS 1602.61 49.58 52.45 57.33 280.82 2.00 13 252y0541 5/7/05 FWD_D RWD_D 1 1 3.36 7.17 Unusual Observations Obs 34 57 72 107 109 110 113 114 Weight 7270 4735 4720 2150 5435 2750 2935 2940 MPG 10.000 14.000 15.000 38.000 14.000 41.000 41.000 24.000 Fit 5.609 13.622 15.901 30.231 13.477 34.346 30.341 30.329 SE Fit 1.377 1.447 1.374 0.574 1.338 1.106 0.765 0.766 Residual 4.391 0.378 -0.901 7.769 0.523 6.654 10.659 -6.329 St Resid 2.44RX 0.22 X -0.50 X 3.55R 0.29 X 3.37RX 5.00R -2.97R R denotes an observation with a large standardized residual. X denotes an observation whose X value gives it large influence. 14 252y0541 5/7/05 II. Do at least 4 of the following 6 Problems (at least 15 each) (or do sections adding to at least 60 points – (Anything extra you do helps, and grades wrap around) . Show your work! State H 0 and H1 where applicable. Use a significance level of 5% unless noted otherwise. Do not answer questions without citing appropriate statistical tests – That is, explain your hypotheses and what values from what table were used to test them. Clearly label what section of each problem you are doing! The entire test has 175 points, but 100 is considered a perfect score. Exhibit 1. A tear-off copy of this exhibit appears at the end of the exam. An entrepreneur believes that her business is growing steadily and wants to compute a trend line for her output Y against time x1 T . She also decides to repeat the regression after adding x 2 T 2 as a second independent variable. Her data and results follow. The t statistics have been relabeled ‘t-ratio’ to prevent confusion with T . Regression Analysis: Y versus T Row 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Y 53.43 59.09 59.58 64.75 68.65 65.53 68.44 70.93 72.85 73.60 72.93 75.14 73.88 76.55 79.05 T 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 T2 1 4 9 16 25 36 49 64 81 100 121 144 169 196 225 The regression equation is Y = 56.7 + 1.54 T Predictor Coef SE Coef Constant 56.659 1.283 T 1.5377 0.1411 S = 2.36169 R-Sq = 90.1% t-ratio P 44.15 0.000 10.89 0.000 R-Sq(adj) = 89.4% Regression Analysis: Y versus T, TSQ The regression equation is Y = 52.4 + 3.04 T - 0.0939 TSQ Predictor Coef SE Coef Constant 52.401 1.545 T 3.0405 0.4444 TSQ -0.09392 0.02701 S = 1.73483 R-Sq = 95.1% t-ratio P 33.91 0.000 6.84 0.000 -3.48 0.005 If you need them, her means and spare parts are below. Y 68.9600 X 22 nX 22 SSX 2 75805.3 X 1 8.00 Y 2 nY 2 SST SSY 734.556 X 2 82.6667 X 1Y nX 1Y SX 1Y 430.550 X 12 nX 12 SSX1 280 X 2 Y nX 2 Y SX 2Y 6501.33 X 1X 2 nX 1 X 2 SX 1X 2 4480.00 15 252x0541 4/22/05 1. Do the following using Exhibit 1. a) Explain what numbers in the printout were used to compute the t-ratio 6.84, what table value you would compare it with to do a 2-sided 1% significance test and whether and why the coefficient is significant. (3) b) The entrepreneur looked at the residual analysis of the first regression and decided that she needs a time squared term. What is she likely to have seen to cause her to make that decision? (1) c) Use the values of R 2 to do an F test to see if the addition of the T 2 term makes a significant improvement in the regression. (4) d) Get (Compute) R 2 ( R 2 adjusted for degrees of freedom) for the second regression and explain what it seems to show. (2) e) In the first regression, the Durbin-Watson statistic was 1.07 and for the second it was 1.94. What do these numbers indicate? (Do a significance test.) (5) f) For the second regression, make a prediction of the output in the 16 th year and use the suggestion in the outline to make it into a prediction interval. Why would a confidence interval be inappropriate here? (3) g) (Extra Credit) Find the partial correlation, rY 1.2 . (2) [15] H 0 : i i 0 b i0 b 0 3.0405 a) n 15 and .01 .To test use t i i . So t1 1 6.84 . H : s s b1i 0.4444 i0 1 i bi Compare this with t nk 1 t 12 3.055 . Since the computed t-ratio is larger than the table value, reject .005 2 H 0 : 1 0 and conclude that the coefficient is significant. b) A curvature about the x- axis. c) With only one independent variable R12 90.1% and after the T 2 was added R22 95.1% The difference between the two is 5.0%. The F test show in the outline was to compute 2 2 n k r 1 Rk r Rk F r ,n k r 1 Here k is the number of independent variables in the first 2 r 1 Rk r regression and r is the number of independent variables added. This was discussed in Problem J1 and the following fake ANOVA was suggested. The second computed F is larger than table F and so our null hypothesis that the T 2 term has no effect is rejected. This test is identical to the t test on the T 2 term and 1,12 9.33 is we can note that 12.42 is approximately equal to the square of the t-ratio (-3.48) and that F.01 12 3.055 . the square of t .005 Source SS 1X 1 more X Error Total DF MS F 90.1 1 90.1 220.65s 5.0 1 5.0 12.42s 4.9 100 12 14 F.05 1,12 9.33 F.01 1,12 9.33 F.01 0.40833 n 1R 2 k 15 1.951 2 .943 . For the previous regression R-Sq(adj) = 89.4% . This is a 15 2 1 n k 1 preliminary indicator that the explanatory power of the regression rose when we added a new variable. d) Rk2 16 252x0541 4/22/05 e) For the first regression DW was 1.07 and for the second it was 1.94. n 15 . k 1 in the first regression and k 2 in the second. The table in the text says that for k 1 and .01 , d L 0.81 and d U 1.07 and that for .05 , d L 1.08 and d U 1.36 . For k 2 and .01 , d L 0.70 and d U 1.25 and that for .05 , d L 0.95 and d U 1.54 . The line in the notes is shown below. 0 + 0 dL + ? 0 dU + 2 + 0 4 dU + ? If we slip the 1% values in, we get the following for k 1 0 0 0.81 ? 1.07 0 2 0 2.93 + + + + + For the 5% values and k 1 0 0 1.08 ? 1.36 + + + 0 For the 1% values and k 2 0 0 0.70 ? 1.25 + + + 0 For the 5% values and k 2 0 0 0.95 ? 1.54 + + + 0 2 + 0 2 + 0 2 + 0 ? 2.64 + ? 2.75 + ? 2.46 + ? 4 dL + 0 4 + 3.19 + 0 3.92 + 0 3.30 + 0 3.05 + 0 4 + 4 + 4 + 4 + For the tests for k 1 , our value of DW seems to be in the ‘?’ range, but for the second regression 1.94 is comfortable in the ‘no autocorrelation’ range. f) T 16 . The regression equation is Y = 52.4 + 3.04 T - 0.0939 TSQ and s e S = s The outline says “To find an approximate confidence interval Y0 Yˆ0 t e and an n approximate prediction interval Y Yˆ t s . Remember df n k 1 .” The prediction interval is 1.73483. 0 0 e appropriate here because we are making a single predication. So Y 52 .4 3.0416 0.0939 16 2 t .12 005 `1.73486 52 .4 48 .64 24 .04 3.055 1.73483 125 .06 5.30 . g) The t-ratio was -3.48 and the outline says that for a regression involving 3 variables, rY23.12 t 22 3.48 2 0.50229 3.48 2 12 t 32 t 32 df . so rY 1.2 0.50229 .7079 . This is an t 22 df indicator of the additional explanatory power of this variable. Similarly here rY21.2 17 252x0541 4/22/05 2. Do the following using Exhibit 1. a) Compute the (Pearson’s) sample correlation between output and time and test it for significance. (5) b) Test the hypothesis that the population correlation 0.8 . (5) c) Do Spearman’s rank correlation between output and time and test it for significance. Why is the rank correlation higher than Pearson’s? (6) [16, 31] XY nXY X nX Y a) r 2 X 2 2 nY So r Y 2 nY 2 SST SSY 734.556, X Y nX Y SX1Y 430.550. nX 12 SSX1 280 and 2 1 We were given 2 1 1 430 .550 2 .9013 .9494 . According to the outline the test for significance is H 0 : xy 0 734 .556 280 r against H1 : xy 0 t n 2 sr r 1 r n2 2 .9013 1 .9494 13 .9013 .003892 .9013 14 .338 . Since this is .0623859 13 larger than t n2 t .025 2.179 , we reject the null hypothesis and say that the correlation is significant. 2 b) According to the outline “If we are testing H 0 : xy 0 against H 1 : xy 0 , and 0 0 , the test is 1 1 r z ln quite different. We need to use Fisher's z-transformation. Let ~ . This has an approximate 2 1 r ~ n 2 z z 1 1 1 0 and a standard deviation of s z t mean of z ln , so that . n3 sz 2 1 0 (Note: To get ln , the natural log, compute the log to the base 10 and divide by .434294482. )” 1 1 r 1 1.9494 1 1 ~ z ln ln ln 38 .5257 1.58575 0.7929 2 1 r 2 0.0506 2 2 1 1 0 0 0.8 so z ln 2 1 0 1 1.8 1 1 ln 2 0.2 2 ln 9.00 2 0.95424 0.4771 ~ n 2 z z 0.7929 0.4771 1 1 sz 0.288675 and t 1.0940 . Since this is not larger n3 12 sz 0.288675 than t n2 t 13 2.179 , we do not reject the null hypothesis and say that the correlation is not .025 2 significantly different from 0.8. c) The data appears below with ranks. Row Y rY T rT T 2 d d 2 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 53.43 59.09 59.58 64.75 68.65 65.53 68.44 70.93 72.85 73.60 72.93 75.14 73.88 76.55 79.05 1 2 3 4 7 5 6 9 8 11 10 13 12 14 15 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1 4 9 16 25 36 49 64 81 100 121 144 169 196 225 0 0 0 0 0 0 0 0 2 4 -1 1 -1 1 0 0 0 0 1 1 -1 1 1 1 -1 1 0 0 0 0 0 10 d 1 610 1 60 1 0.017 .9821 . 1 15225 `1 3360 nn 1 2 6 rs 2 According to the Table 13, the 5% critical value is .4429, so we can reject the null hypothesis that there is no rank correlation. The rank correlation is larger than the Pearson correlation because the relationship, though basically monotonic ( x rises when y rises) it has some curvature rather than being a straight line. 18 252x0541 4/22/05 3. (Berenson et. al.) The operations manager of a light bulb factory wants to determine if there is any difference between the average life expectancy of a light bulb manufactured by two different machines. A random sample of 25 light bulbs from machine 1 has a sample mean of 375 hours. A random sample of 25 light bulbs from machine 2 has a sample mean of 362 hours. a) Test whether the mean lives of the bulbs differ at the 5% significance level. Assume that 110 is the population standard deviation for machine 1 and that 125 is the population standard deviation for machine 2. Do not use a confidence interval. State your null hypothesis! (4) b) Find a p-value for the null hypothesis in part a) and interpret it. Do not use the t-table. (3) c) Test whether the mean lives of the bulbs differ at the 5% significance level. Assume that 110 is the sample standard deviation for machine 1 and that 125 is the sample standard deviation for machine 2. Do not use a confidence interval. State your null hypothesis! Make and state an assumption about the equality of the two standard deviations. (3 or 5) d) Test the assumption about the standard deviations that you made in c). State your null hypothesis! (2) e) Make the following confidence intervals. (i) A confidence interval for the difference between the means in a). (1) (ii) A confidence interval for the difference between the means in c) (2) (iii) A confidence interval for the ratio of the population variances in d) (2) [15, 46] Solution: Part of TABLE 3 appears below. Interval for Confidence Hypotheses Test Ratio Critical Value Interval Difference H 0 : D D0 * d cv D0 z d D d z 2 d d D0 z between Two H : D D , 1 0 d Means ( 12 22 D 1 2 d known) n n 1 2 d x1 x 2 Difference between Two Means ( unknown, variances assumed equal) Difference between Two Means( unknown, variances assumed unequal) 1 1 n1 n2 DF n1 n2 2 sd s p s12 s22 n1 n2 sd DF s12 s22 n 1 n2 1 , DF2 F1DF 2 1 FDF1 , DF2 2 2 s12 2 n1 s 22 H 1 : D D0 , D 1 2 H 0 : D D0 * D d t 2 s d n1 1 Ratio of Variances H 0 : D D0 * D d t 2 s d 2 n2 n2 1 22 s22 DF1 , DF2 F 12 s12 .5 .5 2 DF1 n1 1 DF2 n 2 1 2 .5 .5 2 or 1 2 H 1 : D D0 , t sˆ 2p t D 1 2 *Same as H 0 : 1 2 d cv D0 t 2 s d d D0 sd n1 1s12 n2 1s22 n1 n2 2 d cv D0 t 2 s d d D0 sd H 1 : 1 2 if D0 0. H0 : 12 22 H1 : 12 22 F DF1 , DF2 s12 s 22 and F DF2 , DF1 s 22 s12 This is Exercise 10.5 in the text, which was assigned. At least some of the language in this solution is quoted. I am assuming that .05 . The following hypothotheses are tested in a) – c). 19 252x0541 4/22/05 Light bulbs produced by machine 1 have the same average life expectance as H 0 : 1 2 those produced by machine 2. H1 : 1 2 Light bulbs produced by machine 1 have a different life expectancy from those produced by machine 2 a) n1 25, x1 375 , and 1 110 , n2 25, x 2 362 , and 2 125 ; d 375 362 13 . d 12 n1 22 n2 110 2 125 2 484 625 1109 33 .307 25 25 Test Ratio: z d D0 d z 2 z.025 1.960 13 0 0.390 . Make a diagram showing a Normal 33 .307 curve with a vertical bar at t 0 . Show one 2.5% rejection zone above z .025 1.960 and a second 2.5% rejection zone below z .025 1.960 . Since 0.390 is not in the rejection zone, do not reject the null hypothesis. Critical Value: d cv D0 z d 0 1.960 33 .307 0 65 .28 . Make a diagram showing a Normal curve with a vertical bar at t 0 . Show one 2.5% rejection zone above 65.28 and a second 2.5% rejection zone below -65.28. Since d 13 is not in the rejection zone, do not reject the null hypothesis. b) c) ` pvalue Pz 0.390 .5 P0 z 0.39 .5 .1517 .3484 n1 25, x1 375 , and s1 110 , n2 25, x 2 362 , and s 2 125 d 375 362 13 . (i) Assume that population variances are equal. n 1s12 n2 1s 22 110 2 125 2 12100 15625 s p2 1 13862 .5 and n1 n 2 2 2 2 1 1 s d s p2 n1 n 2 2 13862 .5 1109 33 .3016 25 Test Ratio: t df n1 n 2 2 48 t.48 025 2.011 d D0 13 0 0.390 Make a diagram showing an almostsd 33 .3016 Normal curve with a vertical bar at t 0 . Show one 2.5% rejection zone above 48 t.48 025 2.011 and a second 2.5% rejection zone below t .025 2.011. Since 0.390 is not in the rejection zone, do not reject the null hypothesis. Critical Value: d cv D0 t 2 s d 0 2.01133 .3016 0 66 .97 Make a diagram showing a Normal curve with a vertical bar at t 0 . Show one 2.5% rejection zone above 66.97 and a second 2.5% rejection zone below 66.97. Since d 13 is not in the rejection zone, do not reject the null hypothesis. (ii) Do not assume that population variances are equal. sd s12 s 22 110 2 125 2 484 625 1109 33 .307 n1 n 2 25 25 20 252x0541 4/22/05 s2 s2 2 1 2 n1 n 2 df 2 2 s2 s 22 1 n2 n1 n2 1 n1 1 1109 2 1229881 2 2 625 9760 .6667 16276 .0417 484 24 24 1229881 34 .1286 36036 .7084 Test Ratio: t t.34 025 2.032 d D0 13 0 0.390 sd 33 .307 Critical Value: d cv D0 t 2 sd 0 2.032 33 .307 0 67 .70 Writeups and conclusions are essentially the same as for equal variances. H1 : 12 22 n1 25, x1 375 , and s1 110 , n2 25, x 2 362 , and d) H0 : 12 22 s 2 125 d 375 362 13 . To test equality of variances, test the ratios . The larger of the two ratios is 2 s 22 125 25, 25 1.29 . Compare this with F.025 , which is between 2.30 and 2.24. Since the computed F is 2 s1 110 less than the table F do not reject the null hypothesis. e) (i) From Table 3 D d z 2 d . We already know d 13 , d 12 n1 22 n2 110 2 125 2 33 .307 and z 2 z.025 1.960 , so 25 25 D 13 1.960 (33 .307 ) 13 65.28 (ii) D d t 2 s d . We already know d 13 and depending on what we assumed in c), either 1 1 s d s p2 n1 n 2 33 .3016 and t.48 025 2.011 , so D 13 2.01133 .3016 13 66 .97 or s12 s 22 33 .307 and t.34 025 2.032 , so D 13 2.03233.307 13 67.70 . n1 n 2 sd (iii) The version of the interval on table 3 is a bit too consise. From ‘Confidence Intervals and Hypothesis Testing for Variances’ we find the following two possibilities. s 22 22 s 22 ( n1 1, n2 1) s12 12 s12 ( n2 1, n1 1) 1 1 F F or . s12 Fn2 1,n1 1 12 s12 2 s 22 Fn1 1, n2 1 22 s 22 2 2 2 25, 25 is between 2.30 and 2.24, probably about 2.29 and that We know F.025 2 2 s12 110 125 1 . 2913 , so 0.7744 , so we have s12 110 s 22 125 s 22 1.2913 2 2 1 1 22 1.2913 2.29 or 0.7744 12 0.7744 2.29 , which become 2.29 1 2.29 2 0.564 22 12 2.96 or 0.338 12 22 1.77 . 21 252x0541 4/22/05 4. (Berenson et. al.) A student team is investigating the size of the bubbles that can be blown with various brands of bubble gum. The data below is the total diameter in inches of the bubbles and is presented in two different ways. These Exhibits are repeated as a tear-off sheet at the end of the exam with the sums and sums of squares computed for you. Exhibit 2: Size of Bubbles Blocked by Blower Row 1 2 3 4 5 Student Loopy Percival Poopsy Dizzy Booger Brand 1 Brand 2 Brand 3 x1 x 2 x 3 x 4 9.5 4.0 5.5 8.5 4.5 8.5 8.5 7.5 7.5 8.0 11.5 11.0 7.5 7.5 8.0 8.75 9.50 9.25 9.50 9.25 Brand 4 Exhibit 3: Size of Bubbles Blocked by Blower but ranked as four independent random samples. Row 1 2 3 4 5 Student Loopy Percival Poopsy Dizzy Booger x1 r1 8.75 9.50 9.25 9.50 9.25 x 2 13.0 17.0 14.5 17.0 14.5 9.5 4.0 5.5 8.5 4.5 r2 17 1 3 11 2 x 3 8.5 8.5 7.5 7.5 8.0 r3 11.0 11.0 5.5 5.5 8.5 x 4 11.5 11.0 7.5 7.5 8.0 r4 20.0 19.0 5.5 5.5 8.5 Compare the data in 3 different ways. a) Do only one of the following. (i) Consider the data random samples from Normally distributed populations and compare means. (6) (ii) Consider the data blocked data from Normally distributed populations and compare means. (8) b) Consider the data random samples from non-Normally distributed populations and compare medians. (5) c) Consider the data blocked data from non-Normally distributed populations and compare medians. (5) a) Do only one of the following. (i) Consider the data random samples from Normally distributed populations and compare means. (6) (ii) Consider the data blocked data from Normally distributed populations and compare means. (8) You were given the column sums and sums of squares. x x 1 46.25, 3 40, x x 2 1 428.188, 2 3 321, x x You were also given the row sums and sums of squares. 1 3 5 x x x 1 38.25 3 29.75 5 29.75 x x x 2 1 371.313 2 3 228.313 4 2 5 233.813 2 x 4 2 32, 4 45.5, x 2 33.00 x x 33.00 x 2 4 2 2 229, 2 4 429.75 x 2 2 299.500 275.000 22 252x0541 4/22/05 Notice that the first 4 columns of my tableau would be the same whether you were doing 1-way or 2-way ANOVA. ‘SS’ stands for sum of squares. Brand 1 Block x1 1 2 3 4 5 Sum 8.750 9.500 9.250 9.500 9.250 46.250 Brand 2 Brand 3 Brand 4 x 2 x 3 x 4 9.50 4.00 5.50 8.50 4.50 +32.00 8.5 8.5 7.5 7.5 8.0 +40.0 Sum x i.. ni 11.50 38.25 4 11.00 33.00 4 7.50 29.75 4 7.50 33.00 4 8.00 29.75 4 +45.50 = 163.75 20 9.5625 8.2500 7.4375 8.2500 7.4375 8.1875 = 20.00 n nj 5 +5 +5 +5 x j 9.250 6.40 8.0 9.10 x x 2j 85.563 +40.96 +64.0 Note that x is not a sum, but is x SSC n SST 2 ij +82.81 x . 371.31 299.50 228.31 275.00 233.81 1407.94 x 91.441 68.063 55.316 68.063 55.316 338.199 2 ij x 2 i 8.19 x This is not a sum. x 273.33 x 428.188 +229.00 +321.0 +429.75 = 1407.94 SS x i2. SS x i. = 2 ij 2 j n n x 1407 .938 20 8.1875 2 1407 .938 1340 .703 67 .235 . 2 n x 5273 .3325 20 8.1875 2 1366 .665 1340 .703 25 .960 . This is SSB in a 2 2 j x j one way ANOVA. SSR n x 2 i i. n x 4338 .199 20 8.1875 2 1352 .796 1340 .703 12 .093 2 ( SSW SST SSC SSR 29.182 ) (ii) 2-way ANOVA (Blocked by student) Source SS DF MS F Rows (Blocks) 12.093 4 3.02325 1.243ns Columns(Brands) 25.960 3 8.65333 3.558s F.05 F 4,12 3.26 F 3,12 3.49 H0 Row means equal Column means equal Within (Error) 29.182 12 2.43183 Total 67.235 19 So the brands (column means) are significantly different although the students are not. (i) One way ANOVA (Not blocked by student) ( SSW SST SSB .0694 ) Source SS DF MS F.01 F Columns(Brands) 25.960 3 8.65333 3.354s F 3,16 3.01 H0 Column means equal Within (Error) 41.275 16 2.57969 Total 67.235 19 Once again, the brands (column means) are significantly different. 23 252x0541 4/22/05 The results in b) and c) were totally cut and pasted from the outline. b) Consider the data random samples from non-Normally distributed populations and compare medians. (5) We repeat Exhibit 3. The x s are the original numbers and the r s are their ranks among the 20 data items. The Kruskal-Wallis Test is equivalent to one-way ANOVA when the underlying distribution is non-normal. The null hypothesis is H 0 : Columns come from same distribution or medians equal. Row Student x1 1 Loopy 8.75 2 Percival 9.50 3 Poopsy 9.25 4 Dizzy 9.50 5 Booger 9.25 Sum of Ranks Size of Column So n1 n 2 n3 n 4 4 , n r1 x 2 r2 x 3 r3 x 4 r4 13.0 17.0 14.5 17.0 14.5 76.0 5 9.5 4.0 5.5 8.5 4.5 17 1 3 11 2 34 5 8.5 8.5 7.5 7.5 8.0 11.0 11.0 5.5 5.5 8.5 41.5 5 11.5 11.0 7.5 7.5 8.0 20.0 19.0 5.5 5.5 8.5 58.5 5 n i 20 , SR1 76 , SR2 34 , SR3 41 .5 and SR4 58 .5 . To check the ranking, note that the sum of the four rank sums is 76 + 34 + 41.5 + 58.5 = 210, and that the nn 1 20 21 210 . sum of the first n 20 numbers is 2 2 12 SRi 2 3n 1 Now, compute the Kruskal-Wallis statistic H nn 1 i ni 12 76 2 34 2 41 .52 58 .52 321 12 5776 1156 1722 .25 3422 .25 63 5 5 5 5 420 20 21 5 12 12076 .5 63 69 .0086 63 6.0086 . The Kruskal-Wallis table (Table 9) does not have values for 2100 tests with 4 columns, so we must use the 2 distribution, with df m 1 , where m is the number of columns. Since there are m 4 columns and .05 , test H with .2053 7.8147 . Since H is larger than .205 , reject the null hypothesis of equal medians. 24 252x0541 4/22/05 c) Consider the data blocked data from non-Normally distributed populations and compare medians. (5) We repeat Exhibit 3 somewhat changed. The x s are the original numbers and the r s are their ranks within the rows of 4. The Friedman Test is equivalent to two-way ANOVA with one observation per cell when the underlying distribution is non-normal. The null hypothesis is H 0 : Columns come from same distribution or medians equal. Note that the only difference between this and the Kruskal-Wallis test is that the data is cross-classified in the Friedman test. [24, 70] Row Student x1 r1 x 2 r2 x 3 r3 x 4 r4 1 Loopy 8.75 2 Percival 9.50 3 Poopsy 9.25 4 Dizzy 9.50 5 Booger 9.25 Sum of Ranks Size of Column 2.0 3.0 4.0 4.0 4.0 17.0 5 9.5 4.0 5.5 8.5 4.5 3.0 1.0 1.0 3.0 1.0 9.0 5 8.5 8.5 7.5 7.5 8.0 1.0 2.0 2.5 1.5 2.5 9.5 5 11.5 11.0 7.5 7.5 8.0 4.0 4.0 2.5 1.5 2.5 14.5 5 Assume that .05 . In the data above, the methods are represented by c 4 columns, and the groups by r 5 rows.. In each row the numbers are ranked from 1 to c 4 . For each column, compute SRi , the rank sum of column i . To check the ranking, note that the sum of the four rank sums is 17 + 9 + 9.5 + 14.5 = 50, cc 1 and that the sum of the c numbers in a row is . However, there are r rows, so we must multiply 2 rcc 1 545 SRi 50 . the expression by r . So we have 2 2 12 SRi2 3r c 1 Now compute the Friedman statistic F2 rc c 1 i 12 17 2 92 9.52 14 .52 355 12 289 81 90 .25 210 .25 75 80 .46 75 5.46 100 545 Since the size of the problem is larger than those shown in Table 10, we use the 2 distribution, with df c 1 4 1 3 , where c is the number of columns. We compare F2 5.46 with .2053 7.8147 . Since F2 is not larger than .205 , do not reject the null hypothesis of equal medians. The results in b) and c) seem to indicate the greater power of ANOVA than the non-parametric methods when the assumptions are appropriate. [24, 70] 25 252x0541 4/22/05 5. (Berenson et. al.) The time it takes to design and launch a marketing campaign is called a cycle time. Marketing campaigns are classified by cycle time (in months) and effectiveness. Don’t even think of answering any part of this question without doing a statistical test! Effectiveness D u r a t i o n < 1 mo. 1-2 mo. 2-4 mo. >4 mo. Total Very Effective 15 28 24 6 73 Effective 9 26 33 19 87 Ineffective 5 2 3 5 15 Total 29 56 60 30 175 a. Test to see if the proportion in the various effectiveness categories is related to cycle time. (8) b. Of the campaigns that took 0 – 2 months 7 were ineffective. Of the campaigns that took more than two months, 8 were ineffective. Is the fraction that were ineffective in the first category below the fraction in the second category? (5) c. Test the hypothesis that 45% of campaigns are very effective. (4) d. As you know a Jorcillator has two components, a Phillinx and a Flubberall. We recorded the order in which they were replaced over the last year to see if there was a pattern or the replacement sequence was just random. We got PPPFFFPPPFFPPFFPPFFF. Test it! (3) e. (Anderson et. al.) The number of emergency calls our Fire department receives is believed to have a Poisson distribution with a parameter of 3. Test this against data for a period of 120 days: 0 calls on 9 days, 1 call on 12 days, 2 calls on 30 days, 3 calls on 27 days, 4 calls on 22 days. 5 calls on 13 days and 7 calls on 6 days. (5) [25, 95] 5. (Berenson et. al.) The time it takes to design and launch a marketing campaign is called a cycle time. Marketing campaigns are classified by cycle time (in months) and effectiveness. Don’t even think of answering any part of this question without doing a statistical test! Effectiveness D u r a t i o n < 1 mo. 1-2 mo. 2-4 mo. >4 mo. Total Very Effective 15 28 24 6 73 Effective 9 26 33 19 87 Ineffective 5 2 3 5 15 Total 29 56 60 30 175 a. Test to see if the proportion in the various effectiveness categories is related to cycle time. (8) b. Of the campaigns that took 0 – 2 months 7 were ineffective. Of the campaigns that took more than two months, 8 were ineffective. Is the fraction that were ineffective in the first category below the fraction in the second category? (5) c. Test the hypothesis that 45% of campaigns are very effective. (4) d. As you know a Jorcillator has two components, a Phillinx and a Flubberall. We recorded the order in which they were replaced over the last year to see if there was a pattern or the replacement sequence was just random. We got PPPFFFPPPFFPPFFPPFFF. Test it! (3) e. (Anderson et. al.) The number of emergency calls our Fire department receives is believed to have a Poisson distribution with a parameter of 3. Test this against data for a period of 120 days: 0 calls on 9 days, 1 call on 12 days, 2 calls on 30 days, 3 calls on 27 days, 4 calls on 22 days. 5 calls on 13 days and 7 calls on 6 days. (5) a) Test to see if the proportion in the various effectiveness categories is related to cycle time. (8) . The observed data is indicated by O, the expected data by E . H 0 : Mktg Campaigns are Homogeneous by duration. The original numbers are rewritten to show p r , the proportion in each row and labeled O for observed. O Columns 1 2 3 4 Total Row 1 Row 2 Row 3 15 9 5 28 26 2 24 33 3 6 19 5 73 87 15 29 56 60 30 Total pr .417143 .497143 .085714 175 26 252x0541 4/22/05 p c represents the proportion in each column. n O 175 . There are r 3 rows, c 4 columns and rc 12 cells. Each cell gets p c p r n p c (Column total) . For example, the proportion in Column 1 is 29 175 .165714 . So for the upper left corner the expected value is 29 73 175 175175 .165714 .417143 175 12 .0971 . This was rounded to 12.10. the results are E . E Columns Row 1 Row 2 Row 3 Total 1 2 3 4 Total 12.10 23.36 25.03 14.42 27.84 29.83 2.49 4.80 5.14 12.51 14.91 2.57 29.01 56.00 60.00 28.99 The formula for the chi-squared statistic is 2 O E 2 73 87 15 175 or 2 E formulas is shown in the table below, though only one should be used. Row O 1 2 3 4 5 6 7 8 9 10 11 12 2 So calc E O E 15 12.10 9 14.42 5 2.49 28 23.36 26 27.84 2 4.80 24 25.03 33 29.83 3 5.14 6 12.51 19 14.91 5 2.57 175 175.00 O E 2 E -2.90 5.42 -2.51 -4.64 1.84 2.80 1.03 -3.17 2.14 6.51 -4.09 -2.43 0.00 2 E O2 E O 8.4100 29.3764 6.3001 21.5296 3.3856 7.8400 1.0609 10.0489 4.5796 42.3801 16.7281 5.9049 2 16.01646 or calc E pr .417143 .497143 .085714 O2 n . Both of these two E O2 E 0.69504 18.5950 2.03720 5.6172 2.53016 10.0402 0.92164 33.5616 0.12161 24.2816 1.63333 0.8333 0.04239 23.0124 0.33687 36.5069 0.89097 1.7510 3.38770 2.8777 1.12194 24.2119 2.29763 9.7276 16.01646 191.0165 O2 n 191 .0165 175 16.0165 . E The degrees of freedom for this application are r 1c 1 3 14 1 23 6 . 2 If our significance level is 5%, compare calc to .2056 12 .5916 . Since our value of our computed sum is greater than the table chi-squared, reject the null hypothesis. b) Of the (29 + 56 = 65) campaigns that took 0 – 2 months 7 were ineffective. Of the (60 + 30 = 90) campaigns that took more than two months, 8 were ineffective. Is the fraction that were ineffective in the first category below the fraction in the second category? (5) (It should have been above!) If p1 is the proportion of successes in the first sample, and p2 is the proportion of successes in the second sample, we define p p1 p 2 . Then our hypotheses will be H 0 : p1 p 2 or H 0 : p p 0 0 H 1 : p1 p 2 Let p1 H 1 : p p 0 0 . x1 7 x 8 .088889 and p p1 p2 .0188030 where x1 is the number .107692 , p2 2 n2 90 n1 65 of successes in the first sample, x 2 is the number of successes in the second sample, n1 and n 2 are the sample sizes and q 1 p . The usual three approaches to testing the hypotheses can be used. 27 252x0541 4/22/05 p1 p2 p1 p2 z s p , where .107692 .892308 .088889 .911111 .00147838 .00089986 Confidence Interval: p p z s p or 2 s p p1 q1 p 2 q 2 n1 n2 65 2 90 The one sided interval is p p z s p .0188 1.645.0487 .0989 . Compare this interval with p 0 0 . Since p .0989 does not contradict p 0 do not reject H 0 . p p 0 .0188030 0.3907 where Test Ratio: z p .0481245 1 1 1 1 .0967742 .903226 .0481245 and n n 65 90 2 1 n p n 2 p 2 x1 x 2 78 p0 1 1 .0967742 . Because our alternate hypothesis is n1 n 2 n1 n 2 65 90 p p 0 q 0 p 0 , this is a left-sided test and the rejection zone is below z .05 1.645 . Since the test ratio is not in that interval, do not reject H 0 . Critical Value: pCV p0 z p becomes pCV p0 z p 2 0 1.645 .04812 0.0792 and the rejection zone is below -0.0792. If we test this against p p1 p2 .0188030 , we cannot reject H 0 . For calculation of p , see Test Ratio above. c) Test the hypothesis that 45% of campaigns are very effective. (4) Out of 175 campaigns, 73 were very effective. To test H 0 : p p 0 against H1 : p p0 . Here p 0 .45 and p x 73 .417143 . n 175 (i) Test Ratio: z p p0 p .417143 .45 0.874 where .03761 p0 q0 .45.55 .00141 .03761 . Make a diagram with a mean at zero and n 175 rejection zones below z .025 1.960 and z .025 1.960 . Since z 0.874 falls between these numbers, do not reject H 0 . p (ii) Critical Value: pcv p0 z p .45 1.960.03761 .45 .074 . The rejection 2 regions are below .376 and above .524. Since p x 73 .417 falls between these n 175 numbers, do not reject H 0 . (iii) Confidence Interval: p p z 2 s p .4171 1.960 .03727 .4171 .073 pq .417143 .582857 n 175 includes p 0 .45 . sp .001389 .03727 . The confidence interval 28 .00237824 .04 252x0541 4/22/05 d) As you know a Jorcillator has two components, a Phillinx and a Flubberall. We recorded the order in which they were replaced over the last year to see if there was a pattern or the replacement sequence was just random. We got PPPFFFPPPFFPPFFPPFFF. Test it! (3) To test the null hypothesis of randomness for a small sample, assume that the significance level is 5% and use the table entitled 'Critical values of r in the Runs Test.’ n 20 , n1 10 , n 2 10, and r 8. For n1 10 and n2 10 , the table gives a critical values of 6 and 16. This means that we reject the null hypothesis if r 6 or r 16 . In this case, since r 8 we do not reject the null hypothesis. e) (Anderson et. al.) The number of emergency calls our Fire department receives is believed to have a Poisson distribution with a parameter of 3. Test this against data for a period of 120 days: 0 calls on 9 days, 1 call on 12 days, 2 calls on 30 days, 3 calls on 27 days, 4 calls on 22 days. 5 calls on 13 days and 7 calls on 6 days. (5) No matter how we do this, we need a Poisson table with a parameter of 3. This is copied from the syllabus supplement. The E fn column comes from multiplying the f column by n 120 . Row 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 k 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 f P(x=k) Fe P(xk) E fn 0.049787 0.149361 0.224042 0.224042 0.168031 0.100819 0.050409 0.021604 0.008102 0.002701 0.000810 0.000221 0.000055 0.000013 0.000003 0.000001 0.000000 0.000000 0.04979 0.19915 0.42319 0.64723 0.81526 0.91608 0.96649 0.98810 0.99620 0.99890 0.99971 0.99993 0.99998 1.00000 1.00000 1.00000 1.00000 1.00000 5.9744 17.9233 26.8850 26.8850 20.1637 12.0983 6.0491 2.5925 0.9722 0.3241 0.0972 0.0265 0.0066 0.0016 0.0004 0.0001 0.0000 0.0000 Most of the E column contains values that are below 5, so for a chi-square procedure, they need to be added up, especially since the observed data only goes up to k 7. The chi-square procedure follows. Our null hypothesis is H 0 : Poisson6 row 1 2 3 4 5 6 7 O E O E 9 5.9744 12 17.9233 30 26.8850 27 26.8850 22 20.1637 13 12.0983 7 10.0704 120 120.000 O E 2 -3.02556 5.92332 -3.11496 -0.11496 -1.83628 -0.90172 3.07040 0.00024 2 E O2 E O 9.1540 35.0857 9.7030 0.0132 3.3719 0.8131 9.4274 E O2 E 1.53220 13.5578 1.95755 8.0342 0.36091 33.4759 0.00049 27.1155 0.16723 24.0035 0.06721 13.9689 0.93615 4.8657 5.02174 125.0215 O2 n 125 .0215 120 5.0215 . In this case we have 6 E E degrees of freedom and .2056 12 .5916 . Since our computed value is less than the table value, we cannot 2 So calc 2 5.0274 or calc reject the null hypothesis. 29 252x0541 4/22/05 This problem can also be done by a Kolmogorov-Smirnov procedure. O Row O Fo Fe P(xk) D Fe Fo n 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 9 12 30 27 22 13 7 0.075000 0.100000 0.250000 0.225000 0.183333 0.108333 0.058333 0.07500 0.17500 0.42500 0.65000 0.83333 0.94167 1.00000 1.00000 1.00000 1.00000 1.00000 1.00000 1.00000 1.00000 1.00000 1.00000 1.00000 1.00000 0.04979 0.19915 0.42319 0.64723 0.81526 0.91608 0.96649 0.98810 0.99620 0.99890 0.99971 0.99993 0.99998 1.00000 1.00000 1.00000 1.00000 1.00000 0.0252100 0.0241500 0.0018100 0.0027700 0.0180733 0.0255867 0.0335100 0.0119000 0.0038000 0.0011000 0.0002900 0.0000700 0.0000200 0.0000000 0.0000000 0.0000000 0.0000000 0.0000000 0.1242 . Since all the values in the D column are below the table 120 value, we cannot reject the null hypothesis. The 5% critical value is 1.36 30 252x0541 4/22/05 6. Test to see if the price of new homes rose between 2001 and 2002. The following data represents a random sample of typical prices in thousands in 10 zip codes in 2001 and 2002. Row Location 2001 2002 x1 1 2 3 4 5 6 7 8 9 10 Alexandria Boston Decatur Kirkland New York Philadelphia Phoenix Raleigh San Bruno Tampa 245.795 391.750 205.270 326.524 545.363 185.736 170.413 210.015 385.387 194.205 293.266 408.803 227.561 333.569 531.098 197.874 175.030 196.094 391.409 199.858 Some of the following data may be of use to you. x 2860.458, d -94.104, 1 x d 2 1 2 change d x1 x 2 x2 953941.216, x -47.471 -17.053 -22.291 -7.045 14.265 -12.138 -4.617 13.921 -6.022 -5.653 x 2954.562, 2 2 2 999628.915, 3724.975 If you want to receive full credit, you must clearly label each section that you do! a) Remember that the data is cross classified. Assume that the underlying distribution is not Normal and compare medians. (5) b) Remember that the data is cross classified. Assume that the underlying distribution is Normal and compare means. (4) c) Forget that the data is cross classified. Assume instead that it represents two random samples from Chester County, one for each year and that the underlying distribution is not Normal. Compare medians. (6) [15, 110] Solution: a) Remember that the data is cross classified. Assume that the underlying distribution is not Normal and compare medians. (5) The Wilcoxon Signed Rank Test for Paired Samples is a test for equality of medians when the data is paired. It can also be used for the median of a single sample. The Sign Test for paired data is a simpler test to use in this situation, but it is less powerful. As in many tests for measures of central tendency with paired data, the original numbers are discarded, and the differences between the pairs are used. If there are n pairs, these are ranked according to absolute value from 1 to n , either top to bottom or bottom to top. After replacing tied absolute values with their average rank, each rank is marked with a + or – sign and two rank sums are taken, T and T . The smaller of these is compared with Table 7. Row Location 2001 x1 1 2 3 4 5 6 7 8 9 10 Alexandria Boston Decatur Kirkland New York Philadephia Phoenix Raleigh San Bruno Tampa 245.795 391.750 205.270 326.524 545.363 185.736 170.413 210.015 385.387 194.205 2002 difference x2 293.266 408.803 227.561 333.569 531.098 197.874 175.030 196.094 391.409 199.858 rank signed rank d x 2 x1 d r -47.471 -17.053 -22.291 -7.045 14.265 -12.138 -4.617 13.921 -6.022 -5.653 47.471 17.053 22.291 7.045 14.265 12.138 4.617 13.921 6.022 5.653 10 8 9 4 7 5 1 6 3 2 r* -10 -8 -9 -4 7 -5 -1 6 -3 -2 . H 0 : 1 2 n 10 and .05 . If we add together the numbers in r * with a + sign we get . T 13 . H 1 : 1 2 If we do the same for numbers with a – sign, we get T 42 To check this, note that these two numbers nn 1 10 11 55 , and that must sum to the sum of the first n numbers, and that this is 2 2 T T 13 42 55 . 31 252x0541 4/22/05 We check 13, the smaller of the two rank sums against the numbers in table 7. For a one-sided 5% test, we use the .05 column. For n 10 , the critical value is 11, and we reject the null hypothesis only if our test statistic is below this critical value. Since our test statistic is 13, we do not reject the null hypothesis. b) Remember that the data is cross classified. Assume that the underlying distribution is Normal and compare means. (4) Interval for Confidence Hypotheses Test Ratio Critical Value Interval Difference H 0 : D D0 * D d t 2 s d d cv D0 t 2 s d d D0 t between Two H 1 : D D0 , s d d x1 x 2 Means (paired D 1 2 s data.) df n 1 where sd d n1 n 2 n n H 0 : D D0 0 , H1 : D D0 0 where D 1 2 . We were given d s d2 sd 2 3724.975. d d 2 nd 2 n 1 sd n d -94.104, 94 .104 9.4104 . Recall that 10 3724 .975 10 9.4104 2 315 .4910 so that s d 315 .4910 17 .7621 9 315 .4910 31 .54910 5.6169 df n 1 9 t.905 1.833 10 Test Ratio: t d D0 9.4104 1.675 . Since this is a left-sided test, we reject the null sd 5.6169 hypothesis if t calc is below -1.833. Since t calc is not below the critical value, we cannot reject the null hypothesis. Critical Value: d cv D0 t 2 s d becomes d cv D0 t s d 1.833 5.6169 10 .296 . The rejection region lies below -10.296. Since d 9.4104 is not below the critical value, we cannot reject the null hypothesis. Confidence Interval: D d t 2 s d becomes D d t s d 9.4104 1.833 5.6169 0.8856 . This does not contradict H 0 : D 0 , so we cannot reject the null hypothesis. 32 252x0541 4/22/05 c) Forget that the data is cross classified. Assume instead that it represents two random samples from Chester County, one for each year and that the underlying distribution is not Normal. Compare medians. (6) The Wilcoxon-Mann-Whitney Test for Two Independent Samples is used if samples are independent. This test is appropriate to test whether the two samples come from the same distribution. If the distributions are similar, it is often called a test of equality of medians. H : 2 If we use for the median, our hypotheses are 0 1 and .05 . n1 n 2 10 . H 1 : 1 2 Row 1 2 3 4 5 6 7 8 9 10 Location Alexandria Boston Decatur Kirkland New York Philadephia Phoenix Raleigh San Bruno Tampa 2001 rank x1 r1 245.795 391.750 205.270 326.524 545.363 185.736 170.413 210.015 385.387 194.205 11 17 8 13 20 3 1 9 15 4 101 2002 x2 293.266 408.803 227.561 333.569 531.098 197.874 175.030 196.094 391.409 199.858 rank r2 12 18 10 14 19 6 2 5 16 7 109 Now compute the sums of the ranks. SR1 101, SR2 109 . As a check, note that these two rank sums must add to the sum of the first n numbers, and that this is nn 1 20 21 210 , and that 2 2 SR1 SR2 101 109 210 . This can be compared against the critical values for TL and TU ( TU is actually only needed for a 2-sided test) in table 14b. These are 83 and 127. Since W 109 is between these values, we cannot reject the null hypothesis. [15, 110] 33 252x0541 4/22/05 ECO252 QBA2 Final EXAM May 2-6, 2005 TAKE HOME SECTION Name: _________________________ Student Number: _________________________ Class days and time : _________________________ 1) Please Note: computer problems 2,3 and 4 should be turned in with the exam (2). In problem 2, the 2 way ANOVA table should be checked. The three F tests should be done with a 5% significance level and you should note whether there was (i) a significant difference between drivers, (ii) a significant difference between cars and (iii) significant interaction. In problem 3, you should show on your third graph where the regression line is. Check what your text says about normal probability plots and analyze the plot you did. Explain the results of the t and F tests using a 5% significance level. (2) 2) 4th computer problem (4+) This is an internet project. You are trying to answer the question, ‘how well does manufacturing explain differences in income?’ You should use some measure of income per person or family in each state as your dependent variable and try to explain it as a function of (to start with) percent of output or labor force in manufacturing. This should start out as a simple regression. Then you should try to see whether there are other variables that explain the differences as well. One possibility is the per cent of the adult population with college or high school diplomas. Possible sources of data are below, but think about what you use, and try to find some other sources. Total income of a state, for example is a very poor choice, rather than some per capita measure because it is simply going to be high for places with a lot of people without indicating how well off they are. Similarly the fraction of the workforce with a certain education level is far better then the number. For instructions on how to do a regression, try the material in Doing a Regression. http://www.nam.org/s_nam/sec.asp?CID=5&DID=3 Manufacturing share in state economies (http://www.nam.org/Docs/IEA/26767_20002001ManufacturingShareandChangeinStateEconomies.pdf?DocTypeID=9&TrackID=&Param=@CategoryI D=1156@TPT=2002-2001+Manufacturing+Share+and+Change+in+State+Economics) http://www.nemw.org/data.htm Per capita income by state. http://www.nemw.org/data.htm State personal income per capita. http://www.bea.doc.gov/bea/regional/data.htm Personal income per capita by state. http://www.census.gov/statab/www/ Many state statistics, including persons with bachelor’s degrees. http://www.epinet.org/content.cfm/datazone_index Income inequality, median income, unemployment rates. Anyway, your job is to add whatever variable you think ought to explain your income measure. Consider all 50 states your sample. Your report should tell what numbers you used, from where and from what years. What coefficients were significant and do you think on the basis of your results that manufacturing is an important predictor of a state’s prosperity? Mark all significant F and t coefficients using a 5% significance level. Explain VIFs. Of course, if you don’t like this assignment, get approval to research something else on the internet. For example, does the per cent of the population in prison affect the crime rate (maybe with a few years’ lag)? Or are there better predictors? And get out the Durbin-Watson, prison vs. crime rate is a time series project. [8] 3) Hotshot Associates is afraid of sex discrimination charges and collects the data below. The dependent variable is income in thousands of dollars and the two independent variables are education in years and a dummy variable indicating sex (1 means a female). The lines in the middle are missing because the totals 34 252x0541 4/22/05 are reliable and you don’t need them. The only thing that is missing is you. Add yourself to the sample as a 21st observation with 12 years of education and an income of 100.0 (thousand) plus the last two digits of your student number as hundreds. For example Roland Dough’s student number is 123689, so he adds $8900 to $100000 to get 108900, which he records as 108.9. y Row 1 2 3 4 5 INC 39.0 43.7 62.6 42.8 55.0 17 72.9 18 56.1 19 67.1 20 82.3 1168.5 x1 x2 x12 x 22 EDUC 2 4 8 8 8 SEX 0 1 0 1 0 4 16 64 64 64 0 1 0 1 0 16 16 17 21 241 0 1 0 0 7 256 256 289 441 3285 a. Compute the regression equation y2 x1 y 1521.00 1909.69 3918.76 1831.84 3025.00 x2 y 0.0 43.7 0.0 42.8 0.0 0 4 0 8 0 0 5314.41 1166.4 0.0 1 3147.21 897.6 56.1 0 4502.41 1140.7 0.0 0 6773.29 1728.3 0.0 7 70091.67 14783.9 370.6 0 16 0 0 81 Yˆ b0 b1 x1 78.0 174.8 500.8 342.4 440.0 x1 x 2 to predict salaries the basis of education only. (2) 2 b. Compute R . (2) c. Compute s e . (2) d. Compute s b1 and do a significance test on e. Compute s b0 and do a confidence interval for b1 (1.5) b0 (1.5) f. You are about to hire your nephew for the summer and want to know how much to pay him He has 14 years of education. Using this create a prediction interval his salary. Explain why a confidence interval for the price is inappropriate. (3) g. Do an ANOVA table for the regression. What conclusion can you draw from the hypothesis test in the ANOVA? (2) [22] Extra credit from here on. h. Do a multiple regression of price against education and sex. (5) i. Compute R-squared and R-squared adjusted for degrees of freedom for this regression and compare them with the values for the previous problem. (2) j. Using either R – squares or SST, SSR and SSE do F tests (ANOVA). First check the usefulness of the simple regression and then the value of ‘sex’ as an improvement to the regression. How should this impact Hotshot Associates’ discrimination problem? (Don’t say a word without referring to a statistical test.) (3) k. Predict what you will pay your nephew now. How much change is there from your last prediction? (2) Solution: a. Compute the regression equation Yˆ b0 b1 x1 to predict salaries the basis of education only. (2) Here is the modified data. I seem to think that Roland is a woman. Row 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 INC 39.0 43.7 62.6 42.8 55.0 60.6 59.4 57.1 56.5 53.5 55.7 58.8 64.1 58.8 62.5 60.0 72.9 56.1 67.1 82.3 108.9 1277.4 Solution: a) n 21, EDUC 2 4 8 8 8 10 12 12 12 12 12 13 14 14 15 15 16 16 17 21 12 253 SEX 0 1 0 1 0 0 0 0 0 1 1 0 0 1 0 1 0 1 0 0 1 8 x1sq 4 16 64 64 64 100 144 144 144 144 144 169 196 196 225 225 256 256 289 441 144 3429 y 1277.4, x 1 x2sq 0 1 0 1 0 0 0 0 0 1 1 0 0 1 0 1 0 1 0 0 1 8 253, ysq x1y 1521.0 78.0 1909.7 174.8 3918.8 500.8 1831.8 342.4 3025.0 440.0 3672.4 606.0 3528.4 712.8 3260.4 685.2 3192.3 678.0 2862.3 642.0 3102.5 668.4 3457.4 764.4 4108.8 897.4 3457.4 823.2 3906.3 937.5 3600.0 900.0 5314.4 1166.4 3147.2 897.6 4502.4 1140.7 6773.3 1728.3 11859.2 1306.8 81950.9 16090.7 x 2 8, x 2 1 x2y 0.0 43.7 0.0 42.8 0.0 0.0 0.0 0.0 0.0 53.5 55.7 0.0 0.0 58.8 0.0 60.0 0.0 56.1 0.0 0.0 108.9 479.5 3429, x x1x2 0 4 0 8 0 0 0 0 0 12 12 0 0 14 0 15 0 16 0 0 12 93 2 2 8, 35 252x0541 4/22/05 y 2 81950.9, x y 116090.7, x 1 479.5, 2y x x 1 2 93. .05 . Note: Spare parts in this section were generated by my Minitab program 252OLS2. This program is available from me if you wish to check your own solution. y 1277 .4 60.8286 , x x First, we compute y and x2 x 2 n n 1 21 1 n 253 12 .0476 ( x in simple regression), 21 8 0.380952 . Then, we compute our spare parts: 21 SST SSy y ny 81950 .9 2160 .8286 2 4248 .46 * 2 2 x y nx y 116090 .7 2112.0476 60.8286 701 .071 ( Sxy in simple regression) Sx y X Y nX Y 479 .5 210.380952 60.8286 7.12857 SSx1 x12 nx12 3429 2112.04762 380.952 * ( SSx in simple regression) SSx2 X 22 nX 22 8 210.3809522 4.95238 * and Sx x X X nX X 93 2112.0476 0.380952 3.38095 . Sx1 y 1 1 2 2 1 2 2 1 2 1 2 Note: * These spare parts must be positive. The rest may well be negative. We conclude that b1 Sxy SSx xy nxy 701 .071 1.8403 x nx 380 .952 2 2 b0 y b1 x 60.8286 1.8403 12.0476 38.6574 So Yˆ b b x becomes Yˆ 38.6574 1.8403 x . 0 1 2 b) Compute R . (2) We already know that SST SSy y 2 ny 81950 .9 2160 .8286 2 4248 .46 , 2 Sxy 701.071 and SSx 380 .952 . XY nXY Sxy 701 .071 .3037 Hey! This stinks. SSy 380 .952 4248 .46 SSx X nX Y nY 2 R 2 2 2 2 2 2 2 c) Compute s e . (2) Recall that b1 1.8403 SSR b1 Sxy b1 xy nxy 1.8413 701 .071 1290 .9 or SSR b1 Sxy R 2 SST .30374248.46 1290.26 SSE SST SSR 4248 .46 1290 .26 2958 .20 or s e2 s e2 SSE 2528 .20 155 .6947 n2 19 2 SST b12 SSx 4248 .46 1.8402 380 .952 2858 .42 155 .7067 19 19 n2 s e 155 .7 12 .4779 So ( s e2 is always positive!) 36 252x0541 4/22/05 d) Compute s b1 and do a significance test on b1 (1.5) Recall n 21 , .05 , SSx 380 .952 , s e2 155.7067 and b1 1.8403 . H 0 : 1 10 For most two-sided tests use t n2 2 t .19 use 025 2.093 . From the outline – “To test H 1 : 1 10 b 10 . Remember 10 is most often zero – and if the null hypothesis is false in that case we t 1 s b1 1 155 .7067 say that 1 is significant.” s b21 s e2 0.4087 and s b 0.4087 0.6393 . So 1 SS x 380 .952 b 1.8403 t 1 10 2.879 . Much to my surprise, this is larger than the table value of t , so we sb1 0.6393 can say that b1 is significant. e) Compute s b0 and do a confidence interval for b0 (1.5) Recall n 21 , SSx 380 .952 , s e2 155.7067 , b0 38 .6574 and x 12.0476 . 1 s b20 s e2 n 2 155 .7067 1 12 .0467 155 .7067 1 0.38095 66 .7308 21 380 .952 X 2 nX 2 21 X2 s b 66 .7308 8.1689 0 b0 t 2 sb0 38.6574 2.0938.1689 38.66 17.09 . 0 Since the error part of the interval is smaller than b0 38 .6574 , we can conclude that the intercept is significant too. f) You are about to hire your nephew for the summer and want to know how much to pay him He has 14 years of education. Using this create a prediction interval his salary. Explain why a confidence interval for the price is inappropriate. (3) Recall that Yˆ 38.6574 1.8403 x , n 21 , SSx 380 .952 , s e2 155.7067 and x 12.0476 . 1 X X 2 From the outline, the Prediction Interval is Y0 Yˆ0 t sY , where sY2 s e2 0 1 . In n SS x ˆ this formula, for some specific X , Yˆ b b X . Here X 14 , Y 38.6574 1.8403 x 0 0 0 1 0 38.6574 1.8403 14 64.4216 , i.e. $64,421.60. Then 1 sY2 s e2 n X 0 X 2 X 2 nX 2 0 1 14 12 .0476 2 1 1 155 .7067 1 155 .7067 .010006 1 21 380 . 952 21 155 .7067 1.0576 164 .6790 and sY 164 .6790 12 .8327 , so that, if t n2 2 t .19 025 2.093 the prediction interval is Y0 Yˆ0 t sY 64.4216 2.093 12.8327 64.3 26.9 . The confidence interval represents a confidence interval for the average value that Y will take when x 14 , while the prediction interval is a confidence interval for an individual value and is thus more appropriate. 37 252x0541 4/22/05 g) Do an ANOVA table for the regression. What conclusion can you draw from the hypothesis test in the ANOVA? (2) Recall that SSR 1290 .26 , SSE 2958 .20 and SST 4248 .46 . [22] We can do a ANOVA table as follows: Source SS DF MS F Regression SSR MSR MSR MSE 1 Error MSE SSE n2 Total SST n 1 Source Regression Error Total 1,19 Note that F.05 SS DF MS F 1290.26 1 1290.26 8.287s 2958.20 19 155.69 4248.46 20 4.38 so we reject the null hypothesis that x and y are unrelated. I have indicated this by an ‘s’ next to the computed F. This is the same as saying that H 0 : 1 0 is false. Extra credit from here on. h) Do a multiple regression of price against education and sex. (5) Here comes the fun! It’s time to repeat the whole spare parts box. SST SSy 4248.46 *, Sx1 y 701 .071 , Sx2 y 7.12857 , SSx1 380 .952 *, SSx2 4.95238 *, and Sx1 x 2 3.38095 . Also y 60.8286 , x1 12.0476 and x 2 0.380952 . Note: * These spare parts must be positive. The rest may well be negative. We substitute these numbers into the Simplified Normal Equations: X 1Y nX 1Y b1 X 12 nX 12 b2 X 1 X 2 nX 1 X 2 X Y nX Y b X X 2 which are 2 1 1 2 nX X b X 1 2 2 2 2 nX , 2 2 701 .071 380 .952 b1 3.38095 b2 7.12857 3.38095 b1 4.95238 b2 and solve them as two equations in two unknowns for b1 and b2 . These are a fairly tough pair of 1.464789 we 3.38095 1026 .97143 558 .01448 b1 4.95238 b2 get 4.95238. The equations become If we add these 7.12857 3.38095 b1 4.95238 b2 1019 .84286 1.83877 . Now together, we get 1019 .84286 554 .63353 b1 . This means that b1 554 .63353 remember that 701 .071 380 .952 b1 3.38095 b2 . This can be rewritten as 3.38095 b2 701 .071 380 .952 b1 . Let’s substitute equations to solve until we notice that, if we multiply 3.38095 by 4.95238 b1 1.83877 . 3.38095 b2 701 .071 380 .952 1.83877 0.58789 . So 0.58789 0.17385 . (It’s worth checking your work by substituting your values of 3.38095 b1 and b2 back into the normal equations.) Finally we get b0 by solving b0 Y b1 X 1 b2 X 2 60.8286 1.83877 12.0476 0.17385 0.380952 60.8286 22 .1528 0.0662 38 .6096 . Thus our equation is Yˆ b b X b X 38.6096 1.8388X 0.1739X . b2 0 1 1 2 2 1 2 38 252x0541 4/22/05 i) Compute R-squared and R-squared adjusted for degrees of freedom for this regression and compare them with the values for the previous problem. (2) Recall SST SSy 4248.46 *, Sx1 y 701 .071 , Sx 2 y 7.12857 , SSx1 380 .952 *, SSx2 4.95238 *, and Sx1 x 2 3.38095 . Also y 60.8286 , x1 12.0476 and x 2 0.380952 and Yˆ 38.6096 1.8388X 1 0.1739X 2 . Also from the previous regression R 2 R12 .3037 . SSE SST SSR * and so SSR b1 Sx1 y b2 Sx2 y 1.8388 701 .071 1.8388 7.12857 1289 .129 13.108 1302 .23 * so SSE 4248 .46 1302 .23 2946 .23 * SSR 1302 .23 R 2 R 22 .3065 *. If we use R 2 , which is R 2 adjusted for degrees of SST 4248 .46 freedom, for the first regression, the number of independent variables was k 1 and R2 n 1R 2 k 20 0.3037 1 .2671 R2 n 1R 2 k 20 0.3064 2 .2293 . n k 1 19 and for the second regression k 2 and This is very bad. R-squared adjusted is supposed to n k 1 18 rise if our new variable has any explanatory power. Note: * These numbers must be positive. The rest may well be negative. j) Using either R – squares or SST, SSR and SSE do F tests (ANOVA). First check the usefulness of the simple regression and then the value of ‘sex’ as an improvement to the regression. How should this impact Hotshot Associates’ discrimination problem? (Don’t say a word without referring to a statistical test.) (3) Recall SST SSy 4248.46 , SSE 2946 .23 and SSR 1302 .23 . The general format for a regression ANOVA table reads: Source SS DF MS Fcalc F k Regression SSR MSR MSR MSE F k , nk 1 n k 1 MSE Error SSE Total SST n 1 The ANOVA table from the first regression reads: Source SS DF MS Regression 1290.26 1 1290.26 Error 2958.20 19 155.69 Total 4248.46 20 The ANOVA table from the second regression reads: Source SS DF MS Fcalc 8.287s Fcalc F.05 1,19 4.38 F.05 F.05 2,18 3.55 F.05 Regression 1302.23 2 651.115 3.978s Error 2946.23 18 163.68 Total 4248.46 20 Since our computed F is larger that the table F, we reject the hypothesis that the Xs and Y are unrelated. If we now divide the effects of the two independent variables, we get: Source SS DF MS Fcalc F.05 Educ 1290.26 1 1,19 4.38 Sex 11.97 1 11.97 0.0876ns F.05 Error 2946.23 18 163.68 Total 4248.46 20 Since our computed F is not larger that the table F, we do not reject the hypothesis that the second independent variable (Sex) and Y are unrelated. But was this because I said Roland was female? If this is correct Hotshot Associates doesn’t have much of a problem. 39 252x0541 4/22/05 k) Predict what you will pay your nephew now. How much change is there from your last prediction? (2) ) Recall SST SSy 4248.46 , SSE 2946 .23 and SSR 1302 .23 . Also Yˆ 38.6096 1.8388X 0.1739X 1 2 Since I forgot to include the rest of the question, which was to make the result into an approximate prediction interval, I’ll do it anyway. We need to find s e . The best way to do this is to do an ANOVA or remember that s e2 SSE 2946 .23 163 .679 . n k 1 21 2 1 18 So s e 163 .679 12 .7937 . For two sided tests and intervals we use t nk 1 t .025 2.101 . 2 Our predicted earnings for a male with 14 years of education is Yˆ 38.6096 1.838814 0.17390 64.3528 s The outline says that an approximate confidence interval is Y0 Yˆ0 t e n 64 .3528 2.10112.7937 64 .36 28.98 and an approximate prediction interval is Y Yˆ t s 64.3528 2.10112.7937 64.4 29.0 . 0 0 e Our previous prediction interval was Y0 Yˆ0 t sY 64.3 26.9 . When you consider the fact that the larger error term wipes out the 0.1% increase in Yˆ , the prediction is essentially the same. 0 40 252x0541 4/22/05 4) An airport authority wants to compare training of air traffic controllers at three locations. Data is on the next page. To personalize these data add the last two digits of your student number as a 9 th number to column C. a. Compare the performance of locations A, B, and C assuming that the underlying distribution is nonNormal. (4) [26] b. Use a one-way ANOVA to test the hypothesis of equal means. (5) It is legitimate to check your results by computer, but I expect to see hand computations every step of the way. [31] c. (Extra Credit) Decide between the methods that you used in a) and b). To do this test for equal variances and for Normality on the computer. What is your decision? Why? (4) You can do most of this with the following commands in Minitab if you put your data in 3 columns of Minitab with A, B, and C above them. MTB > MTB > SUBC> SUBC> MTB > MTB > AOVOneway A B C stack A B C c11; subscripts c12; UseNames. rank c11 c13 vartest c11 c12 #Does a 1-way ANOVA # Stacks the data in c12, col.no. in c12. #Puts the ranks of the stacked data in c13 #Does a bunch of tests, including Levene’s On stacked data in c11 with IDs in c12. MTB > Unstack (c13); SUBC> Subscripts c12; SUBC> After; SUBC> VarNames. #Unstacks the ranks in the next 5 available # columns. Uses IDs in c12. MTB > NormTest 'A'; SUBC> KSTest. #Does a test (apparently Lilliefors)for Normality # on column A. Data for Problem 4 Row A B C 1 96 65 60 2 82 74 73 3 88 72 85 4 70 66 61 5 90 79 79 6 91 82 85 7 87 73 88 8 88 79 This might help. MTB > sum c1 Sum of A Sum of A = 692 MTB > ssq c1 Sum of Squares of A Sum of squares (uncorrected) of A = 60278 MTB > sum c2 Sum of B Sum of B = 511 MTB > ssq c2 Sum of Squares of B Sum of squares (uncorrected) of B = 37535 41 252x0541 4/22/05 a) Compare the performance of locations A, B, and C assuming that the underlying distribution is nonNormal. (4) The modified data is shown below. The x s are the original numbers and the r s are their ranks among the 20 data items. The Kruskal-Wallis Test is equivalent to one-way ANOVA when the underlying distribution is non-normal. The null hypothesis is H 0 : Columns come from same distribution or medians equal. x1 r1 x 2 r2 x 3 r3 Row 1 2 3 4 5 6 7 8 9 A 96 82 88 70 90 91 87 88 C9_A 24.0 14.5 20.0 6.0 22.0 23.0 18.0 20.0 147.5 B 65 74 72 66 79 82 73 C9_B 4.0 10.0 7.0 5.0 12.0 14.5 8.5 61.0 So n1 8 , n 2 7 , n 3 9 , n C 60 73 85 61 79 85 88 79 23 n i C9_C 2.0 8.5 16.5 3.0 12.0 16.5 20.0 12.0 1.0 91.5 24 , SR1 147 .5 , SR2 61 .0 and SR3 91 .5 . To check the ranking, note that the sum of the four rank sums is 147.5 + 61.0 + 91.5 = 300, and nn 1 24 25 300 . that the sum of the first n 24 numbers is 2 2 12 SRi 2 3n 1 Now, compute the Kruskal-Wallis statistic H nn 1 i ni 12 147 .52 61 .02 91 .52 3 25 12 2719 .53125 531 .57143 930 .25000 75 24 25 8 7 9 300 167 .254 75 92.254 . The Kruskal-Wallis table (Table 9) does not have values for tests with columns this long, so we must use the 2 distribution, with df m 1 , where m is the number of columns. Since there are m 3 columns and .05 , test H with .2052 5.9915 . Since H is larger than .205 , reject the null hypothesis of equal medians. [26] b) Use a one-way ANOVA to test the hypothesis of equal means. (5) It is legitimate to check your results by computer, but I expect to see hand computations every step of the way. [31] Here’s what the computer output said. One-way ANOVA: A, B, C Source Factor Error Total DF 2 21 23 SS 1228 3986 5214 MS 614 190 F 3.23 P 0.060 Can we get similar results by hand? 42 252x0541 4/22/05 Using the tableau suggested in the outline with a modification for unequal column lengths, we get the following. A B C Sum 1 2 3 96 65 60 82 74 73 88 72 85 70 66 61 90 79 79 91 82 85 87 73 88 88 ---79 -----23 Sum 1836 x ij 692 + 511 + 633 8+ nj 86.5 SS 60278 + 37535 + 47855 n j x2j 59858 + 37303 + 44521 73 70.333 24 n 1836 76 .5 x 24 145668 x 141682 n x 2 xij2 nx 2 145668 2476.52 5214 2 2 2 2 . j x n j x. j nx 141682 24 76 .5 1228 ij 2 ij 2 j j x SSW SST SSB 3986 Source SS Between 9 x j x SSB x SST 7+ 1228 DF MS F F.05 2 614 3.235ns F 2,21 3.47 H0 Column means equal Within 3986 21 189.81 Total 5214 23 Since our computed F is smaller that the table F, we cannot reject the null hypothesis that the locations’ performance is similar. c. (Extra Credit) Decide between the methods that you used in a) and b). To do this test for equal variances and for Normality on the computer. What is your decision? Why? (4) Here are my computer results. MTB > vartest c7 c8 Test for Equal Variances: C7 versus C8 95% C8 A B C Bonferroni confidence intervals for standard deviations N Lower StDev Upper 8 4.7074 7.7460 18.9708 7 3.6650 6.2183 16.8724 9 12.7262 20.4145 46.2301 Bartlett's Test (normal distribution) Test statistic = 10.63, p-value = 0.005 Levene's Test (any continuous distribution) Test statistic = 1.61, p-value = 0.223 Test for Equal Variances: C7 versus C8 43 252x0541 4/22/05 Test for Equal Variances for C7 Bartlett's Test Test Statistic P-Value A 10.63 0.005 Lev ene's Test C8 Test Statistic P-Value 1.61 0.223 B C 0 10 20 30 40 95% Bonferroni Confidence Intervals for StDevs 50 Well, the intervals seem to overlap and Levene’s test has a p-value above 5%, which means we cannot reject the hypothesis of equal variances. But the Bartlett Test is worrisome, since it says that if the distribution is not Normal, the variances are not equal. 44 252x0541 4/22/05 MTB > normtest 'A'; SUBC> KSTest. Probability Plot of A Probability Plot of A Normal 99 Mean StDev N KS P-Value 95 90 Percent 80 70 60 50 40 30 20 10 5 1 70 75 80 85 90 95 100 105 A At this point I am inclining toward the Kruskal-Wallis test as being the right one. ANOVA presumes a Normal parent distribution and equal variances. The p-value of the ‘K-S’ test is above 5%, so we cannot reject the Normality assumption, but then the Bartlett test says the variances are not equal. If we use a 10% significance level instead of 5%, we would reject the Normality assumption and use the results of the Levene test. But if the distribution is not Normal, equal variances won’t push us toward ANOVA. 45 86.5 7.746 8 0.276 0.073