K. REGRESSION EXTENSIONS 252solnK1 11/26/07
advertisement

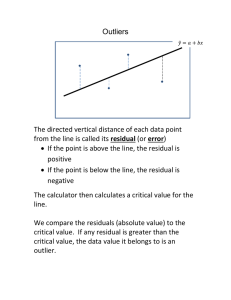
252solnK1 11/26/07 (Open this document in 'Page Layout' view!) K. REGRESSION EXTENSIONS 1. Residual Analysis Text 13.23, 13.24, 13.26, 14.18 [13.20, 13.21, 13.22, 14.9] (13.20, 13.21, 13.22, 14.9) 2. Dummy Variables 14.38-14.39, 14.41 [14.33 – 14.35] (15.6 – 15.8) 3. Nonlinear regression 15.1, 15.6, 15.7 [15.1, 15.6, 15.7] (15.1, 15.13, 15.14) 4. Runs test K1 5. Durbin-Watson test 13.32-13.34 [13.28, 13.29, 13.30] (13.28, 13.29, 13.30) This document includes sections 1-3 --------------------------------------------------------------------------------------------- ------------------------------------ Residual Analysis Most answers below are from the Instructor’s Solution Manual. Exercise 13.23 [13.20 in 9th]: You have to look at the problem in the book for 20 and 21. A residual analysis of the data indicates no apparent pattern. The assumptions of regression appear to be met. Exercise 13.24 [13.21 in 9th]: A residual analysis of the data indicates a pattern, with sizeable clusters of consecutive residuals that are either all positive or all negative. This appears to violate the assumption of independence of errors. Exercise 13.26 [13.22 in 9th]: (a)-(b) The Instructor’s Solution Manual says “Based on a residual analysis, the model appears to be adequate.” I’m not so sure. I ran the data and got the output. ————— 12/2/2003 4:01:58 PM ———————————————————— Welcome to Minitab, press F1 for help. MTB > Retrieve "C:\Documents and Settings\RBOVE.WCUPANET\My Documents\Drive D\MINITAB\petfood.MTW". Retrieving worksheet from file: C:\Documents and Settings\RBOVE.WCUPANET\My Documents\Drive D\MINITAB\petfood.MTW # Worksheet was saved on Wed Nov 12 2003 Results for: petfood.MTW MTB > Name c7 = 'RESI1' c8 = 'SRES1' MTB > Regress c1 1 c2; SUBC> Residuals 'RESI1'; SUBC> SResiduals 'SRES1'; SUBC> Constant; SUBC> Brief 3. Regression Analysis: Sales versus Space The regression equation is Sales = 1.45 + 0.0740 Space Predictor Constant Space S = 0.3081 Coef SE Coef T P 1.4500 0.2178 6.66 0.000 0.07400 0.01591 4.65 0.001 R-Sq = 68.4% R-Sq(adj) = 65.2% 252solnK1 11/26/07 (Open this document in 'Page Layout' view!) Analysis of Variance Source Regression Residual Error Total Obs 1 2 3 4 5 6 7 8 9 10 11 12 Space 5.0 5.0 5.0 10.0 10.0 10.0 15.0 15.0 15.0 20.0 20.0 20.0 DF 1 10 11 SS 2.0535 0.9490 3.0025 Sales 1.6000 2.2000 1.4000 1.9000 2.4000 2.6000 2.3000 2.7000 2.8000 2.6000 2.9000 3.1000 MS 2.0535 0.0949 Fit 1.8200 1.8200 1.8200 2.1900 2.1900 2.1900 2.5600 2.5600 2.5600 2.9300 2.9300 2.9300 F 21.64 SE Fit 0.1488 0.1488 0.1488 0.0974 0.0974 0.0974 0.0974 0.0974 0.0974 0.1488 0.1488 0.1488 P 0.001 Residual -0.2200 0.3800 -0.4200 -0.2900 0.2100 0.4100 -0.2600 0.1400 0.2400 -0.3300 -0.0300 0.1700 MTB > %Fitline c1 c2; SUBC> Confidence 95.0. Executing from file: W:\wminitab13\MACROS\Fitline.MAC Macro is running ... please wait Regression Analysis: Sales versus Space The regression equation is Sales = 1.45 + 0.074 Space S = 0.308058 R-Sq = 68.4 % R-Sq(adj) = 65.2 % Analysis of Variance Source Regression Error Total DF 1 10 11 SS 2.0535 0.9490 3.0025 MS 2.0535 0.0949 F 21.6386 P 0.001 Fitted Line Plot: Sales versus Space MTB > %Resplots c7 c6; SUBC> Title "Residuals vs Fits". Executing from file: W:\wminitab13\MACROS\Resplots.MAC Macro is running ... please wait Residual Plots: RESI1 vs FITS1 MTB > Plot c7*c1; SUBC> Symbol; SUBC> ScFrame; SUBC> ScAnnotation. St Resid -0.82 1.41 -1.56 -0.99 0.72 1.40 -0.89 0.48 0.82 -1.22 -0.11 0.63 252solnK1 11/26/07 (Open this document in 'Page Layout' view!) Plot RESI1 * Sales MTB > Plot c7*c2; SUBC> Symbol; SUBC> Scram; SUBC> ScAnnotation. Plot RESI1 * Space Regression Plot Sales = 1.45 + 0.074 Space S = 0.308058 R-Sq = 68.4 % R-Sq(adj) = 65.2 % 3.0 Sales 2.5 2.0 1.5 5 10 15 20 Space The plot above looks pretty random. Residuals vs Fits I Chart of Residuals Residual Residual Normal Plot of Residuals 0.5 0.4 0.3 0.2 0.1 0.0 -0.1 -0.2 -0.3 -0.4 1 UCL=1.081 0 Mean=1.11E-16 -1 -2 -1 0 1 Normal Score Histogram of Residuals 0 -0.4 -0.3 -0.2 -0.1 0.0 0.1 0.2 0.3 0.4 Residual 10 Residuals v s. Fits Residual Frequency 1 5 Observation Number 3 2 LCL=-1.081 0 2 0.5 0.4 0.3 0.2 0.1 0.0 -0.1 -0.2 -0.3 -0.4 2.0 2.5 3.0 Fit These are the plots that bother me. Normal plots are described on page 227 of the text. The Normal plot looks a lot like the rectangular distribution shown there, though rectangular distributions are not as bad as skewed distributions. The histogram gives us a bimodal distribution. 252solnK1 11/26/07 (Open this document in 'Page Layout' view!) 0.5 0.4 0.3 RESI1 0.2 0.1 0.0 -0.1 -0.2 -0.3 -0.4 5 10 15 20 Space This plot is probably the most important and it shows very little in the way of a pattern. This is nice. Exercise 14.18 [14.9 in 9th]: We go back to the WARECOST model. a) Perform a residual analysis to determine adequacy of the model. b) Plot residuals against months looking for a pattern. c) Find the Durbin-Watson statistic. d) Find evidence of autocorrelation. The Instructor’s Solution Manual says the following. (a) Based upon a residual analysis the model appears adequate. (b) There is no evidence of a pattern in the residuals versus time. (c) D = 2.26 (d) D = 2.26 > 1.55. There is no evidence of positive autocorrelation in the residuals. For an explanation see the printout. To run this regression I used the Statistics pull-down menu and then picked Regression twice. I had put headings on my columns – the data is in the text and on your CD, but, since I’m lazy, I identified the columns as C1, C2 and C3. So C1 was my response (dependent - Y) variable and C2 and C3 were my predictor (independent – X) variables. There are just too many subcommands here to use the session window to drive Minitab. On the Regression menu I went into Graphs and checked all the residual plots. Under Options I picked Variance Inflation Factors and Durbin-Watson. Under Results I took the last and most complete option, though this can also be done by using the session command ‘Brief 3’ before you start. Under storage I picked both of the residuals, though that seems to have been unnecessary unless I wanted to do some extra plotting. When this regression was finished and I had copied all the graphs into a Word document, I ran Stepwise from the Regression menu using C1, C2 and C3. MTB > Retrieve "C:\Documents and Settings\RBOVE.WCUPANET\My Documents\Drive D\MINITAB\Warecost.MTW". Retrieving worksheet from file: C:\Documents and Settings\RBOVE.WCUPANET\My Documents\Drive D\MINITAB\Warecost.MTW # Worksheet was saved on Thu Nov 20 2003 Results for: Warecost.MTW MTB > Name c4 = 'RESI1' c5 = 'SRES1' MTB > Regress c1 2 c2 c3; SUBC> Residuals 'RESI1'; SUBC> SResiduals 'SRES1'; SUBC> GHistogram; SUBC> GNormalplot; SUBC> GFits; SUBC> GOrder; 252solnK1 11/26/07 SUBC> SUBC> SUBC> SUBC> SUBC> SUBC> (Open this document in 'Page Layout' view!) GVars c2 c3; RType 1; Constant; VIF; DW; Brief 3. Regression Analysis: DistCost versus Sales, Orders The regression equation is DistCost = - 2.73 + 0.0471 Sales + 0.0119 Orders Predictor Constant Sales Orders Coef -2.728 0.04711 0.011947 S = 4.766 SE Coef 6.158 0.02033 0.002249 R-Sq = 87.6% T -0.44 2.32 5.31 P 0.662 0.031 0.000 VIF 2.8 2.8 R-Sq(adj) = 86.4% Analysis of Variance Source Regression Residual Error Total Source Sales Orders DF 1 1 DF 2 21 23 SS 3368.1 477.0 3845.1 MS 1684.0 22.7 F 74.13 P 0.000 Seq SS 2726.8 641.3 Comment: The gigantic p-value tells us that the constant is insignificant, but the coefficients of Sales and Orders were significant at the 5% level. The VIF will be discussed later (Check the end of this document), but a value below 5 is usually fine. The low p-value for the ANOVA tells us that the 2 independent variables explained a lot of the variation in DistCost. Their sequential contribution to the Regression sum of squares is shown below the ANOVA. This makes Order look like a fairly feeble, if significant, contributor to the regression. Actually we will find that is not true. Obs 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 Sales 386 446 512 401 457 458 301 484 517 503 535 353 372 328 408 491 527 444 623 596 463 DistCost 52.950 71.660 85.580 63.690 72.810 68.440 52.460 70.770 82.030 74.390 70.840 54.080 62.980 72.300 58.990 79.380 94.440 59.740 90.500 93.240 69.330 Fit 63.425 63.755 84.820 67.082 70.127 67.796 49.839 77.528 84.196 77.503 75.199 48.800 62.311 65.626 63.852 75.145 88.789 59.407 87.302 93.867 70.087 SE Fit 1.332 1.511 1.656 1.332 0.999 1.193 2.134 1.139 1.525 1.126 1.838 2.277 1.483 2.847 1.152 1.069 2.004 2.155 2.535 2.097 1.049 Residual -10.475 7.905 0.760 -3.392 2.683 0.644 2.621 -6.758 -2.166 -3.113 -4.359 5.280 0.669 6.674 -4.862 4.235 5.651 0.333 3.198 -0.627 -0.757 St Resid -2.29R 1.75 0.17 -0.74 0.58 0.14 0.62 -1.46 -0.48 -0.67 -0.99 1.26 0.15 1.75 -1.05 0.91 1.31 0.08 0.79 -0.15 -0.16 252solnK1 11/26/07 22 23 24 389 547 415 (Open this document in 'Page Layout' view!) 53.710 89.180 66.800 59.898 87.401 66.535 1.349 1.657 1.107 -6.188 1.779 0.265 -1.35 0.40 0.06 R denotes an observation with a large standardized residual Durbin-Watson statistic = 2.26 Comment: The Durbin-Watson is checking for autocorrelation, which will be explained later. It’s enough to say that values close to 2 indicate that autocorrelation is not a problem. The dependent variable (Y) and the first independent variable are printed out above, followed by Fit, which means the predicted value of Y, SE Fit, which with the appropriate value if t will give us a confidence interval for Y, and Residual, which is the difference between the predicted and the actual value of Y. The standardized residual seems to be the residual after the mean residual has been subtracted from it and the standard deviation of the residual has been divided into it. Residual Histogram for DistCost Normplot of Residuals for DistCost Residuals vs Fits for DistCost Residuals vs Order for DistCost Residuals from DistCost vs Sales Residuals from DistCost vs Orders Histogram of the Residuals (response is DistCost) 7 6 Frequency 5 4 3 2 1 0 -10 -8 -6 -4 -2 0 2 4 6 8 Residual Comment: The histogram seems to indicate a fairly symmetrical distribution with a peak in the middle. 252solnK1 11/26/07 (Open this document in 'Page Layout' view!) Normal Probability Plot of the Residuals (response is DistCost) 2 Normal Score 1 0 -1 -2 -10 0 10 Residual Comment: The text says that a straight-line Normal Probability plot indicates a Normal distribution. Comment: There doesn’t seem to be much of a pattern here. 252solnK1 11/26/07 (Open this document in 'Page Layout' view!) Comment: A pattern here would indicate autocorrelation. Comment: These two graphs show no pattern either. 252solnK1 11/26/07 (Open this document in 'Page Layout' view!) MTB > Stepwise c1 c2 c3; SUBC> AEnter 0.15; SUBC> ARemove 0.15; SUBC> Constant. Stepwise Regression: DistCost versus Sales, Orders Alpha-to-Enter: 0.15 Alpha-to-Remove: 0.15 Response is DistCost on 2 predictors, with N = Step Constant 1 0.4576 2 -2.7282 Orders T-Value P-Value 0.0161 10.92 0.000 0.0119 5.31 0.000 Sales T-Value P-Value 24 0.047 2.32 0.031 S 5.22 4.77 R-Sq 84.42 87.59 R-Sq(adj) 83.71 86.41 C-p 6.4 3.0 More? (Yes, No, Subcommand, or Help) SUBC> yes No variables entered or removed More? (Yes, No, Subcommand, or Help) SUBC> no Comment: This was a stepwise regression. It was done with no options, so that all the subcommands that you see here were generated by Minitab. It seems that the independent variable with the most explanatory power was ‘Orders,’ and the regression was Y = 0.4576 + .0161 Orders, with an Rsquared of 84.42. Minitab then added the other independent variable and got a regression of Y = -2.7282 + 0.119 Orders + 0.047 Sales, which is the same regression we got with the ‘Regress’ command. The C-p statistic, also explained in the text, should be near k + 1, which it is for this regression. After adding two independent variables, Minitab paused and asked me if I wanted to try for more independent variables. I foolishly said ‘yes,’ whereupon Minitab discovered that it didn’t have any more variables to add. Dummy Variables Exercise 14.38 [14.33 in 9th] (15.6 in 8th edition): The equation is Y 6 4 X 1 2 X 2 . a) Interpret the coefficient of X1 b) Interpret the coefficient of X2 c) If the t for X2 is 3.27 and .05 , does X2 make a significant contribution to the model? (a) Holding constant the effect of X2, the estimated average value of the dependent variable will increase by 4 units for each increase of one unit of X1. (b) Holding constant the effects of X1, the presence of the condition represented by X2 = 1 is estimated to increase the average value of the dependent variable by 2 units. 17 2.11 . You can reject H0 and say t 3.27 . n k 1 20 2 1. This is larger than t .05 (c) that the presence of X2 makes a significant contribution to the model. 252solnK1 11/26/07 (Open this document in 'Page Layout' view!) Exercise 14.39 [14.34 in 9th] (15.7 in 8th edition): The chair of an accounting department wants to predict GPA in accounting on the basis of SAT score and whether the student got a B or better in the introductory statistics course. a) Explain the steps involved in making a model and b) assume that the variable representing the statistics grade has a coefficient of .30. Explain its meaning. (a) First develop a multiple regression model using X1 as the variable for the SAT score and X2 a dummy variable with X2 = 1 if a student had a grade of B or better in the introductory statistics course. If the dummy variable coefficient is significantly different than zero, you need to develop a model with the interaction term X1 X2 to make sure that the coefficient of X1 is not significantly different if X2 = 0 or X2 = 1. (b) If a student received a grade of B or better in the introductory statistics course, the student would be expected to have a grade point average in accountancy that is 0.30 higher than a student who had the same SAT score, but did not get a grade of B or better in the introductory statistics course. Exercise 14.41 [14.35 in 9th] (15.8 in 8th edition): Use the PETFOOD data to develop a regression explaining sales as an effect of the amount of shelf space, and the location of the product in the aisle (back or front). a) State the equation, b) interpret coefficients, predict sales for 8 feet of shelf space in the back of the aisle and make it into 95% confidence and prediction intervals. Data is below. Solution: To run this regression I used the Statistics pull-down menu and then picked Regression twice. I had put headings on my columns – the data is in the text and on your CD, but, since I’m lazy, I identified the columns as C1, C2 and C3. So C2 was my response (dependent - Y) variable and C1 and C3 were my predictor (independent – X) variables. There are just too many subcommands here to use the session window to drive Minitab. On the Regression menu I went into Graphs and checked all the residual plots except residuals vs. order. Under Options I picked Variance Inflation Factors and set up for confidence and prediction intervals by telling it that the independent variables for this prediction were in C5 and C6. Under Results I took the last and most complete option, though this can also be done by using the session command ‘Brief 3’ before you start. Under storage I picked nothing. When this regression was finished and I had copied all the graphs into a Word document, I ran the regression again with the Interaction variable requested in part n) of the problem. To confirm my results, I ran Stepwise from the Regression menu using C1, C3 and C4 as candidates to explain C2. The output from the run follows with comments. ————— 12/2/2003 9:15:15 PM ———————————————————— Welcome to Minitab, press F1 for help. MTB > Retrieve "C:\Berenson\Data_Files-9th\Minitab\petfood.MTW". Retrieving worksheet from file: C:\Berenson\Data_Files-9th\Minitab\petfood.MTW # Worksheet was saved on Mon Apr 27 1998 Comment: I downloaded the data from the text CD, but stored it where I could get it more easily if I needed it again. Results for: petfood.MTW MTB > Save "C:\Documents and Settings\RBOVE.WCUPANET\My Documents\Drive D\MINITAB\petfood3"; SUBC> Replace. Saving file as: C:\Documents and Settings\RBOVE.WCUPANET\My Documents\Drive D\MINITAB\petfood3.MTW * NOTE * Existing file replaced. Results for: petfood3.MTW 252solnK1 11/26/07 (Open this document in 'Page Layout' view!) MTB > regress c2 1 c1 Regression Analysis: Sales versus Space The regression equation is Sales = 1.45 + 0.0740 Space Predictor Coef SE Coef T P Constant 1.4500 0.2178 6.66 0.000 Space 0.07400 0.01591 4.65 0.001 S = 0.3081 R-Sq = 68.4% R-Sq(adj) = 65.2% Analysis of Variance Source DF Regression 1 Residual Error 10 Total 11 SS 2.0535 0.9490 3.0025 MS 2.0535 0.0949 F 21.64 P 0.001 Comment: This is the regression referred to in Problems 13.3 and 13.14. MTB > let c4 = c1 * c3 Comment: This command creates the interaction variable, which I have labeled ‘Inter’ in C4. MTB > print c1-c6 Data Display Row Space Sales Locatn Inter C5 C6 1 2 3 4 5 6 7 8 9 10 11 12 5 5 5 10 10 10 15 15 15 20 20 20 1.6 2.2 1.4 1.9 2.4 2.6 2.3 2.7 2.8 2.6 2.9 3.1 0 1 0 0 0 1 0 0 1 0 0 1 0 5 0 0 0 10 0 0 15 0 0 20 8 0 Comment: This is the data I will use. Because part c) of this problem asks for confidence and prediction intervals I have set up values of space and sales for these intervals in C5 and C6. MTB > Regress c2 2 c1 c3; SUBC> GHistogram; SUBC> GNormalplot; SUBC> GFits; SUBC> GVars c1 c3; SUBC> RType 1; SUBC> Constant; SUBC> VIF; SUBC> Predict c5 c6; SUBC> Brief 3. Regression Analysis: Sales versus Space, Locatn The regression equation is Sales = 1.30 + 0.0740 Space + 0.450 Locatn Predictor Coef SE Coef T P Constant 1.3000 0.1569 8.29 0.000 Space 0.07400 0.01101 6.72 0.000 Locatn 0.4500 0.1305 3.45 0.007 S = 0.2132 R-Sq = 86.4% R-Sq(adj) = 83.4% Analysis of Variance Source DF Regression 2 Residual Error 9 Total 11 SS 2.5935 0.4090 3.0025 MS 1.2967 0.0454 F 28.53 VIF 1.0 1.0 P 0.000 252solnK1 11/26/07 Source Space Locatn (Open this document in 'Page Layout' view!) DF 1 1 Seq SS 2.0535 0.5400 Comment: These results look great. Note that all my coefficients are significant, with p-values below 1%. The VIF is way below 5, which indicates a lack of collinearity. The ANOVA gives me a p-value of zero, indicating that the regression is quite useful. Obs 1 2 3 4 5 6 7 8 9 10 11 12 Space 5.0 5.0 5.0 10.0 10.0 10.0 15.0 15.0 15.0 20.0 20.0 20.0 Sales 1.6000 2.2000 1.4000 1.9000 2.4000 2.6000 2.3000 2.7000 2.8000 2.6000 2.9000 3.1000 Fit 1.6700 2.1200 1.6700 2.0400 2.0400 2.4900 2.4100 2.4100 2.8600 2.7800 2.7800 3.2300 SE Fit 0.1118 0.1348 0.1118 0.0802 0.0802 0.1101 0.0802 0.0802 0.1101 0.1118 0.1118 0.1348 Residual -0.0700 0.0800 -0.2700 -0.1400 0.3600 0.1100 -0.1100 0.2900 -0.0600 -0.1800 0.1200 -0.1300 St Resid -0.39 0.48 -1.49 -0.71 1.82 0.60 -0.56 1.47 -0.33 -0.99 0.66 -0.79 Predicted Values for New Observations New Obs 1 Fit 1.8920 SE Fit 0.0902 95.0% CI 1.6880, 2.0960) ( ( 95.0% PI 1.3684, 2.4156) Values of Predictors for New Observations New Obs 1 Space 8.00 Locatn 0.000000 Residual Histogram for Sales Normplot of Residuals for Sales Residuals vs Fits for Sales Histogram of the Residuals (response is Sales) 5 Frequency 4 3 2 1 0 -0.3 -0.2 -0.1 0.0 0.1 0.2 0.3 0.4 Residual Comment: This graph doesn’t really look bad. Given the relatively small sample size, it could be results from a symmetrical distribution. 252solnK1 11/26/07 (Open this document in 'Page Layout' view!) Normal Probability Plot of the Residuals (response is Sales) 2 Normal Score 1 0 -1 -2 -0.3 -0.2 -0.1 0.0 0.1 0.2 0.3 0.4 Residual Comment: This seems to be fairly close to a straight line indicating that the residuals have a distribution that is close to Normal. 252solnK1 11/26/07 (Open this document in 'Page Layout' view!) Comment: These look fairly random, given the fact that shelves seem to only come in lengths that are multiples of 5 and that Location is a dummy variable. MTB > Regress c2 3 c1 c3 c4; SUBC> RType 1; SUBC> Constant; SUBC> VIF; SUBC> Brief 3. Regression Analysis: Sales versus Space, Locatn, Inter The regression equation is Sales = 1.20 + 0.0820 Space + 0.750 Locatn - 0.0240 Inter Predictor Constant Space Locatn Inter Coef 1.2000 0.08200 0.7500 -0.02400 S = 0.2124 SE Coef 0.1840 0.01344 0.3186 0.02327 R-Sq = 88.0% T 6.52 6.10 2.35 -1.03 P 0.000 0.000 0.046 0.333 VIF 1.5 6.0 6.5 R-Sq(adj) = 83.5% Analysis of Variance Source Regression Residual Error Total Source Space Locatn Inter DF 1 1 1 DF 3 8 11 SS 2.64150 0.36100 3.00250 MS 0.88050 0.04513 F 19.51 P 0.000 Seq SS 2.05350 0.54000 0.04800 Comment: Things don’t look so good in this regression. The VIFs for the last two variables are high indicating collinearity; The p-value for the coefficient of interaction is very high, indicating that it’s not significant at the 1%, 5% or 10% level. 252solnK1 11/26/07 Obs 1 2 3 4 5 6 7 8 9 10 11 12 Space 5.0 5.0 5.0 10.0 10.0 10.0 15.0 15.0 15.0 20.0 20.0 20.0 (Open this document in 'Page Layout' view!) Sales 1.6000 2.2000 1.4000 1.9000 2.4000 2.6000 2.3000 2.7000 2.8000 2.6000 2.9000 3.1000 Fit 1.6100 2.2400 1.6100 2.0200 2.0200 2.5300 2.4300 2.4300 2.8200 2.8400 2.8400 3.1100 SE Fit 0.1257 0.1777 0.1257 0.0823 0.0823 0.1164 0.0823 0.0823 0.1164 0.1257 0.1257 0.1777 Residual -0.0100 -0.0400 -0.2100 -0.1200 0.3800 0.0700 -0.1300 0.2700 -0.0200 -0.2400 0.0600 -0.0100 St Resid -0.06 -0.34 -1.23 -0.61 1.94 0.39 -0.66 1.38 -0.11 -1.40 0.35 -0.09 MTB > Stepwise c2 c1 c3 c4; SUBC> AEnter 0.15; SUBC> ARemove 0.15; SUBC> Constant. Stepwise Regression: Sales versus Space, Locatn, Inter Alpha-to-Enter: 0.15 Response is Sales Alpha-to-Remove: 0.15 on 3 predictors, with N = Step Constant 1 1.450 2 1.300 Space T-Value P-Value 0.074 4.65 0.001 0.074 6.72 0.000 Locatn T-Value P-Value 12 0.45 3.45 0.007 S 0.308 0.213 R-Sq 68.39 86.38 R-Sq(adj) 65.23 83.35 C-p 13.0 3.1 More? (Yes, No, Subcommand, or Help) SUBC> yes No variables entered or removed More? (Yes, No, Subcommand, or Help) SUBC> no MTB > Comment: The stepwise regression confirms the results above. Minitab decides that ‘Space’ is the best single predictor and essentially redoes our first regression. It then brings in ‘Location’ and gets our second regression. But when it is told to go ahead and add a third independent variable, it doesn’t find enough explanatory power in ‘Inter’ to make it worth adding. Note that C-p is close to k + 1 in the second regression, indicating good results. The following material is an edited version of the solution in the Instructor’s Solution Manual. 14.35 (a) (b) (c) Yˆ 1.30 0.074X 1 0.45X 2 , where X1 = shelf space and X2 = aisle location. Holding constant the effect of aisle location, for each additional foot of shelf space, sales are expected to increase on average by 0.074 hundreds of dollars, or $7.40. For a given amount of shelf space, a front-of-aisle location is expected to increase sales on average by 0.45 hundreds of dollars, or $45. Yˆ 1.30 0.074(8) 0.45(0) 1.892 or $189.20 252solnK1 11/26/07 (Open this document in 'Page Layout' view!) These intervals can only be done using Minitab or another regression program and appear in the printout. 1.6880 Y |X X i 2.0960 1.3684 YX X i 2.4156 (d) (e) (f) Based on a residual analysis, the model appears adequate. 2,9 4.26 . Reject H and say that there is evidence of a relationship F 28 .53 F.05 0 between sales and the two dependent variables. 9 For X1: t 6.72 t .025 2.262 . Reject H0 and say that Shelf space makes a significant contribution and should be included in the model. 9 For X2: t 3.45 t .025 2.262 . Reject H0 and say that aisle location makes a significant contribution and should be included in the model. Both variables should be kept in the model. (g) Remember that our results were The regression equation is Sales = 1.30 + 0.0740 Space + 0.450 Locatn Predictor Constant Space Locatn Coef 1.3000 0.07400 0.4500 SE Coef 0.1569 0.01101 0.1305 T 8.29 6.72 3.45 P 0.000 0.000 0.007 VIF 1.0 1.0 9 Using the coefficient of space, b1 0.074, t nk 1 t.025 2.262 , and sb1 0.01101 , 2 you should be able to get 0.049 1 0.099 . (Is this right? I haven’t checked so tell (h) (i) (j) (k) (l) (m) (n) me.). By the same method, you should be able to get 0.155 2 0.745 for location. The slope here takes into account the effect of the other predictor variable, placement, while the solution for Problem 13.3 did not. rY2.12 0.864 . So, 86.4% of the variation in sales can be explained by variation in shelf space and variation in aisle location. 2 radj 0.834 rY2.12 0.864 while about six pages back, for the simple regression, rY2.1 0.684 . The inclusion of the aisle-location variable has resulted in the increase. I’m a little bit too lazy to compute these things the way our author wants you to do it. There’s a formula at the end of 252corr that gets you these results much faster. 6.72 2 45 .1584 t2 rY21.2 2 2 .8338 . Holding constant the effect of aisle t 2 df 6.72 2 9 54 .1584 location, 83.4% of the variation in sales can be explained by variation in shelf space. 3.45 2 11 .9025 t2 rY22.1 2 1 .5694 rY22.1 0.569 . Holding constant the 2 20 . 9025 t1 df 3.45 9 effect of shelf space, 56.9% of the variation in sales can be explained by variation in aisle location. The slope of sales with shelf space is the same regardless of whether the aisle location is front or back. From the last regression in the printout, Yˆ 1.20 0.082 X 1 0.75 X 2 0.024 X 1 X 2 . Do not reject H0. There is not (o) evidence that the interaction term makes a contribution to the model. The two-variable model in (a) should be used. 252solnK1 11/26/07 (Open this document in 'Page Layout' view!) Nonlinear regression Exercise 15.1: The equation given is Yˆ 5 3X 1 1.5 X 12 . n 25 . a) Predict Y for X1 = 2. b) Assume that the t for the x-squared term is 2.35 and .05 , does this mean that the quadratic model is an improvement over the linear model? c) What if the same t is 1.17? d) Assume that the coefficient of x is -3, predict Y for X1 = 2. Solution: (a) Yˆ 5 3X 1.5 X 2 5 3(2) 1.5(2 2 ) 17 (b) df n k 1 25 2 1 22 . t 2.35 t 22 2.0739 with 22 degrees of freedom. Reject H0. The quadratic term is significant. t 1.17 t 22 2.0739 with 22 degrees of freedom. Do not reject H0. The quadratic term (c) is not significant. (d) Yˆ 5 3X 1.5 X 2 5 3(2) 1.5(2 2 ) 5 Exercise 15.6(15.13 in 8th edition): The given equation is ln Yˆ 3.07 0.9 X 1 1.41 ln X 2 . a) Predict Y for x1= 8.5 and x2 = 5.2. b) Interpret the meaning of the slopes. Solution: (a) ln Yˆ 3.07 0.9 ln(8.5) 1.41ln(5.2) 7.32067 Yˆ e 7.32067 1511 .22 (b) Holding constant the effects of X2, for each additional unit of the natural logarithm of X1 the natural logarithm of Y is expected to increase on average by 0.9. Holding constant the effects of X1, for each additional unit of the natural logarithm of X2 the natural logarithm of Y is expected to increase on average by 1.41. Exercise 15.7(15.14 in 8th edition): The given equation is ln Yˆ 4.62 0.5 X 10.7 X 2 (5.2) 12.51 . a) Predict Y for x1= 8.5 and x2 = 5.2. b) Interpret the meaning of the slopes. Solution: Yˆ e12.51 271,034 .12 (a) ln Yˆ 4.62 0.5(8.5) 0.7(5.2) 12.51 (b) Holding constant the effects of X2, for each additional unit of X1 the natural logarithm of Y is expected to increase on average by 0.5. Holding constant the effects of X1, for each additional unit of X2 the natural logarithm of Y is expected to increase on average by 0.7. Note: To deal with the VIF, the following material has been added to 252corr together with an example. A relatively recent method to check for collinearity is to use the Variance Inflation Factor 1 . Here R 2j is the coefficient of multiple correlation gotten by regressing VIF j 2 1 R j the independent variable X j against all the other independent variables Xs . The rule of thumb seems to be that we should be suspicious if any VIFj 5 and positively horrified if VIFj 10 . If you get results like this, drop a variable or change your model. Note that, if you use a correlation matrix for your independent variables and see a large correlation between two of them, putting the square of that correlation into the VIF formula gives you a low estimate of the VIF, since the R-squared that you get from a regression against all the independent variables will be higher.