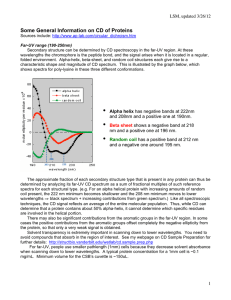
Where is the information in clusters lenses?
advertisement

Where is the Information in
Cluster Lenses?
GLCW8
The Ohio State University
June 2, 2007
Dave Goldberg
Students:
Sanghamitra Deb
Vede Ramdass
There has been a great deal of discussion recently about
how “Strong+Weak” nonparametric mass reconstructions
can be performed on clusters.
The “Bullet Cluster,” 1E0657-56, Bradac et al. (2006)
astro-ph/0608408
Current S+W techniques use two pieces of information:
1) The “Weak Part”
Convergence k
(magnification)
g
g
2
1
Shear
2) The “strong part”:
Typically, a weak prior is computed...
Guess a potential field
{n-1)}
on a coarse gridscale
Compute {k(n-1)}
Minimize for:
2
(n )
gi
i
(n1)
1 k i
i2
Iteratively refine the
grid scale
Here’s what the weak part looks like...
ACS Image of A1689
From Leonard et al. 2007 (astro-ph/0702242)
The weak is then generally used as a prior for the strong...
(Just in case you forgot what a
strong lens system looks like. Okay,
so it’s a bit out of focus.)
b=q aq)
B
Lens
But the background source
for both images is the same!
(a Aj a Bj ) (q Aj q Bj ))
2
) 2
2 = (k i k (weak
)
i
A
a2
To get to the central question: Where is the information?
As we can see, it’s on two different scales.
The weak noise is based on the intrinsic variance of
source ellipticities:
0.3
g
N
So to get S/N > 1, we’ll want 10’s of sources per gridcell.
The weak and the strong operate on very different
scales.
Q: How can we reconcile the different scales for strong and
weak without introducing ad hoc regularization?
A: Don’t use grids!
How about Smoothed
Particle Hydrodynamics
(SPH)?
On the strong lensing side, we use:
0) Position Differences (2 constraints/pair)
But we don’t use:
1) Flux ratios (1 constraint/pair)
2) Ellipticity Differences (2 constraints/pair)
Why not? Naively, we might expect to increase our S/N by:
Magnification is a highly nonlinear function of the underlying fields:
1
=
(1 k ) 2 g 2
We could construct a nearly linear flux estimator which doesn’t
blow up:
2
A
2
A
2
B
2
B
We also want to estimate the ellipticity difference. In principle,
since both images are lensed from the same source, the
image should be less susceptible to the intrinsic ellipticity.
However, we still have a parity problem.
If one image is weak and the other is strong (negative
parity) then we need a relation along the lines
of:
with an error proportional to the square of the intrinsic
ellipticity!
But we still have a problem. We don’t know the parity
in the first place.
We propose simulated annealing!
Since the number of strong sources are relatively
small, convergence should be very fast!
Conclusions & Summary
• Strong+Weak cluster reconstructions have produced some
remarkable results, but...
• They currently do not account for widely differing
scales of information
• They do not include flux ratios or ellipticity ratios
• They don’t explicitly explore into the strong regime
This being a workshop, we figured some of you folks might
have some thoughts about this approach.