Chapter 06.pptx
advertisement

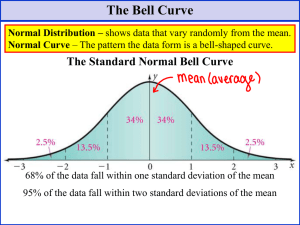
Chapter 6: Continuous Probability Distributions Slide set to accompany "Statistics Using Technology" by Kathryn Kozak (Slides by David H Straayer) is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. Based on a work at http://www.tacomacc.edu/home/dstraayer/published/Statistics/Book/StatisticsUsingTechnology112314b.pdf. 6.1 Uniform Distribution If you have a situation where the probability is always the same, then this is known as a uniform distribution. An example would be waiting for a commuter train. The commuter trains on the Blue and Green Lines for the Regional Transit Authority (RTA) in Cleveland, OH, have a waiting time during peak hours of ten minutes ("2012 annual report," 2012). If you are waiting for a train, you have anywhere from zero minutes to ten minutes to wait. Your probability of having to wait any number of minutes in that interval is the same. Uniform Distribution Graph Probability of an interval Questions about a uniform distribution: our RTA wait time a) State the random variable. b) Find the probability that you have to wait between four and six minutes for a train. c) Find the probability that you have to wait between three and seven minutes for a train. d) Find the probability that you have to wait between zero and ten minutes for a train. e) Find the probability of waiting exactly five minutes. Why study uniform distributions? • Computer random number generators are used for a lot of things. They usually generate a random number in the interval [0.0,1.0) • They introduce the idea of probability as an area under a (straight or curved) line. • They can be used to construct “toy” problems for a statistics class. • For example, the sum of two uniform random numbers makes a slightly more interesting (but still calculable) geometry for areas. 6.2: Graphs of the Normal Distribution “Normal” has a special meaning here. Many real life problems produce a histogram that is a symmetric, unimodal, and bell-shaped continuous probability distribution. For example: height, blood pressure, and cholesterol level. However, not every bell shaped curve is a normal curve. In a normal curve, there is a specific relationship between its “height” and its “width.” Typical Graph of a Normal Curve Characteristics of a normal curve • The center, or the highest point, is at the population mean, . • The transition points (inflection points) are the places where the curve changes from a “hill” to a “valley”. The distance from the mean to the transition point is one standard deviation, . • The area under the whole curve is exactly 1. Therefore, the area under the half below or above the mean is 0.5. “” and “<“, what’s the big deal? • In algebra, we make a big deal about of the difference between a x b and a < x < b. • In terms of probabilities, there is no difference. • For example, the probability of being taller than 6 feet tall, and the probability of being 6 feet tall or taller, is exactly the same. • Because no one is exactly 6 feet tall! Probability of an event as an area Empirical Rule The Empirical Rule for any normal distribution: • Approximately 68% of the data is within one standard deviation of the mean. • Approximately 95% of the data is within two standard deviations of the mean. • Approximately 99.7% of the data is within three standard deviations of the mean. (This like Chebyshev’s rule, but more specific) Empirical Rule z-score • The z-score is normally distributed, with a mean of 0 and a standard deviation of 1. It is known as the standard normal curve. • Before modern technology, we had to calculate a z-score to look up in a table. Standard Normal Curve Z TI Technology • The command on the TI-83/84 is in the DISTR menu and is normalcdf(. You then type in the lower limit, upper limit, mean, standard deviation in that order and including the commas. • Having to use both lower limit and upper limit is sometimes a convenience, and often a nuisance. Especially when there is no lower limit or no upper limit. The “Bell” program • I’ll help transfer the “Bell” program into your calculator. • It leads you step-by-step through normal (and T, but we’ll get to that later) probability calculations. This program is merely a “wrapper” around the TI’s built-in statistical functions. It doesn’t calculate anything that the TI can’t do already, but it provides a user interface that allows you to focus on the statistical implications of what they are calculating. It helps avoid some of the eccentricities of the user interface of the built-in functions. It also provides the functionality of the Inverse T (InvT) function missing from the TI-83. It runs on all versions of the TI-83 and TI-84, as well as the TI-Nspire. Running Bell Let’s assume you are just learning about the Normal (Z) curve, and want to find an area under a region of the curve. For example, a problem may ask you to find P(Z>2.0), the probability that Z is greater than 2.0. • Stick with NORMAL for now. • Sometime we work with “Z” for the standard normal curve, sometimes we use “X” coordinates when the mean 0 or s.d. 1.0 • If there is one boundary, you may be interested in the area to the left, or the area to the right. • If you have two boundaries, you are usually interested in the area between (inside), but sometimes you want the area outside. • After telling BELL which area you want, give the boundary or boundaries. • The result is stored in a memory location named “P”, which you can use in later calculations. Using X instead of Z In this example, we’ll explore “real-world” numbers. For example, college males have heights normally distributed with a mean of about 70 inches and a standard deviation of 2.8 inches. What is the probability that a randomly chosen blind date is over 6 feet (72 inches) tall? There is about a 23.7% chance that a randomlychosen male college student is over six feet tall. Once again, the result is saved in a named memory “P”. “Going the other way” Sometimes we know an area/probability, and we want to know what X or Z value traps that area to the left or right. Sometimes we even have an “inside” area, centered around the mean, and we want to know what values trap that area. If these are Z values, we sometimes refer to these as Z* or Zc or Z/2. We often refer to numbers like this as critical values. Confirm Empirical rule 95% is 2 Do 2 ’s trap 95%? • Pretty close. • Actually, it is more like 1.96 standard deviations. • “Close Enough!” The length of a human pregnancy is normally distributed with a mean of 272 days with a standard deviation of 9 days a) State the random variable b) Find the probability of a pregnancy lasting more than 280 days. c) Find the probability of a pregnancy lasting less than 250 days. d) Find the probability that a pregnancy lasts between 265 and 280 days. e) Find the length of pregnancy that 10% of all pregnancies last less than. f) Suppose you meet a woman who says that she was pregnant for less than 250 days. Would this be unusual and what might you think? SAT: =514, =117, normally distributed a) State the random variable. b) Find the probability that a person has a mathematics SAT score over 700. c) Find the probability that a person has a mathematics SAT score of less than 400. d) Find the probability that a person has a mathematics SAT score between a 500 and a 650. e) Find the mathematics SAT score that represents the top 1% of all scores. Section 6.4: Assessing Normality 1. What is the source of variation in the population? If it is lots of different factors, each adding or subtracting, then the distribution is probably normal. 2. Histogram: should roughly be bell-shaped 3. Outliers: should not be more than 1. Use the 1.5*IQR rule. 4. Normal Probability Plot: if the points lie close to a straight line, data is approximately normal. Make Histogram • Enter Data • Clear out old plots! Both STAT plots and Y= plots. • Set up a plot, choose histogram, identify the data. • Zoom 9 Use Boxplot to identify outliers • Don’t forget to clear out old plots! • Create a Boxplot • Chose the fourth type, not the fifth type suggested by the book. It uses the 1.5*IQR rule to show outliers. • Zoom 9 Normal Probability Plot • This is the sixth plot in the menu of STAT PLOT types. • You need to set up the correct window on which to graph. Click on WINDOW. You need to set up the settings for the x variable. Xmin should be . Xmax should be 4. Xscl should be 1. Ymin and Ymax are based on your data, the Ymin should be below your lowest data value and Ymax should be above your highest data value. Yscl is just how often you would like to see a tick mark on the y-axis. • Press GRAPH • If close to a straight line, this suggests normality. Kiama Blowhole Skewed right, not normal Outliers: two, suspicious. Conclusion: not normal Curved, not straight line IQ scores Look bell shaped No outliers Conclusion, probably normal looks linear Section 6.5: Sampling Distribution and the Central Limit Theorem • Statistical Inference: to make accurate decisions about parameters from statistics • Sampling Distribution: how a sample statistic is distributed when repeated trials of size n are taken. Sampling Distribution • Suppose you have a random variable that has a population mean, , and a population standard deviation, . If a sample of size n is taken, then the sample mean 𝑥, has a mean 𝜎 𝜇𝑥 = 𝜇 and standard deviation of 𝜎𝑥 = . 𝑛 Central Limit Theorem • If the random variable has a normal distribution, 𝑥 will be normally distributed. • If the random variable has any distribution, the distribution of 𝑥 will become normally distributed as n increases. • How big does n have to be? It depends on the shape of the original distribution, but around 30 the sampling distribution usually gets pretty close to normal. The age that American females first have intercourse is on average 17.4 years, with a standard deviation of approximately 2 years. This random variable is not normally distributed, though it is somewhat mound shaped. a) State the random variable. b) Suppose a sample of 35 American females is taken. Find the probability that the mean age that these 35 females first had intercourse is more than 21 years. Could the population mean have increased from the 17.4 years that was stated in the article? Could the sample not have been random, and instead have been a group of women who had similar beliefs about intercourse? These questions, and more, are ones that you would want to ask as a researcher