Handout 4 Measures of Central Tendency and Variation.doc
advertisement

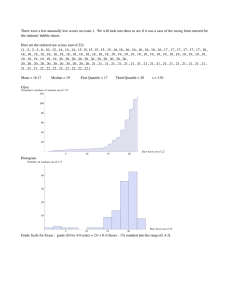
Data Setting: A graduate student in Psychology was asked to grade 40 final exams, selected at random from several large sections of an introductory course. The resulting scores are found below. 77 84 91 50 75 68 92 74 81 92 86 96 61 37 80 84 83 52 60 75 95 62 83 85 78 98 83 73 100 71 87 81 85 79 64 71 85 78 81 65 The professor for the class asked her how the students performed? Unfortunately, the graduate student found that looking at the list of scores was about as informative as looking at a scrambled set of letters. To get information out of the data, she needed to summarize the data. So, how should she go about summarizing the scores on the test? Measures of Central Tendency Measures of central tendency, or more simply measures of center, indicate where the center or most typical value of a data set lies. Three common measures of central tendency are the arithmetic mean (mean), median, and mode. The mean is the sum of the observations divided by the number of observations. We use x to denote sample mean and to denote population mean. Example The following are salaries for four randomly selected employees at Microsoft. $30,000 x $35,000 $32,500 $36,000 30,000 35,000 32,500 36,000 $33,375 4 The median of a set of observations is defined to be the middle value when the observations are arranged from lowest to highest. If the number of observations is odd, then the median is the observation exactly in the middle of the data set. If the number of observations is even, then the median is the mean of the two middle observations in the ordered list. Example Find the median for the sample of four salaries from Microsoft. First put the salaries in order: $30,000 $32,500 $35,000 $36,000 Median = 32,500 35,000 2 $33,750 The mode is the value that occurs most frequently in a data set. There can be more than one mode. When no value is repeated, we say there is no mode. Example Find the mode for the following test scores 84 89 82 91 86 84 The mode is 84. Which measure of central tendency do we use for a given data set? For qualitative data, the mode is the only one of the three that makes sense. For quantitative data, mean or median is often preferred over the mode as a measure of center because the value that occurs most frequently may not necessarily be located near the center of the data set. If there are outliers in the data, median is preferred over the mean as the mean can be misleading when outliers are present. If there are no outliers, the mean is often the preferred choice because it has some nice properties, which will be important in making inferences later in this course. A weighted mean is the mean of a data set whose entries have varying weights. A weighted mean is given by x ( x w) w where w is the weight of each entry x. Example In this class, your grade is determined from the following sources: 20% from exam 1, 20% from exam 2, 25% from the final exam, 15% from lab, 15% from homework, and 5% from the project. If you end up with the following scores, what is your final average in this class? Source Exam 1 Exam 2 Final Exam Lab Homework Project Score, x 84 75 72 90 100 85 x Weight, w .2 .2 .25 .15 .15 .05 w =1 ( x w) 82.55 82.55 w = 1 xw 16.8 15 18 13.5 15 4.25 ( x w) =82.55 Measures of Variability Measures of central tendency provide only a partial description of a quantitative data set. The description is incomplete without a measure of the variability, or spread, of the data set. For example, consider the following three data sets, which contain tests scores for students in three different classes. C1 C2 C3 50 50 70 Test Scores 60 70 73 74 73 74 80 76 76 Mean Median 90 100 77 100 77 80 75 75 75 75 75 75 The three data sets all have the same center but where they differ is in terms of variation in the scores. Three common measures of variability are the range, inter-quartile range, variance, and standard deviation. The range of a data set is equal to the largest measurement minus the smallest measurement. Example Calculate the range for class 1 scores. Range = 100 – 50 = 50 Although the range is easy to compute, it is sensitive to outliers. The inter-quartile range (IQR) of a set of measurements is defined to be the difference between the 75th percentile and the 25th; that is, IQR=75th percentile(third quartile) – 25th percentile(first quartile) To calculate the first and third quartiles 1. Arrange the observations in increasing order and locate the median in the ordered list of observations. 2. The first quartile is the median of the observations whose position in the ordered list is to the left of the location of the overall median. 3. The third quartile is the median of the observations whose position in the ordered list is to the right of the location of the overall median. Here are examples that show how the rules for the quartiles work for both odd and even numbers of observations. Example Finding the quartiles: odd number of observations. Here are the travel times in minutes for 15 workers in North Carolina, chosen at random by the Census Bureau: 30 20 10 40 25 20 10 60 15 40 5 30 12 10 10 Order the data : 5 10 10 10 10 12 15 20 20 25 30 30 40 40 60 Median=20 First quartile = 10 Third Quartile= 30 Example Finding the quartiles: even number of observations. Here are the travel times to work for 20 New York Workers. 5 10 10 15 15 15 15 20 20 20 | 25 30 30 40 40 45 60 60 65 85 Location of the median is denoted by the vertical bar. Median = 22.5 First quartile = 15 Third quartile = 42.5 The IQR does not provide a lot of useful information about the variability of a single set of measurements, but it can be quite helpful in comparing the variability of two or more data sets. Unlike the range, the IQR is not sensitive to outliers. The sample variance for a sample of n measurements is equal to the sum of the squared distances from the mean divided by (n - 1). In symbols, using s2 to represent the sample variance, s2 = ( x x ) 2 n 1 In calculating s2, we divide by (n – 1) instead of n to get a better estimate of the population variance Using n in the formula for s2, we tend to underestimate The sample standard deviation, s, is defined as the positive square root of the sample variance, s2. Example Calculate s2 and s for the class 1 scores x xx 50 60 70 80 90 100 -25 -15 -5 5 15 25 (x x) 0 s2 = ( x x ) n 1 s= 2 ( x x )2 625 225 25 25 225 625 2 (x x) 1,750 1750 350 5 350 18.708 Variance and Standard deviation are useful for comparing variability in two data sets. The data set with the larger variance, or standard deviation, exhibits more variation in the data. Standard deviation has the advantage over variance in that it provides a measure of variability in the same units as the original data. Thus, the standard deviation for a set of incomes would be in dollars whereas the variance would be in dollars2. Standard deviation and variance are sensitive to outliers. Standard deviation can be used in conjunction with the mean to describe the variability in a single data set. Empirical Rule: For a distribution that is approximately bell-shaped, Approximately: 68% of the observations fall within one standard deviation of the mean. 95% of the observations fall within two standard deviations of the mean. 99.7% of the observations fall within three standard deviations of the mean.