courses:cs240-201601:cfg-pda.pptx (274 KB)
advertisement
")
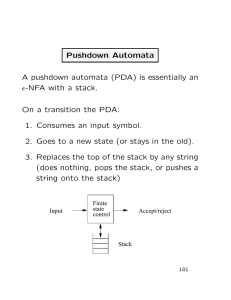
Equivalence of CFGs and PDAs
A language is context free if and only if
some pushdown automaton recognizes it
• As usual with “if and only if” theorems, there
are two clauses (directions) to prove
– If a language is context free, then some pushdown
automaton recognizes it
– If a pushdown automaton recognizes some language,
then it is context free
Only If (CFG to PDA)
• Let L = L(G) for some CFG G = (V,, P,
S)
• Idea: have PDA A simulate leftmost
derivations in G, where a left-sentential
form (LSF) is represented by:
1. The sequence of input symbols that A has
consumed from its input, followed by…
2. As stack, top left-most
Example: If (q, abcd, S) * (q, cd, ABC),
then the LSF represented is abABC
Moves of A
• Place $ and the start variable on the stack
• Repeat:
– If a terminal a is on top of the stack, then if the string is in
the language there will be an a waiting on the input. A
consumes a from the input and pops it from the stack
• The LSF represented doesn't change!
– If a variable B is on top of the stack, then PDA A has a
choice of replacing B on the stack by the body of any
production with head B
• Non-deterministic!
– If $ is on top of the stack, enter the accept state and
accept if all input has been read
Notation
(r,xyz) Î δ(q,a,s)
a,s
• When
– q is the current state
– a is the next input symbol
– s is on the top of the stack
a,s
xyz
z
ε, ε
• Do the following:
– Read a
– Pop s
– Push xyz
ε, ε
x
y
Defining the PDA
• Define PDA A as follows:
– Q = {qstart, qloop, qaccept} U E
• E is the set of states needed to implement the notation
• qstart is the start state
– contains the terminal symbols of the grammar
– contains all terminal and non-terminal symbols from the
grammar
– F =qaccept
– is defined as follows:
• For each production X in the grammar, create a move
(qloop,,X) = (qloop,)
• For each terminal symbol a in the grammar, create a move
(qloop,a,a) = (qloop, )
• To handle $ on the top of the stack, create a move (qloop,,$) =
(qaccept,)
Example
S a | aS | bSS | SSb | SbS
PDA A = ({qstart,qaccept,qloop,},{a,b},{S,a,b}, , qstart, qaccept, S)
is defined as
(qstart,,) = (qloop, S)
(qloop, , S) = {(qloop,a), (qloop,aS), (qloop,bSS), (qloop,SSb),
(qloop,SbS)}
(q,a,a)
= (qloop,)
(q,b,b)
= (qloop,)
(qloop,, $) = (qaccept,)
Processing of baa
stack
qstart
baa
-
qloop
baa
S$
qloop
baa
qloop
move
(qstart,,) = (qloop,S$)
(qloop,,S) = (qloop,bSS)
Generate bSS
bSS$
(qloop,b,b) = (qloop,)
Match b
aa
SS$
(qloop,,S) = (qloop,a)
Generate a
qloop
aa
aS$
(qloop,a,a) = (qloop,)
Match a
qloop
a
S$
(qloop,,S) = (qloop,a)
Generate a
qloop
a
a$
(qloop,a,a) = (qloop,)
Match a
qloop
$
qaccept
-
-
b
match
(qloop,$,) =
(qaccept,)
S
- accept -
Input:
b
S
S
a
a
a
match
input
match
state
a
Let’s try an example together:
R XRX | S
S aTb | bTa
T XTX | X | ε
Xa|b
R XRX | S
S aTb | bTa
T XTX | X | ε
Xa|b
The PDA
N = {qstart,qaccept,qloop,},{a,b},{a,b,R,S,T,X}, , qstart,
{qaccept}, R)
P=
(qstart,,) = {(qloop,R$)}
(qloop,,R) = {(qloop,XRX), (qloop,S)}
(qloop,,S) = {(qloop,aTb), (qloop,bTa)}
(qloop,,T) = {(qloop,XTX), (qloop,X), (qloop,)}
(qloop,,X) = {(qloop,a), (qloop,b)}
(qloop,a,a) = (qloop,)
(qloop,b,b) = (qloop,)
(qloop,,$) = (qaccept,)
d{q,e,R} = {(q,XRX), (q,S)}
d{q,e,S} = {(q,aTb), (q,bTa)}
d{q,e,T} = {(q,XTX), (q,X), (q,e)}
d{q,e,X} = {(q,a), (q,b)}
d{q,a,a} = (q,e)
d{q,b,b} = (q,e)
(q,aabba,R)
=(q,XRX)
(q,aTb)
Using the PDA
|- (q,aabba,XRX)
Moves
{q,,R}
|- (q,aabba,aRX)
|- (q,abba,RX)
|- (q,abba,SX)
|- (q,abba,aTbX)
{q,,X} = (q,a)
{q,a,a} = (q,)
{q,,R} = (q,S)
{q,,S} =
|- (q,bba,TbX)
|- (q,bba,XbX)
|- (q,bba,bbX)
|- (q,ba,bX)
|- (q,a,X)
|- (q,a,a)
{q,a,a} = (q,)
{q,,T} = (q,X)
{q,,X} = (q,b)
{q,b,b} = (q,)
{q,b,b} = (q,)
{q,,X} = (q,a)
Using the PDA
Matched
a
a
a
aa
aa
aa
aab
aabb
aabb
aabaa
Derivation
(q,aabba,R)
(q,aabba,XRX)
(q,aabba,aRX)
(q,abba,RX)
(q,abba,SX)
(q,abba,aTbX)
(q,bba,TbX)
(q,bba,XbX)
(q,bba,bbX)
(q,ba,bX)
(q,a,X)
(q,a)
(q,a,a)
(q,,)
|- (q,aabba,XRX)
|- (q,aabba,aRX)
|- (q,abba,RX)
|- (q,abba,SX)
|- (q,abba,aTbX)
|- (q,bba,TbX)
|- (q,bba,XbX)
|- (q,bba,bbX)
|- (q,ba,bX)
|- (q,a,X)
|- (q,a,a)
|- (q,,)
(q,,R) =(q,XRX)
(q,,X) = (q,a)
(q,a,a) = (q,)
(q,,R) = (q,S)
(q,,S) = (q,aTb)
(q,a,a) = (q,)
(q,,T) = (q,X)
(q,,X) = (q,b)
(q,b,b) = (q,)
(q,b,b) = (q,)
(q,,X) =
(q,a,a) = (q,)
R
XRX
aRX
aSX
aaTbX
aaXbX
aabbX
aabba
Sentential forms
Using the PDA
R
Matched
(q,aabba,R)
(q,aabba,XRX)
(q,aabba,aRX)
(q,abba,RX)
(q,abba,SX)
(q,abba,aTbX)
(q,bba,TbX)
(q,bba,XbX)
(q,bba,bbX)
(q,ba,bX)
(q,a,X)
a
a
a
aa
aa
aa
aab
aabb
aabb
aabba (q,a,a)
(q,,)
|- (q,aabba,XRX)
|- (q,aabba,aRX)
|- (q,abba,RX)
|- (q,abba,SX)
|- (q,abba,aTbX)
|- (q,bba,TbX)
|- (q,bba,XbX)
|- (q,bba,bbX)
|- (q,ba,bX)
|- (q,a,X)
|- (q,a,a)
|- (q,,)
X
a
R
X
a
S
a
T
b
X
b
a a b b a
Converting from PDA to CFG
•
•
•
•
A PDA consumes a character
A CFG generates a character
We want to relate these two
What happens when a PDA consumes
a character?
– It may change state
– It may change the stack
Converting from PDA to CFG
continued
• Suppose X is on the stack and a is read
• What can happen to X?
– It can be popped
– It may be replaced by one or more other stack symbols
– And so on…
– The stack grows and shrinks and grows and shrinks …
– Eventually, as more input is consumed, X must be popped
(or we’ll never reach an empty stack)
– And the state may change many times
– We must track all of this!
PDA to CFG
• Assume L = N(P), where P =
(Q,,,,qstart,qaccept),
– qaccept is empty (accept by empty stack)
– Start variable is Aqstart,qaccept
• Key idea: units of PDA action have the net effect of
popping one symbol from the stack, consuming
some input, and making a state change
• The CFG variable Aq,p generates exactly those
strings w such that P can read w from the input, pop
one symbol from the stack, and go from state q to
state p
– More precisely, (q,w,Z) * (p,, )
– As a consequence of above, (q,wx,Z ) * (p,x,) for any x and
PDA to CFG
• Convert PDA P into CFG G
• A priori step:
– Modify P to be a normalized PDA N so that:
• It has a single accept state, qaccept
– Create -transitions from old accept states to this new accept state
• It empties the stack before accepting
– Push a special character $ on the stack in the start state (introducing a new
start state in the process)
– Introduce a new temporary state qtemp that replaces qaccept, which has
transitions popping all characters from the stack (except $)
– Introduce transition:
qtemp ,$→
qaccept
Continued…
• Each transition either pushes a symbol onto the
stack or pops one off the stack, but it does not do
both at the same time
– Replace a simultaneous pop/push move with a 2-transition
rule that goes through a new state
• E.g.
qi
a,b → c
qj
(read a from input, pop b from stack, push c)
• Introduce special state q’temp plus 2 transitions, one doing pop
and one doing push:
, → c
a,b →
qi
qj
q'temp
– Replace a transition that neither pops nor pushes with two
transitions that push and then immediately pop some newlycreated dummy stack symbol
qi
a, →
qj
qi
a, → X
q'temp
, X→
qj
Normalizing the PDA
EXAMPLE
L(N) = (ba + baa)*b) +
Original PDA
a,
b,X
,$
, $
a, X Y
Pure Push Pop
Make sure the stack is always active by replacing inactive stack moves
by a push followed by immediate pop of a dummy symbol
a,
b,X
,$
, $
a, D
b,X
, D
a, X Y
,$
, $
a, X Y
Pure Push Pop
Any move that replaces the top letter on the stack
should be changed into a pop followed by a push
a, D
a, D
b,X
b,X
, D
,$
, D
, $
,$
a, X Y
, Y
, $
a, X
Unique Accept State
Turn off original accept states and connect to a new
accept state
Remember: each
move must either
push or pop from
the stack)
a, D
b,X
, D
,$
, D
a, D
, $
b,X
, Y
, D
a, X
, D
,$
, Y
, $
a, X
, D
Empty Stack
Make sure the stack empties its content by adding a
new dummy empty stack symbol and new start/accept
states
, D
, D
, ¢
a, D
b,X
, D
,¢
,$
, Y
, $
a, X
, D
, D
, $
, X
, Y
PDA to CFG
INTUITIVE DESCRIPTION
Consider normalized PDA N = (Q,,,,qstart,qaccept)
• Starts in qstart with an empty stack
• Ends in qaccept with an empty stack
– In general, can define the language Lpq, for any two states p,q Q which is
the language of all strings that start in p with an empty stack, and end in q
with an empty stack
• For each pair of states p and q, define a symbol Spq in
the CFG for the language Lpq
• Language of N is
Lqstart qaccept
Steps to process w Lpq
• Two possibilities:
1. During the processing of w the stack
becomes empty at some intermediate
state r
•
This means a word of Lpq can be formed by concatenating
a word of Lpr (which brought N from state p to state r with
an empty stack) and a word of Lrq (that took N from r to q)
2. Stack is never empty in the middle of N’s
transit from p to q in processing w
•
The first transition (from, say, p to p1) must have been a
push, and the last transition (from, say, q1 to q) must have
been a pop, and the pop popped exactly the symbol
pushed by the first transition from p to p1
• In other words, if the PDA read a from input
as it moved from p to p1, and read b as it
moved from q1 to q, then w =ayb, where y is
an input that causes the PDA N to start from
p1 with an empty stack and end in q1 with an
empty stack—i.e., y Lp1q1
• Formally, if there is a push transition (pushing
X onto the stack) from p to p1 (reading a) and
a pop transition from q1 to q (popping X and
reading b), then a word in Lpq can be
constructed from the expression aLp1q1b
• Note that either or both of a or b could be
The Construction
• For every state p, introduce the rule
App
• Empty string can always be considered as getting you from p to
p without doing anything to the stack, since nothing was read
• CONCATENATION RULE
– For the case where the stack empties in the
middle of transition from p to q, introduce, for all
states p, q, r of N, the rule
Apq AprArq
CONCATENATION RULE
Apq AprArq
Stack
height
Generated by Apq
Input string
p
r
q
Generated by Apr Generated by Arq
• RECURSION RULE
– For the case where the stack is never empty, for
any given states p, p1, q1, r of N, such that there is
a push transition from p to p1 and a pop transition
from q1to r (that push and pop the same symbol),
introduce an appropriate rule
– Formally, for p, p1, q1, r of N with the form
p
a, → X
p1
push X
q1
b, X →
pop X
introduce the rule
Apr aAp1q1b
r
RECURSION RULE
Apq aArsb
Stack
height
Generated by Apq
Input string
p
r
s
a
b
q
Generated by Ars
Formal Definition
FROM
SIPSER
• P = (Q,,,,q0,qaccept)
• Non-terminals of G are {Apq | p,q Q}
• Rules:
– For each p, q, r, s Q, t , and a,b , if (p,a, )
contains (r,t) and (s,b,t) contains (q,), put the rule Apq
aArsb in G
– For each p, q, r Q, put the rule Apq AprArq in G
– For each p Q, put the rule App in G
The Grammar
•
•
The rules for generating paths give a
grammar to generate all labels of such
paths
The grammar has non-terminals Aqr which
will generate all strings x that are
processed when passing from state q to
state r
Q: Under this assumption, what should the
production body (right hand side) for
the start variable S be?
The Grammar Symbols
A: S = Aqstartqaccept , where qstart is the start
state and qaccept is the final state
• In addition to this start variable, the other
variables are all Aqr for which there is a
path going from q to r that starts and
ends with an empty stack
Note that Sipser doesn’t require the extra condition that there be a path from q to r which
starts and ends with an empty stack—his method generates all possible combinations.
However, those pairs q,r for which no such path exists will create useless variables Aqr
which end up cluttering the grammar and making the construction extremely ugly, even on
the simplest PDAs. On the other hand, it is not obvious how one would determine a priori
which of the pairs don’t have such paths, which probably explains why Sipser didn’t
include this condition.
Grammar Rules
1. BASIS RULE : Add a production Aqq for
each state q in the PDA
2. CONCATENATION RULE : Add a production
Apr Apq Aqr for all p,q,r when Apr, Apq and
Aqr are all in V.
3. RECURSION RULE : Add a production Aps
aAqrb for all p,s,q,r when
–
–
Aps and Aqr are in V
Transitions (q,X) (p,a,), (s,) (r,b,X) for the same
stack symbol X exist in the PDA
Example
PDA in the normalized form:
(, X
), X
q
, $
r
, $
s
Q: What is the accepted language?
A: “CNP” = correctly nested parentheses,
including sets of pairs [e.g., ()(())]. The
number of X’s on the stack reflects how
deep the current nesting is.
(, X
), X
q
, $
r
, $
s
Q: What are the variables for the
equivalent grammar? What is the
start variable?
A: V = {Aqs , Aqq , Arr , Ass, Arq , Asq , Asr ,
Aqr, Ars}, S = Aqs
Are there any useless variables?
• We don’t need Arq , Asq , Asr because the paths go
in the wrong direction
• We don’t need Aqr or Ars because we can’t add or
remove $ while at r
– I.e., no transition where you both begin and end with an empty
stack
(, X
), X
q
, $
r
, $
s
Productions from the Base
Rule
Add a production Aqq for each state q in the PDA
• Empty string can always be considered as getting you
from p to p without doing any thing to the stack, since
(, X
nothing was read
), X
q
, $
r
, $
s
Aqq , Arr , Ass
V = {Aqs , Aqq , Arr , Ass}
Productions from the
Concatenation rule
Add a production Apr Apq Aqr for all p,q,r when Apr,
Apq and Aqr are all in V
• If you can get from some state p to another state p1 starting and
ending with the stack empty (regardless of stack activity in the
processing of moving from p to p1), and from q1 to q under the
same conditions, then combine paths to get a path from p to q.
Aqs Aqq Aqs | Aqs Ass
Aqq Aqq Aqq
Arr Arr Arr
Ass Ass Ass
q
(, X
), X
, $
r , $
s
V = {Aqs , Aqq , Arr , Ass}
Productions from the Recursion Rule
Add a production Aps aAqrb for all p,s,q,r when
–
–
Aps and Aqr are in V
Transitions (q,X) (p,a,), (s,) (r,b,X) for the same stack symbol X
exist in the PDA
• For any given states p, p1, q1, q of N, such that there is a push
transition from p to p1 and a pop transition from q1to q (that push
and pop the same symbol), i.e., there exist transitions (p,a,)
contains(p1,X) and (q1,b,X) contains (q,), put the rule Apq
aAp1q1b
Aqs Arr = Arr
Arr (Arr)
(q,,) contains (r,$) and (r,,$) contains (s,)
(r,(,) contains (r,X) and (r,),X) contains (r,)
(, X
), X
q , $
r
, $
s
Full Grammar
Aqs Arr | Aqq Aqs |
Aqs Ass
Arr | Arr Arr | (Arr)
Aqq | Aqq Aqq
Ass | Ass Ass
Simplifications
• Apparently Aqq and Ass are purely selfreferential, so there is no way to terminate
them—that is, no string can be derived from
them.
• We can therefore remove the variables Aqq,
Ass
Aqs Arr | Aqq Aqs | Aqs Ass
Arr | Arr Arr | (Arr)
Aqq | Aqq Aqq
Ass | Ass Ass
Becomes:
Aqs Arr | Aqs
Arr | Arr Arr | (Arr)
Showing that the grammar
works…
Aqs Arr | Aqs
Arr | Arr Arr | (Arr)
Rename variables to get:
ST |S
T | TT | (T)
S isn’t needed as its whole purpose is to get you
to T (i.e. first compound production S T | S)
Note: S as Start Symbol is still helpful.
So the final (cleaned up) grammar is
T | TT | (T)
Another Example
• Consider the language L = {wcwR | w
{a,b}*}. A non-normalized PDA for this
language is
a, a
a, a
s
b, b
c,
f
b, b
Convert to Normalized Form
a, a
a, a
s’
, $
b, b
1.
2.
c, D
s
qt
, D
f
,$
a
b, b
Create new start and accepting states
All transitions either pop or push except c, ;
change to 2 transitions that push and pop a
dummy symbol
Generate Grammar
a, a
a, a
c, D
s’
s
b, b
q
, D
f
a
b, b
1. Add start symbol and a production Aqq for
each state q in the PDA
S As’a, As’s’ , Ass , Aqq , Aff , Aaa
Generate Grammar
a, a
a, a
s’
, $
c, D
s
q
, D
f
,$
b, b
b, b
2. Add a production Apr Apq Aqr for all p,q,r
when Apr, Apq and Aqr are all in V
As’a As’s’As’a | As’aAaa
a
Generate Grammar
a,a
a, a
s’
, $
c, D
s
q
, D
f
b, b
3.
,$
a
b,b
Add a production Aps aAqrb for all p,s,q,r when Aps and Aqr are
in V and transitions (q,X) (p,a,), (s,) (r,b,X) for the same
stack symbol X exist in the PDA
As’a $Asf$ | AsfcAqq
Asf bAsfb |aAsfa
Final Grammar
Final grammar
S As’a
As’s’
Ass
Aqq
Aff
Aaa
As’a As’s’As’a
As’a As’aAaa
As’a Asf
Asf cAqq
Asf bAsfb
Asf aAsfa
More readable
Simplified
S T
R
U
V
W
X
T RT
T TX
T Z
Z cV
Z bZb
Z aZa
TZ
Z c
Z bZb
Z aZa
• R,U,V,W,X contribute only so can
be eliminated
• T RT and T TX then become T
T, which is obviously unnecessary
• S is superfluous because it only gets
you to T
• T is superfluous because it only
gets you to Z
Deterministic PDAs
• Intuitively: never a choice of move
– (q, a, Z) has at most one member for any q, a, Z
(including a = )
– If (q, , Z) is nonempty, then (q, a, Z) must be
empty for all input symbols a
• Why Care?
– Parsers, as in YACC, are really DPDA’s
– Thus, the question of what languages a DPDA can
accept is really the question of what programming
language syntax can be parsed conveniently
What’s YACC you say?
• Yacc is a computer program for the Unix
operating system. It is an LLR parser generator,
generating a parser, the part of a compiler that
tries to make syntactic sense of the source code,
specifically an LLR parser, based on an analytic
grammar written in a notation similar to BNF.
• “Yet Another Compiler-Compiler”
• If it’s in Wikipedia, it must be true!™
• https://en.wikipedia.org/wiki/Yacc
Some Language
Relationships
• Acceptance by empty stack is hard
for a DPDA
– Once it accepts, it dies and cannot accept any
continuation.
– Thus, N(P) has the prefix property: if w is in N(P),
then wx is NOT in N(P) for any x .
• However, parsers do accept by
emptying their stack
– Trick: they really process strings followed by a
unique endmarker (typically $) e.g., if they accept
w$, they consider w to be a correct program.
• If L is a regular language, then L is
a DPDA language
– A DPDA can simulate a DFA without using its
stack (acceptance by final state)
• If L is a DPDA language, then L is a
CFL (that is not inherently ambiguous)
– A DPDA yields an unambiguous grammar in
the standard construction
• Factoid: The class of languages accepted by
NPDAs is larger than those accepted by
DPDAs!
PDA more powerful than FA
Languages accepted by
nondeterministic PDA
Languages
accepted by FA
or NFA
Languages accepted by
deterministic PDA