Cove_Sampling_Paper.doc
advertisement

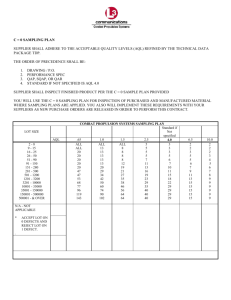
A SAMPLING STORY: CHAPTER 1 On the surface, sampling seemed pretty straightforward to Joe, the sole quality engineer at A.N.Y. manufacturing company. The plan they had been using had been in place since before he arrived and seemed to serve them well. However, when he was asked to meet with suppliers to review and suggest modifications, he realized that he would need a bit of studying in order to talk confidently about sampling. Joe made up his mind to use the ASQ Section meeting to network and discuss sampling. As the Section Meeting was winding down, Joe managed to corner three colleagues: Ted, a seasoned quality tech at an electronics assembly plant; Maria, a quality manager for the medical supply company hosting the evening’s meeting; and Pete, a young engineering professor at a local university who had recently been asked to start teaching some courses on quality engineering. “Well, guys, I was hoping to pick your brains. I need to become an expert in sampling in the next few weeks, and I was hoping you could give me some advice.” “Fire away!” “First,” said Joe, “Why do sampling at all?” “We do sampling as a quick check of quality before we ship,” replied Maria. “Checking just a few items saves a lot of money over testing every item. Besides, many of the medical devices we produce are sterile, one-use devices. If we tested them all, we wouldn’t have any left to ship!” “In our case, it is a question of time,” said Ted. “We receive components in lots 10,000 or more. Combine that with the fact that they only cost pennies each, and there is no way to justify spending the time and money to test them all.” “That answers part of my question,” shot back Joe, “but I also was wondering why not use more powerful techniques, like control charts or cpk calculations? We could just get those numbers from our suppliers and not worry about inspections at all.” “Perhaps, but there are still some reasons to do sampling,” warned Maria. “What if the supplier’s process goes out of control, but they don’t catch it immediately? What if a poorly trained technician there misreads an instrument? What if they don’t really know how to handle the calculations? What if the product is damaged during shipment? And of course there is always the possibility that some dishonest engineer or manager would fudge the numbers to hide a problem.” “Many of our tests are go/no-go tests,” added Ted. “ It’s easier to train inspectors when they just have to make a yes/no decision, but it limits the statistics you can perform on the data.” “So, if I’m hearing you right, sampling is quick, inexpensive inspection method designed to reject bad shipments,” summarized Joe. “Or more specifically, to accept good shipments,” interjected Pete, who had been listening quietly up to this point. “Huh? Isn’t that the same thing – rejecting bad shipment and not rejecting good shipments?” questioned Joe. “I’m sure you have heard this before somewhere,” Pete began, “but it is something I have to keep repeating to my students. With sampling, there is some chance of accepting bad lots or rejecting good lots. Most sampling plans are designed to make it highly likely to accept a good lot. The odds of rejecting a good lot, generally denoted and called the producer’s risk or a Type I error, are usually only a few percent. Unfortunately, this means that is it quite likely you will accept a lot that is out of spec. This chance, denoted and called the consumer’s risk or a Type II error, can be quite large, especially if the lot is only a little out of spec.” “I knew I should have paid more attention in my college stats class. At the time it just seemed to theoretical that I couldn’t really get into it,” Joe admitted/ “Let’s move on a bit. Our sampling plan says something about ‘normal, level II inspection.’ What is that all about?” “It has to do with the number of samples drawn, and the criteria for rejecting lots, but I don’t know the details offhand.” replied Ted. “How about multiple sampling plans?” continued Joe. “I am having enough trouble with basic sampling plans – the idea of multiplying my confusion isn’t very appealing.” The awkward silence was a big hint to Joe that no one else knew much more than he did. “Okay. One last, more specific problem. One of our supplies comes in lots of 5,000 and we test for both major defects, at an AQL of 1.0, and minor defects, at an AQL of 25. The system I inherited has us draw 200 pieces and count both the major and minor defects. The original tables suggested only 50 pieces for the minor defects and rejecting with 22 defects. Since we draw four times as many samples, we have been multiplying the rejection number by four as well. “I’m having my doubts about the plan, on three fronts. First, if we continue to look at 200 pieces for the minor defects, should the reject level be kept at the original 22, or increased fourfold to 88, or should it be somewhere else? How should I analyze the historic data that we have already collected using this system? Second, should we switch in the future from 200 down to 50 pieces for the minor defects? And third, however many pieces we inspect, may the samples for major and minor defects overlap, or must they each be drawn separately?” “Boy, that is a tough one. I don’t think we’ve ever run into such a problem, but then we generally only check for major defects, not minor defects, too,” responded Ted “As to where to set the reject level, offhand 88 sounds better than 22, but I have a sneaking suspicion that neither is correct,” said Pete. “As to the question of drawing one or two samples, in principle it is always safer to draw two different samples, so that is what I would suggest. Perhaps I could get some of my better engineering students to tackle this for extra credit.” “Down the hall I know we have an extra copy or two of the current tables from ASQ,” said Maria, switching into manager mode. “We can meet next month to discuss this further. Ted can look into ‘normal, level II inspection,’ Joe can look into ‘multiple sampling’, and Pete can do some calculations on the sample size and rejection level for the minor defects.” CHAPTER 2 Ted got off to a good start. He dug out a reference that explained that the inspection level, together with the sample size, determines the number of pieces drawn in the sample. General Level II is the most common choice – Level I draws a smaller sample and Level III draws a larger sample. Special Levels S-4, S-3, S-2, and S-1 draw still smaller samples. Fewer pieces means less time and expense, but also means there is an increased level of risk. Ted was expecting a simple relationship between the stringency of the inspection (normal, tightened, and reduced), but he was disappointed. Instead, he spent a couple hours digging through the OC curves and data in the official ANSI/ASQC Z1.4-1993 manual. He came to realize that there were many ways to present the results, and that the different uses required different approaches. 51 -9 0 91 -1 50 15 128 0 28 250 0 50 11, 20 1, 0 20 13, 20 3, 20 0 110 10 ,0 00 ,0 01 -3 35 5, 00 ,0 01 0 -1 15 50 0, ,0 00 00 150 0, 00 0 50 0, 00 0+ Defects per 100 Units He decided to use the case with an AQL of 1 at Normal, Level II inspection as a starting point. First, he looked at the tabulated values for the operating curves (Tables X-A-1 through X-R-1; some of which is summarized in Table VII-B) and from these he could look up the defect rate which would be accepted 95% of the time and 5% of the time and plotted these. As expected, tightened inspection increased the odds of rejecting a shipment. Concentrating on normal inspection, Ted was a little surprised that small lots had 100 to have less than 0.4% 5% Accepted nonconformities to be 95% Accepted accepted 95% of the time, but Normal 10 large lots could have up to Tightened 1.25% nonconformities. On the other hand, small lots had 1 to have over 20% Normal nonconformities to be Tightened rejected 95% of the time, while large lots needed no 0.1 more than 2.5% to virtually ensure rejection. In other words, large lots are both easier to accept and easier to reject. Lot Size He also realized that tightened inspection didn’t necessarily ensure better quality. For example, he considered a product with 5% nonconformities – five times the AQL of 1. If it was a small shipment on tightened inspection, he could see from his graph that it had a greater than 5% chance of being accepted (actually close to 25%). However, a large shipment of the same quality checked at normal inspection had less than 5% chance of being accepted (actually well under 1%). The same general pattern held for other AQL’s. … Joe discovered that multiple sampling wasn’t as bad as he feared. With single sampling, a fixed number of pieces are drawn and tested, and the lot is accepted or rejected based on the results. With double sampling, a smaller number of pieces are drawn and tested. If too many defects are found, the lot is rejected and if few defects are found, the lot is accepted. However, if the number of defects is somewhere in between, a second sample is drawn to determine if the lot is accepted or rejected. On average, fewer pieces are drawn with single sampling, but occasionally more are needed. Multiple sampling extends this idea, drawing up to seven samples before ultimately accepting or rejecting the lot while lowering the average number of pieces inspected. Joe even found references to continuous sampling, where a decision could be made after each piece was drawn! Joe looked at the tables for his lot size of 5000 and an AQL of 1. For single sampling, he needed 200 pieces. For double sampling, he only needed 125, but he might have to do that twice. For multiple sampling, he would draw just 50 pieces for the first round of testing, but he might need to go to 350 pieces before ultimately knowing what to do with the lot. Joe realized that these more complicated plans required much more attention by his inspectors, who would be required to make extra decisions along the way. It would also be harder to budget resources, since they wouldn’t know just how much testing they would need to do. Still, the allure of less testing was enticing. … As Professor Pete and his students started looking at ANSI/ASQC Z1.4-1993, they were confused by the concept of an AQL over 100 [i.e. more than 100 defects per 100 pieces] until they realized that there could easily be more than one defect per piece. They were also a little confused by the double headed arrows in Table II-A until they realized they were just single headed arrows that had been poorly printed so that they ran together. The first problem they tackled was deciding where to put the reject level if Joe’s company kept using 200 samples for minor defects. They put together a spreadsheet to help them with the calculations needed to analyze Joe’s dilemma. After a little research and a little work on the spreadsheet they concluded that the tables were based on the Poisson distribution. At the top of spreadsheet, they set up a spot where they cold enter the defect rate and the sample size. The next line calculated the average number of defects expected, u = AQL * sample size / 100. This was accomplished with the equation =B1*B2/100 in cell B3 of the spreadsheet. Below this, a table was set up, starting with a column for the possible number of defects. The probability of getting exactly that number of defects was calculated from the Poisson distribution. Fortunately, the equation is built into Excel, so =POISSON($A6,$B$3,FALSE) was typed into cell B7 and copied to the cells below. Finally, they wanted the cumulative probability of getting no more defects than listed in the first column. This was accomplished by putting the equation =POISSON($A6,$B$3,TRUE) in cell C7 and copying it downward. (Later, they repeated this process in additional columns, so that they could examine several different sample sizes or AQL’s simultaneously.) With this spreadsheet, they could then calculate the Defects per 100 25 likelihood of accepting a sample for any acceptance number or sample quality, not just Sample Size 50 those specifically listed in the tables. Using their spreadsheet for Joe’s original problem, they explored the situation with a sample size of 50, and an acceptance number of 21. When the actual defect rate was equal to the AQL of 25, then there was approximately a 1% chance of rejecting the lot. Furthermore, there was a 50% chance of rejecting a lot with 44 defects per hundred, and a 99% chance of rejecting a lot with 70 defects per hundred Then they looked at a sample size of 200 pieces and the reject level set at 88, as Joe’s company had been doing,. Pete discovered that for good lots, the larger sample size meant a greatly improved chance of accepting a good. For slightly bad lots (from 25 to 44 defects per hundred) the larger sample size meant a poorer job of detecting a bad lot. However for really bad lots (over 44 defects per hundred) then the larger sample size again was an improvement, leading to a greater chance of rejecting the lot. Pete checked a one more option. A reject level of 67 gave approximately the same 1% chance of rejecting the good lot. They summarized their Average Defects # defects found 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 12.5 Odds 0.000 0.000 0.000 0.001 0.004 0.009 0.020 0.035 0.055 0.077 0.096 0.109 0.113 0.109 0.097 0.081 0.063 0.047 0.032 0.021 0.013 0.008 0.004 0.002 0.001 0.001 Cumulative Odds 0.000 0.000 0.000 0.002 0.005 0.015 0.035 0.070 0.125 0.201 0.297 0.406 0.519 0.628 0.725 0.806 0.869 0.916 0.948 0.969 0.983 0.991 0.995 0.998 0.999 0.999 Defects (per 100) Ac = 21 Ac = 66 Ac = 87 Sample = 50 Sample = 200 Sample = 200 <25 good better best 25 to 44 better best good Odds of acceptance findings in a table and realized there was no simple answer. The current plan worked pretty well. Dropping the acceptance number to 66 slightly increased the odds of rejecting a good lot, but enhanced the odds of rejecting a bad lot. Going to the smaller sample size was not unexpectedly the worse at discriminating between good and bad lots, but it offered a great savings in testing. 1.000 0.800 0.600 0.400 0.200 0.000 0 25 50 Defects per 100 >44 good best better 21/50 67/200 87/200 With this question answered, he spent a little time thinking about the question of how to draw the samples to begin with. The overlap between major and minor defects was the key. After a bit of thought, Pete concluded that using the same sample for both major and minor defects could be a problem, but it was unlikely to be a major concern unless either 1) the sample wasn’t random to begin with, 2) there were a lot a defects, 3) there was a strong correlation between occurrences of major and minor defects, or 4) the sample size was small. However, given Pete’s firm belief in Murphy’s Law, he knew that problems would pop up. With this in mind, he decided to forgo any detailed explanations and simply tell Joe that it shouldn’t have caused any major problems, but suggest that two separate samples be drawn in the future. Chapter 3 At the next month’s Section Meeting, they met and compared notes. They all agreed that sampling was more subtle and complicated than they first thought. “Thanks so much for your help,” said Joe as they were wrapping up the discussion. “I’m going to have to go and write this down before I forget. At a very basic level, we know that if a product has a defect rate equal to or less than the AQL, then you have a very good chance of accepting the lot. The Z1.4 standards have the advantage that they are well established and well known. “On the other hand, even when keeping the same level of inspection, the odds of accepting a lot within spec can vary considerably. The AQL correlates roughly with the quality of the lot, but the only way to know the actual odds of accepting or rejecting lots with specific defect rates is to know the tables inside and out, including the OC curves. Or buy some good software. In any case, I know I’ll be much be better prepared to talk with our suppliers next week!” 75