Database Systems (資料庫系統) December 13, 2004 Chapter 15
advertisement
 December 13, 2004 Chapter 15")
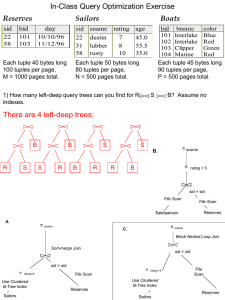
Database Systems (資料庫系統) December 13, 2004 Chapter 15 By Hao-hua Chu (朱浩華) 1 Announcement • Assignment #9 is due next Thursday. • Read chapter 16 for next lecture. 2 Cool Ubicomp Project Hyperdragging (Sony, 1999) • Not enough working surface on your computer screen .… • No shared working surface when collaborating with other people …. 3 A “Typical” Query Optimizer Chapter 15 4 How does a query optimizer work in general? • Decompose a SQL query (can have nested queries) into query blocks (without nested queries). • Translate each query block into relational algebra expressions. • Optimize the relational algebra expression, one query block at a time: – Enumerate a subset of possible evaluation plans (also call explore the plan space) – Estimate the cost (disk I/Os) of each explored plan using system catalogs and statistics – Pick the plan with the least estimated cost 5 Decompose a Query into Query Blocks (Example) SELECT S.sid, MIN(R.day) FROM Sailors S, Reserves R, Boats B WHERE S.sid=R.sid AND R.bid=B.bid AND B.color=‘red’ AND S.rating = (SELECT MAX(S2.rating) FROM Sailors S2) GROUP BY S.sid HAVING COUNT(*) > 1 SELECT S.sid, MIN(R.day) FROM Sailors S, Reserves R, Boats B WHERE S.sid=R.sid AND R.bid=B.bid AND B.color=‘red’ AND S.rating = Reference to the nested block GROUP BY S.sid HAVING COUNT(*) > 1 SELECT MAX(S2.rating) FROM Sailors S2 Nested block Outer block 6 Optimizing A Query Block • Query blocks are optimized one block at a time. – Nested blocks are usually treated as calls to a subroutine, made once per tuple in the outer block. • This is an over-simplification, but good enough for now. • To estimate I/O cost, the optimizer estimates the size of (intermediate) results. – – – System catalogs about the lengths of (projected) fields Statistics about referenced relationships (file size & # tuples) Available access methods (indexes & selection conditions), for each relationship in from clause 7 Translate Query Block into Relational Algebra Expr (1) SELECT S.sid, MIN(R.day) FROM Sailors S, Reserves R, Boats B WHERE S.sid=R.sid AND R.bid=B.bid AND B.color=‘red’ AND S.rating = Reference to the nested block GROUP BY S.sid HAVING COUNT(*) > 1 • Assume that GROUP BY and HAVING are also operators. πS.sid,MIN(R.day) ( HAVING COUNT(*)>2 GROUP BY S.sid ( σ S.sid=R.sid AND R.bid=B.bid AND B.color=‘red’ AND S.rating=value_from_nested_block ( SailorsχReserves χBoats)))) 8 Translate Query Block (2) • Try to simplify query block further into σπχ expression. – Why do this? Easier to find equivalent σπχ expressions (alternative plans), and they may have cheaper costs. • How about GROUP BY and HAVING? – They are carried out after the result of σπχ. – Add attributes specified in GROUP BY and HAVING into projection list. πS.sid,MIN(R.day) ( HAVING COUNT(*)>2 GROUP BY S.sid ( σ S.sid=R.sid AND R.bid=B.bid AND B.color=‘red’ AND S.rating=value_from_nested_block ( SailorsχReserves χBoats)))) πS.sid,MIN(R.day) ( HAVING COUNT(*)>2 GROUP BY S.sid (σπχ expression ) πS.sid,R.day ( σ S.sid=R.sid AND R.bid=B.bid AND B.color=‘red’ AND S.rating= value_from_nested_block ( Sailors χ Reserves χ Boats)))))) 9 Relational Algebra Tree • Represent a plan, which is a relational algebra (RA) expression, as a RA tree. sname SELECT S.sname FROM Reserves R, Sailors S WHERE R.sid=S.sid AND R.bid=100 AND S.rating>5 σbid=100 ^ rating > 5 sid=sid Reserves Sailors 10 Estimate Cost of a Plan • For each enumerated plan, estimate its cost: – Each node in the tree involves a relational operator. We must estimate the cost of evaluating a relational operator. • Size of inputs (#pages), table statistics (selection conditions), available indexes, and chosen algorithms for evaluating operators (Chapter 14). – For each node in the tree, we need to estimate the size of the results and whether the results are sorted or not. • Since the results are inputs to the upper node, they are used to estimate the cost of the upper node (operator). 11 Notes on Query Optimizer • Cost estimation is only an approximation. – Consider the cost of Disk I/Os. • Plan Space: – Too large -> too many possible plans to enumerate and too expensive to estimate the costs for all of them, must be restricted. – Consider only the space of left-deep plans. Why? • Left-deep plans allow output of each operator to be pipelined into the next (parent) operator without physically storing it in a temporary relation. • Avoid cartesian products. 12 Left Deep Join Trees • Restrict the plan search space to only left-deep join trees. – – As the number of joins increases, the number of alternative plans grows rapidly; we need to restrict the search space. Left-deep trees allow us to generate all fully pipelined plans (if we choose so). • Intermediate results not written to temporary files. • Not all left-deep trees are fully pipelined, depending on the choice of join algorithm (e.g., Sort-Merge join). ⋈ ⋈ ⋈ A ⋈ ⋈ B C ⋈ D A D C B 13 Estimating Result Sizes SELECT attribute list FROM relation list WHERE term_1 AND term_2 AND term_3 … AND term_n • How to estimate the size of result by an operator on given inputs? – Use information from system catalogs and statistics. – For each term, find tuple reduction factors (# expected input tuples / # expected qualified tuples). Column = value 1 / NKeys(I), if column is index(I), or 10%. Column1 = Column2 1 / MAX (NKeys(I1), NKeys(I2)), or 1 / NKeys(I), or 10%. Column > value (High(I) – value) / (High(I) – Low(I)), or <50%. Column in (list of values) (reduction factor for column = value) * # values Very Rough Estimation of Reduction Factors 14 Improved Statistics: Histograms • The rough estimation assumes uniform distributions of values. – What if that assumption is not true? For more accurate estimations, use histograms. • Histogram is a data structure to approximate data distribution. – Term # children with (age > 3): result size = 2 tuples. 7 5 2 1 2 3 1 1 4 5 ages 15 Relational Algebra Equivalences • Allow us to choose different join orders and to push selections and projections ahead of joins. • Selections (cascading of selections): – Break a selection condition into many smaller selections. – Combine several selections into one selection. σ c1 AND c2 AND … cn (R) ≡ σ c1 (σ c2 ( …σ cn (R)) …)) • Selection (commutative): – Test conditions in either order. σ c1 (σ c2 (R)) ≡ σ c2 (σ c1 (R)) 16 Relational Algebra Equivalences (Projections, Joins, and Cross-Products) • Projections (cascading projections) – Successively eliminating columns is same as eliminating all but the columns of final projection. πa1.(R) ≡ πa1.( πa2.(…(πan R)) ..)), where a1 is a set of attributes of relation R, and ai is a subset of ai+1 πsid.(R) ≡ πsid.( πsid, bid (Reserves)) • Joins and Cross-Products (commutative) – Freedom to choose inner or outer relations RχS ≡ SχR • Joins and Cross-Products (associative) – Join pairs of relations in any order Rχ(S χT) ≡ (RχS) χT 17 Relational Algebra Equivalences Involving Two or More Operators (1) • Commute a selection with a projection – when the selection condition c involves only attributes retained by the projection a. π a (σ c (R)) ≡ σ c (π a (R)) π sid (σ sid=10 (R)) ≡ σ sid=10 (π sid (R)) π sid (σ bid=10 (R)) ≠ σ bid=10 (π sid (R)) • Combine a selection with a cross-product to form a join. • Push a selection into a cross-product (join) – When the selection condition c involves only attributes of one of the arguments to the cross-product (join). σ c (R χ S ) ≡ σ c (R) χ S σ R.bid=10 (R χ S ) ≡ σ R.bid=10 (R) χ S σ S.rating=10 (R ⋈ S ) ≠ σ S.rating=10 (R) ⋈ S 18 Relational Algebra Equivalences Involving Two or More Operators (2) • Push a selection into a cross-product (join) – Replace a selection with cascading selections, and commute selections. – c1 involves attributes of both R & S (c2 attrs of R, c3 attrs of S). σ c (R χ S ) ≡ σ c1 ^ c2 ^ c3 (R χ S ) ≡ σ c1 (σ c2 (σ c3 (R χ S ))) ≡ σ c1 (σ c2 (R) χ σ c3 (S )) σ sid=10, rname=‘Jane’ ^ sname=‘Paul’ (R χ S ) ≡ σ sid=10 (σ sname=‘Jane’ (R) χ σ rname=‘Paul’ (S )) • Push a projection into a cross-product (join) – when subsets (a1,a2) of projection attribute a involves only attributes of one of the arguments to the cross-product (join). – Same as to push a selection with cross-product (join) π a (R χ S ) ≡ π a1 (R) χ π a2 (S) π R.sid, S.sname (R χ S ) ≡ π R.sid (R) χ π S.sname (S) 19 Relational Algebra Equivalences Involving Two or More Operators (3) • Push a projection into a join – When a1 is subset of a in R, a2 is a subset of a in S, and c is in a. π a (R ⋈c S ) ≡ π a1 (R) ⋈c π a2 (S) π R.sid, S.sname, S.sid (R ⋈ R.sid=S.sid S ) ≡ (π R.sid (R) ) ⋈ R.sid=S.sid (π S.sname,S.sid (S) ) • Push a projection into a join if ∆ ∆ ∆ ∆ – a1 is subset of R that appear in a and c, and a2 is a subset of S that appear in a and c π a (R c S ) ≡ π a ( π a1 (R) c π a2 (S)) π R.sid, S.sname (R R.sid=S.sid S ) ≡ π R.sid,S.sname ( π R.sid,R.sid (R) R.sid=S.sid π S.sname,S.sid (S)) ∆ ∆ ∆ ∆ 20 Enumeration of Alternative Plans • There are two main cases: – – Single-relation plans: (SELECT … FROM Sailors S …) Multiple-relation plans: (SELECT … FROM Sailors S, Reserves R …) • For queries over a single relation, queries consist of a combination of selections, projections, and aggregate ops (no joins). • The general strategy has two parts: – – For selections, consider each available access path (file scan / index) and pick the one with the least estimated cost. Projections and aggregations are carried out together with selections. • For example, if an index is used for a selection, projection is done for each retrieved tuple, and the resulting tuples are pipelined into the aggregate computation. 21 Single-Relation Queries • Example: – “For each rating greater than 5, print the rating and the number of 20year old sailors with that rating, provided that there are at last two such sailors with different names” • Plan without indexes: – Scan Sailors, apply selections and projections. – Write out tuples. – Sort tuples based on S.rating (GROUP BY). – Apply HAVING on the fly at the last sorting step. πS.rating,COUNT(*) ( HAVING COUNT DISTINCT(S.sname)>2 GROUP BY S.rating ( πS.raing,S.sname ( σ S.rating>5 AND S.age=20 (Sailors))))) σ π χ expression 22 Single-Relation Queries: Plans Utilizing an Index • Single-Index Access Path – If several indexes match selection condition(s), pick the best access path. Apply projections and non-primary selections. Sort by grouping attributes. Do aggregations. • Multiple-Index Access Path – If several indexes match selection condition(s), use them to retrieve sets of RIDs. Take intersection of RID sets. Sort resulting RID by page ID. Retrieve all tuples on the same page, while applying projections, selections. Sort by grouping attributes. Do aggregations. • Sorted Index Access Path – If GROUP BY attributes matches a tree index, use the index to retrieve tuples in order. Then apply selections, projections, and aggregation operations. • Index-Only Access Path – If all attributes mentioned in (SELECT, WHERE, GROUP BY, HAVING) are in the index, can do an index-only scan. 23 Example Using Single-Index Access Path • B+ tree index on rating, hash index on age, and B+ tree index on <rating, sname, age> • • • • Retrieve Sailors tuple (age=20) using hash index on age. (most selective path) For retrieved tuple, apply (rating >5 ) and projection out attributes (rating and sname). Write results to temp table. Sort temp table on rating. At the last sorting step, apply HAVING and final projection. πS.rating,COUNT(*) ( HAVING COUNT DISTINCT(S.sname)>2 GROUP BY S.rating ( πS.raing,S.sname ( σ S.rating>5 AND S.age=20 (Sailors))))) σ π χ expression 24 Queries Over Multiple Relations • The general strategy has three parts: – Consider and enumerate only left-deep join trees. Why? • • – – Restrict the search space. Left-deep trees allow us to generate all fully pipelined plans. Consider selections and projections as early as possible (Push selections and projections into lower joins) Estimate the cost for each left-deep plan. Pick the one with the lowest cost. D C C A B D D A B A C B 25 Enumeration of Left-Deep Plans • Left-deep plans differ from each other in – The order of relations – The access method for each relation – The join algorithm for each join operation • We have discussed how to enumerate different access methods and estimate their costs for one relation. • Different join algorithms (e.g., nested loop join, sort-merge join, hash join, …) and their cost analysis are discussed in Chapter 14. 26 Plan Enumeration Algorithm • Enumerated using N passes (if N relations joined): – Pass 1: Find best 1-relation plan for each relation. • • – Pass 2: Find best way to join result of each 1-relation plan (as outer) to another relation. (All 2-relation plans.) • • – Push selection terms & projection attributes to that 1-relation (using equivalences) Consider all different access paths, and pick the one with lowest cost. This is same algorithm as 1-relation query. Again push selection terms & projection attributes into the inner relation using equivalences. Try to pipeline the selected/projected tuples from the inner relation into join operation with outer relation. (Sometimes cannot, e.g., sort-merge join) Pass N: Find best way to join result of a (N-1)-relation plan (as outer) to the N’th relation. (All N-relation plans.) 27 Plan Enumeration Algorithm Illustration Pass 1: Same as SingleRelation Query Pass 2 A B pipelined into join consider alt join algs B A outer C push sel/proj A C inner Pass 3 B C A B A C 28 Enumeration of Plans (Contd.) • For each subset of relations, retain only: – – Cheapest plan overall, plus Cheapest plan for each interesting order of the tuples. • ORDER BY, GROUP BY, aggregates etc. handled as a final step. If tuples going into them are not sorted, apply additional sorting. • Consider left-deep trees, this approach is still exponential in the # of relations. – N relations -> O( N! ) plans 29 Example • Pass1: – Sailors: B+ tree index on rating Hash index on sid Reserves: B+ tree index on bid Sailors: B+ tree matches rating>5, and is probably cheapest. However, if this selection is expected to retrieve a lot of tuples, and index is unclustered, file scan may be cheaper. sname sid=sid bid=100 rating > 5 • Still, B+ tree plan kept (because tuples are in rating order). – • Reserves: B+ tree on bid matches bid=500; cheapest. Reserves Sailors Pass 2: – We consider each plan retained from Pass 1 as the outer, and consider how to join it with the (only) other relation. • Reserves as outer (better): hash index can be used to get Sailors tuples that match sid = outer tuple’s sid value (hash join) • Sailors as outer (worse): B+ tree index can be used to get Reserves tuples that match bid. Then pipeline tuples into join, or write them out for sort-merge join. 30 Nested Subqueries • Nested block is optimized independently (sometimes just evaluated once). • In general, nested queries are dealt with SELECT S.sname using some form of nested loops FROM Sailors S evaluation. WHERE S.rating = – Main query as the outer loop, the subquery as the inner loop – This is necessary for correlated queries below (S is used both in the main query and the subquery.). SELECT S.sname FROM Sailors S WHERE EXISTS (SELECT * FROM Reserves R WHERE R.bid=103 AND S.sid=R.rid) (SELECT MAX(S2.ratings) FROM Sailors S2) SELECT S.sname FROM Sailors S WHERE S.sid IN (SELECT R.sid FROM Reserves R WHERE R.bid=103) 31 Summary • Query optimization is an important task in a relational DBMS. • Must understand optimization in order to understand the performance impact of a given database design (relations, indexes) on a workload (set of queries). • Two parts to optimizing a query: – Consider a set of alternative plans. • Must prune search space; typically, left-deep plans only. – Must estimate cost of each plan that is considered. • Must estimate size of result and cost for each plan node. • Key issues: Statistics, indexes, choice of operator algorithms. 32 Summary (Contd.) • Single-relation queries: – All access paths considered, cheapest is chosen. • Multiple-relation queries: – – – – All single-relation plans are first enumerated. • Selections/projections considered as early as possible. Next, for each 1-relation plan, all different ways of joining another relation (as inner) are considered. Next, for each 2-relation plan that is `retained’, all ways of joining another relation (as inner) are considered, etc. At each level, for each subset of relations, only best plan for each interesting order of tuples is `retained’. 33