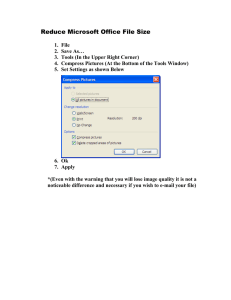
BORANG PENGESAHAN STATUS TESIS UNIVERSITI TEKNOLOGI MALAYSIA
advertisement

PSZ 19 : 16 (Pind. 1/97)
UNIVERSITI TEKNOLOGI MALAYSIA
BORANG PENGESAHAN STATUS TESIS ♦
JUDUL :
THE APPLICATION OF HOUGH TRANSFORM FOR
CORNER DETECTION
SESI PENGAJIAN : SEMESTER II 2005/2006
MOHAD FUAD BIN JAMALUDIN
Saya
(HURUF BESAR)
mengaku membenarkan tesis (PSM/Sarjana/Doktor Falsafah)* ini disimpan di Perpustakaan
Universiti Teknologi Malaysia dengan syarat-syarat kegunaan seperti berikut :
1.
2.
3.
4.
Tesis adalah hakmilik Universiti Teknologi Malaysia.
Perpustakaan Universiti Teknologi Malaysia dibenarkan membuat salinan untuk tujuan
pengajian sahaja.
Perpustakaan dibenarkan membuat salinan tesis ini sebagai bahan pertukaran antara
institusi pengajian tinggi.
**Sila tandakan ( √ )
√
SULIT
(Mengandungi maklumat yang berdarjah keselamatan atau
kepentingan Malaysia seperti yang termaktub di dalam
AKTA RAHSIA RASMI 1972)
TERHAD
(Mengandungi maklumat TERHAD yang telah ditentukan
Oleh organisasi/badan di mana penyelidikan dijalankan)
TIDAK TERHAD
Disahkan oleh
(TANDATANGAN PENULIS)
(TANDATANGAN PENYELIA)
Alamat Tetap :
B-64 FELDA SUNGAI SAYONG,
81000 KULAI, JOHOR
Tarikh :
CATATAN :
8hb Mei, 2006
*
**
♦
ASSOC. PROF. DR.
SHAHARUDDIN SALLEH
Nama Penyelia
Tarikh :
8hb Mei, 2006
Potong yang tidak berkenaan.
Jika tesis ini SULIT atau TERHAD, sila lampirkan surat daripada pihak
berkuasa/organisasi berkenaan dengan menyatakan sekali sebab dan tempoh tesis ini
perlu dikelaskan sebagai SULIT atau TERHAD.
Tesis dimaksudkan sebagai tesis bagi Ijazah Doktor Falsafah dan Sarjana secara
penyelidikan, atau disertai bagi pengajian secara kerja kursus dan penyelidikan, atau
Laporan Projek Sarjana Muda (PSM).
“I hereby declare that I have read this thesis and in my
opinion this thesis is sufficient in terms of scope and quality for the
award of the degree of Master of Science (Mathematics)”
Signature
:
..........................................................
Name of Supervisor :
Assoc. Prof. Dr. Shaharuddin Salleh
Date
8hb Mei, 2006
:
THE APPLICATION OF HOUGH TRANSFORM FOR CORNER DETECTION
MOHAD FUAD BIN JAMALUDIN
A dissertation submitted in fulfilment of the
requirements for the award of the degree of
Master of Science (Mathematics)
Faculty of Science
Universiti Teknologi Malaysia
APRIL, 2006
ii
I declare that this thesis entitled THE APPLICATION OF HOUGH TRANSFORM FOR
CORNER DETECTION is the result of my own research except as cited in the
references. This thesis has not been accepted for any degree and is not concurrently
submitted in candidature of any other degree.
Tandatangan
:
.............................................
Nama Penulis
:
Mohad Fuad Bin Jamaludin
Tarikh
:
8hb Mei, 2006
iii
To my loving parent, Jamludin Bidin and Siti Lilah Juraimi also my lecturers
Assoc. Prof. Dr. Shaharuddin Salleh and Dr. Habibullah Haron
Thanks for your support, sacrifices and blessings
iv
ACKNOWLEDGMENT
Firstly, I would like to thank Allah S.W.T for giving me the health, strength and
patience to complete this dissertation. My deepest gratitude and appreciation to my
supervisor, Assoc. Prof. Dr. Shaharuddin Salleh also Dr. Zaitul Marlizawati Zainuddin
for they invaluable and insightful guidance, and continuous support offered throughout
the length of this study. Also special thanks to Dr. Habibullah Haron for his helpful
suggestions and ideas.
My sincerest appreciation to all my friends and course mates of MSc.
Mathematics in the Faculty of Science, who have support and help me during my study
in UTM. I ‘m also grateful to my family for their endless blessings, support and
understanding.
v
ABSTRACT
Corners are very attractive features of many applications in human perception
and computer vision. The problem of detecting corners is simplified into detecting
simple lines in a local coordinate system. As simple lines can be expressed using only
one parameter, Hough Transform can detect them quickly. Other edge detectors have
some problems when marking edge points around corners. Based on both gradient
magnitude threshold and grey level analysis, the edge points can be detected. Using the
Sobel and Kirsch Operator, an image can be extracted and provide the edge points for
Hough Transform. Mean while, the Zhang Suen Thinning Method can be used to reduce
the edge points into minima points to speed up the algorithm. To illustrate the problem,
the interface program is developed by using Microsoft Visual C++ 6.0.
vi
ABSTRAK
Titik simpang merupakan salah satu sifat-sifat objek yang penting dalam
perspektif visual manusia dan komputer. Masalah di dalam mengesan simpang
dipermudahkan kepada mengesan sifat-sifat garisan di dalam sistem grid atau koordinat.
Kebiasaannya, ciri-ciri garisan dapat ditunjukkan di dalam parameter Hough Transform
dengan lebih cepat. Sesetengah pengesan pinggir (edge detector), mempunyai masalah
dalam menandakan titik pinggir di sekitar titik simpang. Berdasarkan nilai penentu
kecerunan dan analisa grey-level, titik-titik pinggir boleh dikesan. Operator KirschSobel telah digunakan untuk mengekstrak imej dan membentuk pinggiran sebelum
melalui proses seterusnya menggunakan Teknik Hough Transform. Sementara itu,
Teknik Penipisan iaitu Kaedah Zhang-Suen digunakan untuk mengurangkan ketebalan
garisan pinggir supaya menjadi lebih nipis (pinggir minima). Penggunaan kaedah
tersebut adalah untuk mempercepatkan proses pengesanan simpang di dalam Teknik
Hough Transform. Bagi menunjukkan proses pengesanan simpang, satu rekabentuk
program antaramuka telah dibangunkan dengan menggunakan Microsoft Visual C++
6.0.
vii
TABLE OF CONTENTS
CHAPTER
I
TITLE
PAGE
DECLARATION
ii
DEDICATION
iii
ACKNOWLEDGMENT
iv
ABSTRACT
v
ABSTRAK
vi
CONTENTS
vii
LIST OF FIGURES
x
LIST OF TABLES
xii
LIST OF APPENDICES
xiii
RESEARCH FRAMEWORK
1
1.1
Introduction
1
1.2
Problem Statement
2
1.3
Objectives of Study
3
1.4
Scopes of Study
3
1.5
Dissertation Organization
4
viii
II
EDGE AND CORNER DETECTION PROBLEM
5
2.1
Intoduction
5
2.2
Project Framework
6
2.3
Edge Detection Problems
7
Roberts Cross-Gradient Operator
12
2.3.2
Prewitt edge detector and Sobel edge detector
13
2.3.3
Kirsch edge detector
15
2.3.4
Laplacian Filtering Method
16
2.3.5
Gaussian Smoothing Filter
19
2.4
Thresholding
20
2.5
Thinning Problems
23
2.5.1
Simple Thinning Method
24
2.5.2
Zhang-Suen Skeletonizing
26
2.6
2.7
III
2.3.1
2.5.3 Medial Axis Transform
28
Corner Detection Problems
30
2.6.1 Hough Transform
30
2.6.2 Wavelet Transform
31
2.6.3
32
Chain Code Representation
Summary
34
THE HOUGH TRANSFORM
35
3.1
Background
35
3.2
Method of Line Detection
36
3.3
Method of Corner Detection
40
3.4
Algorithm for Line and Corner Detection
43
3.5
Summary
48
ix
IV
V
VI
CASE STUDY IN CORNER DETECTION
49
4.1
Intoduction
49
4.2
Edge Image
50
4.3
Local Minima Image
58
4.4
Locating Corners
60
SIMULATION MODEL
63
5.1
Introduction
63
5.2
Model Description
64
5.3
Simulation Model
65
5.4
Summary
70
SUMMARY AND CONCLUSIONS
71
6.1
Observation
71
6.2
Disscussions
73
6.3
Suggestions
75
REFERENCES
76
APPENDIX A
79
APPENDIX B
81
APPENDIX C
84
APPENDIX D
94
x
LIST OF FIGURES
FIGURE NO.
TITLE
2.1
The main stage of detecting corners
2.2
Detection of edges associated with grey-level corresponding
first and second derivatives (Seul et al. 2000)
PAGE
6
8
2.3
Pixel update at ( x , y ) for mask 3x3 size in windows template
11
2.4
The Gaussian matrix of 7x7 size
19
2.5
Classification of common thinning algorithm
24
2.6(a)
Illustrate the not deleted pixels that may cause discontinuities
25
2.6(b)
The pixel whose removal will shorten an object limb
25
2.7
The eight-neighbourhood of pixel, P
25
2.8
Example of computing distance transform of binary image:
(a) a full region binary image,
(b) a distance transform obtained
2.9
Medial Axis matrix of the binary image shown in
figure 2.8(a) using 8-connected boundary
2.10
28
29
Direction of boundary segments of a chain code for
(a) a 4-connected chain, (b) an 8-connected chain
33
3.1
The line passing two points
36
3.2
The intersection of two lines in the mc-plane correspond to
a line in the xy-plane
37
3.3
The illustration of r and θ in the line
38
3.4
An accumulator array
39
xi
3.5
The algorithm of Hough Line Detector
44
3.6
The algorithm of Hough Corner Detector
44
3.7
The points in the xy-plane lying on a line
45
3.8
Sinusoidal functions are associated with points on a line
46
3.9
The two lines crossing at point (3,5) in Cartesian space
46
3.10
The sinusoidal function of point (3,5) lies on two points that
corresponds to the high lines crossing.
4.1
47
Kirsch and Sobel Algorithm for computing the edges of an
Image.
50
4.2
The original pixel values of an image size of 10x10 matrix
51
4.3
A pixel represented as a 24-bit string (Salleh et al, 2005)
52
4.4
The first 3x3 matrix of the image in Figure 4.2.
55
4.5
The new value of the image in 8x8 matrix after filtering
the image in figure 4.1
57
4.6
The binary edge image of Figure 4.5
57
4.7
The Zhang-Suen Thinning Algorithm.
58
4.8
A 3x3 matrix is obtained from Figure 4.6
59
4.9
The minima image after thinning process with Zhang-Suen
Algorithm and Hough Line Detector.
59
4.10
The corner candidate using the Hough Corner Detector.
62
5.1
The sample of digital image
65
5.2
The result from the edge detector (the Edge Image)
66
5.3
The result of thinning process (the Minima Image)
67
5.4
The corner candidates produced from the thinning image of
5.5
Figure 5.3
68
The accurate corners are obtained from Figure 5.4
69
xii
LIST OF TABLES
TABLE NO.
TITLE
PAGE
4.1
The accumulator of the Hough Transform
60
4.2
The array of rho[i] and theta[i]
61
xiii
LIST OF APPENDICES
APPENDIX
TITLE
PAGE
A
The sinusoidal graph in Hough space
79
B
The Analysis of the Rate of the Maximum Thresholding
81
C
The Result of Corner Image using different Thresholding
84
D
The Related Source Code
94
CHAPTER I
RESEARCH FRAMEWORK
1.1
Introduction
Feature detection such as edge and corner detection is an essential step in human
perception of shapes. Such corner points contain important information about the shape
of objects. The extraction of the corner points is useful for computer applications such
as image recognition, segmentation, description, matching and data compression.
In human perception of shapes, a corner is not only from the mathematical
concept of corners but also from the neighbouring patterns of local features. Human
recognize the corners, which are consistent with each other in the description of shapes.
They develop this imperfect knowledge empirically.
In industrial applications this can be an essential for safety or for quality control,
which require an efficient algorithm for locating specific objects in images with the aims
2
of counting, checking and measuring. Sharp features and well-defined shapes such as
corners help considerably with object location. If the corners can be detected
computationally, the job such as counting, checking and measuring can be done
efficiently.
Recently, corner detection problem is divided into two categories namely
boundary-based and region-based approaches (Chen et al., 1995). Boundary-based
approaches use chain code to detect the corners on the boundary of an object. While the
region-based approaches identify the corners directly on the grey-level image using
gradient and curvature measurements.
Conventionally, a corner is defined as the junction point of two or more straight
lines. Based on this definition, two characteristics of corners can be generalized (Shen
and Wang, 2001). Firstly, a corner point is also an edge point. Secondly, at least two
lines pass through the corner point.
1.2
Problem Statement
Given an image in digital form, the problem is to detect the corners in that image.
A corner is identified at a point in the image through the non-existent of the first
derivative. We apply the Hough Transform method to detect the corners in an image.
The Hough Transform is applied to the boundary object of the binary image, which is
can be a line or curvature. To produce the binary image also known as an edge image,
we apply the Sobel and Kirsch Edge Detector and the Zhang-Suen Thinning Method to
the digital image.
3
1.3
Objectives of Study
The following are the objectives of this dissertation:
Design and develop a simulation model for detecting corner on the digital
image.
Apply the procedure to a real problem.
Evaluate the performance of Hough Transform by using different threshold
values.
1.4
Scopes of Study
The simulation program of corner detection has been developed using the
Microsoft Visual C++. It involves an image of size 640 x 480 pixels. The simulation
program uses the bitmap format to extract and analyses every pixel points in twodimensional array. It uses the RGB values of colouring to extract the image and detect
some edge lines. Then, the edge lines are used to determine the corners. In this study,
the Kirsch and Sobel Edge Detector is used to obtain the edge values in binary image.
The Zhang Suen Thinning Method is used to reduce the thickness of the edges. All
these methods are used in pre-processing stage. In the post-processing, the Hough
Transform is used to detect the corners through the edge lines obtained.
4
1.5
Dissertation Organization
This dissertation consists of six chapters. Chapter I is the research framework.
This chapter includes an introduction of study, the problem statement, objective and
scope of the study. This follows by Chapter II that briefly describes about edge and
corner detection problems. Chapter III discusses in details about the Hough Transform
to detect lines and corners. In Chapter IV, a case study of corner detection using the
Hough Transforms is discussed. The experimental results and analyses are described in
Chapter V. Lastly, Chapter VI discusses in general the conclusion and future works.
CHAPTER II
EDGE AND CORNER DETECTION PROBLEM
2.1
Introduction
This study involves the pre-processing and the post-processing stage of corner
detection. The pre-processing includes the edge image process and the thin image
process. In the simple way, the digital image must be extract to get the binary image by
using edge detector. The edge detectors like Robert, Sobel and Kirsch operator can be
used to detect the edge in an image. In the edge detection process, the threshold value
must be considered when extracting the binary image from the digital image. The next
process is to reduce some noise from the binary image and to detect the minima points
(thinning image). In the post-processing, the corner detection approach is applied to get
the corners.
6
2.2
Project Framework
Image processing is an area of study for modifying, manipulating and extracting
images to improve the quality of an image. The application involves the process of
formation, representation, operation and display. This study is a part of the image
processing that involves the extracting and reformation process.
Chen et al. (1995) proposed the processing stages in detecting corners directly
from the grey-level image by using the Wavelet Transform. In this study, the same
processing stages will be used, but the Hough Transform will be applied to detect the
corners instead of the Wavelet Transform. The stages are shown below:
Digital Image
Acquiring the
edge image
(Input)
Binary
Image
Acquiring the
minima points
Thinning
Image
Eliminating the
edge points
Real Corner
(Output)
Figure 2.1
Locating corners
Corner
Candidates
The main stages of detecting corners
7
First, a two dimension digital image is used to obtain the binary image. Every
pixel of image has a value that represents the colour. The value is called intensity. The
intensity is stored in two-dimension array for extracting. After this stage, the image is
filtered by using the edge detection method. The Kirsch and Sobel edge detector is used
to acquire the edge image. The edge image is represented by binary values that are
determined by using the threshold values.
In this stage, the edge is probably thick. The next process is to thin the edge to
detect the corner easily. Thinning method is used to acquire the minima points. Then
the Hough Line Detector is used to reduce the noise and represent the edges as lines.
The lines are obtained using the accumulator that involved some parameters. These
parameters will be used in the next stage to detect corners.
Next stage is to check every point at edges to get the corner candidate points.
The validation involves the entire candidate of corner points by using the accumulator.
The validation process uses the Hough Corner Detector that involves some
characteristics of lines.
2.3
Edge Detection Problems
Edges carry useful information about object boundaries that can be used for
image filtering applications, image analysis and object identification. Basically, edges
can be detected from an image by looking at the separation regions of image intensity.
The separation between the high and low intensity pixels is verified using the threshold
value. Figure 2.2 shows the separation of high and low intensity more closely modelled
8
as having a ‘ramp-like’ profile. The figure also corresponds to the first and second
derivatives, illustrating the fact that the information of signs and location of an edge may
be extracted by using different operators. Since, some operators may use the first
derivative and some may use the second derivative.
Image
‘Ramp-like’ profile
Profile of a horizontal
line, f ( x )
First derivative,
∇ f ( x, y )
Second derivative,
∇ 2 f ( x, y )
Figure 2.2
Detection of edges associated with grey-level corresponding first and
second derivatives (Seul et al. 2000)
9
The most direct approach to detect edge relies on the evaluation of local spatial
variation of f (x, y ) . The first derivative of f (x, y ) corresponds to a local maximum at
an edge. Therefore, the local maximum can produce gradient image to detect edge.
Typically, the gradient image at location ( x, y ) where x and y are the row and
column coordinates respectively is a two directional derivatives that can be represented
as gradient magnitude and gradient orientation (Chanda and Majumder, 2000). The
gradient magnitude relates to edge strength, while the gradient orientation corresponds
to the angle of gradient (direction).
The image gradient is defined as the vector that refers to the ‘ramp-like’ profile.
⎡ ∂f ⎤
⎡G x ⎤ ⎢ ∂x ⎥
∇f ( x , y ) = ⎢ ⎥ = ⎢ ⎥
⎣G y ⎦ ⎢ ∂f ⎥
⎢⎣ ∂y ⎥⎦
2.1
Most important from vector analysis is the magnitude, commonly approximated as
follows
∇f ( x, y ) = G x2 + G y2 or ∇f ( x, y ) = G x + G y
2.2
This quantity gives the maximum rate of increase of f ( x, y ) per-unit distance in
the direction of ∇f (x, y ) . The gradient orientation can be described by the direction
angle
10
⎛ Gy
⎝ Gx
α (x , y ) = tan −1 ⎜⎜
⎞
⎟⎟
⎠
2.3
where the angle is measured with respect to the x-axis. The direction of an edge at
point (x, y ) is perpendicular to the gradient orientation. Another approach is to calculate
the gradient using forward-difference method as follows:
f ( x + h, y ) − f ( x , y )
∂f
= lim
h
∂x h →0
∂f
f ( x, y + k ) − f ( x , y )
= lim
k
→
0
∂y
k
2.4
Let h and k tend to 1, yields
∂f
= f ( x + 1, y ) − f ( x, y )
∂x
∂f
= f ( x, y + 1) − f ( x, y )
∂y
2.5
Usually in the programming method, [i][j]-notation is used instead of (x, y ) notation, where the column j corresponds to the x-axis and the row i corresponds to the
y-axis. Generally, the edge detection process is a transformation process of a pixel at
f (x, y ) into h(x, y ) or f [i ][ j ] → h[i ][ j ] through programming.
The transformation process involves a derivative of f (x, y ) and thresholding.
The derivative process uses a convolution method by using kernel G, k (x, y) = G ∗ f (x, y)
where G corresponds to an operator of the method of edge detection. The kernel G is
11
known as the weight or coefficient of the element in the mask of 3x3 size. The mask is
as shown in Figure 2.3 below.
Figure 2.3
f ( x − 1, y − 1)
f ( x , y − 1)
f ( x + 1, y − 1)
f ( x − 1, y )
f (x , y )
f ( x + 1, y )
f ( x − 1, y + 1)
f ( x , y + 1)
f ( x + 1, y + 1)
Pixel update at (x , y ) for mask 3x3 size in window template
By using the masks of size 3x3, the transformation equation is approximated as follows:
3
3
k ( x , y ) = ∑∑ G (m , n ) f ( x + m − 2 , y + n − 2 )
2.6
m =1 n =1
Roberts, Prewitt, Sobel and Kirsch are some examples of the edge detection
operator that apply the convolution method to the first derivative. Equation 2.6 is used
to get the value of k (x , y ) for every pixel in an image. The value k (x , y ) is then
compared to a threshold value. If k (x , y ) is greater than the threshold, then 1 (or 0) is
assigned to the pixel. Otherwise, the pixel is assigned with 0 (or 1). The result of the
transformation is in binary form that is held by output image h(x , y ) .
12
2.3.1
Roberts Cross-Gradient Operator
Edge detection operators verify each pixel neighbourhoods by quantifying the
slope and the direction as well as the grey-level. Using the mask in Figure 2.3 to detect
edges, Roberts defined the first order derivative of the column and row of the mask as
K x = f (x + 1, y + 1) − f ( x, y ) and K y = f ( x , y + 1) − f ( x + 1, y )
2.7
where K x and K y correspond to the derivative of the column and the row of the mask.
The above partial derivatives can be represented by masks of 3x3 size. The masks of
Robert operator are defined as
Gx
⎡0 0 0 ⎤
⎡0 0 0 ⎤
⎢
⎥
= ⎢0 - 1 0⎥ and G y = ⎢⎢0 0 - 1⎥⎥
⎢⎣0 0 1⎥⎦
⎢⎣0 1 0 ⎥⎦
This operator is one of the oldest edge detectors in digital image processing
(Gonzalez et al., 2004). It is also the simplest and shortest, thus the position of the edges
is more accurate. But the problem with the short support is noisier. It also produces a
weak response to real edge unless the image is very sharp.
13
2.3.2
Prewitt edge detector and Sobel edge detector
Prewitt and Sobel edge detection algorithms also used the masks to represent the
horizontal, K y and vertical, K x edge components. The method uses one-dimensional
approximation to gradient to reduce the noise.
The idea behind the popular Prewitt and Sobel edge detection is the combination
of differentiation with the central differences of adjacent horizontal and vertical of edge
components. The difference is in the (x, y ) -notation, where x is the column of an array
and y is the row of an array.
∂f
= ( f ( x + 1, y + 1) − f ( x − 1, y + 1)) + ( f ( x + 1, y ) − f ( x − 1, y )) +
∂x
( f (x + 1, y − 1) − f (x − 1, y − 1))
2.8
∂f
= ( f ( x + 1, y + 1) − f ( x + 1, y − 1)) + ( f ( x, y + 1) − f ( x, y − 1)) +
∂y
( f (x − 1, y + 1) − f (x − 1, y − 1))
2.9
The Prewitt edge detector deals better with the effect of noise. Rearranging the
equations 2.8 and 2.9, the partial derivatives of the Prewitt operator are given as
K x = ( f ( x + 1, y + 1) + f ( x + 1, y ) + f ( x + 1, y − 1)) −
( f (x − 1, y + 1) + f (x − 1, j ) + f (x − 1, y − 1))
K y = ( f (x + 1, y + 1) + f ( x , y + 1) + f (x − 1, y + 1)) −
( f (x + 1, y − 1) + f (x , y − 1) + f (x − 1, y − 1))
2.10
2.11
14
Equations 2.10 and 2.11 correspond to the vertical and horizontal mask in
detecting edge. Therefore, the masks of Prewitt operator can be written as
⎡- 1
G x = ⎢⎢- 1
⎢⎣- 1
0
0
0
1⎤
⎡ -1
⎥
1⎥ and G y = ⎢⎢ 0
⎢⎣ 1
1⎥⎦
-1
0
1
- 1⎤
0⎥⎥
1⎥⎦
These masks have longer support. If the masks are used separately, they will only detect
the edges in one direction. However, if they are combined, the edges in both directions
can be detected. It will make the edge detector less noisy.
The Sobel edge detector provides good performance and is relatively insensitive
to noise (Pitas, 1993). The partial derivatives of the Sobel edge detector are similar to
Prewitt partial derivatives. The only difference is that the Sobel edge detector has a
weight of two in the centre coefficient. A weight value of two is applied to achieve
some smoothing by giving more importance to the centre point (Gonzalez et al., 2004).
Arranging equations 2.10 and 2.11 and add coefficient of two at the centre, the partial
derivatives of the Sobel operator yield
K x = ( f ( x + 1, y + 1) + 2 f ( x + 1, y ) + f ( x + 1, y − 1)) −
( f (x − 1, y + 1) + 2 f (x − 1, j ) + f (x − 1, y − 1))
K y = ( f (x + 1, y + 1) + 2 f ( x , y + 1) + f ( x − 1, y + 1)) −
( f (x + 1, y − 1) + 2 f (x , y − 1) + f (x − 1, y − 1))
Therefore the masks of Sobel operator are:
⎡-1
G x = ⎢⎢- 2
⎢⎣ - 1
0
0
0
1⎤
⎡ - 1 - 2 - 1⎤
⎥
2⎥ and G y = ⎢⎢ 0 0 0⎥⎥
⎢⎣ 1 2 1⎥⎦
1⎥⎦
2.12
2.13
15
Most of the applications in computing digital gradients use the Prewitt and Sobel
Operators. The Prewitt operators are simpler to implement than the Sobel Operator, but
the Prewitt Operator has noise suppression characteristics when dealing with derivatives.
Both of these operators can handle more gradual transitions and noisier images better
(Gonzalez et al, 2004).
2.3.3
Kirsch edge detector
The Kirsch edge detector uses eight masks at each point of an image. The masks
are used to determine an edge gradient magnitude and direction. Each mask refers to an
edge oriented in particular general direction such as horizontal (0 degree), vertical (90
degree) or diagonal (45 or 135 degree).
The masks of Kirsch operator give the positive weights to five consecutive
neighbours and the negative weights to another three consecutive neighbours. The
Kirsch edge detector is the first derivative approach that sets the central point of each
mask by a zero. The masks of Kirsch operator are defined as follows:
5⎤
⎡- 3 - 3 - 3⎤
⎡- 3 - 3 - 3⎤
⎢
⎥
⎥
5⎥, G(2) = ⎢- 3 0 5⎥, G(3) = ⎢⎢- 3 0 - 3⎥⎥ ,
⎢⎣- 5 5 5⎥⎦
⎢⎣- 3 5 5⎥⎦
5⎥⎦
⎡- 3 - 3 - 3⎤
⎡ 5 - 3 - 3⎤
⎡ 5 5 - 3⎤
⎡ 5 5 5⎤
⎢
⎥
⎢
⎥
⎢
⎥
G(4) = ⎢ 5 0 - 3⎥, G(5) = ⎢ 5 0 - 3⎥, G(6) = ⎢ 5 0 - 3⎥, G(7) = ⎢⎢- 3 0 - 3⎥⎥
⎢⎣ 5 5 - 3⎥⎦
⎢⎣ 5 - 3 - 3⎥⎦
⎢⎣- 3 - 3 - 3⎥⎦
⎢⎣- 3 - 3 - 3⎥⎦
⎡- 3 - 3
⎡- 3 5 5⎤
⎢
⎥
G(0) = ⎢- 3 0 5⎥, G(1) = ⎢⎢- 3 0
⎢⎣- 3 - 3
⎢⎣- 3 - 3 - 3⎥⎦
16
Consequently, the Kirsch operators are eight directional masks. Effectively, the
masks show the magnitude of each direction. The maximum magnitude of the
derivative has been computed on pixel-by-pixel basis to detect the edge points. The
maximum magnitude of derivatives can be described as below:
K = max {K (i ) }
2.14
i =0 ,1,...,7
After edge extraction, additional processing may be required. To reduce the
amount of data even further, a thinning process can be applied to detect the thin lines for
a single pixel. Note that, the Prewitt and the Sobel operator can be upgraded to the eight
masks like Kirsch operator to obtain edge orientation images (Castleman, 1996).
2.3.4
Laplacian Filtering Method
Another approach to detect edges is the Laplace equation. This method is
defined in terms of the second order differential equation, as follows:
∂2 f ∂2 f
∇ f (x , y ) = 2 + 2
∂y
∂x
2
2.15
The first order derivatives have local maxima or minima at image edges due to large
local intensity changes. Therefore, the second order derivatives have zero-crossings at
edge locations. Thus, an approach to detect edge position is to estimate the Laplace
equation and to find zero crossing positions (Pitas, 1993).
17
An estimator of the Laplace equation uses the central difference method of
∂2 f
∂2 f
and 2 given by
∂x 2
∂y
∂2 f
f ( x + 1, y ) − 2 f ( x, y ) + f ( x − 1, y )
= lim
2
h
→
0
∂x
h2
2.16
∂2 f
f ( x, y + 1) − 2 f ( x, y ) + f ( x, y − 1)
= lim
2
k
→
0
∂y
k2
2.17
where h and k are constants. Substituting equations 2.16 and 2.17 into equation 2.15 and
set h = k = 1 . The equation yields
∇ 2 f ( x, y ) = f ( x + 1, y ) + f ( x − 1, y ) + f ( x, y + 1) + f ( x, y − 1) −
4 f ( x, y )
2.18
Equation 2.18 can also be written as the mask,
⎡0 1 0 ⎤
L = ⎢⎢1 − 4 1⎥⎥
⎢⎣0 1 0⎥⎦
Laplace equation is isotropic and symmetric for rotation increments of 45 and 90
degree respectively (Salleh et al., 2005). Another approximation to the Laplace equation
includes the diagonal neighbours, as follows:
∇2 f ( x, y) = f ( x + 1, y) + f ( x − 1, y) + f ( x, y + 1) + f ( x, y − 1) +
f ( x + 1, y + 1) + f ( x + 1, y − 1) + f ( x − 1, y + 1) +
f ( x − 1, y − 1) − 8 f ( x, y)
2.19
18
and the mask of 3x3 size is given by
⎡1 1 1⎤
L = ⎢⎢1 − 8 1⎥⎥
⎢⎣1 1 1⎥⎦
Thus, the Laplace method is the second order differential that tends to enhance
image noise. It makes the method creates several false edges. Normally, the method is
used in line with the Laplacian of Gaussian (LoG), which handles noise in a more
effective way (Salleh et al., 2005). In Laplacian of Gaussian edge detection, there are
mainly three steps:
i.
Filtering
ii.
Enhancement
iii.
Detection
Gaussian filter is used for smoothing and the second derivative is used in the
enhancement step. The detection criterion is the presence of a zero crossing in the
second derivative with the corresponding to a large peak in the first derivative
(Castleman, 1996).
In this approach, the noise can be reduced by convoluting the image using
Gaussian filter. Isolated noise points and small structures are filtered out from the edges
and therefore, the edges will be smoother. Most the pixels have a local maximum
gradient that correspond an edge, occur around the zero crossing in the second
derivative. In other words, the edges are said to be present if there exists a zero crossing
in second derivative and if magnitude of the first derivative exceeds a threshold at the
same location (Chanda and Majumder, 2000).
19
2.3.5
Gaussian Smoothing Filter
It is sometimes useful to apply a Gaussian Smoothing Filter to an image before
performing edge detection. The filter can be used to soften edges, and to filter out
spurious points (noise) in an image. However, there will also be a lot of unwanted edge
fragments appearing due to noise and fine texture. The figure below shows the example
of Gaussian matrix of 7x7 size.
⎡
⎢
⎢
⎢
⎢
G=⎢
⎢
⎢
⎢
⎢
⎣
1
1
2
2
2
1
1
Figure 2.4
1
2
2
4
2
2
1
2
2
4
8
4
2
2
2
4
8
16
8
4
2
2
2
4
8
4
2
2
1
2
2
4
2
2
1
1
1
2
2
2
1
1
⎤
⎥
⎥
⎥
⎥
⎥
⎥
⎥
⎥
⎥
⎦
The Gaussian matrix of 7x7 size
The filter is applied in the following way:
k (i , j ) =
⎞
1⎛ n n
⎜ ∑ ∑ G (i , j ) f (i , j )⎟
⎟
⎜
s ⎝ i =1 j =1
⎠
2.20
where, k is the filtered value of the target pixel.
f is a pixel in the 2D grid.
G is a coefficient in the 2D Gaussian matrix,
n is the vertical/ horizontal dimensions of the matrix. e.g. n is set to 7.
and s is the sum of all values in the Gaussian matrix
20
The input of the Gaussian filter is a masks of an image as shown in Figure 2.4
and the output is a centre pixel value of the mask. In order to reduce the blurring of
edges, an edge-preserving Gaussian smoothing is used in which the original replaced by
the new computed value if the difference between the two is greater than a given
threshold (Manohar, 2004). Also due to Gaussian smoothing the resulting image
becomes darker. This is mainly because the range of pixel values in the result is small
when compared to the actual range that can be represented in grey-level. This effect can
be alleviated by doing a contrast clipping on the final image.
2.4
Thresholding
Binary images are simpler to analyse than grey-level images, but digital images
often cannot be transformed directly to binary without some pre-processing. Usually,
the thresholding involves the selection of intensity that corresponds to an image f(x,y).
The intensity composed of light objects on a dark background, in such a way that it is
grouped into two regions (Gonzalez, 2004).
An obvious way to extract the objects from the background is to select a
threshold, T that separates these regions. The object point can be detected the image
f ( x, y ) ≥ T . Otherwise, the point is called a background point. The mathematical
definition of standard binary threshold is described below:
⎧1
h(x, y ) = ⎨
⎩0
if f (x, y ) ≥ T
if f ( x, y ) < T
2.21
21
Selection of the value of threshold, T is a critical issue. The threshold can simply
be selected either manually or automatically. In the manual case, the intensity must be
observed in order to get the ideal threshold value. But usually, a digital image has
different intensity. Therefore, to get the ideal threshold value by observing the intensity
will be time consuming. In this case, the automatic concept by mathematical approach
is relevant used in getting the ideal threshold value.
One way to choose a threshold value is to use the intensity of image histogram.
Gonzalez et al. (2004) describe a threshold automatically as a mid-point between the
minimum, T1 and maximum, T2 intensity values in the image. The minimum and
maximum intensity can be described as in equation 2.22.
T1 =
min { f (x , y )} and,
x =0,1,...,m
y =0,1,...,n
T2 =
max { f (x , y )}
x =0,1,...,m
y =0,1,...n
2.22
where m and n are image size, x and y correspond to the column and row of image array.
The threshold can be calculated as below.
T =
1
(T1 + T2 )
2
2.23
Another way to get a threshold value is by using an average of intensity value.
Salleh et al. (2005) used this approach to separate the image in their example works.
The summation of intensity values was divided by the size of image as describes below.
1 m n
T=
∑∑ f (x , y )
mn x =0 y =0
2.24
22
Pitas (1993) also proposed some heuristic adaptation technique to determine the
threshold value, T (k ,l ) . The method is to calculate the local arithmetic mean of the
intensity image. It is described by
⎛ 1 ⎞
T3 (k ,l ) = ⎜
⎟
⎝ mn + 1 ⎠
2 x+m
l +n
∑ ∑ f (x , y )
2.25
x =k −m l = y −n
and this value will be used to calculate the threshold given be equation 2.26.
T (k, l ) = (1 + β )T3 (k, l )
2.26
where β is a percentage indicating the level of the threshold, 0 < β ≤ 1 above the local
arithmetic mean.
As mentioned, one of the objectives in this study is to evaluate the Hough
Transform by using different threshold value. Based on the thresholding proposed by
Pitas (1993), this study uses a rate of the maximum thresholding to determine the
threshold value. The threshold calculation is:
T = α T2
2.27
where α is the rate of the maximum threshold, T2 given in equation 2.22 with
0 < α ≤ 1.
In this study, the thresholding is used for different functions, specifically in the
Kirsch and Sobel Edge Detector, the Hough Line and Corner Detector. The thresholding
of the Kirsch and Sobel Edge Detector is used to separate the image into two regions,
which are black and white pixel colours or value 1 and 0 in binary image. Meanwhile,
23
the thresholding in the Hough Line Detector is applied to the accumulator in detecting
the significant lines. The thresholding of the Hough Corner Detector is used to
determine the real corner from the corner candidate.
We use α 1 , α 2 and α 3 as a parameter to evaluate the performance of Hough
Transform under different value of α , where α 1 is correspond to the rate of
thresholding in Kirsch and Sobel Edge Detector, α 2 and α 3 are correspond to the
Hough Line and Corner Detector.
2.5
Thinning Problems
Thinning can be defined heuristically as a set of successive erosions of the
outermost layers of a shape, until a connected unit width set of lines (skeleton) is
obtained (Pitas, 1993). Thinning algorithms examine the neighbourhoods of each
contour pixel and identify those pixels that can be skeletal pixel and deleted. These
algorithms reduce the thickness of the object in a binary image to produce thinner
representations called skeletons.
These algorithms have been used in many applications such as pattern
recognition, medical image analysis, text and handwriting recognition, fingerprint
classification, printed circuit board design, robot vision and automatic visual analyses of
industrial parts.
24
The thinning algorithms can be classified into two categories, iterative thinning
algorithms and non-iterative thinning algorithms (Engkamat, 2005). Figure 2.5 shows
the classifications of thinning algorithms. The iterative thinning algorithms use a pixel
scheme based on the eight-neighbourhood, while the non-iterative thinning algorithms
consider the centre line of the pattern only without examining the entire individual
pixels.
Thinning
Algorithms
Iterative
(Pixel based)
Parallel
Non-iterative
(Non-pixel based)
Sequential
Line Following
Medial Axis
Transform
Figure 2.5
2.5.1
Fourier
Transform
Classification of common thinning algorithm (Engkamat, 2005)
Simple Thinning Method
Simple Thinning is an iterative algorithm that converts border pixel from 1 to 0.
Connectivity is an essential property, which is preserved in the thinned object.
Therefore, border pixels are deleted in such a way that object connectivity is stable.
25
This Simple Thinning algorithm satisfies the following two constraints (Pitas, 1993).
Maintain connectivity at each iteration. Border pixels whose removal
1.
may cause discontinuities are shown as in Figure 2.6(a).
Do not shorten the end of thinned shape limbs. Border pixel whose
2.
removal will shorten the end of thinned shape limbs are shown in Figure
2.6(b).
0
0
0
0
0
0
1
1
0
1
1
0
0
0
1
0
0
0
(a)
(b)
Figure 2.6(a) Illustrate the not deleted pixels that may cause discontinuities
Figure 2.6(b) The pixel whose removal will shorten an object limb
The algorithm operates in an eight-neighbourhood as shown below:
P8
P1
P2
P7
P
P3
P6
P5
P4
Figure 2.7
The eight-neighbourhood of pixel, P
26
The basic disadvantage of this algorithm is that it does not thin the image object
symmetrically (Pitas, 1993). This algorithm does not perform in a satisfactory way
when the binary image objects are relatively large and convex. A more elaborate
thinning algorithm that thins the edges symmetrically is described in Zhang and Suen
algorithm.
2.5.2
Zhang-Suen Skeletonizing
The Zhang-Suen thinning algorithm is a parallel method, where the new value of
any pixel can be computed using only the values known from previous iteration (Ritter
and Wilson, 2001). It uses the eight-neighbourhood to verify boundary point for
validating the skeletal.
In this algorithm the 3x3 window has been used and the contour pixel P, which
the centre pixel is connected to the other eight neighbouring pixels. Let P1 , P2 ,..., P8 be
the eight neighbours of P (shown as in Figure 2.7) and Pi ∈{0,1} is taken from the source
image (binary image). The selected contour pixels are removed iteratively until a
skeletal pixel remains. A contour pixel is a point that has pixel value 1 and another eight
neighbouring pixel has value 0 or 1.
Let N (P ) be the number of nonzero of the eight neighbours of P and let N (T )
denote the number of ‘zero to one’ pattern in the ordered sequence P1 , P2 ,..., P8 , P1 . The
‘zero to one’ pattern is the transition bit from 0 to 1 of the ordered sequence
P1 , P2 ,..., P8 , P1 to determine the number of a connected component.
27
If the number of 0 → 1 transitions in this sequence is 1, only one connected
component presents in the eight-neighbourhood of pixel P (Pitas, 1993). In this case, it
is allowed to verify the contour pixel whether it is a centre of the eight-neighbourhood or
not. This verification involves some conditions to check the boundary position and the
corner direction of the eight-neighbourhood of pixel P.
The conditions consist of two sub-iterations. The first sub-iteration removes the
southeast boundary points and northwest corner points.
The second sub-iteration deletes the northwest boundary points and southeast corner
points (Ritter and Wilson, 2001). In the first sub-iteration, the conditions that must be
satisfied are:
i.
2 ≤ N ( P) ≤ 6
ii.
N (T ) = 1
iii.
P1 • P3 • P5 = 0
iv.
P3 • P5 • P7 = 0
In the second sub-iteration, the conditions (i) and (ii) are same as in the first subiteration but only conditions (iii) and (iv) are changed to:
iii.
P7 • P1 • P3 = 0
iv.
P1 • P7 • P5 = 0
When N (T ) > 1 , the contour P cannot be removed. Under this condition, it has
more part of ‘zero to one’ patterns around the contour P and makes more regions. When
no more pixels to be removed the algorithm is stopped. The algorithm will produce a
thin image with minima binary value.
28
2.5.3
Medial Axis Transform
The Medial Axis is the locus of the corners and forms the skeleton of the object
(Parker, 1997). The function of Medial Axis treats all boundary pixels as point sources
of a wave front. The wave (line) passes through each point only once. So when the two
waves meet it produces a corner. Usually the Medial Axis is used to get the skeleton of
an object with full region binary.
One way to find the medial axis is to use the boundary of the object. Firstly,
compute the distance from each object pixel to the nearest boundary pixel. Next, the
Laplacian of the distance image is calculated and pixels having large values are medial
axis. Figure 2.8 shows an example of computing the distance transform.
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
0
0
0
0
0
0
0
1
1
1
1
1
1
0
0
0
0
0
0
0
1
1
1
1
1
1
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
1
1
0
0
1
1
1
1
1
1
1
1
1
1
1
0
0
1
1
1
1
1
1
1
1
1
1
1
0
0
1
1
1
1
1
1
1
1
1
1
1
0
0
1
1
1
1
1
1
1
1
1
1
1
0
0
1
1
1
1
1
1
1
1
1
1
1
0
0
1
1
1
1
1
1
1
1
1
1
1
0
0
1
1
1
1
1
1
0
0
0
0
0
0
0
1
1
1
1
1
1
0
0
0
0
0
0
0
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
(a)
Figure 2.8
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
0
0
0
0
0
0
0
1
2
2
2
2
1
0
0
0
0
0
0
0
1
2
3
3
2
1
0
0
0
0
0
0
0
1
2
3
3
2
1
1
1
1
1
1
0
0
1
2
3
3
2
2
2
2
2
2
1
0
0
1
2
3
3
3
3
3
3
3
2
1
0
0
1
2
3
4
4
4
4
4
3
2
1
0
0
1
2
3
3
3
3
3
3
3
2
1
0
0
1
2
3
3
2
2
2
2
2
2
1
0
(b)
Example of computing distance transform of binary image:
(a) a full region binary image,
(b) a distance transform obtained
0
1
2
3
3
2
1
1
1
1
1
1
0
0
1
2
3
3
2
1
0
0
0
0
0
0
0
1
2
2
2
2
1
0
0
0
0
0
0
0
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
29
Pixels that belong to the medial axis of a connected component or object may not
in general be connected (Chanda and Majumder, 2000). Thus, it apparently loses some
important shape information that is very useful for image analysis. Most researchers
would agree that the Medial Axis Transform is an ideal skeleton but it takes long
computation (Parker, 1997). However, the Medial Axis Transform can describe the
basis concept of the thinning method.
The Medial Axis was found for the skeleton object using the Euclidean distance,
4-connected boundary and 8-connected boundary. There are clear differences in the
Medial Axis depending on how the distance is calculated. Figure 2.9 shows a skeleton
image by using 8-connected boundary.
0
0
0
0
0
0
0
0
0
0
0
0
0
Figure 2.9
0
1
0
0
0
0
1
0
0
0
0
0
0
0
0
2
0
0
2
0
0
0
0
0
0
0
0
0
0
3
3
0
0
0
0
0
0
0
0
0
0
0
3
3
0
0
0
0
0
0
0
0
0
0
0
3
3
0
0
0
0
0
0
1
0
0
0
0
3
3
0
0
0
0
0
2
0
0
0
0
0
3
4
4
4
4
4
3
0
0
0
0
0
0
3
3
0
0
0
0
0
2
0
0
0
0
0
3
3
0
0
0
0
0
0
1
0
0
0
0
3
3
0
0
0
0
0
0
0
0
0
0
0
3
3
0
0
0
0
0
0
0
0
0
0
2
0
0
2
0
0
0
0
0
0
0
0
1
0
0
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
Medial Axis matrix of the binary image shown in Figure 2.8(a) using
8-connected boundary
30
2.6
Corner Detection Problems
Generally, corners can be described as two or more meeting lines or sides. In
other words, a corner is yielded when two or more lines intersect each other. A corner
provides a feature of shape that is used in object matching and registration. Thus corner
detection is essential step in many image analysis and object recognition procedure.
Recently, the corner detection can be divided in two approaches (Chen et al.,
1995). The common method of the first approach is initially segment of an image into
regions and represents the object boundary with chain code. The second approach
works directly on the grey-level and mainly uses the gradient and curvature
measurements. Some corner detection methods are described in the following
subsections.
2.6.1
Hough Transform
The Hough Transform was developed by Paul Hough in 1962 and patented by
IBM (Ritter and Wilson, 2001). It became in the last decade a standard tool in the
domain of artificial vision for finding straight lines hidden in larger amounts of other
data. It is an important technique in image processing. For detecting lines in images,
the image is first binaries using some form of thresholding and then the positive
instances catalogued in an examples dataset.
31
The idea of the Hough Transform is that each of these points votes for several
combinations of parameters. The parameters that win a majority of votes are declared
the best lines, circles or ellipses given by these points.
Davies (1988) applied the generalised Hough Transform to corner detection in
line mode as square object detection and look for peaks in parameter space. The
approach has the advantage that it can be used when objects have curved sides or blunt
corners. It can be tuned for varying degrees of corner bluntness.
Shen and Wang (2002) simplified the corner detection problem into detecting
simple lines using the Hough Transform. They presented a dynamic edge detection
scheme based on both gradient magnitude threshold and grey level analysis. The Hough
Transform is very time consuming if the dimension of its parameter space is high. Also,
Hough Transform depends on the performance of the edge detector. General edge
detector cannot localise edge points well around corners, leading to errors in reporting
corners.
2.6.2
Wavelet Transform
The fundamental idea behind wavelets is to analyse according to scale. Indeed,
some researchers in the wavelet field is adopting a whole new perspective in processing
data. Wavelets are functions that satisfy certain mathematical requirements used in
representing data or other functions.
32
This idea is not new. In wavelet analysis, the scale that is used to analyse the data
plays a special role. Wavelet algorithms process data at different scales or resolutions.
Lee et al. (1995) proposed a multiscale corner detection algorithm based on Wavelet
Transform of contour orientation. They utilize both information of the local extrema
and modulus of transform results to detect corners and arcs effectively. The ramp width
of contour orientation profile, which can be computed using the transformed modulus of
two scales, is utilized in the determination of corner points.
Chen et al. (1995) also proposed a new edge detector based on the ratio of the
inter scale wavelet transform modulus. This edge detector can correctly detect edges at
the corner positions, making accurate corner detection possible. They apply the nonminima suppression scheme to edge image and extract the minima image. By the
orientation variance, these non-corner edge points are eliminated. In order to locate the
corner points, they propose a corner indicator based on the scale invariant property of
the corner orientations.
2.6.3
Chain Code Representation
Binary image consists of binary values such as 0 and 1. Every pixel of value 1
has a connected path to represent an object. Freeman (1961) introduced a representation
consisting of codes representing direction that involves 4-connected and 8-connected
paths. Each segment possesses a specific direction if boundary is traversed in a
clockwise manner. The chain directions can be coded in the way shown in Figure 2.10
for 4-connected and 8-connected chains.
33
1
2
3
0
3
(a)
Figure 2.10
2
4
5
1
0
6
7
(b)
Direction of boundary segments of a chain code for
(a) a 4-connected chain, (b) an 8-connected chain
The boundary of an object is represented by a connected path of value 1 in a
binary image. The path which is 4-connected or 8-connected chains can be considered
to consist of line segments connecting adjacent pixels. Each segment possesses a
specific direction if the boundary is traversed in a clockwise manner. The codes of the
successive boundary segments are taken from the boundary segments of a chain code.
The chain code depends on the starting pixel of the boundary. An advantage of chain
code is that it is translation invariant (Pitas, 1993). Scale invariance can be obtained by
changing the size of the sampling grid. However, such a resampling seldom produces
exactly the same chain code.
Haron et al. (2005) proposed a corner detection algorithm for thinned binary
image by using an 8-connected chain code. The algorithm is based on chain-coded
image deriving from the slope between each code. Then the series is analysed and
checked for the existence of corner at the current pixel location. He also identified that
the length of segment and threshold value was identified as significant factors in
determining the accuracy of corner detection.
34
2.7
Summary
This chapter explains all the stages in the project framework of this study. Three
stages must be focused in order to understand the overall process i.e the edge image, the
minima image and locating corners. In the edge image stage, the Kirsch and Sobel edge
detector will be used in the case study. While in the minima stage, the Zhang-Suen
Skeletonizing will be used to build the thin image in binary form. This study emphasizes
the application of Hough Transform in corner detection problem.
CHAPTER III
THE HOUGH TRANSFORM
3.1
Background
The Hough Transform is a feature extraction technique which can be used to
isolate features of a particular shape within an image. Developed by Paul Hough in
1962 and patented by IBM with the name "Method and Means for Recognizing Complex
Patterns" (Wikipedia). The Hough Transform is used in a variety of different
algorithms for pattern recognition.
The transform consists of a slope-intercept parameterisation (mc-space) for
straight lines, which awkwardly leads to an unbounded transform space since the slope
can go to infinity. Universally, the rho-theta parameter (rθ-space) is in popular used
today.
36
3.2
Method of Line Detection
The underlying principle of the Hough Transform is that there are an infinite
number of potential lines that pass through any point at different orientation. The idea
of the transform is to determine each point votes for several combinations of parameters.
The parameters that win a majority of votes are declared the best line given by these
points.
Consider a point (xi , y i ) in the image. The Hough Transform describes the line
as y = mx + c . Here x and y are the observed points and m and c are the parameters.
There are infinitely many lines that pass through this point, but they all satisfy the
condition
y i = mxi + c
3.1
for varying values of m and c. See Figure 3.1 below:
Figure 3.1
The line passing two points
37
The idea of the Hough Transform is to write the line equation in a new form.
Equation 3.1 can also be written as
c = −mxi + yi
3.2
where x and y to be a constant and m and c are the varying parameters. When their
values of m and c are changed, the line on the Figure 3.1 can be transformed shown in
Figure 3.2.
Figure 3.2
The intersection of two lines in the mc-plane correspond to a line in the
xy-plane
Each point in the xy-plane corresponds to a line in the mc-space. If the xy-plane
has 10 points on a line then the mc-space will have 10 lines. Thus, the intersection
between each line in the mc-space shows that the points lie on the same line. However,
Equation 3.2 has a problem to represent vertical lines. In that case, m = ∞ and the
parameter space is unbounded. For solving this case, Hough represents an alternative
way to describe lines as
r = xi cosθ + y i sin θ
3.3
38
where r is the perpendicular distance from the origin to the line and θ is the angle
between r and the x-axis. The parameter space is now in r and θ, where 0° ≤ θ ≤ 180°
and r is limited by the size of the image, −
1
2
x2 + y2 ≤ r ≤
1
2
x2 + y2 .
Equation 3.3 be obtained from the Cartesian coordinate using the Trigonometry
Identities and Theorem Pythagoras. Figure 3.3 shows the relationship between r, θ, x
and y.
r = xcosθ + ysinθ
Figure 3.3
The illustration of r and θ in the line
From Figure 3.3, it can be seen that
x = r cosθ and y = r sin θ
3.4
From Theorem Pythagoras, we know that
r 2 = x2 + y2
3.5
39
Substituting 3.4 into 3.5 gives us
r 2 = x2 + y2
= (rcos θ ) + (rsin θ )
2
2
................................ from 3.4
r = rcos 2 θ + rsin 2 θ
r = (rcosθ )cosθ + (rsinθ )sinθ
∴ r = xcosθ + ysinθ
To implement the method in the discrete domain, rθ-plane is approximated by a
two-dimensional array, which is called an accumulator A as shown in Figure 3.4
(Chanda and Majumder, 2000). It is expected that the elements A(θ, r) corresponding to
the point of intersection curves in rθ-plane would be incremented more rapidly than any
other cell. Hence, a local maximum in accumulator A gives the parameters of a line in
the rθ-plane on which relatively large number of points lie.
θ
r
Figure 3.4
An accumulator array
40
3.3
Method of Corner Detection
When the Hough Transform detects the line, we can apply the straight-line
equation to find the corner point. We must verify it whether the lines are parallel or
intersect. The following theorems show the relationship between the slope, the angle
and the type of lines (Raji et al., 2002).
Theorem 3.1:
The relationship between slope and the angle of line
If a line with the slope m makes an angle Q towards
positive x-axis, then m = tan Q
Theorem 3.2:
The relationship between the slopes of two perpendicular
Lines
Two lines with the slopes of m1 and m2 are
perpendicular, if m1m2 = -1
The angle Q between two intersecting lines with known slopes is given
⎛ m − m1 ⎞
⎟⎟
Q = tan − 1 ⎜⎜ 2
⎝ 1 + m2 m1 ⎠
3.6
where, m2 m1 ≠ −1
From this formula, we can conclude that
a) when Q = 0°, that is when both lines are parallel (m1 = m2)
b) when Q = 90°, that is when both lines are perpendicular from theorem 3.2
(m1m2 = -1)
c) two lines are intersecting when 0° < Q < 180°
41
From Equation 3.6, if m1 and m2 are the same, then the lines are parallel. We can
make an assumption that the intersecting lines are not parallel, where m2 ≠ m1 . We
need to compute the slope of lines to verify the characteristics of lines. Theorem 3.1
gives mi = tan θ i and θ i can be determined from the peak of the accumulator in Hough
Line Detector.
When corner is detected by the non-parallel lines, the corner points can be
computed using linear equation. Suppose we have two different r and θ as below,
r1 = x cosθ1 + y sin θ1
3.7
r2 = x cosθ 2 + y sin θ 2
3.8
Equation 3.7 and 3.8 can be written in matrix from as
⎡ r1 ⎤ ⎡ cos θ1
⎢r ⎥ = ⎢cos θ
2
⎣ 2⎦ ⎣
sin θ1 ⎤ ⎡ x ⎤
sin θ 2 ⎥⎦ ⎢⎣ y ⎥⎦
3.9
This can be rewritten as
ri = Ai t
⎡ r1 ⎤
⎡ cosθ1
⎡ x⎤
where, ri = ⎢ ⎥ ,t = ⎢ ⎥ and Ai = ⎢
⎣ y⎦
⎣r2 ⎦
⎣cosθ 2
3.10
sinθ1 ⎤
. Therefore, the intersection
sinθ 2 ⎥⎦
point ( x , y ) , is given as
t = Ai−1 ri
3.11
42
We can compute the inverse of Ai as below
Ai−1 =
=
1
sin θ 2 cos θ1 − cos θ 2 sin θ1
1
sin (θ 2 − θ1 )
⎡ sinθ 2
⎢− cosθ
2
⎣
⎡ sin θ 2
⎢− cos θ
2
⎣
− sin θ1 ⎤
cos θ1 ⎥⎦
− sinθ1 ⎤
cosθ1 ⎥⎦
Substitute into 3.11, the corner can be detected as
⎡x ⎤
⎡ sinθ 2
1
⎢ y ⎥ = sin (θ − θ ) ⎢− cosθ
2
⎣ ⎦
2
1 ⎣
⎡x ⎤
1
⎢ y ⎥ = sin (θ − θ )
⎣ ⎦
2
1
− sinθ1 ⎤ ⎡ r1 ⎤
cosθ1 ⎥⎦ ⎢⎣r2 ⎥⎦
⎡ r1sinθ 2 − r2 sinθ1 ⎤
⎢r cosθ − r cosθ ⎥
1
1
2⎦
⎣2
⎡ x ⎤ ⎡ R1 sin θ 2 − R2 sin θ1 ⎤
⎢ y ⎥ = ⎢ R cos θ − R cos θ ⎥
1
1
2⎦
⎣ ⎦ ⎣ 2
where
R1 =
r1
sin(θ 2 − θ 1 )
and R2 =
3.12
r2
sin(θ 2 − θ 1 )
We can apply Equation 3.12 into the algorithm to detect the corner. Before that,
we need to determine the parameters of ri and θ i, which is obtained from the
accumulator of Hough Line Detector described in section 3.2. In real time processing,
we have found many lines that imply the corner candidates. Therefore we must find a
method to minimize the corners in order to detect the corners accurately.
The approach that we use to detect the real corner is by using the thresholding in
corner candidates. We assume that real corners have many lines intersecting at one
point. So, we need to determine the highest number of lines intersecting at one point to
be the threshold value to separate the corner candidates.
43
3.4
Algorithm for Line and Corner Detection
After filtering the digital image, the thinning image will be built. The thinning
image has the boundary object with the connection pixel of value 1. We use the
connected pixel with value 1 to detect a line. For apply this process, the two-dimension
array of accumulator A must be built and then initialise every element A(t,r) with a zero.
Note that, a parameter t in the accumulator A refers to a parameter θ in rθ-plane. The
accumulator A has r =
x 2 + y 2 row size and t = 360 column size where x and y
correspond to the image size.
Through programming, the elements A(t, r) is written as A[r][t] and the image
pixel f(x,y) is written as f[i][j] where, x corresponds to column j and y corresponds to
row i. The array image f[i][j] uses Equation 3.3 to compute r with 0 ≤ t ≤ 360 . The
same r and t that is obtained by Equation 3.3 will be stored into the element A[r][t].
For such cases, the element A[r][t] will be increased by 1 for each lies with same
parameters. The large value of accumulator A can be assumed as the lines. But in this
case, we use the thresholding to detect significant lines. The significant lines can be
detected according to the following algorithm as shown in Figure 3.5.
The Hough Transform also can be used to detect a corner. The determined
parameters r and t in the accumulator A are stored by parameters rho[i] and theta[i].
Then, the parameters rho[i] and theta[i] will be used to detect whether the lines are
parallel or not. When the lines are not parallel, the corner points can be detected using
Equation 3.12. The algorithm to detect the corner points is described in Figure 3.6. This
algorithm also uses the thresholding to separate the significant corners from corner
candidates.
44
Step 1:
Initialise all elements of A[r][t] to zero.
Step 2:
For each pixel f[i][j] corresponding to the edge line
in the image, add 1 to all elements A[r][t], whose
indices r and t satisfy Equation 3.3, where
A[r][t]= A[r][t]+1
Step 3:
Determine the threshold value T from accumulator A and
set the largest value of element A[r][t] to be a
maximum value. The threshold value T is then calculated
using Equation 2.27.
Step 4:
Compare all the elements A[r][t] with the threshold
value. Determine r and t correspond to a line in the
[ ][ ]
accumulator A where A r t ≥ T and store into the
parameters rho[i] and theta[i].
Step 5:
The parameters rho[i] and theta[i] can be constructed
the lines with the connected path of value 1.
Figure 3.5
The algorithm of Hough Line Detector
Step 1:
Initialise the array image f[i][j] to zero.
Step 2:
Compute the slope m1 and m2 for all lines,
m1 = tan(theta[i]) and m 2 = tan(theta[i + 1])
Step 3:
If
(m1 ≠ m2 )
then compute the corner candidates by using
equation 3.12 and store into f[i][j].
Step 4:
Set threshold value T from the array image f[i][j]. The
maximum value is the highest intersecting pixel in
f[i][j].
Step 5:
Determine the real corners by using the thresholding.
If the real corners produce the pixel nearby, find the
converge pixel.
Figure 3.6
The algorithm of Hough Corner Detector
45
For example, assume the points (1,7), (3,5), (5,3) and (6,2) are on the same line
as shown in Figure 3.7 below:
Example 3.1
8
(1,7)
7
y -axis
6
(3,5)
5
4
Line
(5,3)
3
(6,2)
2
1
0
0
1
2
3
4
5
6
7
x -axis
Figure 3.7
The points in the xy-plane lying on a line
Hough Transform is generated and the indicated points are mapped to the sinusoidal
functions as follow.
r1 = cosθ 1 + 7 sin θ 1
r2 = 3 cosθ 2 + 5 sin θ 2
r3 = 5 cosθ 3 + 3 sin θ 3
r4 = 6 cosθ 4 + 2 sin θ 4
Each point in the line (as shown in Figure 3.7) corresponds to the sinusoidal function
that intersects at θ = 45 and r = 5.66 as shown in Figure 3.8. Therefore, the line in
Figure 3.7 corresponds to θ = 45 and r = 5.66 . From this example, we can make an
assumption that a line in the xy-plane must has their own value of r and θ. The
algorithm of Hough Line Detector use parameters rho[i] and theta[i] to store every
determined r and θ.
46
Hough space
(1,7)
r -axis
8
(45,5.66)
(3,5)
6
(5,3)
4
(6,2)
2
0
-2 0
50
100
150
200
-4
-6
-8
theta -axis
Sinusoidal functions are associated with points on a line.
Figure 3.8
A corner is defined as the intersection of two or more straight lines. Based on
this definition, the Hough Transform can detect a corner by using Equation 3.12.
Suppose we use the same example as in Figure 3.7 and add a line that intersects at the
point (3,5). The lines are shown in Figure 3.9.
Example 3.2
8
7
y -axis
6
as a corner point
(3,5)
5
Line 1
Line 2
4
3
2
1
0
0
1
2
3
4
5
6
7
x -axis
Figure 3.9
The two lines crossing at point (3,5) in Cartesian space
47
The line in Figure 3.9 is transformed to the Hough space as in Figure 3.10. The
figure shows the two points with the highest intersection of the sinusoidal functions. We
obtain the points (45, 5.66) and (135, 1.41) as the intersection points (corners) in Figure
3.10. Before that, we must compute m1 and m2 to verify the parallel lines. We have
r1 = 5.6, θ 1 = 45° and r2 = 1.41, θ 2 = 135° and then compute mi = tan θ i we obtain
m1 = 1 and m2 = −1 . Since m2 ≠ m1 , we see that the lines are not parallel. After that,
we compute the intersecting point or the corner using Equation 3.12, we have
⎡ x ⎤ ⎡3.0052⎤ ⎡3⎤
⎢ y ⎥ = ⎢4.9992⎥ ≈ ⎢5⎥ as shown in Figure 3.9.
⎦ ⎣ ⎦
⎣ ⎦ ⎣
Hough space
(1,7)
(3,5)
10
8
6
(5,3)
(6,2)
(45,5.66)
(1,3)
r -axis
4
0
-2 0
(5,7)
(135,1.41)
2
50
100
150
200
-4
-6
-8
theta -axis
Figure 3.10
The sinusoidal function of point (3,5) lies on two points that
corresponds to the high lines crossing.
48
3.4
Summary
The lines produced by the Hough Transform probably are not the lines that
human viewer would select. The arbitrary line can be detected by using the value in the
accumulator. The criterion for an exact line in the Hough Transform sense is a large
number in the collinear points. The Hough Transform uses the accumulator to set the
point in the arbitrary lines. Each element in the accumulator represents a line in the xyplane. This means the accumulator size is based on the size of image. The Hough
Transform needs to construct a big array to store the element value in accumulator that
corresponding to a line. There fore, a large memory space is needed for the operation of
line detection.
CHAPTER IV
CASE STUDY IN CORNER DETECTION
4.1
Introduction
In this chapter, a simple model is developed to implement the algorithm and
method that had been discussed in Chapter II by using Microsoft Visual C++ 6.0. The
model is used to show the concept and their calculations. The main tasks are to get the
local minima image by using the edge detection and thinning them. For the edge
detection, the Sobel and Kirsch Operator are used to detect edges and the Zhang-Suen
thinning algorithm is used to solve the thinning problem. The last stage is to detect
corners by using the local minima result in the thinning image. This study uses the
Hough Transform for searching the corners that are direct to the object behaviour. The
final result will be an image that has corner points and the binary image with numbers
that refer to the corners.
50
4.2
Edge Image
The first stage is to get the edge image from the digital image in the bitmap
format. The Kirsch and Sobel operator is used to compute the magnitude (derivative)
and the image will be extracted as the edges. Before extracting, the threshold value must
be determined from the image. The threshold value uses Equation 2.27 to separate the
object from the background. Then, condition 2.21 is used to convert the intensity value
in array to a binary value.
Through programming, it uses [i][j]-notation instead of ( x , y ) -notation where
row i and column j correspond to y and x in xy-plane. Therefore, to apply the equation is
described in Chapter II and III, we need to change ( x , y ) -notation into [i][j]-notation.
The edge detection algorithm use the array f[i][j] that corresponds to input of image and
array h[i][j] correspond to output of process image. The algorithm is described in
Figure 4.1.
Step 1:
Set image size (xSize,ySize).
Step 2:
Initialise the image into array f[i][j]. Determine the
grey value in image.
Step 3:
Compute threshold value T by using Equation 2.27
Step 4:
Compute the derivatives of Kirsch and Sobel operator and
determine the maximum magnitude of derivative, K[i]
max=K[0]
for c=1 to 7
if (max<K[c]) max = K[c]
Step 5:
Compare all max for each f[i][j] with T and save the
result into h[i][j] that correspond to edge image with
binary value.
if (max >= T) then h[i][j] = 1;
else
h[i][j] = 0;
Figure 4.1
Kirsch and Sobel Algorithm for computing the edges of an image
51
As an example, consider the generated 10x10 pixels of image in bitmap format.
Let f[i][j] corresponds to the pixel image and contains eight bits of data, which has the
value between 0 to 255 for each pixel in grey-level image. Figure 4.2 represents the
extracted image that be declared in grey value.
1
2
3
4
5
6
7
8
9
10
Figure 4.2
1
144
144
144
144
144
144
144
152
152
152
2
152
152
160
152
152
152
152
160
160
160
3
144
152
152
152
160
168
176
176
168
168
4
152
152
152
160
192
224
240
240
240
240
5
152
152
160
168
208
248
255
255
255
255
6
152
152
160
168
224
255
255
255
255
255
7
152
152
160
176
232
255
255
255
255
255
8
152
152
160
176
232
255
248
255
248
255
9
152
160
160
176
232
255
255
255
255
255
10
152
160
160
176
232
255
255
255
255
255
The original pixel values of an image size of 10x10 matrix.
We want to implement the edge detection using the Kirsch and Sobel operator.
We apply the algorithm, which is described in Figure 4.1 to extract the image using the
example given (as shown in Figure 4.2). The algorithm is applied in the following steps.
Step 1: Set a image size
We know the image is the matrix with 10x10 size. Therefore, the image has a
xSize = 10 and ySize = 10.
52
Step 2: Initialise the array image f[i][j]
In windows, the bitmap image is represented by 24 bits of data that contains total
of 16,777,126 colours (Salleh et al., 2005). This will cause the computation to involve
large values. To initialise the values, every pixel is held by array f[i][j]. In the next
process, the image needs to be transformed into grey-level image. The transformation
involves a bit-shifting function to move the bit values that refer to the colour.
The bitmap uses the RGB values for every colour pixel. RGB are red, green and
blue colour, which has eight bits data for each colour. The transformation will shift the
bit colour into a grey value.
174
55
Red
A
Green
3
B
171
Blue
7
A
E
1 0 1 0 1 0 1 1
0 0 1 1 1 0 1 1
1 0 1 0 1 1 1 0
Blue
Green
Red
Figure 4.3
A pixel represented as a 24-bit string (Salleh et al., 2005).
53
For example, we have a pixel f[1][2] = RGB (174,55,171) as shown in Figure
4.3. In windows the pixels are represented in binary or hexadecimal value. The pixels
need to be converted into grey-level image by shifting the bit values for every colour
involved.
First, the red colour pixel is obtained by shifting 16 bits to the right. Then, shift 8
bits to the left to get the green colour. To get the blue colour, shift 8 bits to the left from
green colour. All colours bits are added to get the grey-level pixel. The process can be
described as follows using the function in Microsoft Visual C++.
f[0][0]=RGB(174,55,171)=AB37AE
R=f[0][0]>>16=0000AB
G=R<<8=00AB00
B=G<<8=AB0000
f[0][0]=R+G+B=ABABAB=11250603
In this case study, we use 8 bits data that contains 0 to 255 for keeping the
calculation simple. Therefore, no shifting is needed in this case. The initialise value of
f[i][j] is same as in Figure 4.2.
Step 3: Compute the threshold value T
From the image in Figure 4.2 the maximum intensity value is 255. Equation 2.27
is used and arbitrary set α to 0.7. Therefore the threshold value is T = 178.5. In this
case the image is in integer form. After integer function int( ) in Microsoft Visual C++
has been applied, the threshold value is T = 178. This threshold value will then be used
to separate the intensity of image into two regions. The edge image can be obtained
after the separation process.
54
Step 4: Compute the Kirsch and Sobel operator
The Kirsch and Sobel operator is a combination algorithm between Kirsch
operator and Sobel operator. The Sobel coefficient in Sobel operator is used in
Equations 2.12 and 2.13 to be implemented in the Kirsch masks. Note that the Sobel
operator is two-directional orientations (horizontal and vertical) and the Kirsch masks
are an eight-neighbourhood orientation. The combination of Kirsch and Sobel operator
make the algorithm more efficient.
The combination of Kirsch and Sobel operator is an eight neighbourhood masks
with the coefficients of Sobel operator. Equation 2.14 is used to get the maximum
magnitude to determine the directional orientation. The masks of Kirsch and Sobel
operator are as below:
⎡- 2 - 1
G(0) = ⎢⎢ - 1 0
⎢⎣ 0 1
0⎤
⎡- 1
⎥
1⎥. G(1) = ⎢⎢- 2
⎢⎣- 1
2⎥⎦
⎡ 2 1 0⎤
⎡ 1
⎢
⎥
G(0) = ⎢ 1 0 - 1⎥. G(1) = ⎢⎢ 2
⎢⎣ 0 - 1 - 2⎥⎦
⎢⎣ 1
0
0
0
1⎤
2⎥⎥. G(2) =
1⎥⎦
⎡ 0 1
⎢- 1 0
⎢
⎢⎣- 2 - 1
2⎤
⎡ 1 2 1⎤
⎥
1⎥, G(3) = ⎢⎢ 0 0 0⎥⎥
⎢⎣- 1 - 2 - 1⎥⎦
0⎥⎦
0 - 1⎤
⎡ - 1 - 2 - 1⎤
⎡ 0 - 1 - 2⎤
⎥
⎥
⎢
0 - 2⎥. G(2) = ⎢ 1 0 - 1⎥, G(3) = ⎢⎢ 0 0 0⎥⎥
⎢⎣ 1 2 1⎥⎦
⎢⎣ 2 1 0⎥⎦
0 - 1⎥⎦
The Kernels G in the masks of Kirsch and Sobel operator is used to obtain the
derivatives by [i][j]-notation.
K[0] = f[i][j+1]+2*f[i+1][j+1]+f[i+1][j]
-f[i][j-1]-2*f[i-1][j-1]-f[i-1][j]
K[1] = f[i+1][j+1]+2*f[i+1][j]+f[i+1][j-1]
-f[i-1][j-1]-2*f[i-1][j]-f[i-1][j+1]
K[2] = f[i+1][j]+2*f[i+1][j-1]+f[i][j-1]
-f[i-1][j]-2*f[i-1][j+1]-f[i][j+1]
K[3] = f[i+1][j-1]+2*f[i][j-1]+f[i-1][j-1]
f[i-1][j+1]-2*f[i][j+1]-f[i+1][j+1]
55
K[4] = f[i][j-1]+2*f[i-1][j-1]+f[i-1][j]
-f[i][j+1]-2*f[i+1][j+1]-f[i+1][j]
K[5] = f[i-1][j-1]+2*f[i-1][j]+f[i-1][j+1]
-f[i+1][j+1]-2*f[i+1][j]-f[i+1][j-1]
K[6] = f[i-1][j]+2*f[i-1][j+1]+f[i][j+1]
-f[i+1][j]-2*f[i+1][j-1]-f[i][j-1]
K[7] = f[i-1][j+1]+2*f[i][j+1]+f[i+1][j+1]
-f[i+1][j-1]-2*f[i][j-1]-f[i-1][j-1]
For example, we compute the first 3x3 matrix from the generated10x10 pixels of image
(in Figure 4.2). It can be shown as below.
Figure 4.4
144
152
144
144
152
152
144
160
152
The first 3x3 matrix of the image in Figure 4.2.
The centre pixel of the first 3x3 matrix is 152. The derivatives of Kirsch and
Sobel are used to transform the centre pixel into a new value.
K[0]= f[i][j+ 1]+ 2 * f[i + 1][j+ 1]+ f[i + 1][j] f[i][j- 1]- 2 * f[i - 1][j- 1]- f[i - 1][j]
= 152 + 2(152) + 160 − 144 − 2(144) − 152
= 32
K[1] = f[i + 1][j + 1]+ 2 * f[i + 1][j]+ f[i + 1][j- 1] f[i - 1][j- 1]- 2 * f[i - 1][j]- f[i - 1][j + 1]
= 152 + 2(160) + 144 − 144 − 2(152) − 144
= 24
56
K[2] = f[i + 1][j]+ 2 * f[i + 1][j- 1]+ f[i][j- 1] f[i - 1][j]- 2 * f[i - 1][j + 1]- f[i][j + 1]
= 160 + 2(144) + 144 − 152 − 2(144) − 152
=0
K[3] = f[i + 1][j- 1]+ 2 * f[i][j- 1]+ f[i - 1][j- 1] f[i - 1][j + 1]- 2 * f[i][j + 1]- f[i + 1][j + 1]
= 144 + 2(144) + 144 − 144 − 2(152) − 152
= −24
K[4] = f[i][j- 1]+ 2 * f[i - 1][j- 1]+ f[i - 1][j] f[i][j + 1]- 2 * f[i + 1][j + 1]- f[i + 1][j]
= 144 + 2(144) + 152 − 152 − 2(152) − 160
= −32
K[5] = f[i - 1][j- 1]+ 2 * f[i - 1][j]+ f[i - 1][j + 1] f[i + 1][j + 1]- 2 * f[i + 1][j]- f[i + 1][j- 1]
= 144 + 2(152) + 144 − 152 − 2(160) − 144
= −24
K[6]= f[i - 1][j]+ 2 * f[i - 1][j + 1]+ f[i][j + 1] f[i + 1][j]- 2 * f[i + 1][j- 1]- f[i][j- 1]
= 152 + 2(144) + 152 − 160 − 2(144) − 144
=0
K[7]= f[i - 1][j + 1]+ 2 * f[i][j + 1] + f[i + 1][j + 1] f[i + 1][j - 1]- 2 * f[i][j- 1]- f[i - 1][j - 1]
= 144 + 2(152) + 152 − 144 − 2(144) − 144
= 24
From the calculation, we can determine the absolute of maximum magnitude
K [ i ] , i ∈ {0,1,...,7} to be max = 32. Therefore, the centre pixel of the first 3x3 matrix
is changed from 152 to 32. The calculation is repeated until all the centre pixels value
has been changed. From the calculation, the new values of the centre pixels are as
shown in Figure 4.5.
57
2
3
4
5
6
7
8
9
Figure 4.5
2
32
32
40
64
96
112
96
72
3
24
8
80
200
272
328
328
320
4
32
48
168
304
318
317
324
340
5
24
56
200
311
204
84
60
60
6
32
72
248
333
132
14
0
0
7
32
88
280
324
93
14
14
14
8
32
88
288
316
78
0
0
0
9
32
72
288
316
85
14
14
14
The new value of the image in 8x8 matrix after filtering the image
in Figure 4.2.
Step 5: Compare the filtering image f[i][j] with the threshold value T
The last step is to compare the new value with the threshold value, T = 178. The
process produces two regions with value 1 and 0. After all the pixel values in Figure 4.5
are compared, the new form as shown in Figure 4.6 is produced.
2
3
4
5
6
7
8
9
Figure 4.6
2
0
0
0
0
0
0
0
0
3
0
0
0
1
1
1
1
1
4
0
0
0
1
1
1
1
1
5
0
0
1
1
1
0
0
0
6
0
0
1
1
0
0
0
0
7
0
0
1
1
0
0
0
0
8
0
0
1
1
0
0
0
0
9
0
0
1
1
0
0
0
0
The binary edge image of Figure 4.5.
58
4.3
Local Minima Image
In this stage, we want to get the minima pixels to smooth the edge. A thick edge
will make it difficult to acquire the real corners. Therefore, we apply the Zhang-Suen
Thinning Algorithm to the edge that will detect the minima pixels by suppressing all the
other non-minimum pixels. The resulting image is called a thinning image and those
extracted pixels are called minima pixels. By applying this step, the number of points
will be reduced significantly. The Zhang-Suen Thinning Algorithm is described as in
Figure 4.7.
Step 1:
Count the number of object pixels with value 1, N(P) for
the eight neighbourhoods as shown in Figure 2.7.
Step 2:
Check if 2 ≤ N(P) ≤ 8 then
2.1
Generate the pixel sequence P1, P2,..., P8, P1 .
2.2
Count the number of ‘zero to one’ patterns, N(T)
2.3
Check if N(T) = 1 then
2.3.1 Check if
(P1 • P3 • P5 = 0)
and
(P3 • P5 • P7 = 0)
then
the central pixel can been deleted.
2.3.2 Check if
(P7
• P1 • P3 = 0) and (P1 • P7 • P5 = 0) then
the central pixel can been deleted.
Step 3:
Stop the process when is no more pixel to be removed.
Figure 4.7
The Zhang-Suen Thinning Algorithm
After the thinning process, the probability lines in an edge image are calculated
to reduce some noise. The algorithm of Hough Line Detector is used to get the
probability of line edges. As an example, consider a 3x3 matrix from Figure 4.6 as
shown in Figure 4.8.
59
P7
Figure 4.8
P8
P1
P2
0
0
0
0
1
1
1
1
1
P6
P5
P4
P3
A 3x3 matrix is obtained from Figure 4.6.
The centre pixel in Figure 4.8 corresponds to the array f[4][5] in Figure 4.6. We
have the number of object pixels with value 1 denoted by N(P) to be 4 that P3, P4, P5 and
P6. Then, the pixel sequence P1, P2,…, P8, P1 is generated by using the template in
Figure 2.7. The sequence obtained is 001111000. The next step is to count the number
of ‘zero to one’ patterns, N(T). So we have N(T)=1. Using the condition (P1 • P3 • P5 = 0)
and (P3 • P5 • P7 = 0) , the pixel at array f[4][5] can be deleted, therefore the pixel in array
f[4][5] equal to 0. All processes are repeated for all pixels and the Hough Line Detector
is used to produce a line in minima pixels as illustrated in Figure 4.9.
2
3
4
5
6
7
8
9
Figure 4.9
2
0
0
0
0
0
0
0
0
3
0
0
0
0
0
0
0
0
4
0
0
0
1
1
1
1
1
5
0
0
0
1
0
0
0
0
6
0
0
0
1
0
0
0
0
7
0
0
0
1
0
0
0
0
8
0
0
0
1
0
0
0
0
9
0
0
0
1
0
0
0
0
The minima image after thinning process with Zhang-Suen Algorithm
and Hough Line Detector.
60
4.4
Locating Corners
The peaks of accumulator array mark the equations of significant lines. The
Hough Transform does not require prior grouping or linking of the edge points. The
edge points that lie along the curve of interest may constitute a small fraction of the
edges in the image. Moreover, if the peak in the parameter space covers more than one
accumulator, then the centre of the region that contains the peak provides an estimate of
the parameters.
The peaks of accumulator can be defined with the setting of threshold value.
From these peaks, we can detect the arbitrary line in the image. Table 4.1 shows the
example of accumulator that describes as in an array is produced by Figure 4.9. In
summary, the accumulator can be illustrated as in appendix A.
Table 4.1
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
0
0
0
0
0
5
1
1
1
1
1
0
0
0
0
0
15
0
0
0
0
0
2
4
1
1
1
1
0
0
0
0
30
0
0
0
0
0
0
2
3
2
2
1
0
0
0
0
The accumulator of the Hough Transform
45
0
0
0
0
0
0
1
2
4
2
1
0
0
0
0
60
0
0
0
0
0
0
1
3
3
2
1
0
0
0
0
75
0
0
0
0
0
0
3
4
1
1
1
0
0
0
0
90
0
0
0
0
0
6
1
1
1
1
0
0
0
0
0
105
0
0
0
4
2
1
1
1
1
0
0
0
0
0
0
120
2
2
2
1
1
1
1
0
0
0
0
0
0
0
0
135
1
2
1
1
1
0
0
0
0
0
0
0
0
0
0
150
2
2
0
0
0
0
0
0
0
0
0
0
0
0
0
165
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
180
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
61
From Figure 4.9, we can see obviously the two lines that are constructed by a
pixel 1. The algorithm of Hough Line Detector is applied to detect the two lines by
using the parameters r and t. Equation 2.27 uses the maximum value and the setting
value of α to determine the threshold value.
The maximum value in the accumulator is 6. Suppose we set α to 0.8. The
threshold value T that we have is 4.8. Since we use the int() function in programming,
the threshold value becomes T = 4. Every element in the accumulator (as shown in
Figure 4.5) is compared with the threshold value to detect lines. But, we obtain 6 line
candidates by using the thresholding in the accumulator. Table 4.2 shows the pair of r
and t that is held by parameters rho[i] and theta[i].
Table 4.2
i
rho[i]
theta[i]
1
4
0
2
6
15
The array of rho[i] and theta[i]
3
8
45
4
7
75
5
5
90
6
3
105
Since the detected lines are not same, we need to reset α with 0.9. So, we have
the threshold value T = 5. In this case we have rho[1] = 4, theta[1] = 0 and rho[2] = 5,
theta[1] = 90 that correspond to the two lines. From these values, the two lines can be
constructed by the connected pixel with value 1 as in Figure 4.9.
We can apply the values of rho[i] and theta[i] to detect a corner. By using the
algorithm of Hough Corner Detector, we need to reset the value of image array f[i][j]
with 0. Then, we use the values of rho[i] and theta[i] to compute the slopes where m1 = 0
and m2 = ∞. The slopes show the lines are not parallel where m2 ≠ m1 .
62
Therefore, we use Equation 3.12 to detect a corner and have R1 = 4 and R2 = 5.
We also have sin(0) = 0, sin(90) = 1, cos(0) = 1 and cos(90) = 0 . Then, the corner pixel
⎡ x ⎤ ⎡ 4⎤
can be obtained by ⎢ ⎥ = ⎢ ⎥ and then the image array f[5][4] equal to 1. The corner
⎣ y ⎦ ⎣5 ⎦
pixel can be illustrated as figure below.
2
3
4
5
6
7
8
9
Figure 4.10
2
0
0
0
0
0
0
0
0
3
0
0
0
0
0
0
0
0
4
0
0
0
1
0
0
0
0
5
0
0
0
0
0
0
0
0
6
0
0
0
0
0
0
0
0
7
0
0
0
0
0
0
0
0
8
0
0
0
0
0
0
0
0
9
0
0
0
0
0
0
0
0
The corner candidate using the Hough Corner Detector.
CHAPTER V
SIMULATION MODEL
5.1
Introduction
A simulation model is developed to provide the results of several sample images,
which are conducted to study the performance of the Hough Transform. In this
implementation, images in bitmap format are used and the rate of the maximum
threshold value is selected as given by equation 2.27. Our simulation is based on the
case study described in Chapter IV.
This simulation uses the MFC programming with Microsoft Visual C++. The
MFC programming has a tool to create windows to illustrate the result image properly.
Some variables, arrays and functions are being constructed to represent each stage
parameter used in the corner detection process. This Interface simulation is created to
help analysing the number of corners that should be detected.
64
5.2
Model Description
The simulation will process a digital image into bitmap format. The image
consists of 640 x 480 pixels and uses the RGB colours. This simulation is an objectoriented approach that can construct the windows and other object easily. An objective
of this study is to design a simulation model to detect the corner. Therefore, some
functions and procedures must be studied to develop the simulation program. Some
member functions in the simulation are:
CMainFrame(); - it is a constructor. A class member function allocating memory
storage and initialising class variables.
~CMainFrame(); - it is a destructor that allocated from free store memory.
OnPaint(); - Activate the paint area.
OnLButtonDown(UINT, CPoint); - Activate the left mouse button
void ImageEdgeDraw(); - Illustrate the edge image in the paint area.
void ConvertFileBinary(CString); - Convert the magnitude into binary
form.
void GreyLevelImage(); - The function that convert the image into grey
colour.
void KSobelEdgeDetector(int); - Filter the image.
void ZhangSuenThinning(); - Smoothing the edge image.
void HoughAccumulator(); - Determine the significant lines that refers to the
parameters r and θ.
void HoughLineDetector(); - Function to detect the line.
void HoughCornerCandidate(); - Function to compute the corner candidate.
void HoughAccurateCorner(); - Function to detect the real corner.
65
5.3
Simulation Model
The order of the process in detecting corner is given by the stages in Figure 2.10.
In the first stage, the digital image is analysed and the intensity is extracted. The result
from this process is the edge image with black and white colour. The edge image holds
the binary value. The value 1 corresponds to black pixel while 0 corresponds to white.
Figure 5.1 is a sample of digital image and Figure 5.2 is the resulted of edge detector
using Sobel and Kirsch Operator.
Figure 5.1
The sample of digital image
66
Figure 5.2
The result from the edge detector (the Edge Image)
After filtering process is done by using Sobel and Kirsch edge detector, the
thresholding process will be carried out. Note that, the image is in RGB format that
contains 16,77,126 colours per-pixel. Equation 2.27 is used and the rate of thresholding
in Kirsch and Sobel operator is set as α1 = 0.5. By multiplying this rate with the
maximum magnitude value, the threshold value is obtained. By using the threshold
value, the image can be separated into two regions as shown in Figure 5.2 above.
The next step is to smooth the edges to detect the lines. The Hough Transform
can detect the line using the accumulator that is produced from the Thinning Method.
The Zhang- Suen Thinning Algorithm reduces the non-minima point that refers to the
edges until it is smoothed out. Then the accumulator is used to find the r and θ that
corresponds to the lines.
67
More lines can be generated using the r and θ that are obtained from the
accumulator. The thresholding is used to find the best lines that are similar to the object
represented. The rate of the largest value in the accumulator is set to α2 = 0.3. Figure 5.3
shows the thin lines image that is produced from the thinning process applied to the
image given in Figure 5.2.
Figure 5.3
The result of thinning process (the Minima Image)
The next process is to detect the corner candidates. The corner candidates are
produced from the linear equation 3.12. We have detected the lines that have their own
r and θ values. Using these values, the corner candidates that correspond to the
intersection point of the lines in Figure 5.3 will be calculated. We can see the result as
shown in Figure 5.4. The blue dots in the figure correspond to the corner candidates.
68
Figure 5.4
The corner candidates produced from the thinning image of Figure 5.3
To detect the accurate corner, the candidates must been verified. In this study,
the accurate corners are assumed to have the highest value of the intersecting lines. The
thresholding is then set to determine the accurate corners. In this study, the rate of the
largest number of the corner candidates is set as α3 = 0.4. Figure 5.5 shows the accurate
corners produced from the separation of corner candidates given in Figure 5.4. The red
dots are used to illustrate the accurate corners in the image.
69
Figure 5.5
The accurate corners are obtained from Figure 5.4
Not all accurate corners can be detected by using the Hough Transform. The
algorithm only detected 10 corner points out of 20 corner points in the sample of digital
image. We can make an assumption that the Hough Transform is an important process
in detecting lines. However, the detected number of lines depends on the performance
of edge detector. The selection of thresholding in the edge detection plays an important
role in producing the accurate corners.
In this study, we will describe the importance of thresholding to detect the
accurate corners from the image. The parameters are set manually to provide the
accurate corners. The parameters are the rate of maximum values that refer to α1, α2 and
α3. Through programming, the parameters are changed into a1, a2 and a3.
70
The effect of the threshold value to the number of detected corners is given in
Appendix B. The analysis shows the accuracy of selected rates in detecting the real
corners. The rates have not accurate still produce the corner candidates. We can see
that a1 = 0.9, a2 = 0.1 and a3 = 0.4 is the best rates of maximum value for this image.
The rates produce 14 corner points out of the 20 corner points. Most of the detected
corners are in the middle region of image. We know that the middle region is brighter
than the other regions. That makes the corners easily detected in that area.
5.4
Summary
The Hough Transform can detect the simple corner based on the lines detected.
We can see that the Hough Transform is sensitive to the thresholding used in the edge
detector. The three parameters (a1, a2 and a3) that refer to the rate of maximum value
are important to detect the significant corner.
Generally, high value of parameter a1 will make the edges smoother with less
noise. Otherwise, the image produced will have thick edges and more noise. While the
parameter a2 is the rate of threshold for selecting lines and parameter a3 is for selecting
corners. Both parameters depend on the selection of parameter a1. The detected corners
using different parameters values are shown in Appendix C.
CHAPTER VI
SUMMARY AND CONCLUSIONS
6.1
Observation
The main focus of this study is to use the method of Hough Transform to detect
corners in an image. The process of detecting corners involves four stages. The four
stages are the edge detection, thinning problem, line detection and corner detection.
In the first stage, the Kirsch and Sobel operator is used to detect edges. The real
values of the edges are in binary form. The binary values are then constructed into client
area with an MFC application by using the function in Microsoft Visual C++. The
selection of the rate of thresholding will effect the detection of edge image. The edges
are thick and have noise when the rate is low. Whereas, the edges are thin and less noisy
when the rate is high. This factor will affect the process of detecting the accurate
corners.
72
The Zhang-Suen thinning algorithm is used to thin the edges. The aim is to
speed up the method of Hough Transform in obtaining the corner. This algorithm will
verify the edges whether to remove pixel or not. The main condition is 2 ≤ N ( P ) ≤ 6
where N (P ) is the number of nonzero of the eight neighbours of P.
From this condition, only the upper and left parts of the edges are removed. The
pixel removal is not symmetrical. By changing the condition into 2 ≤ N(P) ≤ 8 , the
pixel removal (centre pixel) is symmetrical and the edges are thinned smoothly. It is
because the condition uses the entire pixels neighbourhood (eight-neighbourhood) to
verify whether to remove the centre pixel or not.
The third stage is to detect the lines. The Hough Line Detector has been used to
detect the probability of the existing lines in the second stage by using the accumulator.
This stage involves the computation of the parameters r and θ to show the probability of
lines and will be used to detect the existing corners.
The Hough Transform detects the lines using the high value in the accumulator
that represent the parameters of r and θ. The rate of thresholding is used to detect the
actual lines. The lower rate of thresholding makes the Hough Transform detect more
lines. The effect is the Hough Transform cannot detect the corner accurately.
The accumulator in Hough Line Detector is also used to detect the corners. The
parameters that refer to the lines are used to detect the corner candidates by using
Equation 3.12. We know the corner candidates are the intersection points in two or
more lines. The corner candidates that are obtained are not the same as in real
visualisation. Therefore, the last stage is used to detect real corners.
73
An assumption is made that the high intersection points define the corner. The
thresholding is used to detect real corners from the corner candidates. Overall, the real
corners not well defined using the Hough Transform. Almost the real corners easily
detect surroundings at the brightness region in an image.
6.2
Discussions
Corner detection is one of the most commonly used operations in image analysis
especially in providing information for object recognition. A corner is usually related
with the edges in an image. This means that if the edges in an image can be accurately
identified, the corners can be easily detected. The corner points can then be used to
describe basic properties such as area, perimeter and shape. Since computer vision
involves in the identification and classification of objects in an image, corner detection
is an essential tool.
Most good algorithms begin with a clear statement of the problem to be solved.
The aim of this study is to find the corner points in an image. The problem is then
separated into three minor problems. First problem is to extract the digital image into
the edge image. Then, find the accurate line by searching the minima points. Lastly, the
problem is to detect the corner points in the minima image.
This study consists of four main stages of implementation. The first stage is the
problem to identify the edge points. Some edge detector such as Roberts, Prewitt, Sobel
and Kirsch Operators had been used to study the characteristic that corresponds to the
performance. In the simulation model, we can see that the brightness factor plays an
74
important role in detecting the accurate edges. The fundamental of thresholding is also
the essential characteristic to determine the separation region between edges and the
background.
The threshold can be chosen by inspecting the edge magnitude histogram. Only a
small percentage of the pixel f ( x , y ) is obtained. Thresholding 2.21 is global and can be
applied to the entire image. In general, the edge magnitude output has regions
possessing different statistical properties. Therefore, the global thresholding may
produce thick edges in one region and thin or broken edges in another region.
The second stage problem is to acquire the minima points from the edge image.
The problem is solved by using the thinning approach. The Zhang-Suen thinning
algorithm is chosen to get the minima point of the edge image. By observation, the
Zhang- Suen Algorithm did not produce good results in reducing the noise in the edge
image. Other factors that contribute to this result is the brightness of digital image or the
selected edge detector. For future work, the observation of the edge detector must be
interpreted to produce some good results.
The Last stage problem is to define the approach that can detect the corner well.
This study involves the application of Hough Transform in image processing. The
Hough Transform is well known as the line detection algorithm in the imaging area.
The algorithm produces the accumulator to detect lines using the parameters of r and θ.
Whereas, the main objective is to study the Hough Transform in application of
corner detection. The parameters in the accumulator are used to detect the corners using
Equation 3.12 as well as can. Nevertheless, the Hough Transform is suitable for image
that has lines to detect easily the intersection points known as corners.
75
6.3
Suggestions
The following are some of the suggestions on improving the results of this
dissertation and possibly on future research of this area:
Use other edge detector that can reduce the noise such as Canny Edge
Detector or Laplacian of Gaussian. The approach must be understood
very well to produce good result.
Further research on the thresholding that corresponds to the performance
of separating the edge image.
Use other method such as Wavelet Transform, Genetic Algorithm or
Mathematical Morphology Approach to improve the detection of the
candidate corners.
Determine other stages to acquire the corner and study the performance.
76
REFFERENCES
Anton, H, Bivens, I. And Davis, Stephen (2005). Calculus 8th Edition. Singapore: John
Willey & Sons (Asia) Pte. Ltd.
Awcock, G. W. And Thomas R. (1996). Applied Image Processing. New York:
McGraw-Hill Inc.
Castleman, K. R. (1996). Digital Image Processing. New Jersey: Prentice Hall.
Chanda, B. And Majumder D. D. (2000). Digital Image Processing and Analysis. New
Delhi: Prentice Hall of India.
Chen, C.H, Lee J. S. and Sun Y. N. (1995). Wavelet Transformation for Gray Level
corner detection. Tainan University: Elsevier Science B.V.
Davies, E.R. (1988). Application of the generalised Hough Transfrom to corner
detection. IEE Proceedings, vol 135.
Engkamat, A (2005). Enhancement of Parallel Thinning algorithm for Handwritten
Characters using Neural Network. Universiti Teknologi Malaysia: Master
Thesis.
Freeman, H. (1961). On the encoding of arbitrary geometric configurations. IRE Trans.
Electron Comp. EC-10, June 1961, 260-268.
77
Gonzalez, R. C. and Woods, R. E. (2004). Digital Image Processing using Matlab. New
Jersey: Prentice Hall.
Haron, H., Shamsuddin, S. M. and Mohamed, D. (2005). A New Corner Detect
algorithm for Chain Code representation. Loughborough University: Taylor &
Francis Group.
Jones, R. M. (2000). Intoduction to MFC programming with Visual C++. New Jersey:
Prentice Hall PTR.
Lee J. S., Sun, Y. N. and Chen, C. H. (1995). Multiscale Corner Detection by using
Wavelet Transform. IEEE Transactions on Image Processing: no.1 vol.4.
Manohar V. (2004). Digital Image Processing-Basic Thresholding and Smoothig.
University of South Florida at http:Marathon.csee.usf.edu/~yqiu2/ Basic_
Thresholding_and_Smoothing.doc.
Matteson, R. G. (1995). Introduction to Document Image Processing Techniques.
Boston, London: Artech House Publishers.
Pappas, C. H. and Murray III W. H. (1998). Visual C++ 6: The Complete Reference.
Osborne: Mc Graw Hill.
Parker, J. R. (1997). Algorithms for Image Processing and Computer Vision. Canada:
Wiley Computer Publishing.
Pitas, I. (1993). Digital Image Processing Algorithms. UK: Prentice Hall International
Ltd.
Raji, A. W. M. et al. (2002). Matematik Asas. Universiti Teknologi Malaysia: Skudai.
78
Ritter, G. X. and Wilson, J. N. (2001). Handbook of ComputerVision Algorithms in
Image Algebra. Boca Raton: CRC Press.
Salleh, S. et al. (2005). Numerical Simulations and Case Studies using C++ .Net.
USA: Tab Books.
Seul, M. et al. (2000). Practical Algorithms for Image Analysis Description, Examples
and Code. UK: Cambridge University Press.
Shen, F. and Wang, H. (2002). Corner detection based on modified Hough Transfrom.
Nanyang Technological University: Elsavier Science B.V.
The Hough Transform at http://en.wikipedia.org/wiki/Hough_ transform.
The Hough Transform at http://planetmath.org/encyclopedis/HoughTransform.html.
Yaakop, M. H. (2004). Sistem Bantuan Pengesanan Simpang bagi garisan tidak sekata
dengan menggunakan Teknik Wavelet Transform. Universiti Teknologi
Malaysia: Bachelor Thesis.
Zhang, T. Y. and Suen, C. Y. (1984). A Fast Parallel Algorithm for Thinning Digital
Patterns. Comm. ACM. 27(3): 236-239.
APPENDIX A
The sinusoidal graph in Hough space
The sinusoidal function in Hough space from the accumulator in Figure 4.9
(5,5)
(6,5)
(7,5)
(8,5)
(9,5)
(4,6)
(4,5)
(4,7)
(4,8)
(4,9)
Hough space
15
rho -axis
10
5
0
0
30
60
90
-5
-10
theta -axis
120
150
180
APPENDIX B
The Analysis of the Rate of the Maximum Thresholding
a1
a2
a3
Accuracy
Number
Points
1.0
0.1
0.5
Yes
10
212
318
426
243
57
532
352
164
460
274
48
124
202
231
261
281
311
341
389
423
1.0
0.1
0.4
Yes
10
212
318
426
242
57
532
351
164
459
274
48
124
202
230
260
280
310
342
391
423
1.0
0.1
0.3
No
12
212
318
135
425
242
57
375
532
351
164
459
274
48
124
153
201
230
260
278
279
310
342
391
423
0.9
0.1
0.5
Yes
11
212
318
136
426
242
57
532
353
164
461
274
48
123
151
202
230
259
281
310
342
388
423
0.9
0.1
0.4
Yes
14
212
493
318
136
596
425
242
57
532
352
164
461
274
562
48
99
123
151
175
202
230
260
281
310
342
389
423
471
0.9
0.1
0.3
No
16
212
494
318
136
597
425
242
56
375
532
352
164
632
460
273
562
47
99
123
151
175
201
230
260
278
280
310
342
358
389
422
470
0.8
0.2
0.5
Yes
7
212
318
136
425
532
352
274
49
123
152
202
280
310
423
0.8
0.2
0.4
Yes
10
213
318
136
426
242
56
532
351
461
274
48
123
152
201
230
261
279
311
390
423
0.8
0.2
0.3
No
11
214
318
135
426
242
56
374
532
351
461
274
46
123
153
201
230
261
277
279
311
390
424
a1
a2
a3
Accuracy
Number
Points
0.7
0.3
0.6
Yes
5
318
426
242
352
460
123
202
230
311
388
0.7
0.3
0.5
Yes
5
318
426
242
352
460
123
202
230
311
388
0.7
0.3
0.4
No
12
214
318
137
297
426
264
242
468
531
353
165
460
46
123
154
153
202
200
230
233
279
311
342
389
0.6
0.3
0.5
Yes
6
318
426
242
532
352
460
123
203
231
280
311
389
0.6
0.3
0.4
Yes
7
318
136
426
242
532
352
460
123
153
202
231
279
311
389
0.6
0.3
0.3
No
14
214
318
137
297
158
426
264
205
242
468
531
352
165
459
46
123
153
153
170
202
200
203
231
233
279
312
342
391
0.5
0.3
0.5
Yes
9
389
213
317
136
426
242
531
353
460
21
50
124
153
204
230
280
311
389
0.5
0.3
0.4
Yes
10
389
213
317
136
426
242
531
353
460
276
21
50
124
153
203
230
281
310
389
426
0.5
0.3
0.3
No
21
389
214
495
318
136
297
598
264
426
242
407
467
56
514
375
531
560
353
165
460
276
21
48
100
124
154
153
178
200
203
230
230
233
259
268
278
280
302
311
342
389
426
APPENDIX C
The Result of Corner Image using different Thresholding
85
86
87
88
89
90
91
92
93
APPENDIX F
The Related Source Code
95
Code 1
File header: Project.h
#include <afxwin.h>
#include <fstream.h>
#include <math.h>
#include "resource.h"
#define Timer 1
#define RAD 0.0174532925
#define a1 0.5 //the thresholding rate in Kirsch-Sobel Edge Detector
#define a2 0.3 //the thresholding rate in Houg Line Detector
#define a3 0.4 //the thresholding rate in Hough Corner Detector
typedef struct
{
int i;
int *px,*py;
double *rho,*theta;
}SCorner;
class CMainFrame : public CFrameWnd
{
private:
int i,j,r,t,m,n,rA,click;
int **f,**h,**A;
int xHome,yHome,xSize,ySize;
SCorner cDet;
public:
CMainFrame();
~CMainFrame();
CBitmap mBitmap;
afx_msg void OnPaint();
afx_msg void OnKeyDown (UINT MyKey,UINT nRep,UINT nFlags);
void MainStageProcess();
void ResultListReport();
void LabelProcess(int,int);
void TheRawImage();
void GreyLevelImage();
void ImageEdgeDraw();
void ConvertFileBinary(CString);
void KSobelEdgeDetector();
void ZhangSuenThinning();
void HoughAccumulator();
void HoughThresholding();
void HoughLineDetector();
void HoughCornerCandidate();
void HoughAccurateCorner();
DECLARE_MESSAGE_MAP()
};
class CMyWinApp : public CWinApp
{
public:
BOOL InitInstance();
};
96
Code 2
Main programming in Project.cpp
#include "Project.h"
CMyWinApp MyApplication;
BOOL CMyWinApp::InitInstance()
{
m_pMainWnd = new CMainFrame();
m_pMainWnd->ShowWindow(m_nCmdShow);
m_pMainWnd->UpdateWindow();
return TRUE;
}
BEGIN_MESSAGE_MAP(CMainFrame, CFrameWnd)
ON_WM_PAINT()
ON_WM_KEYDOWN()
END_MESSAGE_MAP()
CMainFrame::CMainFrame()
{
click=0;
xHome=10; yHome=30,
xSize=640, ySize=480;
rA=(int)(sqrt(xSize*xSize+ySize*ySize)/2.0);
m=2*rA+1; n=360;
cDet.px=new int [xSize*ySize];
cDet.py=new int [xSize*ySize];
cDet.rho=new double [m*n];
cDet.theta=new double [m*n];
A=new int *[m+1];
for (r=0;r<=m;r++)
A[r]=new int [n+2];
f=new int *[ySize+1];
h=new int *[ySize+1];
for (i=0;i<=ySize;i++)
{
f[i]=new int [xSize+1];
h[i]=new int [xSize+1];
}
for (r=0;r<m;r++)
for (t=0;t<=n;t++)
A[r][t]=0;
mBitmap.LoadBitmap(IDB_IMEJB);
Create(NULL, "Corner Detection by Hough Transform",
WS_OVERLAPPEDWINDOW,CRect(CPoint(170,100),CSize(670,600)));
}
97
CMainFrame::~CMainFrame()
{
delete cDet.px;
delete cDet.py;
delete cDet.rho;
delete cDet.theta;
for (r=0;r<=m;r++)
delete A[r];
delete A;
for (i=0;i<=ySize;i++)
{
delete f[i];
delete h[i];
}
delete f;
delete h;
}
void CMainFrame::OnPaint()
{
if (click==0)
MainStageProcess();
}
void CMainFrame::OnKeyDown(UINT MyKey,UINT nRep,UINT nFlags)
{
switch(MyKey)
{
case VK_SPACE: click++;
MainStageProcess();
break;
case VK_ESCAPE: DestroyWindow();
break;
}
}
void CMainFrame::MainStageProcess()
{
CClientDC dc(this);
CString Label;
switch (click)
{
case 0: dc.TextOut(xHome+220,yHome-25," The Digital Image
");
TheRawImage();
“
dc.TextOut(xHome+220,yHome+500,"<< Press Space Bar >>");
break;
98
case 1: dc.TextOut(xHome+240,yHome+500,"
dc.TextOut(xHome+220,yHome-25," Grey-Level process
GreyLevelImage();
dc.TextOut(xHome+240,yHome+500,"
");
");
");
dc.TextOut(xHome+220,yHome-25,"
Stage [1] :
The Edge Image
");
KSobelEdgeDetector();
ImageEdgeDraw();
ConvertFileBinary("P1_EdgeImage.out");
dc.TextOut(xHome+220,yHome-25," Accumulator Process ");
ZhangSuenThinning();
HoughAccumulator();
dc.TextOut(xHome+220,yHome-25,"
Stage [2] :
The Thinning Image
");
HoughThresholding();
HoughLineDetector();
ImageEdgeDraw();
ConvertFileBinary("P2_ThinImage.out");
break;
case 2: dc.TextOut(xHome+220,yHome-25,"
Stage [3] :
The Corner Candidate
");
HoughCornerCandidate();
break;
case 3: dc.TextOut(xHome+220,yHome-25,"
Stage [4] :
The Corner Image
");
HoughLineDetector();
ImageEdgeDraw();
HoughAccurateCorner();
ResultListReport();
ConvertFileBinary("P3_CornerImage.out");
break;
default: DestroyWindow();
break;
}
}
void CMainFrame::ResultListReport()
{
CClientDC dc(this);
CString Label;
CRect Titik;
Label.Format("Threshold 1 : %.2f",a1);
dc.TextOut(xHome,yHome+485,Label);
Label.Format("Threshold 2 : %.2f",a2);
dc.TextOut(xHome,yHome+500,Label);
Label.Format("Threshold 3 : %.2f",a3);
dc.TextOut(xHome,yHome+515,Label);
dc.TextOut(xHome+490,yHome+485,"The candidate corner
dc.TextOut(xHome+490,yHome+505,"The real corner
Titik=CRect(CPoint(xHome+470,yHome+485),CSize(15,15));
dc.FillSolidRect(&Titik,RGB(0,0,255));
Titik=CRect(CPoint(xHome+470,yHome+505),CSize(15,15));
dc.FillSolidRect(&Titik,RGB(255,0,0));
}
");
");
99
void CMainFrame::LabelProcess(int x,int xs)
{
CClientDC dc(this);
CString Label;
int percentage;
::Sleep(Timer);
percentage=100*x/xs;
Label.Format("
dc.TextOut(xHome+530,yHome+485,Label);
Label.Format("Processing [%d]",percentage);
dc.TextOut(xHome+530,yHome+485,Label);
");
}
void CMainFrame::TheRawImage()
{
CPaintDC dc(this);
CDC memDC;
memDC.CreateCompatibleDC(&dc);
memDC.SelectObject(&mBitmap);
dc.BitBlt(xHome,yHome,xSize,ySize,&memDC,0,0,SRCCOPY);
}
void CMainFrame::GreyLevelImage()
{
CClientDC dc(this);
int r,g,b,gs;
for (i=0;i<=ySize;i++)
{
LabelProcess(i+1,ySize+1);
for (j=0;j<=xSize;j++)
{
gs=dc.GetPixel(xHome+j,yHome+i);
r= gs >> 16;
// red
g= r << 8;
// green
b= g << 8;
// blue
gs=r+g+b;
// grayscale
f[i][j]=gs;
dc.SetPixel(xHome+j,yHome+i,f[i][j]);
}
}
}
100
void CMainFrame::ImageEdgeDraw()
{
CClientDC dc(this);
int Draw;
for (i=1;i<ySize-1;i++)
{
LabelProcess(i,ySize-2);
for (j=1;j<xSize-1;j++)
{
if(h[i][j]==1)
Draw=RGB(0,0,0);
else
Draw=RGB(255,255,255);
dc.SetPixel(xHome+j,yHome+i,Draw);
}
}
}
void CMainFrame::ConvertFileBinary(CString NameFile)
{
ofstream ofp(NameFile);
for (i=1;i<ySize;i++)
{
for (j=1;j<xSize;j++)
ofp << h[i][j];
ofp << endl;
}
ofp.close();
}
101
Code 3
Source Code of the Sobel and Kirsch Edge Detector
void CMainFrame::KSobelEdgeDetector()
{
int T,K[8];
//Compute the threshold value on Kirsch and Sobel Edge Detector
T=f[0][0];
for (i=0;i<=ySize;i++)
for (j=0;j<=xSize;j++)
if(T<f[i][j]) T=f[i][j]; //max
T= (int)(a1*T);
// Kircsh and Sobel masking for detecting the edges
for (i=1;i<ySize;i++)
for (j=1;j<xSize;j++)
{
K[0]=f[i][j+1]+2*f[i+1][j+1]+f[i+1][j]
-f[i][j-1]-2*f[i-1][j-1]-f[i-1][j];
K[1]=f[i+1][j+1]+2*f[i+1][j]+f[i+1][j-1]
-f[i-1][j-1]-2*f[i-1][j]-f[i-1][j+1];
K[2]=f[i+1][j]+2*f[i+1][j-1]+f[i][j-1]
-f[i-1][j]-2*f[i-1][j+1]-f[i][j+1];
K[3]=f[i+1][j-1]+2*f[i][j-1]+f[i-1][j-1]
-f[i-1][j+1]-2*f[i][j+1]-f[i+1][j+1];
K[4]=f[i][j-1]+2*f[i-1][j-1]+f[i-1][j]
-f[i][j+1]-2*f[i+1][j+1]-f[i+1][j];
K[5]=f[i-1][j-1]+2*f[i-1][j]+f[i-1][j+1]
-f[i+1][j+1]-2*f[i+1][j]-f[i+1][j-1];
K[6]=f[i-1][j]+2*f[i-1][j+1]+f[i][j+1]
-f[i+1][j]-2*f[i+1][j-1]-f[i][j-1];
K[7]=f[i-1][j+1]+2*f[i][j+1]+f[i+1][j+1]
-f[i+1][j-1]-2*f[i][j-1]-f[i-1][j-1];
//find maximum of K[8]
h[i][j]=K[0];
for(int c=1;c<=7;c++)
if (h[i][j]<K[c]) h[i][j]=K[c];
if(h[i][j]>=abs(T)) h[i][j]=1;
else
h[i][j]=0;
}
}
102
Code 4
Source Code of the Zhang-Suen Thinning Method
void CMainFrame::ZhangSuenThinning()
{
int count,trans,P[9];
int check;
//Zhang-Suen Thinning process
do
{
check=1;
for (i=1;i<ySize;i++)
for (j=1;j<xSize;j++)
if(h[i][j]==1)
{
count=0;
for (r=-1;r<=1;r++)
for (t=-1;t<=1;t++)
count += h[i+r][j+t];
if((count>=2)&&(count<=8))
{
P[0]=h[i-1][j];
P[1]=h[i-1][j+1];
P[2]=h[i][j+1];
P[3]=h[i+1][j+1];
P[4]=h[i+1][j];
P[5]=h[i+1][j-1];
P[6]=h[i][j-1];
P[7]=h[i-1][j-1];
P[8]=h[i-1][j];
trans=0;
for (int t=0;t<=7;t++)
if((P[t]==0)&&(P[t+1]==1))trans++;
if(trans==1)
{
if((P[0]*P[2]*P[4]==0)&&(P[2]*P[4]*P[6]==0))
{
h[i][j]=0;
check=0;
}
else if((P[6]*P[2]*P[0]==0)&&(P[0]*P[6]*P[4]==0))
{
h[i][j]=0;
check=0;
}
}
}
}
}while(check==1);
}
103
Code 5
Source Code of the Hough Transform
//Computer the Accumulator of Hough Transform
void CMainFrame::HoughAccumulator()
{
double rho,theta;
int cx=xSize/2,cy=ySize/2;
for (i=1;i<ySize;i++)
{
LabelProcess(i,ySize-1);
for (j=1;j<xSize;j++)
if(h[i][j]==1)
{
for (t=0;t<=n;t++)
{
theta=t*RAD; // average 0 < theta < 180
rho=(j-cx)*cos(theta)+(i-cy)*sin(theta);
rho+=0.5;
r=(int)rho;
A[rA+r][t]+=1;
}
}
}
}
//Determine the Threshold value on Hough Table
void CMainFrame::HoughThresholding()
{
int T=0;
for (r=0;r<m;r++)
for (t=0;t<=n;t++)
if((A[r][t]>0)&&(T<A[r][t]))
T=A[r][t]; //max
T=(int)(a2*T);
//Determine theta and rho using Acumulator
cDet.i=0;
for (r=0;r<m;r++)
for (t=0;t<=n;t++)
if(A[r][t]>=T)
{
cDet.i+=1;
cDet.rho[cDet.i]=r-rA;
cDet.theta[cDet.i]=t*RAD;
}
}
104
//Determine the line in the Image
void CMainFrame::HoughLineDetector()
{
double y;
int **g;;
int cx=xSize/2,cy=ySize/2;
g=new int *[ySize+1];
for (i=0;i<=ySize;i++)
g[i]=new int [xSize+1];
for (i=1;i<ySize;i++)
for (j=1;j<xSize;j++) g[i][j]=0;
for (r=1;r<=cDet.i;r++)
for (j=1;j<xSize;j++)
{
if(sin(cDet.theta[r])==0.0)
{
y+=1;
}
else
{
y=cDet.rho[r]-(j-cx)*cos(cDet.theta[r]);
y=0.5+(y/sin(cDet.theta[r]));
}
i=cy+(int)y;
if((i>0)&&(i<ySize))
//draw line by binary input
if (h[i][j]==1) g[i][j]=1;
}
for (i=1;i<ySize;i++)
for (j=1;j<xSize;j++) h[i][j]=g[i][j];
for (i=0;i<=ySize;i++)
delete g[i];
delete g;
}
105
//Compute the Candidate Corner
void CMainFrame::HoughCornerCandidate()
{
CClientDC dc(this);
int px,py,cx=xSize/2,cy=ySize/2;
double x,y,R1,R2;
for (i=1;i<ySize;i++)
for (j=1;j<xSize;j++) f[i][j]=0;
for (i=1;i<=cDet.i;i++)
for (j=2;j<=cDet.i;j++)
{
if (i>=j)
{
R2=tan(cDet.theta[j]);
R1=tan(cDet.theta[i]);
// the lines are not parallel but perpendicular
if(R1!=R2)
{
R1=cDet.rho[i]/sin(cDet.theta[j]-cDet.theta[i]);
R2=cDet.rho[j]/sin(cDet.theta[j]-cDet.theta[i]);
x=(R1*sin(cDet.theta[j])-R2*sin(cDet.theta[i]));
y=(R2*cos(cDet.theta[i])-R1*cos(cDet.theta[j]));
px=(int)(0.5+x+cx);
py=(int)(0.5+y+cy);
if (((px>7)&&(px<xSize-7))&&((py>7)&&(py<ySize-7)))
f[py][px]+=1;
}
}
}
//keep the candidate corner to the data structure
for (i=1;i<ySize;i++)
for (j=1;j<xSize;j++)
if(f[i][j]>=1)
{
CRect Titik(CPoint(j+xHome-5,i+yHome-5),
CPoint(j+xHome+5,i+yHome+5));
dc.FillSolidRect(&Titik,RGB(0,0,255));
}
}
106
//Compute the Accurate Corner
void CMainFrame::HoughAccurateCorner()
{
CClientDC dc(this);
CString Label;
int T=0;
//Eliminating the noise candidate corner
for (i=1;i<ySize;i++)
for (j=1;j<xSize;j++)
if((f[i][j]>0)&&(T<f[i][j]))
T=f[i][j]; //max
T=(int)(a3*T);
for (i=1;i<ySize;i++)
for (j=1;j<xSize;j++)
{
h[i][j]=0;
if(f[i][j]>=T) f[i][j]=1;
else
f[i][j]=0;
}
//Determine the real corner using the differentiate of
r=sqrt(x*x+y*y)
cDet.i=0;
for (i=1;i<ySize;i++)
for (j=1;j<xSize;j++)
if(f[i][j]==1)
{
cDet.i+=1;
cDet.px[cDet.i]=j;
cDet.py[cDet.i]=i;
cDet.rho[cDet.i]=sqrt((double)(j*j+i*i));
}
//Locating corner on paint
Label.Format("CP_%2.1f_%2.1f_%2.1f.txt",a1,a2,a3);
ofstream ofp(Label);
ofp << a1 << endl;
ofp << a2 << endl;
ofp << a3 << endl;
ofp << cDet.i << endl << endl;
if(cDet.i>=1)
{
for (i=1;i<=cDet.i;i++)
{
h[cDet.py[i]][cDet.px[i]]=1;
CRect Titik(CPoint(cDet.px[i]+xHome-9,cDet.py[i]+yHome-9),
CPoint(cDet.px[i]+xHome+9,cDet.py[i]+yHome+9));
dc.FillSolidRect(&Titik,RGB(255,0,0));
ofp << cDet.px[i] << " " << cDet.py[i] << endl;
}
}
ofp.close();
}