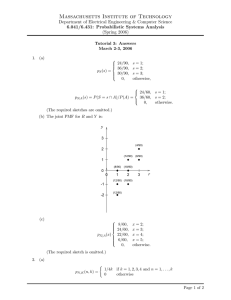
Graphical Models for Collaborative Filtering Le Song
advertisement

Graphical Models for
Collaborative Filtering
Le Song
Machine Learning II: Advanced Topics
CSE 8803ML, Spring 2012
Sequence modeling
HMM, Kalman Filter, etc.:
Similarity: the same graphical model topology, learning and
inference follow the same principle
Difference: the actual transition and observation model chosen
Learning parameter: EM
Compute posterior of hidden states: message passing
Decoding: message passing with max-product
𝑌1
𝑌2
𝑌𝑡
𝑌𝑡+1
𝑋1
𝑋2
𝑋𝑡
𝑋𝑡+1
2
MRF vs. CRF
MRF models joint of 𝑋 and 𝑌
𝑃 𝑋, 𝑌 =
1
∏Ψ(𝑋𝑐 , 𝑌𝑐 )
𝑍
𝑍 does not depend on 𝑋 or 𝑌
CRF models conditional of 𝑋
given 𝑌
𝑃 𝑋𝑌 =
1
∏Ψ
𝑍(𝑌)
𝑋𝑐 , 𝑌𝑐
𝑍(𝑌) is a function of 𝑌
Some complicated relation in 𝑌
may be hard to model
Avoid modeling complicated
relation in 𝑌
Learning: each gradient needs
one inference
Learning: in each gradient,
one inference per training
point
3
Parameter Learning for Conditional Random Fields
𝑃 𝑋1 , … , 𝑋𝑘 |𝑌, 𝜃 =
1
𝑍 𝑌,𝜃
exp
𝑖𝑗 𝜃𝑖𝑗 𝑋𝑖 𝑋𝑗 𝑌
+
𝑖 𝜃𝑖 𝑋𝑖
𝑌
1
= 𝑍 𝑌,𝜃 ∏𝑖𝑗 exp(𝜃𝑖𝑗 𝑋𝑖 𝑋𝑗 𝑌) ∏𝑖 exp(𝜃𝑖 𝑋𝑖 𝑌)
𝑍 𝑌, 𝜃 =
𝑥 ∏𝑖𝑗 exp(𝜃𝑖𝑗 𝑋𝑖 𝑋𝑗 𝑌) ∏𝑖 exp(𝜃𝑖 𝑋𝑖 𝑌)
𝑋1
𝑋2
𝑋3
𝑌
Maximize log conditional likelihood
𝑐𝑙 𝜃, 𝐷 =
1
𝑁
log(∏𝑙=1
𝑙
𝑍 𝑦 ,𝜃
=
=
𝑁
𝑙 (
𝑁
𝑙 (
∏𝑖𝑗 exp(𝜃𝑖𝑗 𝑥𝑖 𝑙𝑥𝑗𝑙 𝑦 𝑙 ) ∏𝑖 exp(𝜃𝑖 𝑥𝑖𝑙 𝑦 𝑙 ))
𝑖𝑗 log(exp(𝜃𝑖𝑗 𝑥𝑖
𝑙𝑥 𝑙 𝑦 𝑙 +
𝜃
𝑥
𝑖𝑗
𝑖
𝑖𝑗
𝑗
𝑐𝑎𝑛 𝑏𝑒 𝑜𝑡ℎ𝑒𝑟 𝑓𝑒𝑎𝑡𝑢𝑟𝑒
𝑓𝑢𝑛𝑐𝑡𝑖𝑜𝑛 𝑓 𝑥𝑖
𝑙 𝑙 𝑙
𝑥𝑗 𝑦 )) + 𝑖 log(exp(𝜃𝑖 𝑥𝑖𝑙 𝑦 𝑙 )) −
𝑙 𝑙
𝑙, 𝜃 )
𝜃
𝑥
𝑦
−
log
𝑍
𝑦
𝑖
𝑖
𝑖
log 𝑍 𝑦 𝑙 , 𝜃 )
𝑇𝑒𝑟𝑚 𝑙𝑜𝑔𝑍 𝑦 𝑙 , 𝜃 𝑑𝑜𝑒𝑠 𝑛𝑜𝑡
𝑑𝑒𝑐𝑜𝑚𝑝𝑜𝑠𝑒!
4
Derivatives of log likelihood
𝑐𝑙 𝜃, 𝐷 =
𝜕𝑐𝑙 𝜃,𝐷
𝜕𝜃𝑖𝑗
=
1
𝑁
=
1
𝑁
=
1
𝑁
𝑁
𝑙
1
𝑁
𝑙𝑥 𝑙 𝑦 𝑙 +
𝜃
𝑥
𝑖𝑗
𝑖
𝑖𝑗
𝑗
𝑁 𝑙 𝑙 𝑙
𝑙 𝑥𝑖 𝑥𝑗 𝑦
𝑁 𝑙 𝑙 𝑙
𝑙 𝑥𝑖 𝑥𝑗 𝑦
𝑁 𝑙 𝑙 𝑙
𝑙 𝑥𝑖 𝑥𝑗 𝑦
(
−
−
−
𝜕 log 𝑍 𝑦 𝑙 ,𝜃
𝜕𝜃𝑖𝑗
𝑙 𝑙
𝑙, 𝜃 )
𝜃
𝑥
𝑦
−
log
𝑍
𝑦
𝑖
𝑖
𝑖
𝐴 𝑐𝑜𝑛𝑣𝑒𝑥 𝑝𝑟𝑜𝑏𝑙𝑒𝑚
Can find global optimum
𝜕 𝑍 𝑦 𝑙 ,𝜃
1
Z(𝑦 𝑙 ,𝜃)
𝜕𝜃𝑖𝑗
1
Z(𝑦 𝑙 ,𝜃)
𝑥 ∏𝑖𝑗 exp(𝜃𝑖𝑗 𝑋𝑖 𝑋𝑗
𝑦 𝑙 ) ∏𝑖 exp(𝜃𝑖 𝑋𝑖 𝑦 𝑙 ) 𝑋𝑖 𝑋𝑗 𝑦 𝑙
𝑛𝑒𝑒𝑑 𝑡𝑜 𝑑𝑜 𝑖𝑛𝑓𝑒𝑟𝑒𝑛𝑐𝑒 𝑓𝑜𝑟 𝑒𝑎𝑐ℎ 𝑦 𝑙 ‼!
5
Moment matching condition
𝜕𝑐𝑙 𝜃,𝐷
=
𝜕𝜃𝑖𝑗
1 𝑁 𝑙 𝑙 𝑙
𝑥 𝑥 𝑦
𝑁 𝑙 𝑖 𝑗
−
1
Z 𝑦 𝑙 ,𝜃
𝑐𝑜𝑣𝑎𝑟𝑖𝑎𝑛𝑐𝑒 𝑚𝑎𝑡𝑟𝑖𝑥
from model
𝑒𝑚𝑝𝑖𝑟𝑖𝑐𝑎𝑙
𝑐𝑜𝑣𝑎𝑟𝑖𝑎𝑛𝑐𝑒 𝑚𝑎𝑡𝑟𝑖𝑥
P 𝑋𝑖 , 𝑋𝑗 , 𝑌 =
P 𝑌 =
1
𝑁
𝑙 ∏ exp 𝜃 𝑋 𝑦 𝑙 𝑋 𝑋 𝑦 𝑙
∏
exp
𝜃
𝑋
𝑋
𝑦
𝑥 𝑖𝑗
𝑖𝑗 𝑖 𝑗
𝑖
𝑖 𝑖
𝑖 𝑗
1
𝑁
𝑙
𝑙
𝑁
𝑙=1 𝛿(𝑋𝑖 , 𝑥𝑖 ) 𝛿(𝑋𝑗 , 𝑥𝑗 )
𝛿(𝑌, 𝑦 𝑙 )
𝑁
𝑙
𝑙=1 𝛿(𝑌, 𝑦 )
Moment matching:
𝜕𝑐𝑙 𝜃,𝐷
𝜕𝜃𝑖𝑗
= 𝐸P
𝑋𝑖 ,𝑋𝑗 ,𝑌
𝑋𝑖 𝑋𝑗 𝑌 − 𝐸𝑃(𝑋|𝑌,𝜃)P
𝑌
[𝑋𝑖 𝑋𝑗 𝑌]
6
Optimize MLE for undirected models
max 𝑐𝑙 𝜃, 𝐷 is a convex optimization problem.
𝜃
Can be solve by many methods, such as gradient descent,
conjugate gradient.
Initialize model parameters 𝜃
Loop until convergence
Compute
𝜕𝑐𝑙 𝜃,𝐷
𝜕𝜃𝑖𝑗
= 𝐸P
Update 𝜃𝑖𝑗 ← 𝜃𝑖𝑗 − 𝜂
𝑋𝑖 ,𝑋𝑗 ,𝑌
𝑋𝑖 𝑋𝑗 𝑌 − 𝐸𝑃(𝑋|𝑌,𝜃)P
𝑌
[𝑋𝑖 𝑋𝑗 𝑌]
𝜕𝑐𝑙 𝜃,𝐷
𝜕𝜃𝑖𝑗
7
Collaborative Filtering
8
Collaborative Filtering
R: rating matrix; U: user
factor; V: movie factor
min
U ,V
s .t .
f ( U ,V ) R UV
T
2
F
U 0 ,V 0 , k m , n .
Low rank matrix
approximation approach
Probabilistic matrix
factorization
Bayesian probabilistic matrix
factorization
9
Parameter Estimation and Prediction
Bayesian treats the unknown parameters as a random variable:
𝑃(𝜃|𝐷) =
𝑃 𝐷 𝜃 𝑃(𝜃)
𝑃(𝐷)
=
𝑃 𝐷 𝜃 𝑃(𝜃)
∫ 𝑃 𝐷 𝜃 𝑃 𝜃 𝑑𝜃
Posterior mean estimation: 𝜃𝑏𝑎𝑦𝑒𝑠 = ∫ 𝜃 𝑃 𝜃 𝐷 𝑑𝜃
𝜃
𝑋𝑛𝑒𝑤
Maximum likelihood approach
𝜃𝑀𝐿 = 𝑎𝑟𝑔𝑚𝑎𝑥𝜃 𝑃 𝐷 𝜃 , 𝜃𝑀𝐴𝑃 = 𝑎𝑟𝑔𝑚𝑎𝑥𝜃 𝑃(𝜃|𝐷)
𝑋
𝑁
Bayesian prediction, take into account all possible value of 𝜃
𝑃 𝑥𝑛𝑒𝑤 𝐷 = ∫ 𝑃 𝑥𝑛𝑒𝑤 , 𝜃 𝐷 𝑑𝜃 = ∫ 𝑃 𝑥𝑛𝑒𝑤 𝜃 𝑃 𝜃 𝐷 𝑑𝜃
A frequentist prediction: use a “plug-in” estimator
𝑃 𝑥𝑛𝑒𝑤 𝐷 = 𝑃(𝑥𝑛𝑒𝑤 | 𝜃𝑀𝐿 ) 𝑜𝑟 𝑃 𝑥𝑛𝑒𝑤 𝐷 = 𝑃(𝑥𝑛𝑒𝑤 | 𝜃𝑀𝐴𝑃 )
10
Matrix Factorization Approach
Unconstrained problem with Frobenius norm can be solved
using SVD
𝑎𝑟𝑔𝑚𝑖𝑛𝑈,𝑉 𝑅 − 𝑈𝑉 ⊤
Global optimal
2
𝐹
𝑉⊤
𝑅
= 𝑈
When we have sparse entries, Frobenius norm is computed
only for the observed entries, can no longer use SVD
Eg. Use nonnegative matrix factorization
𝑎𝑟𝑔𝑚𝑖𝑛𝑈,𝑉 𝑅 − 𝑈𝑉 ⊤ 2𝐹 , 𝑈𝑉 ⊤ ≥ 0
Local optimal, over fitting problem
11
Probabilistic matrix factorization (PMF)
Model components
12
PMF: Parameter Estimation
Parameter estimation: MAP estimate
𝜃𝑀𝐴𝑃 = 𝑎𝑟𝑔𝑚𝑎𝑥𝜃 𝑃 𝜃 𝐷, 𝛼 = 𝑎𝑟𝑔𝑚𝑎𝑥𝜃 𝑃 𝜃, 𝐷 𝛼
= 𝑎𝑟𝑔𝑚𝑎𝑥𝜃 𝑃 𝐷 𝜃 𝑃(𝜃|𝛼)
In the paper:
13
PMF: Interpret prior as regularization
Maximize the posterior distribution with respect to parameter
U and V
Equivalent to minimize the sum-of-squares error function with
quadratic regularization term (Plug in Gaussians and take log)
14
PMF: optimization
Optimization: alternating between 𝑈 and 𝑉
Fix 𝑈, it is convex in 𝑉
Fix 𝑉, it is convex in 𝑈
Find a local minima
Need to choose the regularization parameter 𝜆𝑈 and 𝜆𝑉
15
Bayesian PMF: generative model
A more flexible prior over 𝑈 and
𝑉 factor
Hyperparameters
Θ𝑈 = {𝜇𝑈 , Λ 𝑈 }
Θ𝑉 = {𝜇𝑉 , Λ𝑉 }
16
Bayesian PMF: prior over prior
Add a prior over the hyperparameter
Hyperhyperparameter Θ0 = {𝜇0 , 𝜈0 , 𝑊0 }
𝑊 is the Wishart distribution with 𝑣0 degrees of freedom and
a 𝐷 × 𝐷 scale matrix 𝑊0
17
Bayesian PMF: predicting new ratings
Bayesian prediction, take into account all possible value of 𝜃
𝑃 𝑥𝑛𝑒𝑤 𝐷 = ∫ 𝑃 𝑥𝑛𝑒𝑤 , 𝜃 𝐷 𝑑𝜃 = ∫ 𝑃 𝑥𝑛𝑒𝑤 𝜃 𝑃 𝜃 𝐷 𝑑𝜃
In the paper, integrating out all parameters and
hyperparameters.
18
Bayesian PMF: sampling for inference
Use sampling technique to compute
Key idea: approximate expectation by sample average
𝐸𝑓 ≈
1
𝑁
𝑁
𝑖=1 𝑓
𝑥𝑖
∗
𝐸𝑈,𝑉,Θ𝑈 ,ΘV|𝑅 𝑝 𝑅𝑖𝑗
𝑈𝑖 , 𝑉𝑗
≈
1
𝑁
𝑘𝑝
∗
𝑅𝑖𝑗
𝑈𝑖𝑘 , 𝑉𝑗𝑘
19
Gibbs Sampling
Gibbs sampling
𝑋 = 𝑥0
For t = 1 to N
𝐹𝑜𝑟 𝑔𝑟𝑎𝑝ℎ𝑖𝑐𝑎𝑙 𝑚𝑜𝑑𝑒𝑙𝑠
Only need to condition on the
Variables in the Markov blanket
𝑥1𝑡 = 𝑃(𝑋1 |𝑥2𝑡−1 , … , 𝑥𝐾𝑡−1 )
𝑥2𝑡 = 𝑃(𝑋2 |𝑥1𝑡 , … , 𝑥𝐾𝑡−1 )
…
𝑡
𝑥𝐾𝑡 = 𝑃(𝑋2 |𝑥1𝑡 , … , 𝑥𝐾−1
)
𝑋3
𝑋2
𝑋1
Variants:
Randomly pick variable to sample
sample block by block
𝑋4
𝑋5
20
Bayesian PMF: Gibbs sampling
We have a directed graphical model
Moralize first
Markov blankets
𝑈𝑖 : 𝑅, 𝑉, Θ𝑈
𝑉𝑖 : 𝑅, 𝑈, Θ𝑉
Θ𝑈 : 𝑈, Θ0
Θ𝑉 : 𝑉, Θ0
21
Bayesian PMF: Gibbs sampling equation
Gibbs sampling equation for 𝑈𝑖
22
Bayesian PMF: overall algorithm
𝐶𝑎𝑛 𝑏𝑒 𝑠𝑎𝑚𝑝𝑙𝑒𝑑
𝑖𝑛 𝑝𝑎𝑟𝑎𝑙𝑙𝑒𝑙
23
Experiments: RMSE
24
Experiments: Runtime
25
Experiments: posterior distribution
26
Experiments: users with different history
27
Experiments: effect of training size
28
Issue: diagnose convergence
Gibbs sampling: take sample after burn-in period
Sampled Value
Iteration number
29