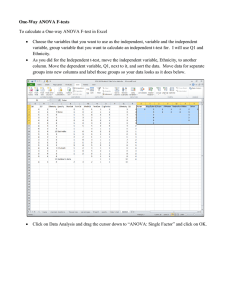
This time: Some ANOVA theory, two large examples.
advertisement

This time: Some ANOVA theory, two large examples. Last time, we started on ANOVA, or AnOVa, which is short for Analysis Of Variance. AnOVa is a set of statistical methods designed to answer one question “Where is the variance coming from?” A less formal way to ask this question is: “Why are the data values from my sample different? How can I explain these differences?” Sometimes the values are different because they come from groups that have different true means. Doing an ANOVA will tell us that the variation is due to the different group means in this case. ANOVA can tell us how much evidence there is against there being no group differences. (This is the null hypothesis ) Here, we would reject the null hypothesis because most of the variation can be explained by the differences between groups. Sometimes the group means are not very different compared to the differences between values within a group. Here, doing an ANOVA will tell us that the variation is from random scatter. In other words, the groups won’t explain very much of the variation in the response. The group means are close enough we would fail to reject the hypothesis that the true means were different. Small differences between the group means is a lot like a weak correlation in its use: The independent variable (nominal in ANOVA, and interval in correlation) doesn’t explain much of the variation in the dependent variable (interval in both cases) Large differences between group means are akin to a strong correlation. Knowing the group will tell you a lot about the values to expect, just as knowing the independent X value tells you a lot about the Y values to expect. If a correlation is significant, that means that our sample showed it to be far enough from zero to reject the hypothesis that the true correlation was zero. It also means that at least some of the variance in Y is explained by X. (Because r-squared isn’t zero) The same is true for the ANOVA F-Test. If it yields a small pvalue, that means the sample means are far enough to reject the hypothesis that the difference between true means is zero. It also means that some of the variance is explained by groups. In correlation, the closer values get to a straight line, the more 2 variance is explained (r gets closer to 1) In ANOVA, the closer values get to their group means, the more variance is explained (again, proportion explained gets closer to 1) Just as when X has nothing to do with Y in correlation/regression r 2 =0 , if the group has nothing to do with the measured values, none of the variance is explained. Enough theory. To examples. To ACTION! Consider the data from these three groups. The means of these three groups are definitely different. Knowing the group a value belonged to would give you a better estimate of it, but not nail it down perfectly. This is the ANOVA output from that same data. F is the F-stat mentioned last day. We’ll skip to the p-value. As always, Sig. is our p-value. The p-value against “All three means are the same” is less than .001, so we have very strong evidence that some of the group means are different from each other. “Proportion of variance explained” appears in the output tables from ANOVA. Variance explained = Between Groups / Total = 1411.6 / 1472 = 0.959 This is how ANOVA answers “Where is the variance coming from?” p-value answers: Is any of the variance due to the groups? Sum of Squares answers: How much is due to the groups? Let’s try one from scratch: From exercise 28, chapter 8. We have the data of 15 cases from a marriage counsellor. Specifically… - The number of years each marriage lasted before it went to the marriage counsellor for a divorce. - If the marriage was the 1st, 2nd , or 3rd of the divorcees. We want to know if there is a difference in marriage lengths that can be explained by whether it was the first, second, or third marriage. Note: These are from 15 totally separate cases, just because there are 5 in each group, it doesn’t mean it’s 5 clients getting divorced three times each. This data is like an independent t-test, but with three samples. 1st marriage 8.50 9.00 6.75 8.50 9.50 2nd marriage 7.50 4.75 3.75 6.50 5.00 3rd marriage 2.75 4.00 1.50 3.75 3.50 First, let’s plot the data in a scatterplot. (Ch8_28.sav) (Graphs Legacy Dialogs Scatter/Dot Then choose Simple Scatter and click Define) We’re using 1st/2nd/3rd marriage to explain the length of the marriage, so length[Years] is the Y variable, Marriage number [MarNum] is X. Result: A definite difference in lengths by marriage number. Next, we quantify the trend from the scatterplot with ANOVA. We’re comparing three means, so it’s in Compare Means Analyze Compare Means One-Way ANOVA. We want to see if Marriage Length depends on Marriage Number, so Length goes in the dependent list, and Number goes in as the factor. (Nominal data always goes in factor) Then click OK. These are the results: p-value is less than .001, so there is strong evidence that the st nd rd 1 , 2 , and 3 marriages are not all the same length. Also, most of the variance in marriage lengths can be explained by marriage number (at least among this counsellor’s clients). Specifically, the proportion of variance explained by the groups is: SSbetween / SStotal = 71.808 / 89.058 = 0.806 ….analogous to r 2 = 0.806. Notes: If there were only two groups like “First marriage” and “Other” we could do a two-sample t-test. It would be independent and assume pooled variance. (p-value less than = .000, degrees of freedom = 13, t = 4.856) st All of the groups have roughly the same amount of spread (1 nd marriages were 7-10 years, 2 marriages were 4-8 years, and 3rd 2-4 years) . As long as there isn’t one or two groups that are MUCH more spread out (i.e. more variable) than the others, then ANOVA works. Let’s round it out with an example with more than 3 means. Example: Tea Brewing. Let’s say we want to know if black tea being brewed in different parts of the world has different amounts of caffeine. We brew large batches from 10 different shipments from the world’s four largest tea exporting countries: China, India, Kenya, and Sri Lanka. We then measure the caffeine in terms of mg/250mL (a cup), and record the results in Caffeine.sav What now? First: Identify. We want to know how interval data (caffeine content) changes as a function of nominal data (country of origin). Is this a cross tab problem? First: Identify. We want to know how interval data (caffeine content) changes as a function of nominal data (country of origin). Is this a cross tab problem? NO. Cross tabs are useful when both variables are categories (nominal or ordinal). Caffeine content isn’t a category unless we simplify it to “Low”, “Medium”, “High”. We won’t do this without good reason. Is this a correlation or regression problem? Is this a correlation or regression problem? No, but it’s close. We COULD do a regression with dummy variables. But we would need three dummy variables. Also, all our tests would be comparing teas against the teas of whatever country became the baseline, or intercept, and we don’t have a specific ‘baseline’ country to compare against. Is this a t-test problem? Is this a t-test problem? No, it’s a tea test, not a t-test. It’s structured very similarly to a t-test (do the mean responses change between the groups?), but a t-test is only good for comparing… - One group mean against a specific value or… - Two group means against each other. Is this an ANOVA problem? Is this an ANOVA problem? Yes. It is. We have an interval response that is dependent on a nominal variable. We’re also interested whether the country matters at all, so a wide-ranging but low-detail method like Analysis of Variance is a good tool for the job. ****HANDY SLIDE**** Knowing the data type of your explanatory and response variables tells you a lot about the type of analysis you should do. Explanatory: Interval (X) Response: Interval (Y) Correlation Regression Explanatory: Nominal (group) Response: Interval T-Test ANOVA Explanatory: Nominal Response: Nominal Odds Ratio Chi-Squared For interest: Nominal response, interval explanatory covered at the 300 level, see “Logistic Regression” and “Clustering”. Start with a visualization when possible. For ANOVA, that’s usually a scatterplot. Each column is country, in the order China India Kenya Sri Lanka Now we’re ready to do an ANOVA. Using alpha = 0.05, we reject the null hypothesis that all four countries’ tea has the same amount of caffeine in it. We reject this because Sig., our p-value, is less than 0.05. Also, we can tell that the country of origin explains… 235.611 / 281.67 = 0.836 …or 83.6% of the variation in caffeine content in teas. *This data set is made up, I imagine any results wouldn’t be nearly this conclusive. This Slide For interest: We’re comparing 4 means, so 4-1 df are for the means. Each group had 10 data points, that’s 10 – 1 = 9 df each, or 36 df in total for within groups. That makes a total of N – 1 = 40 – 1 = 39 degrees of freedom. Do our ANOVA results tell us that all four means are different? NO. Rejecting the null in ANOVA just implies that some of the means are different. Like chi-squared, the ANOVA F-test doesn’t tell us which ones are different or in what direction, just that the group (country of origin) matters. ANOVA is often used as a first step in a major analysis to see what the important factors are before doing detailed work. The first two countries (China and India) have about the same caffeine, however, not every country’s tea has the same caffeine. The second part, “not all the same”, is what the ANOVA F-test is testing. We can see from the graph that Sri Lankan tea has more caffeine than other countries’ tea and that Kenyan tea has less. To test these differences, we should use something more specific that an ANOVA test. (t-test with multiple testing?) Also, none of these countries’ teas have a lot more or a lot less variance than the rest of the groups. That means pooled standard deviation, a requirement of ANOVA, is a reasonable assumption. Next time: At least 2 more ANOVA examples, student reviews. FINALS SUGGESTIONS, ASSIGNMENT: DUE WEDNESDAY