Short-ish example: Handedness and Career Field
advertisement

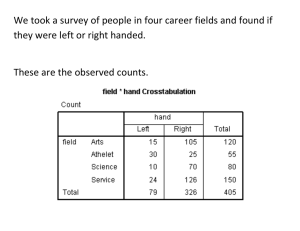
Short-ish example: Handedness and Career Field Long example: Handedness and Brain Mapping ANOVA: Jumping from 2 sample t-test to 3+ samples. Final review session (optional for the class) Aug 7 10am-noon. West Mall Centre 3260. Final exam questions recommended so far: Zero. Don’t forget about the secondary resources on the bottom of the webpage, they can help. We took a survey of people in four career fields and found if they were left or right handed. These are the observed counts. Most of the respondents are right handed except for in the athletics field, where a few more than half are left handed. Is this a fluke? We want to know or if career and handedness are somehow dependent. We have a 2x4 crosstab, so we should use a chi-squared test. These are the results: Degrees of freedom = 2 χ = There is evidence against independence. We have a 2x4 crosstab, so we should use a chi-squared test. These are the results: Degrees of freedom = 3 2 χ = 50.434 There is very significant evidence against independence. The chi-squared test has a very small p-value (less than .001). Do the results of this test tell us that there are more left handed people in athletics in general? The chi-squared test has a very small p-value (less than .001). Do the results of this test tell us that there are more left handed people in athletics in general? No. Chi-squared only checks whether two variables are independent, not specific trends within them. By comparing the expected and observed counts, we can see that the athletic field is much different from the others. We can use this information to guide a next step even if we’re not getting definite answers from just the expected counts. We could try merging the other three fields into “non-athletic” and “athletic”, as long as those three fields together fairly represented everything non-athletic. In that case, the odds ratio shows that someone in the athletic field has 7.371 times the odds of being left handed as someone in a non-athletic profession. The confidence interval shows that this odds ratio is significantly more than 1 at the alpha = 0.025 level. One more cross tab analysis. Because they belong in pairs. We randomly selected 150 people from the pool of righthanded people, 70 from the pool of left-handed people, and 10 ambidextrous people (who use both hands equally well). Then we performed a brain scan and found that some people’s brains operated in a “mirrored” fashion to most other people. (The opposite half was activated that what we would expect) Ordinary Mirrored Total Right 126 24 150 Left 37 33 70 Both 4 6 10 Total 167 63 230 Ordinary Mirrored Total Right 126 24 150 Left 37 33 70 Both 4 6 10 Total 167 63 230 a) What is the probability of someone from this sample having mirrored brain activity? Ordinary Mirrored Right 126 24 Left 37 33 Both 4 6 Total 150 70 10 Total 167 63 230 a) What is the probability of someone from this sample having mirrored brain activity? Probability uses the frequency of the event in question and the total. Pr(Mirrored) = # that are mirrored / # total 63 / 270 = 0.273 Ordinary Right 126 Left 37 Both 4 Total Mirrored 24 33 6 167 63 Total 150 70 10 230 b) What are the odds of someone from this sample having mirrored brain activity? Ordinary Right 126 Left 37 Both 4 Total Mirrored 24 33 6 167 63 Total 150 70 10 230 b) What are the odds of someone from this sample having mirrored brain activity? Odds use the frequency of the event and the frequency of everything that wasn’t the event. Odds of Mirrored = # mirrored to # not mirrored = 63 to 167 = 0.377 Or: Pr / (1-Pr) = .273/(1-.273) = 0.377 c) Why can’t we use this data to estimate the probability and odds that someone has mirrored brain activity in the population as a whole?* We selected 150 righties, 70 lefties, and 10 ambidextrous people on purpose. They weren’t randomly selected. We may have done this to increase the number of left-handed people in the sample to improve the quality of methods like the chi-squared test. If we used this data to talk about the whole population (if we inferred something about the population) we would be assuming that about 70/230 or 30% of people are left handed. (In reality, it’s more like 12%) Each left-handed person had a greater chance of being in our sample than each right-handed person, so the chances of being in the sample weren’t equal for everyone. That makes the sample, with regards to handed-ness, not random. Ordinary Mirrored Total Right 126 24 150 Left 37 33 70 Both 4 6 10 Total 167 63 230 e) What are the odds of someone in this sample having mirrored brain activity conditional on them being right-handed? Right Ordinary Mirrored 126 24 Total 150 Left 37 Both 4 Total 33 6 63 70 10 230 167 e) What are the odds of someone in this sample having mirrored brain activity conditional on them being right-handed? Only use the data from the right-handed cases because of the condition. Odds = 24 to 126 = 0.190 e) Can we estimate the odds of a right-handed person in the population having mirrored brain activity? YES. The distortion from selection a certain proportion of left/right/both handed people doesn’t affect our estimate when we’re only considering one type of handedness to begin with. For this question, we’re only interested in right-handed people, so that’s our population. Every right-handed person had an equal chance of being in the same, therefore sampling was random. What’s the difference between parts C and E? Why is it okay to infer for only right handed people and not every one? When considering all people Sample Population Right 65% 83% Left 30% 12% Both 5% 5% When only considering right-handed people Sample Population Right 100% 100% Left 0% 0% Both 0% 0% When considering all people Sample Population Right 65% 83% Left 30% 12% Both 5% 5% If we had picked the number of left/right handed people to match the population, this would have been a stratified sample. Each of the types of handedness would be a stratum, and the brain activity would be the value of interest. We want to test if handedness/brain activity are independent. Ordinary Mirrored Right 126 24 Left 37 33 Both 4 6 Total 167 63 Total 150 70 10 230 We would use the chi-squared test. However, there is a potential problem. We have very few people in the both-handed cells. Chi-squared generally needs an expected frequency of 5 in each cell to be accurate. Ordinary Mirrored Right 126 24 Left 37 33 Both 4 6 Total 167 63 Total 150 70 10 230 The common solution: Merge two categories. Which two should we merge? For any benefit, it has to be Both-handed with something? In this case, it makes more sense to merge Left-handed and Both-handed. The frequencies indicate they are the two most similar categories. Ordinary Right 126 Mirrored 24 Total 150 Other 41 39 80 Total 167 63 230 Now we have a 2x2 cross tab. In this case, we could use either the chi-square or the odds ratio. The odds ratio is easier to compute, and it lets us do one-tailed tests, so we’ll do that. Ordinary Mirrored Right 126 24 Other 41 39 Total 167 63 Total 150 80 230 Odds ratio by quick formula: AD/BC OR = (126)(39) / (24)(41) = 4.99 The odds of having mirrored brain activity if you something other than right handed is 4.99 times as much as it is when you are right handed. Ordinary Mirrored Right 126 A 24 C Other 41 B 39 D The interpretation of the odds ratio is found directly in the quick formula: AD/BC The odds are (OR) times as high if (A or D) instead of (B or C) Here, that’s the odds of (Ordinary Righthand or Mirrored Left/Bothhand) are 4.99 times higher than (Ordinary Left/Bothhand or Mirrored Righthand) The 95% confidence interval of the odds ratio is (2.656 to 9.389) That means at alpha = 0.05, the handed-ness and having mirrored brain activity or not are dependent on each other. Why? The odds ratio of 1 is not in the confidence interval. An odds ratio of 1 implies that the odds of one thing are just as much as the odds of another thing. In our case that would be the odds of having a mirrored brain are the same regardless of handedness. This slide for interest, skip in lecture: *Technically, we could use our sample to infer to the population (for all handedness), but we would need a method called weighting. Since we oversampled the left-handed people, we could use a weighted probability that counts each sampled left-handed person for less so that their total contribution to the probability, their WEIGHT in other words, matched the proportion of people that are left handed in the population. Here, lefties are 30% of the sample, but 12% of the population, so each lefty would count for a 12/30 of a sampled person. 19 slide example problem, woo! All that leaves is AnOVa A simple ANOVA in a familiar form. Around Week 7-9, we looked at how to find a difference between the means of two groups. We did this by taking a sample mean from each group and comparing the difference to the standard error. Our method of testing whether this difference was significant (in other words, testing the null hypothesis that the difference between the true means was zero) was the t-score. It was always t = (difference) / Standard Error. The definition of standard error depended on the details (paired/independent, pooled/non-pooled standard deviation) If the difference was bigger, the t-score was bigger and we more often rejected the null hypothesis. It’s easier to say a difference is real when the sample mean difference is larger. (Easier to detect larger effects) If there was more scatter between the points within a group, the standard error got bigger, and we more often failed to reject the null hypothesis. Standard error also gets smaller when there are more data points. In every case that the t-test is used, you’re ultimately just answering one question over and over again: Are the differences between the two groups large compared to the differences within each group? Can we use the t-test to determine if there are differences between any of the three means from three samples? We can’t do this all as a single t-test, because the t-test is only a comparison between two sample means. We have three We could test each pair of groups and look for differences. If we found a significant difference between two means, that would imply that not all the means are the same. We’d need to test: Mean of group 1 vs group 2 Mean of group 2 vs group 3 Mean of group 1 vs group 3 Doing multiple t-tests takes time, and what’s worse: It opens up the issue of multiple testing (the more tests you to, more likely you are to commit an error like falsely rejecting the null) A much cleaner solution is the F-statistic of ANOVA. MS stands for Mean Squared, and MSwithin is the average squared difference from a data point to the average for the that group. It’s the mean squared WITHIN a group If we were just looking at a single group, this average squared distance would be the standard deviation squared, or the variance. MSwithin is large when the spread within the samples is large. Spread/variance within a sample makes it hard to detect differences between the samples, and so the F-statistics gets smaller, just like the t-statistic. MSbetween is large when there are large differences between the sample means. MSbetween stands for the differences between means, instead of within them. Here, the average (squared) difference from a group mean to the grand mean, the average of data points from all the groups put together, is much larger than the differences between each point and its group mean. F will be large and there is strong evidence that there is some difference is the true means between the groups. Next time: More on ANOVA, ANOVA tables, and examples.