Nonlinear Capital Taxation Iván Werning, MIT September 19, 2011 (12:24 Noon)
advertisement
")
Nonlinear Capital Taxation
Iván Werning, MIT
September 19, 2011 (12:24 Noon)
Abstract
In the presence of private information, constrained optima may call for a distortion
or wedge in the intertemporal Euler equation for consumption. However, without
explicitly modeling a savings choice subject to taxation, one cannot immediately interpret this as a tax on savings. In this paper I provide a construction that provides
this interpretation: I take any given mechanism and augment it to allow a choice over
savings subject to nonlinear taxation. The tax is required to be independent of the
current shock, so that the returns to saving are risk free. I show that the augmented
mechanism implements the original allocation. The tax schedule is differentiable under natural conditions and its derivative, the marginal tax, coincides with the wedge
in the worker’s intertemporal Euler equation. The implementation favors a progressive tax in the sense that the schedule can always be made convex, but not necessarily
concave. However, I show that in some cases a linear tax suffices. Finally, I show how
to make the savings tax independent of the history of shocks.
1
1 Introduction
When insurance is imperfect, individuals smooth consumption by saving and dissaving.
However, if insurance is limited due to the presence of asymmetric information, then it
may be best to restrict free access to savings. Indeed, constrained optima are typically
incompatible with free savings and require distortions in the intertemporal path for consumption [Rogerson, 1985]. In dynamic Mirrlees models, where productivity is private
information, this has been interpreted as a justification for capital taxation (Diamond and
Mirrlees, 1978; Golosov et al., 2003; Kocherlakota, 2005). The question I address here is
the precise form of such a tax system.
One possibility is to ban private savings altogether. The government can then engage
in public savings and control private consumption directly, through taxes and transfers.
This essentially replicates the direct mechanism underlying the revelation principle. Although theoretically possible, tax systems that are less extreme seem of greater interest.
First, an outright ban on private savings is far from current policy discussions and is
likely to be impractical. Second, tax policies that allow for savings are more revealing, as
when marginal tax rates make explicit the distortions that are otherwise implicit in the
allocation.
Kocherlakota [2005] and Albanesi and Sleet [2006] provide tax systems that are less extreme than a direct mechanism. Kocherlakota proposes an implementation where wealth
is taxed linearly, at a rate that depends on the agent’s current and past report for productivity. In his implementation, the dependence on the current report is crucial. It ensures
that zero saving is optimal for the agent regardless of the reporting strategy. In Albanesi
and Sleet’s implementation wealth plays a more active role, with taxes set according to a
nonlinear function of wealth and the current shock. However, the implementation only
works for the optimal allocation in a setting with i.i.d. shocks. In both implementations,
the dependence of the wealth tax on the current shock makes the rate of return on savings
risky. Both papers also require utility from consumption to be additively separable from
the disutility of labor.
The goal of this paper is to offer a new implementation with some desirable features.
First, I seek to implement any incentive compatible allocation, not just optimal ones. Second, I consider persistent shocks, modeling productivity as a general Markov process.
Third, I do not require utility from consumption to be additively separable from that of
labor. Finally, I consider nonlinear savings taxes that are restricted to be independent of
the current shock, so that the after-tax rate of return on savings is risk free.
When the agent can save, the planner must induce the agent to follow some prescribed
2
savings plan. The precise savings plan is indeterminate, since the planner can reshuffle
the agent’s net income across periods, using labor taxes and transfers. The proof that it
is possible to induce some prescribed savings plan using the tax instruments allowed in
my proposed implementation is constructive and proceeds by a dynamic programming
argument.
I first show that there exists a lowest tax schedule for the next to last period that makes
it optimal not to deviate at that stage, provided the agent has not deviated in prior periods. This lower bound is defined by the agent’s indifference to all saving levels. Any
other tax schedule that coincides at the prescibed level of saving and lies weakly above
it elsewhere, induces the prescribed level of saving. Once the prescribed level of saving
is induced, truth-telling follows because the original allocation is incentive compatible.
Note that the tax schedule constructed may depend on the history of reports up to the
next to last period, but, by definition, not on the last period’s report.
The construction then continues by backward induction. Taking as given the tax
schedules imposed in future periods, there exists a tax in the current period that induces
an agent, who has not deviated up to this point, to be indifferent to all saving levels. Any
schedule that is above this lower bound and coincides with it at the prescribed level induces the agent not to deviate from this point forward. We can then construct the entire
sequence of tax schedules that induces the prescribed savings plan.
Having constructed a sequence of tax schedules that implements the allocation, I turn
my attention to deriving some properties of these schedules. I first investigate differentiability and show that under plausible conditions, there are differentiable tax schedules that
implements the allocation. Furthermore, whenever the tax schedule is differentiable, its
derivative, the marginal tax, coincides with the wedge in the agent’s intertemporal Euler
equation.1 Thus, under my implementation, wedges equal marginal taxes.
Next I study the shape of these tax schedules. As explained above, in any period,
the construction implies a lower bound for the allowable tax schedules. It follows that
one can always choose a convex schedule, but not necessarily a concave one, unless the
lower bound is concave. In this sense, progressive taxation, with rising marginal taxes,
is favored by my implementation. Despite this general property, I show that concave or
linear tax schedules are possible in many cases. Indeed, whenever a concave schedule
is possible, it follows that a linear tax that is tangent to it also works. I examine a wide
number of examples numerically and find that a concave lower bound schedule in all
1 The
intertemporal wedge is defined, for any given allocation, as the proportional adjustment in the
rate of return that is required for the standard consumption Euler equation to hold, i.e. letting Uc,t denote
marginal utility at time t the wedge τt is such that Uc,t = β(1 + rt )(1 − τt )E t [Uc,t+1].
3
cases.
Finally, I explore the possibility of making the savings tax history independent, so
that agents face the same tax schedule in all periods, regardless of their past history. It is
important to understand that most allocations, including optimal ones, feature intertemporal wedges that depend on the history. Thus, the challenge is to construct a savings tax
that is history independent, yet delivers the appropriate history-dependent wedges.2
The key idea is to ensure that wealth is a sufficient statistic for the desired intertemporal wedge. Agents with different histories choose different saving levels, ending up
on different positions of the same tax schedule, precisely where the marginal tax rate
equals the intended intertemporal wedge for them. This can be done by exploiting the
aforementioned indeterminacy in the prescribed savings plan.
The shape of the history-independent schedule is restricted because it must be the upper envelope, appropriately transposed, of all history-independent tax schedules. This
implies that it must be sufficiently convex. In this way, history independence favors progressive taxation.
An attractive feature of my implementation is that it avoids unnecessary taxation.
Suppose we confront agents with the simplest of tax systems: labor income is taxed, but
agents can borrow and save freely, with no savings tax. The equilibrium under this system
produces a particular incentive-compatible allocation, where the intertemporal wedge
is zero, by definition. Taking this allocation as the starting point, one can then request
different implementation schemes to support it. With my proposed implementation one
recovers the original tax system, with no tax on savings. In other words, the original
simple tax system is one of the supporting implementations. In this sense it is a fixed
point of sorts. In contrast, the implementation constructed in Kocherlakota [2005] calls
for non-zero and stochastic taxes on savings. For this implementation, the original simple
tax system is not a fixed point of this thought experiment. The implementation demands
a tax on savings, to support an allocation that was generated with no tax on savings.3
Some well-known examples in the literature seem directly at odds with my results.
These examples motivated the need for state-dependent savings taxes—that is, for conditioning on current productivity or labor income—and also suggested a distinction between wedges and marginal taxes. In particular, Kocherlakota [2004, 2005] shows that
2 Studying
the subset of allocations and welfare that obtain using relatively simple and historyindependent tax systems (including the tax on savings and income) is an interesting different question
that is not attempted here. The goal here, as stated at the outset of the paper, remains to implement any
incentive compatible allocation, not a subset. The goal now is to attempt this with a history-independent
savings tax, but allowing the labor-income tax to remain history dependent.
3 One cannot ask the same question for the implementation in Albanesi and Sleet [2006], since their
results only apply to optimal allocations (which feature savings distortions).
4
if the savings tax is differentiable and state-independent, then the agent may plan on a
“double deviation”: saving some positive amount and reporting a lower shock in the
next period. In the example, productivity types are discrete and the optimal allocation
has the agent indifferent between truth telling and underreporting productivity. When
the agent is allowed to save, any small amount of wealth breaks indifference in favor of
underreporting. As a result of this double deviation the intended implementation fails.
These examples allow one to conclude that optimal allocations, discrete shocks, differentiable tax functions and state-independent taxes are incompatible. Kocherlakota relaxes
the latter assumption and proceeds to characterize state-dependent taxes.
This paper takes a different route. I show that a nonlinear tax can substitute for state
depenence. Although I do not rule out kinks a priori, I show that kinks do not arise
under plausible conditions when productivity is continuously distributed. On the other
hand, kinks are natural with discrete shocks. One cannot expect a model to generate
differentiable tax schedules, if primitives, such as the distribution of productivity, are
not continuous. Indeed, with discrete shocks, kinks also arise in the labor-income tax
schedule, even in the static Mirrlees [1971] model.4 It seems inconsistent to insist on a
differentiable savings tax, and allow kinks in the labor-income tax. Thus, I do not rule out
kinks a priori.
2 Non-Linear Tax Implementation
I begin with a two-period horizon version of the model. Time periods are denoted t = 0, 1.
Productivity is given by θt . Initial productivity, θ0 , is known, while θ1 is uncertain. It is
realized privately to the agent at t = 1. An allocation specifies c0 , y0 , c1 (θ1 ), y1 (θ1 ) and
delivers utility
v0∗ = U 0 (c0 , y0 , θ0 ) + βE U 1 c1 (θ1 ), y1 (θ1 ), θ1 ,
where U t (c, y, θ ) represents the utility in period t = 0, 1, assumed to be increasing in c and
θ, concave in (c, y) and satisfy the standard single-crossing condition that the marginal
rates of substitution Uct (c, y, θ )/Uyt (c, y, θ ) is increasing in θ, for any given (c, y).
Unlike Kocherlakota [2005] and Albanesi and Sleet [2006], the implementation I develop does not require additively separable utility of the form U (c, y, θ ) = u(c) − h(y, θ ).
Theoretically, the additively separable case is an important benchmark since it separability is required for the Inverse Euler equations to characterize constrained optimal alloca4 In
Mirrlees (1971), kinks may be required in the income-tax schedule even when the distribution of
productivity is continuous if bunching is optimal over some interval of productivities. These kinks have no
counterpart in the savings tax schedule under my implementation.
5
tions. Empirically, Aguiar and Hurst [2005] provide evidence supporting departures from
separability in the direction of assuming that consumption (expenditures) c and labor y
are Hicksian complements, so that Ucy > 0.
Incentive compatibility requires truth telling to be optimal
U 1 c 1 ( θ1 ), y 1 ( θ1 ), θ1 ≥ U 1 c 1 (r 1 ), y 1 (r 1 ), θ1
for all θ1 ∈ Θ and all r1 ∈ Θ; here, r1 represents the report made by the agent regarding
the true shock θ1 .
This concludes the description of the model’s environment. The main goal of this
paper is to extend a given mechanism so that it allows for saving and attains the same
equilibrium allocation. For that purpose, it is unnecessary to introduce technology, or to
set up a planning problem and solve for optimal allocations.
For any given incentive compatible allocation (c0 , y0 , c1 (θ1 ), y1 (θ1 )), consider an implementation that confronts the agent with the following budget constraints:
c̃0 + a1 ≤ c0 ,
c̃1 ≤ R(a1 ) + c1 (r1 ).
Here where R(·) represents the retention function, with R(0) = 0. Without loss of generality, one can take R to be increasing, since the agent will never save at a level where R is
locally decreasing. If the net interest rate is i then R(a) − (1 + i )a represents the nonlinear
tax on wealth at t = 1.
Equivalently, consider the budget constraints
c̃0 + M( x1 ) ≤ c0 ,
c̃1 ≤ x1 + c1 (r1 ),
for M = R−1 , with M(0) = 0. If the net interest rate is r then M( x ) − x/(1 + r ) represents
a nonlinear savings tax at t = 0. Clearly, one can go back and forth between R and M. I
shall use the second formulation and refer to M as the savings tax function.
These budget constraints strictly augment the original direct mechanism by adding a
saving choice x1 ; the constraints effectively specialize to the direct mechanism when x1 =
0. The agent takes M as given and optimizes by choosing a saving and reporting strategy.
The tax function M is said to implement the proposed allocation (c0 , y0 , c1 (θ1 ), y1 (θ1 )) if
the agent finds it optimal to save zero x1 = 0. The original incentive compatibility of the
allocation then ensures that truth telling is optimal.
6
Consider the agent’s problem in two stages. In the second period, the agent enters
holding wealth x1 , then productivity θ1 is realized and the agent makes a report r1 . The
utility obtained is
V1 ( x1 , θ1 ) ≡ max U 1 c1 (r1 ) + x1 , y1 (r1 ), θ1 .
r1
Define the set of maximizers to be
R∗ ( x1 , θ1 ) ≡ arg max U 1 c1 (r1 ) + x1 , y1 (r1 ), θ1
r1
Given a choice of x1 , expected utility is
W0 ( x1 ; M) ≡ U 0 c0 − M( x1 ), y0 , θ0 + βE [V1 ( x1 , θ1 )].
If M(0) = 0 and the allocation is incentive compatible then W0 (0; M) = v0∗ . Now define
M∗ ( x ) so that
W0 ( x1 ; M∗ ) = v0∗
∀ x1 ,
implying
M∗ ( x1 ) ≡ c0 − Ψ0 v0∗ − βE [V1 ( x1 , θ1 )], y0 , θ0 ,
(1)
where Ψt (·, y, θ ) denotes the inverse of U t (·, y, θ ).
The tax schedule M∗ is the lowest possible schedule to implement the desired allocation. It makes the agent indifferent to all saving levels. Higher schedules, with M(0) = 0,
also work by discouraging deviations from x1 = 0 still further. Lower schedules, on the
other hand, with M( x1 ) < M∗ ( x1 ) for some x1 , cannot work because they offer higher
utility than v0∗ . I summarize these arguments in the following proposition.
Proposition 1. Any incentive compatible allocation (c0 , y0 , c1 (θ1 ), y1 (θ1 )) can be implemented
with a savings tax schedule M( x1 ) as long as
M ( x1 ) ≥ M ∗ ( x1 )
∀ x1
with M(0) = M∗ (0) = 0 and M∗ ( x1 ) defined by equation (1).
In the next two sections I examine the shape of tax functions satisfying Proposition 1.
3 Differentiability: Marginal Taxes and Wedges
In this section, I investigate the differentiability of tax schedules. For any allocation
(c0 , y0 , c1 (θ1 ), y1 (θ1 )), define m∗ by
7
Uc0 (c0 , y0 , θ0 )m∗ ≡ βE Uc1 c1 (θ1 ), y1 (θ1 ), θ1 .
To interpret m∗ , suppose technology offers a marginal net rate of return of ρ. Then
m∗ −
1
1+ρ
is a measure of the intertemporal distortion implicit in the allocation, sometimes referred
to as the intertemporal wedge or implicit marginal tax rate.
When M( x1 ) is differentiable at x1 = 0, the first-order condition for the agent at zero
savings and truth telling is
Uc0 (c0 , y0 , θ0 ) M′ (0) = βE Uc1 c1 (θ1 ), y1 (θ1 ), θ1 .
It follows that the marginal tax equals the intertemporal wedge:
M ′ (0 ) = m ∗ .
In other words, implicit and explicit marginal tax rates coincide. Next, I seek conditions
for M′ (0) to exist.
Since M∗ acts as a lower envelope for M at x = 0, it follows that M inherits certain
properties of M∗ . As we shall see, M∗ can only have convex kinks. Thus, if M is differentiable at x = 0, then its derivative, the marginal tax, must coincide with that of M∗ .
Moreover, M can be differentiable at x = 0 only if M∗ is differentiable at x = 0.
To establishing differentiability of M∗ one can verify the differentiability of V1 (·, θ1 ).
Since V1 is defined as a maximization, I appeal to an envelope theorem. In particular,
Corollary 4 in Milgrom and Segal [2002] applies. It implies that V1 (·, θ1 ) has left and right
derivatives given by
∂
V1 ( x1 +, θ1 ) =
max Uc1 (c1 (r ) + x1 , y1 (r1 ), θ1 )
∂x1
r1 ∈ R∗ ( x1 ,θ1 )
∂
V1 ( x1 −, θ1 ) =
min Uc1 (c1 (r ) + x1 , y1 (r1 ), θ1 )
∂x1
r1 ∈ R∗ ( x1 ,θ1 )
If the agent’s optimal reporting strategy is unique, so that R∗ ( x1 , θ1 ) is a singleton, the left
and right derivative coincide. Kinks only occur if the agent is indifferent to two or more
8
reports r1 . In addition, we always have
∂
∂
V1 ( x1 −, θ1 ) ≤
V1 ( x1 +, θ1 )
∂x1
∂x1
so that
M∗′ ( x1 −) ≤ m∗ ≤ M∗′ ( x1 +).
Thus, the implict marginal tax given by m∗ is sandwiched between the two explicit marginal
taxes M∗′ ( x1 −) and M∗′ ( x1 +).
I now show that the tax schedule M∗ is differentiable if the distribution of productivity is continuous. Intuitively, indifference is “knife edge” and occurs with zero probability. Since V1 (·, θ1 ) is differentiable, except on a set of probability zero, it follows that
E [V1 (·, θ1 )] is differentiable.
Proposition 2. If θ1 has a continuous distribution then M∗ ( x1 ) defined by equation (1) is differentiable and M∗′ (0) = m∗ .
Proof. Incentive compatibility implies that c1 (θ1 ) and y1 (θ1 ) are non-decreasing functions
of θ1 . It follows that there are at most countably many points of discontinuity. Define Θ̂ to
be the set of points of discontinuity in c1 (·). By Theorem 3 in Milgrom and Segal (2002),
the function V1 ( x1 , θ1 ) is differentiable with respect to x1 at x1 = 0 and θ1 ∈
/ Θ̂, with
1
derivative given by the envelope formula: Vx (0, θ1 ) = Uc (c1 (θ1 ), y1 (θ1 ), θ1 ) (since r1 = θ1
is optimal by incentive compatibility). The function of interest to us is
V̄1 ( x1 ) ≡ E [V1 ( x1 , θ1 )],
Thus, V̄1 is the integral of a function that is differentiable at x1 = 0, except on a set of
countable points. With a continuous distribution for θ1 the set of points of non-differentiability
is of probability zero. It then follows that V̄1 ( x1 ) is differentiable at x1 = 0 with derivative
V̄1′ (0) = E Vx (0, θ1 ) = E Uc1 c1 (θ1 ), y1 (θ1 ), θ1 .
If productivity types are finite, so that Θ = {θ 1 , θ 2 , . . . , θ N }, indifference may occur
with positive probability, producing a convex kink. This happens when there are binding
incentive constraints, a common feature of optimal allocations. However, this source for
kinks should not be a concern. First, with finite types, kinks are inherent to the Mirrlees
[1971] model and are also present in the labor-income tax schedule. Second, although
implementing an optimum with finite types requires kinks, one can get arbitrarily close
to this optimum using differentiable schedules. Finally, in the limit as the number of finite
9
types increases and we approach a continuous distribution, kinks disappear, in that the
left and right derivatives converging to each other.
4 Linear and Progressive Capital Taxation
Although a key element of my implementation is to allow for nonlinear taxation, in some
cases a linear tax will do. By Proposition 1, tax function M with M( x1 ) ≥ M∗ ( x1 ) and
M(0) = 0 implements the desired allocation. It follows that, if M∗ ( x1 ) is concave, one
can let M( x1 ) be the linear tangent at x1 = 0.
When can we expect M∗ to be concave? Its definition in equation (1) shows that a sufficient condition for concavity of M∗ is for E [V1 (·, θ1 )] to be concave.5 In turn, a sufficient
condition for concavity of E [V1 (·, θ1 )] is for each V1 (·, θ1 ) function to be concave, for all
θ1 ∈ Θ.6
Concavity of V1 ( x1 , θ1 ) is not a foregone conclusion. A sufficient condition for concavity is that the agent faces as a convex tax schedule in the second period, so that the
the loci of points (y, c) available to him are in a convex relation. This will be the case if
labor-income taxation is progressive.
Proposition 3. (a) If E [V1 (·, θ1 )] is concave a linear schedule M( x1 ) = m∗ x1 implements the
optimal allocation with zero savings; (b) If labor-income taxation is progressive in period t = 1,
then V1 ( x1 , θ1 ) is concave.
5 Arbitrary Finite Horizon
In this section we extend the previous results to a longer horizon, with periods t =
0, 1, . . . , T. The agent has utility function
T
∑ βt E[U t (ct , yt , θt )].
(2)
t =0
We assume {θt } is a Markov process with θt ∈ Θ.
Consider any incentive compatible allocation (c(θ t ), y(θ t )) with equilibrium values
v(θ t ) satisfying
v(θ t ) = U t c(θ t ), y(θ t ), θt + βE [v(θ t+1 )|θt ].
(3)
5 This follows by the following fact. Suppose f : R → R is decreasing and concave and that g : R → R
is decreasing and convex. Then f ( g(·)) is concave.
6 Of course, these conditions are not necessary. For example, E [V (·, θ )] may be concave even if V (·, θ )
1
1
1
is only concave for a subset of values of θ1 .
10
The agent’s optimization problem is captured by the associated Bellman equation
w(r t−1 , θt ) = max U t c(r t ), y(r t ), θt + βE [w(r t , θt+1 )|θt ] .
rt
(4)
An agent with current shock θt enters the period with a history r t−1 which affects the
contract. Thus, the state variable is (r t−1 , θt ). The agent chooses the report rt to maximize
utility. Note that the Markov assumption allows us to ignore the history of shocks θ t−1 .
For an incentive compatible allocation, truth telling is optimal even if the agent has made
false reports in the past.
Incentive compatibility is equivalent to
w (r t − 1 , θ t ) = v (r t − 1 , θ t ),
so that v defined by the recursion (3) solves the Bellman equation (4).
5.1 Nonlinear Tax Implementation
For any given incentive compatible allocation (c(θ t ), y(θ t )), consider the budget constraints
c̃t + M( xt+1 , r t ) ≤ xt + c(r t ),
(5)
with initial condition x0 = 0 and terminal condition x T +1 ≥ 0. If technology offers a net
marginal rate of return ρt , then M( xt+1 , r t ) − xt+1 /(1 + ρt ) represents a tax on savings.
The goal of the implementation is to find a sequence of functions { M( xt+1 , r t )} to
ensure that the agent finds it optimal not to save, so that xt+1 = 0 for all t = 0, 1, . . . , T.
To simplify, I refer to { M( xt+1 , r t )} as tax functions. The agent’s dynamic programming
problem has state variables xt , r t−1 and θt with Bellman equation
V ( xt , r t−1 , θt ) = max U t c(r t ) + xt − M( xt+1 , r t ), y(r t ), θt + βE [V ( xt+1 , r t , θt+1 ) | θ t ]
rt ,x ′
(6)
with V ( x T +1
, rT , θ
T +1 )
= 0 so that
V ( x T , r T −1 , θT ) = max U T c(r T ) + x T , y(r T ), θT .
rT
It is useful to define W ( xt , xt+1, r t , θt ) as the right hand side of the Bellman equation
W ( xt , xt+1, r t , θt ) ≡ U t c(r t ) + xt − M( xt+1 , r t ), y(r t ), θt + βE [V ( xt+1 , r t , θt+1 ) | θ t ] (7)
11
I proceed recursively, starting in the last period and working backwards.
5.2 Last Two Periods
I start at T − 1 when only two periods remain. The argument is similar to the two period
case studied previously, but now there are shocks and reporting in both periods.
At t = T − 1 impose
W (0, x T , r T −1 , θT −1 ) ≤ v(r T −2 , θT −1 )
W (0, 0, (r T −2 , θT −1 ), θT −1 ) = v(r T −2 , θT −1 )
∀ x T , r T −1 , θ T −1
(8)
∀r T −2 , θ T −1
(9)
The inequality ensures that if the agent arrives in period T − 1 with zero savings, x T −1 =
0, then it is optimal to report the current shock truthfully, r T −1 = θT −1 , and not save, x T =
0. The equality ensures that this delivers the same utility as originally, or, equivalently
that M(0, r T −1 ) = 0. These conditions are both necessary and sufficient to implement
the desired allocation. If the inequality is violated the agent can do better by deviating
to another savings level x T 6= 0. Similarly, if the equality is violated it must be that the
original allocation is not available.
These conditions do not ignore double deviations. Indeed, if the agent were to deviate
and save x T 6= 0, then misreporting r T 6= θT may be optimal. Relatedly, if the agent misreports r T −1 6= θT −1 , then saving x T 6= 0 may be optimal. Thus, double deviations may be
better than single deviations. In this implementation, there is no need to ensure that double deviations are not strictly prefered to single deviations. Instead, the conditions ensure
that not deviating at all is preferable to any set of deviations. This is in contrast to the
implementation in Kocherlakota [2005] which rules out double deviations by ensuring
that zero saving is optimal for any reporting strategy.
The inequalities are equivalent to imposing that
M ( x T , r T −1 ) ≥ M ∗ ( x T , r T −1 )
(10)
M∗ ( x T , r T −1 ) ≡ max M̃∗ ( x T , r T −1 , θT −1 ),
(11)
where
θ T −1
M̃∗ ( x T , r T −1 , θT −1 ) ≡ c(r T −1 )
i
h
− ΨT −1 v(r T −2 , θT −1 ) − βE [V ( x T , r T −1 , θT ) | θT −1 ], y(r T −1 ), θT −1 . (12)
12
Here, M̃∗ represents a fictitious tax function that ensures that each agent θT −1 is indifferent to any savings and report, that is, that the inequality (8) holds with equality for all x T ,
r T −1 and θT −1 . Such a tax function is not really feasible, since it would have to depend on
the true type θT −1 , in addition to report r T −1 . Taking the upper envelope over true types
θT −1 to define M∗ yields takes care of this. When an agent θT −1 faces M∗ , instead M̃∗ ,
they will generally not be indifferent to various savings and reports.
Note that, for each r T −1 and θT −1 , the fictitious tax M̃∗ is the analog of the tax function
defined in equation (1), where θT −1 = θ0 was known. The innovation here is to take the
upper envelope over θT −1 and to condition on the history r T −1 . This rules out misreporting in period T − 1 as well as in period T.
The tax function M∗ is defined as the lowest possible tax that prevents a deviation.
Any tax function that is lower necessarily violates inequality (8) for some agent θT −1 . Feasible tax functions M must lie above M∗ , satisfying inequality (10), and have M(0, r T −1 ) =
0.
5.3 Earlier Periods
I now work backwards, defining a tax schedule for all periods t = T − 2, T − 3, . . . , 0.
Suppose tax schedules for periods s = t + 1, t + 2, . . . , T − 1 have already been constructed. Associated with these tax schedules { M( xs+1 , r s )}sT=−t1+1 are value functions
{V ( xs , r s−1, θs )}sT=−t1+1 . I seek to construct a tax schedule M( xt+1 , r t ) and value function
V ( xt , r t−1 , θt ) for period t.
Recall that these functions W ( xt , xt+1, r t , θt ) are given by (7) using next period’s value
function V ( xt+1 , r t , θt+1 ) and the current tax schedule M( xt+1 , r t ), which must be constructed. I impose that, whatever the value function V ( xt+1 , r t , θt+1 ), that the tax function
M( xt+1 , r t ) be such that the implied W satisfy
W (0, xt+1 , r t , θt ) ≤ v(r t−1 , θt )
W (0, 0, (r t−1 , θt ), θt ) = v(r t−1 , θt )
∀ x t +1 , r t , θt
(13)
∀r t −1 , θt
(14)
The previous conditions (8)–(9) are the special case of conditions (13)–(14) for t = T − 1.
The same arguments lead us to define
M∗ ( xt+1 , r t ) ≡ max M̃∗ ( xt+1 , r t , θt ),
θt
13
(15)
where
∗
t
t
M̃ ( xt+1 , r , θt ) ≡ c(r ) − Ψ
t
h
v (r
t −1
t
t
, θt ) − βE [V ( xt+1 , r , θt+1 ) | θt ], y(r ), θt
i
and impose:
M ( x t + 1 , r t ) ≥ M ∗ ( x t + 1 , r t ).
(16)
Given a choice for M( xt+1 , r t ) this defines a value function V ( xt , r t−1 , θt ) using the Bellman equation (6).
Continuing this way gives a tax schedule M( xt+1 , r t ) and value function V ( xt , r t−1, θt )
for t = 0, 1, . . . , T − 1. This construction ensures that the Bellman equation (6) holds
and that the maximum is attained by truth-telling and no savings in all periods t =
0, 1, . . . , T − 1. By the principle of optimality this implies that truth telling and no savings is optimal among all possible reporting and savings strategies satisfying the budget
constraint (5).
Proposition 4. Any incentive-compatible allocation {c(θ t ), y(θ t )}tT=0 can be implemented using the budget constraints (5) by any sequence of tax functions on savings { M( xt+1 , r t )}tT=−01
satisfying the inequalities (16), where M∗ ( xt+1 , r t ) defined implicitly from { M( xt+1 , r t )}tT=−01
using conditions (15) and the Bellman equation (6). Conversely, if a sequence of tax functions
{ M( xt+1 , r t )}tT=−01 implements the incentive-compatible allocation {c(θ t ), y(θ t )}tT=0 it must satisfy inequalities (16).
The characterization provided by (15)–(16) is exhaustive, providing all the tax schedules that implement the allocation. Note that, according to equation (15), the tax schedules { M( xs+1 , r s )}sT=−t1+1 affect the schedule M∗ ( xt+1 , r t ) in period t. Indeed, higher tax
functions { M( xs+1 , r s )}sT=−t1+1 lead to lower values of V ( xt+1 , r t , θt+1 ), resulting in lower
values for M∗ ( xt+1 , r t ). In this way, there is a trade-off between current and future taxes.
We conclude that, unlike the two-period horizon case, it is incorrect to interpret the sequence generated by setting M( xt+1 , r t ) = M∗ ( xt+1 , r t ) for t = 0, . . . , T − 1 as producing
lowest possible tax schedules.
6 History Independent Taxation
I now explore the possibility of making the savings tax history independent. It is important to understand that most allocations, including optimal ones, have history-dependent
intertemporal wedges. Thus, the challenge is to create a savings tax that is history independent, but still manages to deliver the appropriate history-dependent wedges. I show
14
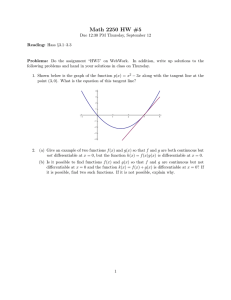
M̂ ( x )
M( x; r ′′ )
M( x; r ′ )
0
M( x; r )
Figure 1: A kinked upper envelope M̂ ( x ) function constructed from M( x; r ) functions
that have not been transposed.
two ways to do this.
The first implementation takes the history independent schedule as the upper envelope of the history dependent ones:
M̂ ( x ) ≡ sup M( x, r t ),
rt
where each function M(·, r t ) is constructed as in section 5 . Since M̂ ( x ) ≥ M( x, r t ) and
M̂ (0) = M(0, r t ) by definition, this history independent tax continues to implement zero
savings. However, because the slope Mx (0, r t ) equals the intertemporal wedge, if the
latter varies across histories r t , the upper envelope M̂ defined in this way will necessarily
have a kink at x = 0. Indeed, the left and right derivatives are the smallest and largest
intertemporal wedge, respectively. This situation is depicted in Figure 1.
The second way of achieving history independence attempts to avoid creating kinks.
Up to now, the implementations have zero savings. In contrast, the next implementation
relies on agents making non-trivial saving decisions. The idea is to have savings act as a
sufficient statistic for the intertemporal wedge. Different savings place agents at different
points along the same history-independent schedule, precisely where the marginal tax
rate equals the desired intertemporal wedge.
The construction relies on Ricardian equivalence arguments, which ensures that there
there are many tax functions that implement the same allocation, each with a different
15
x
savings choice. As I show below, this degree of freedom can be exploited to construct a
history independent tax schedule.
Agents face budget constraints
c t + M ( x t + 1 , r t ) ≤ x t + y (r t ) − T (r t ).
(17)
Here T represents an income tax on labor income. We now separate more explicitly the
income and savings taxes. Previously, we worked with a particular income tax, given by
T (r t ) = y (r t ) − c (r t ).
Suppose { M(·, r t ), T (r t )} implements {c(r t ), y(r t )} with zero savings, x (r t ) = 0 for all
r t . First, consider the set of perturbations defined by:
M̃( x, r t ) = M( x, r t ) + ∆v (r t )
T̃ (r t ) = T (r t ) − ∆v (r t ).
Clearly this perturbation does not affect the budget constraint, since only the sum of taxes
paid matters and M + T = M̃ + T̃. As a result, this perturbation continues to implement
{c(r t ), y(r t )} with zero savings x (r t ) = 0. Next, consider the set of perturbation defined
by
M̃( x, r t ) = M( x − ∆h (r t ), r t )
T̃ (r t+1 ) = T (r t+1 ) + ∆h (r t+1 ).
This perturbation increases labor income taxes at t + 1 but provides a deduction in the
savings tax at t. By saving x (r t ) = ∆h (r t ) in period t the agent is able to pay for the
increase in taxes at t + 1. Indeed, the set of feasible sequences {c(r t ), y(r t )} is unchanged.
Thus, this perturbation implements {c(r t ), y(r t )} with savings given by x (r t ) = ∆h (r t )
for all r t .
Geometrically, the first perturbation shifts the savings tax schedule vertically, while
the second does so horizontally; indeed, the subscripts v and h in ∆ stand for vertical and
horizontal, respectively. Combining both perturbations we can reposition, each function
M(·, r t ) both vertically and horizontally, for any history r t .
The goal is now as follows. One is given some sequence of functions { M(·, r t ), T (r t )}
that implements some allocation. The idea is to reposition each tax schedules M(·, r t ) so
that M̃(·, r t ) is tangent to a common, differentiable, upper-envelope function M̂( x ). If
this turns out to be possible, then, since M̂ lies above each M̃ (·, r t ) and is equal to it at the
proposed equilibrium saving points, the history-independent tax schedule M̂ together
16
M̂ ( x )
M( x; r ′′ )
M( x; r ′ )
0
x
M( x; r )
Figure 2: A smooth upper envelope M̂( x ) function constructed from transposed M( x; r )
functions.
with the labor tax { T̃ (r t )}, implement the same allocation as { M̃ (·, r t ), T̃ (r t )}, which, in
turn, implement the original allocation.
To see how finding a differentiable upper envelope may be possible, consider first the
case where the function M(·, r t ) is concave, for all history of reports r t . Now take any convex and differentiable function M̂( x ) such that limx→−∞ M̂′ ( x ) = −∞ and limx→∞ M̂′ ( x ) =
∞. Fix a history of reports r t and reposition M(·, r t ) so that the perturbed schedule M̃ (·, r t )
is equal to and tangent to M̂ at x = ∆h .7 Since M̂ is convex and M(·, r t ) is concave, it then
follows that M̃ ( x, r t ) ≤ M̂( x ) for all x, with equality at x = ∆h . Repeating this for all
histories r t , one constructs a perturbed sequence of tax schedules { M̃ (·, r t )} for which M̂
can play the role of an upper envelope. This situation is illustrated in Figure 2.
The upper envelope M̂ is not unique. Each M̂ requires a different sequence for the
taxes on labor { T̂ (r t )}. Moreover, the assumption that M̂ is convex in this case provides
a sufficient condition for M̃ ( x, r t ) ≤ M̂ ( x ), but convexity of M̂ is not necessary. There are
cases where a concave M̂ can play the role of an upper envelope. What is required is that
M̂ be “less concave” than each M(·, r t ). In this way, the curvature in the tax schedules
constrains the curvature of the upper envelope.
Similarly, as illustrated in Figure 3, when all the tax functions M(·, r t ) are convex we
can find an upper envelope M̂ that is “more convex” than each one of them. This is
possible if the convexity of the functions { M(·, r t )} is bounded in a sense made precise
7 That
is, setting M̂ ′ (∆h ) = M̃x (∆h , r t ) = Mx (0, r t ) and ∆v = M̂(∆h ) − M (0, r t ).
17
M̂ ( x )
M( x; r ′′ )
M( x; r ′ )
M( x; r )
0
x
Figure 3: A smooth upper envelope M̂( x ) function constructed from transposed M( x; r )
functions.
by the next proposition.
Proposition 5. Suppose the allocation {c(θ t ), y(θ t )}tT=0 is implemented by facing agents with
budget constraints (17) for some sequence of tax functions on savings { M( xt+1 , r t ), T (r t )}tT=−01
with M(·, r t ) differentiable at xt+1 = 0 for all r t . Suppose further that there exists a scalar A ∈ R
such that
M( x, r t ) ≤ Ax2 + Mx (0, r t ) x + M(0, r t )
(18)
for all for all history of reports r t . Take any twice differentiable function M̂ ( x ) with M̂′′ ( x ) ≥ A
for all x and inf.
Then the same allocation can be implemented with a history independent tax on savings
M̂ ( xt+1 ) and some alternative tax on labor { T̂ (r t )}tT=−01 .
The proposition provides a sufficient condition for the existence of a smooth upper
envelope. The key to condition (18) is that it bounds the convexity of the functions
{ M(·, r t )}. To see this, note that taken together, the last two terms, Mx (0, r t ) x + M(0, r t ),
represent the linear Taylor expansion for M(·, r t ). The quadratic term, Ax2 , contributes
strict convexity to the right-hand side of the condition. Thus, if the functions { M(·, r t )}
are all concave, the condition holds with A = 0. If the functions { M(·, r t )} are all twice
differentiable, a sufficient condition for inequality (18) is that their second derivative be
bounded above by some scalar A. The inequality (18) is weaker than this requirement,
for two reasons. First, it does not require the additional differentiability—the second
derivative need not exist, and the first derivative is only required at x = 0. Second, even
18
if M(·, r t ) is twice differentiable, the inequality (18) is weaker than a bounded second
derivative.8
Note that M̂ is not unique. Indeed, if M̂ can serve as an upper envelope, so too can
any more convex function. Indeed, this implementation favors convexity of the M̂ function. In this sense, progressive taxation of savings, with marginal tax rates that rise with
savings, emerges as a desirable feature. Of course, even if M̂ is convex, this does not say
anything about whether the overall tax system is “progressive”. First of all, this should
be hardly expected to be possible because the implementation is meant for any incentive
compatible allocation, regardless of its redistributive properties. Secondly, it is unclear
whether agents that will be saving more and, thus, facing higher marginal tax rates, are
“richer”. Given the allocation, each period agents are ordered by their intertemporal
wedge. This is used in this implementation as a sufficient statistic for their equilibrium
savings: those with a higher wedge must save more. But it is unclear whether agents with
a higher wedge are “richer” in the sense of having high productivity or enjoying higher
consumption.
Finally, it is worth pointing out that while this procedure removes the history dependence in the savings tax, the labor income tax remains generally history dependent.
Again, this should hardly be surprising in the present context, where we aim to implement any incentive compatible allocation. In abstract, it is unclear whether the labor
income tax becomes more or less sophisticated when we move from T (r t ) to T̃ (r t ). The
perturbations to T do have a simple interpretation in terms of lump-sum tax credits, for
∆v , or allowances and deductions on savings taxes, for ∆h . Social security benefits and
sheltered savings accounts that depend on the history of labor income are real-world
counterparts of the kind of instrument that is required.
References
Mark Aguiar and Erik Hurst. Consumption versus expenditure. Journal of Political Economy, 113(5):919–948, October 2005.
Stefania Albanesi and Christoper Sleet. Dynamic optimal taxation with private information. Review of Economic Studies, 2006. forthcoming.
8 In
particular, the second derivative could become unbounded away from x = 0 without violating the
the inequality (18). Note that if, instead, we limit ourselves to a discussion of the second derivative at x = 0
then, if M (·, r t ) is differentiable there, inequality (18) implies that that this second derivative is less than A
for all r t .
19
Peter A. Diamond and James A. Mirrlees. A model of social insurance with variable
retirement. Journal of Public Economics, 10(3), 1978.
Mikhail Golosov, Narayana Kocherlakota, and Aleh Tsyvinski. Optimal indirect and capital taxation. Review of Economic Studies, 70(3):569–587, 2003.
Narayana R. Kocherlakota. Figuring out the impact of hidden savings on optimal unemployment insurance. Review of Economic Dynamics, 7:541–554, 2004.
Narayana R. Kocherlakota. Zero expected wealth taxes: A mirrlees approach to dynamic
optimal taxation. Econometrica, 73(5):1587–1621, 2005.
Paul Milgrom and Ilya Segal. Envelope theorems for arbitrary choice sets. Econometrica,
70(2):583–601, March 2002.
James A. Mirrlees. An exploration in the theory of optimum income taxation. Review of
Economic Studies, 38(2):175–208, 1971.
William P. Rogerson. Repeated moral hazard. Econometrica, 53(1):69–76, 1985.
20