Decentralizing Grids Jon Weissman University of Minnesota E-Science Institute
advertisement

Decentralizing Grids
Jon Weissman
University of Minnesota
E-Science Institute
Nov. 8 2007
Roadmap
•
•
•
•
•
Background
The problem space
Some early solutions
Research frontier/opportunities
Wrapup
Background
• Grids are distributed … but also centralized
– Condor, Globus, BOINC, Grid Services, VOs
– Why? client-server based
• Centralization pros
– Security, policy, global resource management
• Decentralization pros
– Reliability, dynamic, flexible, scalable
– **Fertile CS research frontier**
Challenges
• May have to live within the Grid ecosystem
– Condor, Globus, Grid services, VOs, etc.
– First principle approaches are risky (Legion)
• 50K foot view
– How to decentralize Grids yet retain their existing
features?
– High performance, workflows, performance
prediction, etc.
Decentralized Grid platform
• Minimal assumptions about each “node”
• Nodes have associated “assets” (A)
– basic: CPU, memory, disk, etc.
– complex: application services
– exposed interface to assets: OS, Condor, BOINC, Web service
•
•
•
•
•
Nodes may up or down
Node trust is not a given (do X, does Y instead)
Nodes may connect to other nodes or not
Nodes may be aggregates
Grid may be large > 100K nodes, scalability is key
Grid Overlay
Grid service
Condor network
Raw – OS services
BOINC network
Grid Overlay - Join
Grid service
Condor network
Raw – OS services
BOINC network
Grid Overlay - Departure
Grid service
Condor network
Raw – OS services
BOINC network
Routing = Discovery
discover A
Query contains sufficient information to locate a node: RSL, ClassAd, etc
Exact match or semantic match
Routing = Discovery
bingo!
Routing = Discovery
Discovered node returns a handle sufficient for the “client” to interact with it
- perform service invocation, job/data transmission, etc
Routing = Discovery
• Three parties
– initiator of discovery events for A
– client: invocation, health of A
– node offering A
• Often initiator and client will be the same
• Other times client will be determined dynamically
– if W is a web service and results are returned to a calling
client, want to locate CW near W =>
– discover W, then CW !
Routing = Discovery
X
discover A
Routing = Discovery
Routing = Discovery
bingo!
Routing = Discovery
Routing = Discovery
outside
client
Routing = Discovery
discover A’s
Routing = Discovery
Grid Overlay
• This generalizes …
– Resource query (query contains job requirements)
– Looks like decentralized “matchmaking”
• These are the easy cases …
– independent simple queries
• find a CPU with characteristics x, y, z
• find 100 CPUs each with x, y, z
– suppose queries are complex or related?
• find N CPUs with aggregate power = G Gflops
• locate an asset near a prior discovered asset
Grid Scenarios
• Grid applications are more challenging
– Application has a more complex structure – multi-task,
parallel/distributed, control/data dependencies
• individual job/task needs a resource near a data source
• workflow
• queries are not independent
– Metrics are collective
•
•
•
•
not simply raw throughput
makespan
response
QoS
Related Work
• Maryland/Purdue
– matchmaking
CAN
• Oregon-CCOF
– time-zone
Related Work (cont’d)
None of these approaches address the Grid
scenarios (in a decentralized manner)
– Complex multi-task data/control dependencies
– Collective metrics
50K Ft Research Issues
• Overlay Architecture
– structured, unstructured, hybrid
– what is the right architecture?
• Decentralized control/data dependencies
– how to do it?
• Reliability
– how to achieve it?
• Collective metrics
– how to achieve them?
Context: Application Model
answer
= data source
= component
service request
job
task
…
Context: Application Models
Reliability
Collective metrics
Data dependence
Control dependence
Context: Environment
• RIDGE project - ridge.cs.umn.edu
– reliable infrastructure for donation grid envs
• Live deployment on PlanetLab – planet-lab.org
– 700 nodes spanning 335 sites and 35 countries
– emulators and simulators
• Applications
– BLAST
– Traffic planning
– Image comparison
Application Models
Reliability
Collective metrics
Data dependence
Control dependence
Reliability Example
B
C
G
E
D
B
G
Reliability Example
B
C
G
E
D
B
G
CG
CG responsible for G’s health
Reliability Example
B
C
G
E
D
B
G, loc(CG )
CG
Reliability Example
B
C
G
E
D
BG
CG
could also discover G then CG
Reliability Example
B
C
G
E
D
X
B
CG
Reliability Example
B
C
G
E
D
G. …
CG
Reliability Example
B
C
G
E
D
G
CG
Client Replication
B
C
G
E
D
B
G
Client Replication
B
C
G
E
D
BG
CG2
CG1
loc (G), loc (CG1), loc (CG2) propagated
Client Replication
B
C
G
E
D
BG
CG2
X
CG1
client “hand-off” depends on nature of G and interaction
Component Replication
B
C
G
E
D
B
G
Component Replication
B
C
G
E
D
G1
CG
G2
Replication Research
• Nodes are unreliable – crash, hacked, churn,
malicious, slow, etc.
• How many replicas?
– too many – waste of resources
– too few – application suffers
System Model
• Reputation rating ri– degree of node
0.9
reliability
0.8
0.8
0.7
0.7
• Dynamically size the redundancy
based on ri
0.4
• Nodes are not connected and
check-in to a central server
0.3
0.4
• Note: variable sized groups
0.8
0.8
Reputation-based Scheduling
• Reputation rating
– Techniques for estimating reliability based on
past interactions
• Reputation-based scheduling algorithms
– Using reliabilities for allocating work
– Relies on a success threshold parameter
Algorithm Space
• How many replicas?
– first-, best-fit, random, fixed, …
– algorithms compute how many replicas to meet a
success threshold
• How to reach consensus?
– M-first (better for timeliness)
– Majority (better for byzantine threats)
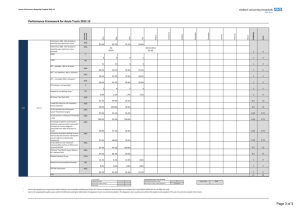
Experimental Results: correctness
This was a simulation based on byzantine behavior … majority voting
Experimental Results: timeliness
M-first (M=1), best BOINC (BOINC*), conservative (BOINC-) vs. RIDGE
Next steps
• Nodes are decentralized, but not trust
management!
• Need a peer-based trust exchange framework
– Stanford: Eigentrust project – local exchange until
network converges to a global state
Application Models
Reliability
Collective metrics
Data dependence
Control dependence
Collective Metrics
• Throughput not always the best metric
• Response, completion time, application-centric
– makespan
- response
BLAST
Communication Makespan
• Nodes download data from replicated data nodes
– Nodes choose “data servers” independently (decentralized)
– Minimize the maximum download time for all worker nodes
(communication makespan)
data download dominates
Data node selection
• Several possible factors
– Proximity (RTT)
– Network bandwidth
– Server capacity
Mean Download Time / RTT
[Download Time vs. RTT - linear]
1000
900
Time (msec)
800
flux
700
tamu
600
venus
500
ksu
400
ubc
300
wroc
200
100
0
1
3
5
Concurrency
7
10
[Download Time vs. Bandwidth - exp]
Heuristic Ranking Function
• Query to get candidates, RTT/bw probes
• Node i, data server node j
– Cost function = rtti,j * exp(kj /bwi,j), kj load/capacity
• Least cost data node selected independently
• Three server selection heuristics that use kj
– BW-ONLY: kj = 1
– BW-LOAD: kj = n-minute average load (past)
– BW-CAND: kj = # of candidate responses in last m
seconds (~ future load)
Performance Comparison
Computational Makespan
compute dominates:
BLAST
Computational Makespan
*
equal-sized
variable-sized
Next Steps
• Other makespan scenarios
• Eliminate probes for bw and RTT -> estimation
• Richer collective metrics
– deadlines: user-in-the-loop
Application Models
Reliability
Collective metrics
Data dependence
Control dependence
Application Models
Reliability
Collective metrics
Data dependence
Control dependence
Data Dependence
• Data-dependent component needs access to
one or more data sources – data may be large
discover A
,
Data Dependence (cont’d)
discover A
,
Where to run it?
The Problem
• Where to run a data-dependent component?
– determine candidate set
– select a candidate
• Unlikely a candidate knows downstream bw
from particular data nodes
• Idea: infer bw from neighbor observations w/r
to data nodes!
Estimation Technique
C1
• C1 may have had little past interaction with
– … but its neighbors
may have
C2
• For each neighbor generate a download estimate:
– DT: prior download time to
from
neighbor
– RTT: from candidate and neighbor to
respectively
– DP: average weighted measure of prior download
times for any node to any data source
Estimation Technique (cont’d)
• Download Power (DP) characterizes download capability
of a node
– DP = average (DT * RTT)
– DT not enough (far-away vs. nearby data source)
• Estimation associated with each neighbor ni
– ElapsedEst [ni] = α ∙ β ∙ DT
• α : my_RTT/neighbor_RTT (to
)
• β : neighbor_DP /my_DP
• no active probes: historical data, RTT inference
• Combining neighbor estimates
– mean, median, min, ….
– median worked the best
• Take a min over all candidate estimates
Comparison of Candidate Selection
Heuristics
Impact of Neighbor Size (Mix, N=8, Trial=50k)
55
OMNI
RANDOM
PROXIM
SELF
NEIGHBOR
50
45
Mean Elapse Time (sec)
40
35
30
25
20
15
10
5
0
2
4
8
16
Neighbor Size
32
SELF uses
direct observations
Take Away
• Next steps
– routing to the best candidates
• Locality between a data source and component
– scalable, no probing needed
– many uses
Application Models
Reliability
Collective metrics
Data dependence
Control dependence
The Problem
• How to enable decentralized control?
– propagate downstream graph stages
– perform distributed synchronization
• Idea:
– distributed dataflow – token matching
– graph forwarding, futures (Mentat project)
Control Example
B
C
G
E
D
B
control node
token matching
Simple Example
B
C
G
E
D
Control Example
{E, B*C*D}
B
{C, G}
C
G
{D, G}
{E, B*C*D}
E
D
{E, B*C*D}
Control Example
B
C
G
E
D
B
{E, B*C*D}
C
{E, B*C*D}
D
{E, B*C*D}
Control Example
B
C
G
E
D
B
{E, B*C*D,
loc(SB) }
C
{E, B*C*D,
loc(SC) }
D
{E, B*C*D,
loc(SD) }
output stored at loc(…) – where component is run, or client, or a storage node
Control Example
B
C
G
E
D
BB
C
D
Control Example
B
C
G
E
D
BB
C
D
Control Example
B
C
G
E
D
BB
C
D
Control Example
B
C
G
E
D
BB
E
C
D
Control Example
B
C
G
E
D
BB
E
C
D
Control Example
B
C
G
E
D
How to color and
route tokens so that
they arrive to the
same control node?
BB
E
C
D
Open Problems
• Support for Global Operations
– troubleshooting – what happened?
– monitoring – application progress?
– cleanup – application died, cleanup state
• Load balance across different applications
– routing to guarantee dispersion
Summary
• Decentralizing Grids is a challenging problem
• Re-think systems, algorithms, protocols, and
middleware => fertile research
• Keep our “eye on the ball”
– reliability, scalability, and maintaining performance
• Some preliminary progress on “point solutions”
My visit
• Looking to apply some of these ideas to existing UK
projects via collaboration
• Current and potential projects
– Decentralized dataflow: (Adam Barker)
– Decentralized applications: Haplotype analysis (Andrea
Christoforou, Mike Baker)
– Decentralized control: openKnowledge (Dave Robertson)
• Goal – improve reliability and scalability of applications
and/or infrastructures
Questions
EXTRAS
Non-stationarity
• Nodes may suddenly shift gears
– deliberately malicious, virus, detach/rejoin
– underlying reliability distribution changes
• Solution
– window-based rating
– adapt/learn ltarget
• Experiment: blackout at
round 300 (30% effected)
Adapting …
Adaptive Algorithm
throughput
success rate
throughput
success rate
Scheduling Algorithms
Estimation Accuracy
• Objects: 27 (.5 MB – 2MB)
• Nodes: 130 on PlanetLab
• Download: 15,000 times from a
randomly chosen node
• Download Elapsed Time Ratio (x-axis) is a ratio of estimation to real
measured time
– ‘1’ means perfect estimation
• Accept if the estimation is within a range measured ± (measured * error)
– Accept with error=0.33: 67% of the total are accepted
– Accept with error=0.50: 83% of the total are accepted
Impact of Churn
Comparision of Elapsed Time (Candidate=8, Neighbor=8)
6.5
Without Churn
Churn 0.1%
Churn 0.5%
Churn 1.0%
6
Ratio to Omniscient
5.5
Random mean
5
Global(Prox) mean
4.5
4
3.5
3
2.5
0
0.5
1
1.5
• Jinoh – mean over what?
2
2.5
Query
3
3.5
4
4.5
5
4
x 10
Estimating RTT
•
•
•
–
We use distance = √(RTT+1)
Simple RTT inference technique based on triangle inequality
Triangle Inequality: Latency(a,c) ≤ Latency(a,b) + Latency(b,c)
|Latency(a,b)-Latency(b,c)| ≤ Latency(a,c) ≤
Latency(a,b)+Latency(b,c)
• Pick the intersected area as the range, and take the mean
Lower
bound
Higher
bound
Via Neighbor A
Via Neighbor B
Via Neighbor C
Inference
Intersected range
Final inference
RTT
RTT Inference Result
• More neighbors, greater accuracy
• With 5 neighbors, 85% of the total < 16% error
Inferred Latency Difference CDF
1
0.9
N=2
N=3
N=5
N=10
0.8
0.7
F(x)
0.6
0.5
0.4
0.3
0.2
0.1
0
-150
-100
-50
0
50
100
Latency Difference (= |Inferred-Measured|)
150
200
Other Constraints
{E, B*C*D}
B
{C, A, dep-CD}
C
A
{D, A, dep-CD}
{E, B*C*D}
E
D
{E, B*C*D}
C & D interact and they should be co-allocated, nearby …
Tokens in bold should route to same control point so a collective query
for C & D can be issued
Support for Global Operations
•
•
•
•
Troubleshooting – what happened?
Monitoring – application progress?
Cleanup – application died, cleanup state
Solution mechanism: propagate control node
IPs back to origin (=> origin IP piggybacked)
• Control nodes and matcher nodes report
progress (or lack thereof via timeouts) to origin
• Load balance across different applications
Other Constraints
{E, B*C*D}
B
{C, A}
C
A
{D, A}
{E, B*C*D}
E
D
{E, B*C*D}
C & D interact and they should be co-allocated, nearby …
Combining Neighbors’ Estimation
Acceptance 50%
0.91
0.9
Accepted Rate
0.89
0.88
RANDOM
CLOSEST
MEAN
MEDIAN
RANK
WMEAN
TRMEAN
0.87
0.86
0.85
0.84
0.83
0
5
10
15
Neighbor Size
20
25
30
• MEDIAN shows best results – using 3 neighbors 88% of the time error is
within 50% (variation in download times is a factor of 10-20)
• 3 neighbors gives greatest bang
Effect of Candidate Size
Impact of Candidate Size (Mix, N=8, Trial=25k)
120
OMNI
RANDOM
PROXIM
SELF
NEIGHBOR
Mean Elapse Time (sec)
100
80
60
40
20
0
24
8
16
32
Candidate Size
ALL
Performance Comparison
Parameters:
Data size: 2MB
Replication: 10
Candidates: 5
Computation Makespan (cont’d)
• Now bring in reliability … makespan
improvement scales well
# components
Token loss
• Between B and matcher; matcher and next stage
– matcher must notify CB when token arrives (pass
loc(CB) with B’s token
– destination (E) must notify CB when token arrives
(pass loc(CB) with B’s token
BB
E
C
D
RTT Inference
• >= 90-95% of Internet paths obey triangle
inequality
– RTT (a, c) <= RTT (a, b) + RTT (b, c)
– RTT (server, c) <= RTT (server, ni) + RTT (ni, c)
– upper- bound
– lower-bound: | RTT (server, ni) - RTT (ni, c) |
• iterate over all neighbors to get max L, min U
• return mid-point