Linux’s DCCP—slower than RFC 1149 Andrea Bittau June 21, 2006 Introduction
advertisement

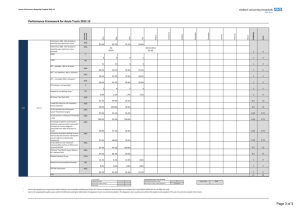
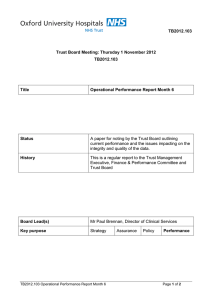
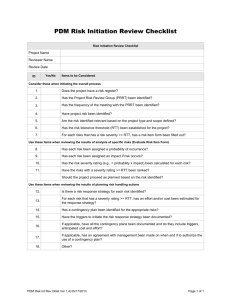
Introduction 100Mbit 1Gbit Conclusion 1/10 Linux’s DCCP—slower than RFC 1149 Andrea Bittau June 21, 2006 DCCP Introduction 100Mbit 1Gbit Conclusion 2/10 DCCP is a protocol with modular congestion control algorithms: CCID2: TCP-like. Use all available bandwidth but high variance in transmission rate. CCID3: TFRC. Low variance in transmission rate by sacrificing some bandwidth. Relevance: Define a CCID which suits application needs. Unreliable: do not waste time retransmitting—send new data. Linux implementation status Introduction 100Mbit 1Gbit Conclusion 3/10 Status of DCCP implementation in Linux 2.6.17 (latest): Has CCID2 and feature negotiation: thanks to this project. Most of the DCCP spec is implemented. Unstable and buggy. Wait for next Kernel before sending flames. Now that we got a lot of code in Linux, lets make it work. Performance tests Introduction 100Mbit 1Gbit Conclusion 4/10 The next milestone is to get DCCP to be stable and fast. Stress efficiency. 100Mbit/s, 0ms RTT. 1Gbit/s, 0ms RTT. Hardware: Athlon 1.2GHz. PCI 33MHz 32-bit. (≈1Gb/s.) Realtek 8169 1Gb/s. Stress correctness. 100Mbit/s, 100ms RTT. 1Gbit/s, 100ms RTT. 100Mbit/s, 0ms RTT Introduction 100Mbit 1Gbit Conclusion 5/10 Throughput: 94Mbit/s. Success! 500 cwnd pipe packets 400 300 200 100 0 0 10 20 30 time (s) CCID2 reported 45 losses: 37 were incorrect IP lengths. 8 were incorrect DCCP checksums. 40 50 60 100Mbit/s, 100ms RTT Introduction 100Mbit 1Gbit Conclusion Simulating delay with netem 6/10 Average throughput: 15.6Mbit/s. Failure! 500 cwnd pipe packets 400 300 200 100 0 0 10 20 30 40 50 60 70 time (s) CCID2 reports 10 losses. They all were incorrect IP lengths. TCP averages 75Mbit/s in this scenario. 1Gbit/s, 0ms RTT Introduction 100Mbit 1Gbit Conclusion 7/10 Throughput (CPU limited at TX): UDP: 335Mbit/s. TCP: 310Mbit/s. DCCP: 230Mbit/s. Kernel profile for DCCP run samples 3734 769 362 357 230 182 ... 151 % 20.1185 4.1433 1.9504 1.9235 1.2392 0.9806 0.8136 image name vmlinux vmlinux vmlinux vmlinux vmlinux vmlinux symbol name handle_IRQ_event __do_softirq rtl8169_rx_interrupt rtl8169_interrupt __copy_from_user_ll rtl8169_poll dccp_ccid2.ko ccid2_hc_tx_packet_recv 1Gbit/s, 100ms RTT Introduction 100Mbit 1Gbit Conclusion 8/10 Average throughput: 75Mbit/s. Failure! 3000 cwnd pipe packets 2500 2000 1500 1000 500 0 0 10 20 30 time (s) 40 50 60 CCID2 reports 543 losses. Some packets were never received, others were dropped in receiver’s DCCP stack. TCP achieves 206Mbit/s (CPU limited at TX). Summary Introduction 100Mbit 1Gbit Conclusion 9/10 Link speed 100Mbit/s 100Mbit/s 1Gbit/s 1Gbit/s RTT 0ms 100ms 0ms 100ms Throughput 94Mbit/s 15.6Mbit/s 230Mbit/s 75Mbit/s Bottleneck Link Implementation? CPU Implementation? I have also seen CCID2 do line rate with a powerful box on 1Gbit/s, 0ms RTT. Conclusion Introduction 100Mbit 1Gbit Conclusion 10/10 Preliminary results are not that bad: We expected more blue screens rather than numbers. Future work: [Get two powerful boxes.] Achieve 1Gb/s on a large delay network. Devise a performant API. Currently, one system call transmits one packet. Maybe we need something like writev. Implement a CCID which meets the requirements of VLBI.