Topic Selection of Wikipedia-Articles Dag Sonntag Department of Computer and Information Science (IDA)
advertisement
")
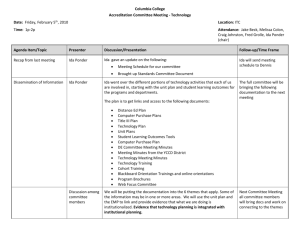
Topic Selection of Wikipedia-Articles Dag Sonntag Department of Computer and Information Science (IDA) Linköping University Sweden June 7, 2013 1 Overview Topic models Implementation and the project Results Conclusions and experiences Department of Computer and Information Science (IDA) Linköpings universitet, Sweden June 7, 2013 2 Dag Sonntag Topic Modelling - Theory Topic modelling is about finding underlying (hidden) themes in large datasets Can be used to organize, summarize, search or model the different themes Each topic is represented by a sub-model that is fitted to the samples representing that special topic Topic models can be both deterministic and probabilistic Department of Computer and Information Science (IDA) Linköpings universitet, Sweden June 7, 2013 3 Dag Sonntag Topic Modelling – Theory (2) - Inference Each sample (or document) is classified into the topic for which the corresponding model best explains the sample Example Two sentences: Three models, each with a probability of word in it being either cat, dog, ball or tree. “Dogs bark at cats” “Cats climb in trees” Model 1, Pr(dog = 0.5, ball = 0.3, cat = 0.2, tree = 0.0) Model 2, Pr(dog = 0.1, ball = 0.1, cat = 0.5, tree = 0.3) The first sentence is now more likely to belong to model 1, while the second only can belong to model 2 Department of Computer and Information Science (IDA) Linköpings universitet, Sweden June 7, 2013 4 Dag Sonntag Topic Modelling – Latent Dirichlet Allocation - Training LDA - A set of bag-of-word models Expectation step: Each document has a probability of belonging to each class depending on how good the model of that class explains the document The probabilities for each document sum up to 1 A class is randomly chosen with the probabilities above Maximization step: Each model is updated to fit the documents that belong to it Department of Computer and Information Science (IDA) Linköpings universitet, Sweden June 7, 2013 5 Dag Sonntag Implementation and the Project Problem statement: What underlying topic-structure exists on Wikipedia, and does this structure correspond to the known Wikipedia article structure Implementation: 1, Download random Wikipedia articles 2, Download Wikipedia articles within a known category 3, Preprocess these articles 4, Train topic models on the uncategorized articles 5, Classify the categorized articles with the trained topic models and see if articles from the same category belonged to the same topic Department of Computer and Information Science (IDA) Linköpings universitet, Sweden June 7, 2013 6 Dag Sonntag Implementation – Downloading and Preprocessing Articles Wikipedia has a random article generator-page that was used, title and text was then mined The preprocessing: HTML-tags and code were removed Only kept alpha-numeric characters, and then even removed the numbers Removed stopwords, uncommon words (<1%) and very common words (>0.99%) Lower casing of letters No stemming used Department of Computer and Information Science (IDA) Linköpings universitet, Sweden June 7, 2013 7 Dag Sonntag Implementation – Topic Models Used Two different implementations of LDA One commercial (Gensim) One academic (OnlineLDAVB) One implementation of LSI (Gensim) Department of Computer and Information Science (IDA) Linköpings universitet, Sweden June 7, 2013 8 Dag Sonntag Results Clear and relatively separated topics were found Topic: 0: => Schools and places ['county', 'school', 'city', 'state', 'new', 'area', 'river', 'district', 'population', 'university', 'north', 'south', 'coordinates', 'west', 'station', 'town', 'location', 'road', 'east', 'also’] Topic: 1: => Articles and webpages etc. ['wikipedia', 'page', 'article', 'may', 'links', 'view', 'policy', 'pages', 'help', 'create', 'changes', 'terms', 'link', 'contact', 'privacy', 'edit', 'articles', 'categories', 'text', 'disambiguation'] Topic: 2: => History, wars, etc. ['also', 'may', 'one', 'used', 'united', 'first', 'two', 'war', 'world', 'article', 'family', 'states', 'new', 'time', 'name', 'species', 'see', 'system', 'would', 'many'] Topic: 3: => Music and culture ['first', 'also', 'one', 'new', 'album', 'music', 'film', 'two', 'released', 'time', 'party', 'john', 'song', 'band', 'later', 'life', 'years', 'series', 'may', 'house'] Topic: 4: => Sports ['team', 'club', 'league', 'career', 'season', 'first', 'new', 'football', 'born', 'player', 'won', 'united', 'cup', 'games', 'national', 'year', 'played', 'game', 'may', 'one'] Department of Computer and Information Science (IDA) Linköpings universitet, Sweden June 7, 2013 9 Dag Sonntag Results (2) Topics corresponding to existing Wikipedia classification: General reference, Culture and the arts, Geography and places, Health and fitness, History and events, Mathematics and logic, Natural and physical sciences, People and self, Philosophy and thinking, Religion and belief systems, Society and social sciences, Technology and applied sciences Found Topics: • Topic: 0: Scools and places, • Topic: 1: Articles and webpages etc., • Topic: 2: History, wars, etc., • Topic: 3: Music and culture, • Topic: 4: Sports Most articles were classified to the same topic Probably due to large differences in training data and testing data Department of Computer and Information Science (IDA) Linköpings universitet, Sweden June 7, 2013 10 Dag Sonntag Results (3) Major problems: The academic LDA and the LSI topic models did sometimes have problem differentiating the models Common words became common in all models Defining the priors Department of Computer and Information Science (IDA) Linköpings universitet, Sweden June 7, 2013 11 Dag Sonntag Conclusion and Experiences Wikipedia does provide solutions for data-mining, don’t go through the ”normal” web-crawling in the HTMLinterface Decide at an early stage what model to use, and from there also decide what features to use Topic modelling works pretty good Department of Computer and Information Science (IDA) Linköpings universitet, Sweden June 7, 2013 12 Dag Sonntag Questions? References: David M. Blei, Princeton Gensim: http://www.cs.princeton.edu/~blei/papers/Blei2012.pdf http://www.cs.princeton.edu/~blei/blei-mlss-2012.pdf http://www.cs.princeton.edu/~blei/topicmodeling.html http://radimrehurek.com/gensim/index.html Wikipedia: http://en.wikipedia.org/wiki/Latent_Dirichlet_allocation http://en.wikipedia.org/wiki/Latent_semantic_indexing Department of Computer and Information Science (IDA) Linköpings universitet, Sweden June 7, 2013 13 Dag Sonntag