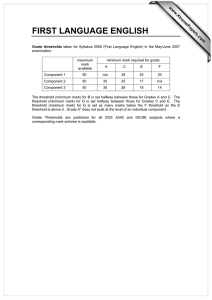
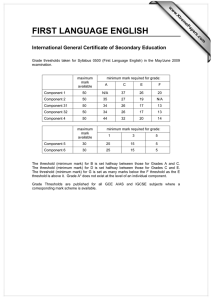
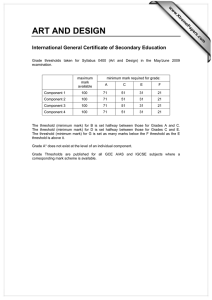
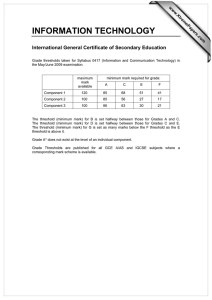
Survey Methods on Measuring Minimum Threshold for Association Rules
advertisement

International Journal of Engineering Trends and Technology- Volume3Issue3- 2012
Survey Methods on Measuring Minimum
Threshold for Association Rules
Pinnaboyina Tejaswi #1 Dhulipalla Navya #1 and D. Radharani #2
#1 Student,
M.Tech (CSE)
Green Fields, K.L.Univerisity,
Vaddeswaram, India.
#2
Assistant Professor, (CSE)
Green Fields, K.L.Univerisity,
Vaddeswaram, India.
Abstract: The extraction of information from large
amount of database in order to mine the frequent items
the association rules are used to discover the frequent
items, with that minimum threshold value the rules
have been discovered and these minimum threshold
value can be calculated by using some statistical
methods like support, confidence, lift, leverage all these
methods is discussed in this paper.
Keywords: Minimum threshold value, Analyst, Support,
Confidence, Lift, Leverage, Correlation, Conditional
Probability
I. INTRODUCTION
The retrieving of most useful information from
the database the discovering of this information may
help the market analysts in order to know which
items are most frequently occurred and by this
analysis they can take decisions for the items in their
market database. The rules are extracted by using
minimum threshold value the minimum threshold
value can be set by using the measures like support,
confidence, lift, leverage, conditional probability and
correlations by using all these methods the minimum
threshold value can be set. In order to set these
minimum threshold it should very accurate and
settings this minimum threshold may come across the
problems like if the minimum threshold is set too low
the inconsistency in the database may occur and if the
minimum threshold value is set too high means the
rare items which are more frequent can be missing
since all the rare items are discarded if it is set high
so it may leads the decision maker to make wrong
decisions so in order to overcome all these we are
going to discuss some measures to mine association
ISSN: 2231-5381
rules. The analyst is who makes the decisions to
improve the productivity as the ecommerce
applications are increasing rapidly the analyst are
interested in knowing the frequent items that are
purchased in their market so that they can take
actions like increasing in the productivity of that
frequently purchased items or to arrange the
frequently sold items according to their
occurrence(for e.g. the association rules like this
bread->butter and their probability of their
occurrence is high according to their occurrence the
minimum threshold is kept so that the items which
satisfy that min-threshold are mined and formed as
frequent items by knowing this details the analyst
may arrange the items side by side to increase the
sales) the minimum threshold value is described as
the cutoff point and this can be fixed by observing
the different patterns.
II. METHODS
As discussed in order to discover the items we
have different methods the first stage all the items are
which are present in the database is represented and
then by using some combinations the 2 items that are
frequent is represented by the rule and by the
minimum threshold the items which are below the
threshold is discarded and further it is applied for all
the subset and it is applied until all the specified
iterations are achieved like until (Ø value is occurred)
in this way all the items or the transactions in the
database is searched and then the rules are formed by
antecedent or precedent by this rules all the items
which satisfy those rules are extracted and by using
that threshold values finally the item sets which are
http://www.internationaljournalssrg.org
Page 286
International Journal of Engineering Trends and Technology- Volume3Issue3- 2012
most frequently occurred in the database is extracted
these threshold value can be measured in different
statistical methods like support, confidence, lift,
leverage, conditional probability, correlation[1].
III. SUPPORT
In data mining association rule learning is a
popular and well researched method for discovering
interesting relations between variables in large
databases. Piatetsky-Shapiro [4] describes analyzing
and presenting strong rules discovered in databases
using different methods of in te r e st in g n es s .
Based on the concept of strong rules, Agrawal
et.al [2] introduced association rules for discovering
regularities between products in large scale
transaction data recorded by point-of scale systems in
super markets.
For
example,
the
rule
{onions,
potatoes}=>{burger} found in the sales data of a
super market would indicate that if a customer buys
onions and potatoes together, he or she is likely to
also buy burger . Such information can be used as
the basis for decisions about marketing activities
such as, e.g., promotional pricing or product
placements. In addition to the above example from
market basket analysis association rules are
employed today in many application areas including
web usage mining, intrusion detection and
bioinformatics. To illustrate the concepts, a small
example from the supermarket domain. The set of
items is I = {milk, bread, butter, beer} and a small
database containing the items (1 indicates presence
and 0 indicates absence of an item in a transaction)
is shown in the table [1].
An example rule for the supermarket could be
{butter, bread} => {burger} meaning that if butter
and bread is bought, customers also buy milk. In
practical applications, a rule needs a support of
several hundred transactions before it can be
considered statistically significant and datasets
often contain thousands or millions of transactions.
To select interesting rules from the set of all
possible rules, constraints on various measures of
significance and interest can be used. The bestknown constraints are minimum thresholds on
support and confidence. The support supp(X) of an
item set X is defined as the proportion of
transactions in the data set which contain the item
set. In the example database, the item set {milk,
bread, butter} has a support of 1 / 5 = 0.2 since it
occurs in 20% of all transactions (1 out of 5
transactions).
ISSN: 2231-5381
TABLE 1
Database with Four Transactions and Five Items [2]
Tid
1
2
3
4
5
Milk
1
0
0
1
0
Bread
1
0
0
1
1
Butter
0
1
0
1
0
Beer
0
0
1
0
0
IV. CONFIDENCE
The confidence of a rule is defined conf{X=>Y}
=supp{X∪ Y}/supp{X}. For example, the rule {milk,
bread} => {butter} has a confidence of 0.2 / 0.4 =
0.5 in the database, which means that for 50% of the
transactions containing milk and bread the rule is
correct. Confidence can be interpreted as an estimate
of the probability P (Y|X), the probability of finding
the RHS of the rule in transactions under the
condition that these transactions also contain the LHS
[5].
A. LIFT
The lift of a rule is defined by the equation
Lift(X=>Y) = (supp (X ∪ Y)/supp (Y) *supp (X)) or
the ratio of the observed to support that expected
X and Y are independent.
B. CONVICTION
The rule {milk, bread}=>{butter} has a lift
of ((0.2)/ (0.4)*(0.4)) =1.25.The conviction of a
rule is defined as conv(X=>Y) =(1-supp(Y)/1conf(X=>Y)). The rule {milk, bread} => {butter}
has a conviction of ((1-0.4)/ (1-0.5)) =1.2, and can
be interpreted as the ratio of the expected frequency
that X occurs without Y (that is to say, the
frequency that the rule makes an incorrect
prediction) if X and Y were independent divided by
the observed frequency of incorrect predictions. In
this example, the conviction value of 1.2 shows that
the rule {milk, bread}=>{butter} would be incorrect
20% more often (1.2 times as often) if the
association between X and Y was purely random
chance.
For
e.g.
Interestingness
Measure:
Correlations (Lift) the correlation how strong one
item is dependent on the other item.
Play basketball eat cereal [40%, 66.7%]
is misleading. The overall % of students eating
cereal is 75% > 66.7%.
http://www.internationaljournalssrg.org
Page 287
International Journal of Engineering Trends and Technology- Volume3Issue3- 2012
Play basketball not eat cereal [20%, 33.3%] is
more accurate, although with lower support and
confidence.
large transactional DBs, all-conf or coherence could
be good measures, Both all-conf and coherence have
the downward closure property.
Measure of dependent/correlated events: lift
=
( , )=
,ﬧ
( ∪ )
( ). ( )
V. CONCLUSION
(2000/5000)
= 0.89
3000
∗
(3750/5000)
5000
1000
5000
=
= 1.33
3000
1250
∗
5000
5000
TABLE 2
The items of a database
Basket
ball
cereal
Not cereal
Sum(col.)
2000
1000
3000
Not
basket
ball
1750
250
2000
Sum(row)
3750
1250
5000
In this way the items of the database which are
having correlated are mined by using some
conditional probability liking by taking the condition
we are calculating the occurrence and non
occurrence of the event. Is lift and 2 Good
Measures of Correlations
Buy walnuts buy milk [1%, 80%]” is
misleading if 85% of customers buy milk and by the
results we can say that Support and confidence are
not good to represent correlations.
=
=
REFERENCES
[1] Alex Tze Hiang Sim,Maria Indrawan, Samar
Zutshi,
Member,IEEE, and Bala Srinivasan,“Logic-Based Pattern
Discovery,”IEEE transactions on knowledge and data engineering,
vol. 22,no.6,2010.
[2] R.Agrawal,T. Imielinski, and A. Swami, “Mining Association
Rules between Sets of Items in Large Databases,” SIGMOD
Record, vol. 22, pp. 207-216, 1993.
[3]C. Longbing, “Introduction to Domain Driven Data
Mining,” Data Mining forBusiness Applications, L.Cao,P.S.
Yu, C. Zhang, and H. Zhang, eds., pp. 3-10,Springer,2008.
[4]Piatetsky-Shapiro,G.(1991),Discovery, analysis and presentation
of strong rules, in G.Piatetsky – Shapiro & W. J. Frawley,
“Knowledge Discovery in Databases,” AAAI/MIT Press,
Cambridge, MA.
[5]Jochen Hipp, Ulrich Güntzer, and Gholamreza Nakhaeizadeh
“Algorithms for association rule mining”- A general survey and
comparison, SIGKDD,Explorations, 2(2):1-58, 2000.
( ∪ )
( ). ( )
(max_
ℎ=
All the statistical measures that are used for
association rules is discussed and according to these
measures the items which are more frequent is
discovered from the database.
( )
_sup( ))
( )
|universe( )|
All the statistical measures like support,
confidence ,lift, coherence is measured and these
results leads to extract the items from the database
and which measures should be used is discussed lift
and 2 are not good measures for correlations in
ISSN: 2231-5381
http://www.internationaljournalssrg.org
Page 288