Evaluation of Punjabi Extraction based Summarizer for Stories
advertisement

International Journal of Engineering Trends and Technology (IJETT) – Volume 6 Number 6- Dec 2013
Evaluation of Punjabi Extraction based Summarizer
for Stories
Vishal Gupta
Assistant Professor, UIET Panjab University,
Chandigarh, India
Abstract— Text Extraction based summarization is shortening
input text by extracting subset of suitable lines from input by
maintaining its meaning, concept and information. Overall we
can evaluate text Summaries by applying techniques of extrinsic
and intrinsic evaluation. In intrinsic techniques, we judge the
quality and correctness of summary using its evaluation by
human experts. On the other hand in extrinsic techniques, we can
judge the quality and correctness of summary by applying task
oriented evaluation methods like question answering, clustering
and classification etc. This paper has applied both intrinsic and
extrinsic measures of summary evaluation for sentence extraction
based Punjabi text summarization system. We know that Punjab
is among states of India and in Punjab the officially spoken
language is Punjabi. For other languages of India Tamil, Bengali,
Marathi and Hindi etc. a considerable number of research
papers can be found on text summarizers but in case of Punjabi,
there is only one research paper found on text summarization
which is developed by Gupta and Lehal in 2011 [5] [6] and can
be found online on web. Moreover, evaluating this summarizer is
not easy job because, no dataset of DUC/TAC is available for
Punjabi language. This paper discusses intrinsic techniques of
evaluating Punjabi summary including F-Measure, Cosine based
Similarity, coefficient of Jaccard and Euclidean distance. In
extrinsic techniques of evaluating Punjabi summary we have
used technique of question answering and task of association of
key terms. This task of evaluation is performed at 10% to 50%
compression ratios.
Keywords—Summarization, summary evaluation, text mining,
intrinsic evaluation, extrinsic evaluation.
I.
INTRODUCTION
Summary evaluation [1] is a essential component associated
with text summarization. Normally we can evaluate
summaries by applying either intrinsic, or extrinsic or both
techniques. . In intrinsic techniques, we can judge the quality
and correctness of summary using its evaluation by human
experts. On the other hand in extrinsic techniques, we can
judge the quality and correctness of summary by applying task
oriented evaluation methods like question answering,
clustering and classification etc. Text Extraction based
summarization [2] [3] [4] is shortening input text by extracting
subset of suitable lines from input by maintaining its meaning,
concept and information. We can divide text Summarization
into two methods: summarization using abstractive methods
and summarization using extractive methods. Abstractive
methods of summary evaluation involve understanding of
input text and reformulation of it in small number of terms and
sentences. At present abstractive summarization is very
ISSN: 2231-5381
difficult. It may take some time to reach a level where
machines can fully understand text documents. Extractive
summarization, involves retrieving relevant lines from input
text. Important lines are retrieved by applying methods of
statistics and linguistic.
We know that Punjab is among states of India and in
Punjab the officially spoken language is Punjabi. Which ia
also part of family of Indo-Aryan. Punjabi is not only spoken
in India but also in other countries like: UK, Canada, Pakistan,
USA and in various nations having immigrants of Punjabi. For
other languages of India Tamil, Bengali, Marathi and Hindi
etc. a considerable number of research papers can be found on
text summarizers but in case of Punjabi, there is only one
research paper found on text summarization which is
developed by Gupta and Lehal in 2011 [5] [6] and can be
found online on web. Similarly for evaluating Punjabi text
summary, no Punjabi summary evaluation system is available.
This is first time that, this paper has proposed the methods for
evaluating Punjabi text summary. Moreover for evaluation of
Punjabi text summary, no previous dataset of DUC/TAC is
available for Punjabi language. In Punjabi text summarization
system, each sentence of Punjabi document is considered as
feature vector for various features like sentences length,
Punjabi cue phrases, Punjabi nouns, Punjabi proper nouns,
sentence position, Punjabi tile words and Punjabi keywords
etc. Importance of different features deciding important lines
is calculated using method of weight learning i.e. regression
[4]. For every Punjabi sentence, score of each feature is
determined. Final value of scores for each line is found by
applying mathematical equation of features and weights.
Punjabi lines with high score values are retrieved finally in
summary. Coherence among lines is retained by ordering lines
in the same order of input lines. Duplicate sentences are
removed from input text. This paper is concentrated on both
intrinsic and extrinsic measures for summary evaluation for
Punjabi text summary. Gold summary is the reference
summary produced by human experts against which
performance of any automatic text summarization system can
be judged. Punjabi text summary evaluation is done on
Punjabi stories. Fifty Punjabi stories were collected from
www.likhari.org. Firstly we had prepared gold summaries
which were also called reference summaries from fifty stories
of Punjabi. For preparing these gold reference summaries of
50 Punjabi documents, we had given this work of creating
manual summaries to 03 human beings at different
compression ratios (i.e. at 10%, 30% & 50% C.R.). Ultimately
http://www.ijettjournal.org
Page 325
International Journal of Engineering Trends and Technology (IJETT) – Volume 6 Number 6- Dec 2013
we made reference gold summaries which were created by
involving all common lines in three sets of summaries
prepared by human beings.
II. RELATED WORK
Intrinsic method of evaluating the summary[7] is done
human beings. It is performed after comparing it with
reference summary created by human beings. The main issues
judged by intrinsic techniques of evaluating the summary are
information retained in summary and coherence. Recall &
Precision [1]: recall evaluates the frequency of lines of gold
summary which are also part of system created summary.
Similarly we can also calculate precision. In information
extraction, recall and precision are most commonly used
standard evaluation metrics and can be clubbed together to Fmeasure. The difficulties of these metrics are that these are
unable to tell the difference between different summaries
which are also equally good and in other case sometimes they
are unable to assign dissimilar score values to summaries
which are very much different from each others content wise.
In method of utility[8] gold summaries are allowed to contain
different units of extraction like lines and sections etc.) along
with membership which is fuzzy in nature in gold summary.
In this method of utility, gold summary consists of all the lines
in input text along with values of confidence for including
them in final summary. Moreover, we can extend this method
for granting units of extraction for exerting support to the
other which is negative in nature. It is very suitable in judging
quality of summaries which are based on extraction. Further
current experiments on evaluating the quality of summary
have shown way for developing another measure called
Relative Utility measure [9]. Also we can apply another metric
on judging similarity of contents [10] might be used for
judging the semantic content of extraction based summary and
abstraction based summary. Similar type of one metric is test
of vocabulary in which various information extraction
techniques can be applied for comparing vectors with
frequency of words. ROUGE is another measure for
evaluating quality of summary. Full form of ROUGE [11] is
recall-oriented understudy for gisting evaluation. It applies
different metrics for finding correctness and quality in
summary automatically by comparing the summary with gold
summary made by human being. It finds frequency of units of
text which are overlapping like n-grams, sequences of
different terms, and term combinations existing in systemcreated summary and gold summaries made by human beings.
Extrinsic techniques of evaluating the summary [1] find
overall efficiency of system created summaries for some real
time task like: finding whether summary is relevant or not or
by applying task of comprehension reading. Further, if there
are instructions contained in summary, we can find up to
which level these instructions can be followed and can
produce the results. Other tasks that can be applied for
evaluating quality of summary are gathering of information
from huge collection of text documents, document
classification, documents clustering, association of documents
and task of question answering etc. Contents of information
ISSN: 2231-5381
can be quantified by applying Shannon game [12] by
predicting next possible word. In this way it attempts to
recreate the input text. Same concept can be applied as
measures of Shannon’s in theory of Information in which one
can use 03 number of informants groups for again building of
relevant paragraphs in input text. Overall motive of game of
questions [1] is judging the reading and understanding ability
of users for any summary and to judge whether summary is
highlighting key points of input text. In task of classification
[13] we can compare classifiability by telling human experts
for classifying either input text documents or system made
summaries to any class. In this classification task, summaries
should have been categorized to same class as of input
document. Association of keyword is an approach which
depends on association of key terms automatically or
manually to input documents to be summarized. Saggion et al,
(2000) [14] discussed human experts having system generated
summaries along with five key terms lists arranged from
research papers published in publication journal. Then experts
were assigned job of associating summary with key terms list.
If this task was successful then that summary was able to
cover key points of research article.
III.
INTRINSIC SUMMARY EVALUATION FOR PUNJABI TEXT
SUMMARIZATION
This paper has discussed four intrinsic measures [15] [16]
of summary evaluation for Punjabi text: a) F-Measure b)
Cosine-Similarity c) Coefficient of Jaccard and d) Euclidean
distance for Punjabi stories. For Punjabi story articles, Initial
metric of evaluating summary quality, F-measure is applied at
different compression ratios from 10% to 50%.
F-measure= (2 x Precision x Recall) /Precision+ Recall
Recall=
(Frequency of correct lines extracted by system) / (Total
frequency of lines extracted by human expert)
Precision=
(Frequency of correct lines extracted by system) / (Total
number of lines etracted by system)
For 2nd intrinsic metric of evaluating the summary, Cosine
similarity is calculated between system generated summary
and reference summary made by human beings. Using this
metric, documents are denoted as vector of words and
resemblance of two text documents relates to correlation
among their vectors of words. Suppose there are two text
documents. Vectors C and D are vectors of words frequency
for those text documents with set of words W= {w1,…….., wm}
Cosine similarity among these vectors can be found as:
Cosine-Similarity (C, D) = Cos(Ө)= (C ∙ D) / (|C| |D|)
= ∑ Cj × Dj / √ ∑ (Cj)2 ×√ ∑ (Dj)2 here j= 1 to k and every
dimension denotes a word alongwith frequency of that word in
input text document, and it is not negative and its value lies
from 0 to 1. For any two documents, If vaue of this metric
http://www.ijettjournal.org
Page 326
International Journal of Engineering Trends and Technology (IJETT) – Volume 6 Number 6- Dec 2013
lying near to 01 then it is understood that the two text
documents very close with each other and are almost similar.
For thosed text documents which are not similar, the value of
cosine similarity moves near to 0. In our case cosine
similarity is calculated between system made summary and
summary produced by human experts.
3rd metric of intrinsic summary evaluation we have applied
coefficient of Jaccard among summary made by our Punjabi
summarization system and reference summary created by
human beings. This metric judges resemblance between two
summaries with ratio of intersection to union between
different objects. For any two input text documents,
coefficient of Jaccard checks addition of weights between
words which are shared to addition of weights of words which
are lying in any two text documents and words are not shared.
With two input text documents with their word vectors C and
D and set of words W= {w1,…….., wm}
Coefficient_of_Jaccard = SIMILARITY (C, D) = (C ∙ D)/ (|C|2
+|D|2- C ∙ D)
= (C ∙ D) / (√ ∑ (C j)2 × √ ∑ (Cj)2 + √ ∑ (Dj)2 × √ ∑ (Dj)2 C ∙ D)
Here j= 1 to k with every dimension denotes a word
alongwith frequency of that word in input text document. The
value of this similarity metric lies from 0 to 1. If its value is
mving closer to 01 then we can conclude that these documents
are very close to each other and are similar. On the other hand
If its value moves closer to 0 then we can conclude that two
documents are vary far from each other and are dissimilar.
4th metric of intrinsic summary evaluation we have applied
Euclidean distance among summary generated by our Punjabi
summarizer and summary created by human beings as gold
summary. For judging distance among two input text
documents, along with keywords frequency vectors Yig and
Yjg here g= 1 to m key words. Then Euclidean distance
between documents can be given as: Euclidean distance(Yig,
Yjg)= ( ∑( Yig- Yjg)2 )1/ 2 where g=1 to m keywords.
IV.
EXTRINSIC SUMMARY EVALUATION FOR PUNJABI TEXT
SUMMARIZATION
Extrinsic metrics [1] for evaluating the summary are task
based. In our case for extrinsic evaluation of Punjabi summary,
we have applied task of query answering and association of
keywords at different CR ranging from 10% to 50%. In this
question answering task, initially 03 human beings were
assigned 50 Punjabi documents related to Punjabi stories and
after that these human experts created 05 questions jointly for
every Punjabi document related to stories. Then we tried to
find out answers of question sets made by human exerts into
summary made by our system. Value of counter was
incremented by 01 for every correct answer of the question
found in system made summary. We can calculate accuracy of
question answering as follows:
Accuracy_Question Answering_Task=
ISSN: 2231-5381
Frequency of correct answers found in summary/ Frequency
of questions asked.
In performing task of association of keywords, which are
the main thematic concept of the whole document and they
can denote the overall theme of input text. In this, Initially, 05
key terms called the gold key terms are retrieved manually
from every text document related to Punjabi stories by human
beings and after that we can try to associate these key terms
with the summary created by our summarizer. The value of
accuracy for this task is calculated as given below:
Accuracy_Keywords_Association_Task=
Frequency of reference key terms found in system made
summary/ Total frequency of reference key terms
V. RESULTS AND DISCUSSIONS
Test dataset for Punjabi Text Summarizer includes Punjabi
stories as given in TABLE I.
TABLE I
TEST DATASET FOR PUNJABI TEXT SUMMARIZER
Punjabi Stories
Total Documents
50
Total Sentences
17538
Total Words
178400
For intrinsic summary evaluation its results are given in
TABLE II at different C.R. from 10% to 30%.
TABLE II
RESULTS OF INTRINSIC SUMMARY EVALUATION FOR PUNJABI STORIES
Compressi
on Ratio
(In %)
10%
Intrinsic Summary Evaluation for Punjabi
Stories
FCosine
Jaccard
Euclidean
Score
Similarity Coefficien distance
t
(In %
)
81.78
0.82
0.81
1.02
30%
89.32
0.88
0.87
0.52
50%
94.21
0.94
0.93
0.40
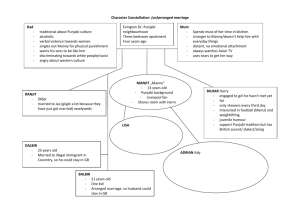
Intrinsic summary Evaluation for Punjabi stories at 30% C.R.
90
85
F-Score
Accuracy
80
Cosine Sim
Jaccard coff
75
Intrinsic Methods
Fig. 1. Results of intrinsic summary evaluation for Punjabi stories at 30%
CR
http://www.ijettjournal.org
Page 327
International Journal of Engineering Trends and Technology (IJETT) – Volume 6 Number 6- Dec 2013
Fig. 1. represents intrinsic evaluation results for Punjabi
documents related to stories at 30% C.R. As can be seen from
the results F-measure, Cosine-similarity, Cofficient of Jaccard
and Euclidean distance have been calculated for fifty Punjabi
stories at different C.R. from 10% to 50%. For story articles of
Punjabi, values of first three intrinsic metrics are increasing
with respect to compression ratios. On the other hand value of
Euclidean distance is decreasing with respect to compression
ratios. At 10% C.R., the values of first three intrinsic metrics
are less as comparison values at 30%, 50% C.R. Moreover
value of Euclidean distance is more at 10% C.R. as at this C.R.
very less number of lines are retrieved and these lines are not
able to denote the complete sense of Punjabi story. Moreover
in case of stories, there is no concept of head lines which is
there in case of news documents.
Extrinsic measures of summary evaluation are task oriented.
Regarding extrinsic metrics, two tasks are performed on system
made summary i.e. task of question answering and association
of key terms at different C.R. from 10% to 50% for Punjabi
documents related to stories. TABLE III shows results of
question answering task.
Accuracy of Question
Answering Task for Punjabi
Stories
(In %)
80.65
84.26
90.72
10%
30%
50%
As can be seen from TABLE III, the accuracy of question
answering task is increasing with increase in compression ratio
for Punjabi stories.
Accuracy of Question Answering task for Punjabi
stories
95
90
Accuracy 85
80
75
Compression
Ratio
(In %)
10%
30%
50%
Accuracy of
Keywords Association Task
for Punjabi Stories
(In %)
84.29
90.68
95.16
Accuracy of Keywords Association task for Punjabi
stories
100
95
90
Accuracy
85
80
75
Punjabi Stories
10%
30%
50%
Compression Ratio
Fig. 3. Results of keywords association task for Punjabi stories
TABLE III
QUESTION ANSWERING TASK RESULTS
Compression
Ratio
TABLE IV
KEY TERMS ASSOCIATION RESULTS
As can be seen from TABLE IV and Fig. 3, accuracy of
keywords association task is increasing with increase in
compression ratios for Punjabi stories. The performance of task
of association of key terms is very good at 50% C.R. as system
made summary is sufficient for covering almost all the key
terms.
VI. CONCLUSIONS
It is first time that, summary evaluation for Punjabi Text
Summarization system has been discussed using intrinsic and
extrinsic measures. For Punjabi stories, performance of this
summarizer is very good at 50% C.R. and its performance is
not good at 10% C.R. because small number of sentences are
extracted as summary sentences and are not sufficient to
represent complete Punjabi story.
REFERENCES
Punjabi Stories
10%
30%
50%
Compression Ratio
Fig. 2. Results of question answering task for Punjabi summarizer
As can be seen from Fig. 2, performance of question
answering is very good at 50% C.R. for Punjabi stories because
sufficient lines are extracted to describe the whole text.
TABLE IV shows results of task of association of Key
terms.
ISSN: 2231-5381
[1] M. Hassel, “Evaluation of Automatic Text Summarization,”
Licentiate Thesis, Stockholm, Sweden, pp. 1-75, 2004.
[2] F. Kyoomarsi, H. Khosravi, E. Eslami and P.K. Dehkordy,
“Optimizing Text Summarization Based on Fuzzy Logic,” In
Proceedings of International Conference on Computer and
Information Science, IEEE, University of Shahid Bahonar
Kerman, UK, pp. 347-352, 2008.
[3] K. Kaikhah, “Automatic Text Summarization with Neural
Networks,” In Proceedings of International Conference on
Intelligent Systems, IEEE, Texas, USA, pp. 40-44, 2004.
[4] A. Fattah and F. Ren, “Automatic Text Summarization,” World
Academy of Science, Engineering and Technology, vol. 27, pp.
192-195, 2008.
http://www.ijettjournal.org
Page 328
International Journal of Engineering Trends and Technology (IJETT) – Volume 6 Number 6- Dec 2013
[5] V. Gupta and G.S. Lehal, “Automatic Punjabi Text Extractive
Summarization System,” International Conf. on Computational
Linguistics COLING, IIT Bombay, India, pp. 191-198, 2012.
[6] V. Gupta and G.S. Lehal, "Automatic Text Summarization
System for Punjabi Language," Int. Journal of Emerging
Technologies in Web Intelligence, vol. 5, pp. 257-271, 2013.
[7] K. Spark-Jones and J. R. Galliers, "Evaluating Natural Language
Processing Systems: An Analysis and Review," Lecture Notes
in Artificial Intelligence, Springer, 1995.
[8] D.R. Radev, H. Jing, and M. Budzikowska, “Centroid-Based
Summarization of Multiple Documents: Sentence Extraction,
Utility-Based Evaluation, and User Studies,” In Proceedings of
the Workshop on Automatic Summarization at the 6th Applied
Natural Language Processing Conference and the 1st
Conference of the North American Chapter of the Association
for Computational Linguistics, Seattle, WA, 2000.
[9] D.R. Radev and D. Tam, “Single-Document and MultiDocument Summary Evaluation via Relative Utility,” In
Proceedings of the CIKM ’03, ACM, New Orleans, LA, 2003.
[10] R.L. Donaway, K. W. Drummey, and L. A. Mather, "A
Comparison of Rankings Produced by Summarization
Evaluation Measures," In Proceedings of the Workshop on
Automatic Summarization at the 6th Applied Natural Language
Processing Conference and the 1st Conference of the North
American Chapter of the Association for Computational
Linguistics, pp. 69–78, 2000.
ISSN: 2231-5381
[11] C.W. Lin, “ROUGE: Package for Automatic Evaluation of
Summaries,” Workshop on Text Summarization Branches Out
WAS , Spain, 2004.
[12] Shannon, “A mathematical theory of communication,” The Bell
System Technical Journal, pp. 623–656, 1948.
[13] I. Mani, D. House, G. Klein, L. Hirshman, L. Orbst, T. Firmin,
M. Chrzanowski, and B. Sundheim, “Text Summarization
Evaluation,” Technical Report TIPSTER SUMMAC, The Mitre
Corporation, McLean, Virginia, 1998.
[14] H. Saggion and G. Lapalme, “Concept Identification and
Presentation in the Context of Technical Text Summarization,”
Proceedings of the Workshop on Automatic Summarization at
the Applied Natural Language Processing Conference and the
Conference of the North American Chapter of the Association
for Computational Linguistics, Seattle, WA, USA, 2000.
[15] H. Nanba and M. Okumura, “Some Examinations of Intrinsic
Methods for Summary Evaluation Based on the Text
Summarization Challenge,” Journal of Natural Language
Processing, vol. 9, pp. 129-146, 2002.
[16] A. Huang, “Similarity Measures for Text Document
Clustering,”, In the Proceedings
of
New
Zealand
Computer Science Research Conference, Christchurch, New
Zealand, pp. 49-56, 2008.
http://www.ijettjournal.org
Page 329