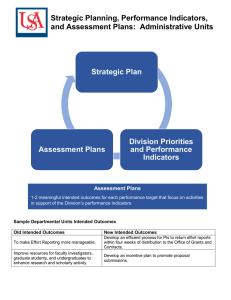
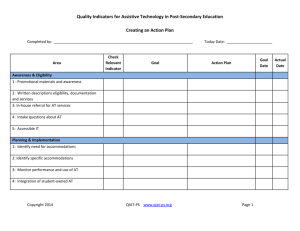
- - 79
advertisement

-79- 4. THE ACCURACY OF QUALITY MEASUREMENT WITH CLAIMS DATA Chapter 3 highlighted that claims data are available to assess multiple dimensions of performance. The purpose of the analysis in this chapter is to identify the characteristics of quality indicators that are associated with more or less accurate quality assessments with claims data. With this knowledge, we can identify situations where claims data can be used as valid and reliable data sources and consequently when the additional costs of using medical records data may be justified. Using medical records as the benchmark for the accuracy of quality measurement with claims data, the analysis in this chapter addresses the following question: • How well do quality assessments with claims data agree with those from medical records and what factors contribute to better or worse agreement? To answer this question, (a) performance rates for a selection of the QA Tools indicators were constructed with claims data and compared to medical records assessments and (b) the factors associated with better or worse agreement between the two data sources were identified. Before presenting the findings of this analysis, the data and approach are described, and a theory of what determines agreement between claims and medical records data is developed. DESCRIPTION OF THE DATA This research was based on data from one health maintenance organization (HMO) located in the Mid-Western United States. The HMO provided claims data and medical records to RAND for a different research project and consented to their use for this dissertation. The data were for the health care services delivered in 1998 and 1999 to 375 adult enrollees. Additional data from publicly available files were used to supplement the analysis. Specifically, Medicare’s Physician Fee -80- Schedule and Clinical Diagnostic Laboratory Fee Schedule were used to approximate reimbursement rates for health care services. HMO Data The data in this study came from one HMO. The HMO is a network model, meaning the HMO contracts with several single- or multispecialty physician groups. Patients may use any doctor within the network. The HMO mainly pays providers through fee-for-service mechanisms. The HMO does not run its own hospital, but contracts with local hospitals for inpatient services. The claims data files included demographic information such as age and gender, the diagnostic and procedure codes associated with claims for ambulatory and inpatient care, and the specific medications that were dispensed to the patients by outpatient pharmacies. The claims data used standardized codes including ICD-9, CPT-4, HCPCS, NDC, and UB92 Revenue codes. The medical records for the 375 patients were abstracted for a different project using RAND’s QA Tools medical record computer-assisted abstraction software. People with the conditions evaluated by the QA Tools system and those with multiple chronic conditions were oversampled. Medical records were requested from all of the providers who submitted claims in 1998 and 1999 to the health plan for encounters with patients in the sample. A patient was included in the study if at least one medical record was received. In the original study for which the data were obtained, the abstracted medical records data were used to determine whether a patient was eligible for each of the indicators and whether the patient received the recommended care; the resulting analytic files were also used for this dissertation. Neither the claims data nor the analytic files from the abstracted medical records included patient identifiers such as name, Social Security Number, or address. Descriptive statistics of the study sample are listed in Table 4.1. -81- Table 4.1 Descriptive Statistics of Study Sample Total number of patients Percent female Percent Medicare Percent of patients for whom PCP* record was received Average age (Std. Deviation; Range) Average number of outpatient visits over 2 years (Std. Deviation; Range) Average number of emergency department visits over 2 years (Std. Deviation; Range) Average number of hospitalizations over 2 years (Std. Deviation; Range) Average number of filled prescriptions over 2 years (Std. Deviation; Range) 375 53 53 62 59 (17.59; 20-96) 16 (11.99; 0-72) 1 (2.01; 0-23) 0.8 (1.82; 0-21) 43 (47.49; 0-284) * PCP = Primary care provider STUDY APPROACH A selection of the QA Tools indicators was used to analyze agreement between quality assessments based on claims versus medical records data. Indicators were selected to represent (a) the types of indicators that can be assessed with claims data, and (b) significant causes of disease burden. In this study, the accuracy of claims data is defined as agreement with medical records about who is eligible for and passes an indicator. Although quality measurement with any data source is susceptible to error (Luck, Peabody et al. 2000), medical records data are often considered the gold standard for quality measurement (Fowles, Fowler et al. 1997; Steinwachs, Stuart et al. 1998). Evaluating the level of agreement between claims and medical records data is the most practical approach for gauging the accuracy of claims data since medical records contain the most reliable information available to measure technical quality. Multiple measures of agreement were analyzed separately for the eligibility and scoring components of the quality indicators. This study is unique because it uses numerous quality of care indicators to assess the determinants of agreement about performance between claims and medical records data. Prior studies that have evaluated agreement between claims and medical records data have focused -82- primarily on whether identical diagnoses or procedures are found in both data sources for one specific encounter (Fisher, Whaley et al. 1992; Romano and Mark 1994; Steinwachs, Stuart et al. 1998; Lawthers, McCarthy et al. 2000). While these studies provide important information about the accuracy of claims data, there is a difference between evaluating whether all diagnoses and procedures documented in the medical record for a given encounter (e.g., hospitalization or office visit) are coded in claims data, and whether the data sources generate comparable assessments of performance. For example, a diagnosis such as diabetes may be noted in the medical record during a hospitalization, but not coded in the claims data. Although there is disagreement about the diagnosis for the encounter, longitudinal claims data could be used to determine that the patient was diabetic and error would not necessarily be introduced into determining the denominator of a performance rate. A few studies have compared the ability of claims data to identify people with chronic conditions, but these studies did not look at whether the patients received indicated care (Quam, Ellis et al. 1993; Fowles, Fowler et al. 1998). There have been studies that have compared the performance rates generated with claims data to the medical record rates (Dresser, Feingold et al. 1997; Fowles, Fowler et al. 1997). However, these studies included at most five quality of care indicators and did not include a multivariate assessment of the determinants of better or worse agreement. The advantages of the current study design include its reliance on more indicators spanning a wider range conditions and care, and the ability to identify the indicator and patient characteristics that affect the accuracy of quality measurement with claims data. The indicators selected for this analysis, how they were constructed with claims data, and the measures of agreement are described below. Selected Indicators Ideally, this analysis would have included each of the 186 QA Tools indicators that were identified in Chapter 3 as being feasible to construct with claims data. However, to keep this analysis to a -83- manageable size, a sub-set of the indicators was constructed. Fifty-two indicators were selected based on the following criteria: (a) the indicators should represent significant causes of morbidity and mortality where there is potential to improve practice, and (b) the indicators should represent the types of indicators deemed feasible to construct with claims data. The full text of the selected indicators is given in Appendix B. The selected indicators were from the following QA Tools condition modules: Asthma, Coronary Artery Disease, Congestive Heart Failure, Diabetes, Pneumonia, and Preventive Care. While indicators for preventive care services do not focus on a specific disease, each of the other selected conditions are among the top l0 causes of mortality and morbidity in the US (Anderson 2002). The selected conditions are frequent targets of performance measurement and quality improvement. For example, HEDIS® assesses the performance of health plans in their delivery of care for asthma, coronary artery disease, diabetes, and preventive care (NCQA 2000). The conditions in Medicare’s Health Care Quality Improvement Program include acute myocardial infarction (coronary artery disease), diabetes, heart failure, and pneumonia (Jencks, Cuerdon, et al. 2000). Because the selected conditions are associated with significant health burden, they represent an appropriate starting point to develop an understanding of how well quality assessments with claims and medical records agree when the goal is quality and health improvement. Although the distribution of the selected indicators across type, function, and mode are not identical to that of the set of 186 indicators that could be constructed with claims data, a variety of the indicators is represented. As depicted in Table 4.2, the selected indicators represent all types (preventive, acute and chronic) and functions (screening, diagnosis, treatment and follow-up) of care. The selected indicators represent five of the 10 modes of care that can be measured with claims data. However, the modes of care not represented by the selected indicators (surgery, admission, education, history, and other interventions) together represent just 10% of all indicators that could be constructed with claims data. -84- Table 4.2 Description of Indicators Used in Agreement Analysis TOTAL CONDITON Asthma Coronary Artery Disease Congestive Heart Failure Diabetes Pneumonia Preventive Care TYPE Preventive Acute Chronic FUNCTION Screening Diagnosis Treatment Follow-up MODALITY Immunization Visit Laboratory test Physical examination Medication Other interventions Surgery Admission Education History Number of Feasible Indicators Number of Selected Indicators 186 52 Proportion of Feasible Indicators Selected 0.28 6 16 6 16 1.00 1.00 11 11 1.00 6 5 8 6 5 8 1.00 1.00 1.00 18 63 105 8 6 38 0.44 0.10 0.36 11 64 75 36 1 23 17 10 0.09 0.36 0.23 0.28 12 10 87 11 6 4 30 2 0.50 0.40 0.34 0.18 48 5 8 3 1 1 10 0 0 0 0 0 0.21 0.00 0.00 0.00 0.00 0.00 Constructing the QA Tools Indicators with Claims Data Whether patients were eligible for and passed each of the QA Tools indicators, according to medical records data, had previously been analyzed at RAND. To develop analogous information for the claims data, I specified the data fields and corresponding values in the claims data -85- required to identify patients who satisfied the eligibility and scoring criteria for each of the 52 indicators. To develop the claims data specifications, I started with the RAND medical records analysis and the standardized specifications used to calculate HEDIS measures with claims data (NCQA 2000). I identified additional codes by referring to the ICD-9-CM 1999 code book, the CPT-4 2000 code book, and CMS files for HCPCS and ICD-926 procedure codes. To determine the appropriate NDC codes for medications, I used Multum’s 1999 Lexicon™ database27 that listed medications by class and active ingredients. Clinicians were consulted to verify that the appropriate diagnostic, procedure, and drug codes were specified. A programmer at RAND translated these specifications into SAS programs that were used to generate analytic files containing the eligibility and scoring status for each patient on the 52 QA Tools indicators. The claims data specifications that were used to write the SAS programs to construct the 52 QA Tools indicators are detailed in Appendix C. An overview of how the specifications were developed is described below. Developing claims data specifications - example. Consider the following indicator from QA Tools: Patients with the diagnosis of Type 1 or Type 2 diabetes should have a measurement of urine protein documented annually. For this indicator, patients satisfy the eligibility criteria if they have a diagnosis of either Type 1 or Type 2 diabetes. Using the HEDIS specifications, patients were inferred to be diabetic if within the two ___________ 26 The HCPCS and ICD-9 procedures codes are available through public use files from CMS: www.hcfa.gov/stats/pufiles.htm. (Accessed January 28, 2002). 27 Multum is a health care information company that has created a comprehensive database on drug products. Multum gathers the information for their database from a variety of sources, including pharmaceutical companies, manufacturer’s package labeling, wholesalers, the Federal Government, industry trade newsletters, and drug catalogues. The Lexicon® database can be downloaded from the Multum web site: http://www.multum.com. (Accessed August 24, 1999.) -86- years of the study a diagnosis of diabetes was coded either (a) on at least two different dates of service in an ambulatory setting or nonacute inpatient setting or (b) on at least one face-to-face encounter in an acute inpatient or emergency room setting. The codes used to infer a diagnosis of diabetes and the setting of the encounter are detailed in Table 4.3. This example illustrates that multiple codes from a variety of coding systems were specified to construct each of the QA Tools indicators included in this analysis. Analogous specifications were written and applied to the claims data for each of the 52 indicators included in this analysis. -87- Table 4.3 Standardized Codes Used to Identify People Meeting Eligibility and Scoring Criteria - Example Code System Codes ICD-9-CM 250.xx28 = diabetes mellitus 357.2x = neuropathy in diabetes 362.0x = diabetic retinopathy 366.41= diabetic cataract Diagnosis of diabetes EXCLUDE: 648.8 = gestational diabetes Ambulatory or non-acute inpatient encounter UB-92 Revenue 49x-53x, 55x-59x, 65x, 66x, Codes 76x, 82x-85x, 88x, 92x, 94x, 96x, 972-979, 982-986, 988, 989 CPT-4 92002-92014, 99201-99205, 99211-99215, 99217-99220, 99241-99245, 99271-99275, 99301-99303, 99311-99333, 99341-99355, 99381-99387, 99391-99397, 99401-99404, 99411, 99412, 99420-99429, 99499 Acute inpatient and emergency room contacts UB-92 Revenue 10x, 11x, 12x, 13x, 14x, 15x, Codes 16x, 20x, 21x, 22x, 45x, 72x, 80x, 981, 987 CPT-4 99221-99223, 99231-99233, 99238-99239, 99251-99255, 99261-99263, 99291-99292, 99281-99288 CPT-4 81000-81003, 82042, 82043, 82044 Urine protein tests ___________ 28 An “x” in either the fourth or fifth digit of the ICD-9 code implies that any value in that position paired with the other specified values satisfies the criterion. -88- Measuring Agreement For both eligibility and scoring, five measures of agreement were analyzed – overall agreement, sensitivity of claims data, sensitivity of medical records data, specificity of claims data, and specificity of medical records data. analysis. The tables in Figure 4.2 are used to explain the The first table represents agreement about eligibility and the second table represents agreement about whether or not the indicated care was delivered. Patient-indicator pairs across all 52 indicators are the unit of analysis. The sum of the cells in the eligibility table (Ne), therefore represents all patient-indicator combinations that were used in the analysis of agreement about eligibility. Cell ae represents the number of patient-indicator combinations for which both data sources agreed that the patient was eligible; de is the number of observations where both data sources agreed the patient was ineligible. Disagreement is represented by the off-diagonal cells be and ce. Whether an indicator was passed was considered only if eligibility had been established. Specifically, if claims or medical records data determined that the eligibility criteria were not satisfied, then whether the indicated care was delivered according to that data source was not evaluated. The scoring analyses were therefore limited to those observations where the medical records and claims data agreed about eligibility (i.e., cell ae=Ns). -89- Figure 4.1 Schematic Overview of Analysis of Agreement between Medical Record and Claims Data STEP 1: Is Patient Eligible For Indicator? Medical Records Yes No Claims Data ae be ce de be, ce, and de not used in Step 2 Yes No Ne STEP 2: Does Patient Pass the Indicator? Medical Records Yes No Claims Data Yes as bs No cs ds Ns The five measures of agreement used in this analysis and how they can be calculated from the tables in Figure 4.1 are described presently. Overall agreement. Overall agreement is a statistical summary of concordance that ignores distinctions between positive and negative agreement (i.e., does not separately evaluate how closely the data sources agree about who is a “yes” and who is a “no”). With reference to the tables in Figure 4.2, the overall agreement rate is: (1) Overall Agreement = (a + d)/N -90- The kappa statistic (κ) is another measure of overall agreement that is frequently used in the Health Services literature to summarize agreement between data sources (Horner, Paris et al. 1991; Hannan, Kilburn et al. 1992; Jollis, Ancukiewicz et al. 1993; Romano and Mark 1994; Fowles, Fowler et al. 1997; Kashner 1998). The kappa statistic is appealing because it is a single index of agreement that considers chance. However, interpretation of κ is not straightforward because the statistic is affected by prevalence (Cicchetti and Feinstein 1990; Feinstein and Cicchetti 1990; Berry 1992). For example, high levels of agreement between claims and medical records data may emerge with low values of κ if the prevalence of the event of interest is low. this reason, the main text of this analysis does not report κ. For However, to allow for comparability with other studies that measure agreement between claims and medical records data that do not report the measures of agreement emphasized here (i.e., overall agreement, sensitivity, and specificity), κ values are reported in Appendix D. Since measures of overall agreement do not distinguish whether the disagreement stems from claims data underestimating (i.e., from poor positive agreement) or overestimating (i.e., from poor negative agreement) the number of patients who satisfy the eligibility and scoring criteria, measures of sensitivity and specificity were also used in this analysis. Sensitivity. In epidemiology, sensitivity is a measure of the validity of a screening test and is defined as the probability of testing positive if the disease is truly present. In this analysis, sensitivity evaluates how well one data source agrees with the other about whether an indicator’s criteria for eligibility and scoring have been satisfied. Since neither the medical records (MR) nor the claims data (CD) always reveal truth, the sensitivity of each data source, relative to the other, was estimated: (2) SensitivityAD = a/(a+c) = Prob(CD=yes | MR=yes) (3) SensitivityMR = a/(a+b) = Prob(MR=yes | CD=yes) -91- If the medical records data indicate “yes” (cells a and c), the sensitivity of claims data reports the probability that claims data will agree (cell a). Similarly, if claims data are taken as the standard, the sensitivity of medical records data indicates how likely it is that the medical records will say “yes” (cell a), given the claims data says “yes” (cells a and b). High rates of sensitivity indicate that a data source is not substantially underestimating the number of patients who satisfy the eligibility or scoring criteria relative to the other data source. Specificity. Specificity measures how closely each data source agrees with the other on negative assessments. Identifying people as either ineligible for an indicator or as failing an indicator are the negative assessments in this analysis. As with sensitivity, specificity was estimated for both claims data and medical record data: (4) SpecificityAD = d/(b+d) = Prob(CD=no | MR=no) (5) SpecificityMR = d/(c+d) = Prob(MR=no | CD=no) Using medical records data as the gold standard, as the specificity of claims data increases, the likelihood that the claims data will overestimate the number of patients who satisfy the eligible or passing criteria decreases. Description of Agreement about Eligibility and Scoring The tables in Figure 4.2 summarize agreement between the claims and medical records data about eligibility and scoring for the 52 indicators. There were 13,875 observations in the analysis about eligibility because there were 37 unique eligibility statements29 and 375 patients (375 * 37 = 13,875). Agreement about scoring was analyzed ___________ 29 Although 52 QA Tools indicators were included in the analysis, some of them had identical eligibility statements; only unique eligibility statements were included in the analysis. For example, five indicators specify different types of care that a diabetic should receive. Although five separate scoring statements were used, the eligibility statement for diabetes was included once for each patient in the agreement analysis about eligibility because the specifications for a diagnosis of diabetes were identical across the five indicators. -92- for the 1451 unique patient-indicator dyads where both data sources agreed the eligibility criteria were satisfied. -93- Figure 4.2 Data for Agreement Analyses about Eligibility and Scoring Step 1- Eligibility Medical Records Eligible Ineligible Claims Eligible 985* 301 Data Ineligible 232 12,357 13,875 Step 2 – Scoring Medical Records Pass Fail Claims Pass 261 251 Data Fail 152 787 1451^ * A patient-indicator dyad is the unit of observation. ^ The total number of observations in the scoring table is larger than the number of observations where both data sources agreed on eligibility, because the eligibility analysis was limited to unique eligibility statements. Based on the information in Figure 4.2, the five measures of agreement were calculated for eligibility and scoring (Table 4.4). These univariate characterizations of agreement highlight two key findings: Result 1: Across all measures, agreement was better for eligibility than for scoring. Result 2: For both eligibility and scoring the specificity of both data sources was considerably higher than the sensitivity. -94- This suggests that claims and medical records data are more likely to agree about who is ineligible for quality of care indicators than about who is eligible. Similarly, the data sources have better agreement about who fails an indicator than about who received the recommended care. Table 4.4 Claims and Medical Records Data Agreement about Eligibility and Scoring Eligibility Rate (std dev) N* Overall agreement SensitivityAD SensitivityMR SpecificityAD SpecificityMR 0.96 (0.19) 0.81 (0.39) 0.77 (0.42) 0.98 (0.15) 0.98 (0.13) 13,875 1217 1286 12,658 12,589 Scoring Rate (std dev) N* 0.72 (0.45) 0.61 (0.48) 0.51 (0.50) 0.76 (0.43) 0.84 (0.37) 1451 413 512 1038 939 * A patient-indicator dyad is the unit of observation. Agreement about eligibility. The rates of overall agreement, specificity of medical records data, and specificity of claims data about eligibility were all quite high (>0.95). The sensitivity of claims data was 0.81, meaning that when the medical record identified a patient as being eligible for an indicator, the claims data agreed 81% of the time. The sensitivity of the medical records data (0.77) was lower than the sensitivity of the claims data. Agreement about scoring. The level of agreement between claims and medical records data across each measure was lower for scoring than for eligibility. The overall rate of agreement about who passed an indicator (0.72) as well as the specificity of claims data (0.76) and medical records data (0.84) were higher than the sensitivity of claims data (0.61) and medical records data (0.51). -95- THEORY OF AGREEMENT Performance rates for one or more indicators are typically used to assess the technical quality of care. The accuracy of a performance rate is sensitive to measurement errors in the numerator and denominator. As demonstrated in Table 4.9 by the varying levels of agreement between claims and medical records data about eligibility (i.e., denominator of performance rate) and scoring (i.e., numerator of performance rate), measurement with claims data is sensitive to both sources of error. This suggests we can better predict when and how quality assessments with claims data will differ from medical records assessments by understanding separately the effects of errors in identifying the people who satisfy the eligibility and scoring criteria of an indicator. After describing how performance rates are influenced by these errors, factors affecting agreement between claims and medical records data about quality assessments are discussed, and some hypotheses about agreement are developed. The Effects of Errors on Quality Measurement Errors in identifying people who satisfy the eligibility criteria. When eligibility is either underestimated or overestimated, the error on the overall performance rate is generally expected to be in the opposite direction. Consider the quality indicator that assesses the HbA1c screening rate for diabetics. If claims data identified people as diabetic who did not have diabetes according to their medical records (i.e., overestimated eligibility), then the performance rate would be equivalent to the medical records rate only if all people judged eligible, whether they have diabetes or not, have HbA1c measurements at the same rate. However, since non-diabetics are less likely to have their HbA1c measured, it is expected that overstating the number of people who satisfy the eligibility criteria when claims data is used will result in underestimating performance. Similarly, if claims data fail to identify some diabetics (i.e., underestimate eligibility), the performance rate will be equal to the medical records rate if those diabetics who were identified and those who were missed receive the test at the same rate. However, if those diabetics who were missed with -96- claims data receive care at a different rate than those who were identified as being eligible, then the performance rate will differ. For example, if claims data tend to misclassify diabetics with few visits, and those people are also less likely to receive care for their diabetes, then the performance rate for annual HbA1c measurements would be overestimated by claims data. In sum, overestimating eligibility usually will generate a lower performance rate relative to medical records while underestimating eligibility may increase, perhaps to a relatively minor degree, the performance rate constructed with medical records data. Errors in identifying people who satisfy the scoring criteria. Assuming eligibility is correctly determined, if the number of people who satisfy the scoring criteria is underestimated then the performance rate will be underestimated. Similarly, if the number of people who satisfy the scoring criteria is overestimated then the performance rate will be overestimated. Factors Affecting Agreement Between Claims and Medical Records Data Chapter 2 discussed potential sources of error in claims data. That review suggests that claims data are more likely to be accurate, and thus agree with medical records data, when (a) the indicator criteria correspond more closely to the standardized coding systems and (b) claims for the measurement criteria are more likely to be submitted for payment. Although medical records are the standard against which the accuracy of quality assessments with claims data is being gauged, there are some pieces of information that are better documented than others in medical records. This variability in capturing information from the medical records is also likely to influence agreement between the two data sources. Factors affecting the accuracy of claims and medical records data are used to guide the analysis of the characteristics of quality indicators that influence agreement between claims and medical records data. Factors affecting agreement: Correspondence between standardized codes or documentation practices and indicator criteria. -97- Agreement between claims and medical records data is expected to be more common when the eligibility and scoring criteria within an indicator correspond closely to the standardized codes. Three factors that are likely to indicate how well the codes and indicator criteria correspond are (1) the complexity of the indicator specifications, (2) the types of information required to construct the indicator, and (3) the time-frame for the indicated care. These factors are also associated with the likelihood that the information will be in the medical record. Complexity. When eligibility and scoring criteria do not correspond directly to the standardized codes in claims data they can be approximated with an algorithm. As the discrepancy between the indicator criteria and the available codes increases, the algorithm to construct the indicator becomes more complex. Additional opportunities for error are introduced as the complexity of indicator specifications increase. Medical records are also sensitive to the complexity of indicator specifications. As more data elements are required to construct an indicator, the likelihood of information either not being documented in the medical record or being overlooked during the abstraction process increases. I expect that as indicator specifications become more complex, the level of agreement between claims and medical records data will decrease. I measure the complexity of the specifications for eligibility and scoring separately. I measure complexity in terms of (a) the number of data elements specified to construct the eligibility or scoring statement with claims data, and (b) whether the specifications are more compound or parallel in nature. Compound specifications require specific values that must be determined for multiple data elements; parallel indicators, in contrast, refer to multiple data elements, but only a sub-set of them is required to determine either eligibility or scoring. A count of the number of “ands” in the claims data specification is used to measure the level of compound requirements, and the number of “ors” is used to measure the level of parallel requirements. Consider the following indicator: -98- Patients with the diagnosis of diabetes should have a measurement of urine protein documented annually. Having two outpatient visits for diabetes, or one emergency department visit or hospitalization for diabetes was used to specify a diagnosis of diabetes.30 Therefore the complexity of the eligibility criteria for the indicator was characterized by: • Number of data elements = 4 • Count of “ands” = 1 • Count of “ors” = 2 Since the data were for a two-year period, two separate measurements of urine protein were required to satisfy the scoring criteria for this indicator.31 The complexity of the scoring criteria was characterized by: • Number of data elements = 2 • Count of “ands” = 1 • Count of “ors” = 0 Type of information. The standardized codes found in claims data correspond to some types of information better than others. As highlighted in Chapter 2, the coding of diagnoses, for example, is particularly fallible. Specifically, the ICD-9-CM codes generally do not communicate information on the severity of a condition, or whether the diagnosis is new or pre-existing. Although medical records may not explicitly state the severity level of a condition or whether a diagnosis is new, they are much richer in clinical information. This additional information can be used to discern details that cannot be captured with claims data. For example, a medical record is not likely to specifically document “patient has moderate asthma.” But, the medical record may document a patient’s symptom status and this is a good indication of severity. ___________ 30 The eligibility specifications are: [(1) outpatient visit for diabetes AND (2) outpatient visit for diabetes] OR (3) emergency room encounter for diabetes OR (4) hospitalization for diabetes. 31 The scoring specifications are: (1) urine protein measurement AND (2) urine protein measurement. -99- Detailed information about diagnoses is often required to define the eligible population for an indicator. Therefore, I expect that agreement between claims and medical records data about eligibility will be better for indicators that do not rely on diagnostic information. In addition, among those indicators that do use diagnostic information to identify the eligible population, agreement will be better if prevalent diagnoses are of interest rather than new diagnoses because prevalent diagnoses are more common and there is nothing within claims data to code specifically for a new diagnosis. Timing of indicated care. For this analysis, the claims and medical records data were limited to a two-year period (1998-1999). The time-frame for the recommended care in most of the indicators was less than two years. However, there were five indicators where the care required to pass could have occurred prior to the two-year period (e.g., cholesterol screening in the past 5 years, pneumococcal test at any time). While it was sometimes possible to determine services delivered prior to 1998 with historical notes or documentation of prior services (e.g., immunization records) in the medical records, the claims data exclusively contained information about the services provided during 1998 and 1999. Therefore, it is expected that agreement between claims and medical records data will be poorer if the indicated care could have been delivered prior to 1998. Although the two-year span of data is an artifact of the study design, it is not unlike what is often available in claims data. The length of time for which claims data are available for a patient is limited to his or her enrollment with a single health plan, which is not particularly long for many individuals. Nearly one in five patients, for example, switch health plans annually (Cunningham and Kohn 2000). Factors affecting agreement: Probability of a claim or documentation in a medical record If claims are not submitted for a service or do not include codes for all of a patient’s diagnoses, then the accuracy of quality measurement with claims data is compromised. The submission of claims for payment depends on both patient and provider behavior. First, the -100 - patient must seek care from a provider whose services are covered by the health plan. Then, the provider or patient must submit a claim for payment to the insurance company that codes the diagnoses and procedures of interest. These patient and provider behaviors are likely to be affected by (1) the kind of care that is being sought by the patient or delivered by the provider, (2) the payment structure and reimbursement rate for care. Each of these factors can be used to characterize quality of care indicators. The kind of care. Whether a patient seeks care from a provider who can be reimbursed by his or her health plan is likely to vary by the type of condition and health care service. For example, patients may be able to obtain preventive health care services such as flu shots or cholesterol screening tests at no or low cost from their employers or community health fairs. When patients do obtain care through these alternative providers there will not be a claim for the care in the health plan’s claims data. Similarly, this information would be in the medical record only if the patient reported it to his or her physician and the physician documented that the patient received the services elsewhere. In contrast to preventive services, if a patient had an acute condition such as an asthma exacerbation and sought treatment from an emergency department at a hospital, there would be a claim because emergent care is typically covered by insurance and the encounter would generate documentation in a medical record. The coding practices of providers may also vary by the type of care. A provider may code acute conditions that require immediate attention, for example, but fail to code chronic conditions that are not being addressed during the visit (Iezzoni, Foley et al. 1992; Romano and Mark 1994). Even if a condition is not addressed during the visit, the capacity to use medical records to determine the presence of a chronic condition is good because the record is likely to include a problem list for the patient. The presence of claims is also likely to vary by the mode of care (i.e., the type of service being delivered). Claims for prescriptions and laboratory services are usually billed by non-physician providers -101 - who are not reimbursed for patient encounters, while immunizations and other interventions are often provided in a physician’s office and the physician is reimbursed for the patient encounter. Since the physician is reimbursed for the encounter, any additional services provided may not be coded. However, services delivered or ordered by physicians are likely to be noted in the medical record. Payment structure and reimbursement. In addition to type and mode of care, other factors that may influence providers’ coding and claims submission practices are payment structures and reimbursement rates associated with a service. For example, the diagnoses for which a patient is hospitalized are likely to be coded, but the specific services such as laboratory tests and administered medications delivered during a hospitalization are not. This is because the health plan in this study pays for hospitalizations using a prospective payment system, meaning that the diagnosis helps identify the appropriate diagnostic related group (DRG) on which the payment should be based, but ancillary services such as laboratory tests or medications do not affect the rate of reimbursement. Since diagnoses are generally a component of eligibility, but not scoring, this suggests that agreement about eligibility will be better for indicators specific to hospitalizations, but agreement about scoring will be poorer. Incentives to code services that are reimbursed on a fee-forservice basis increases as their reimbursement rates increase. Similarly, a patient has a greater incentive to submit claims for reimbursement when the cost of the service exceeds their co-payment. This suggests that agreement about whether indicated services were delivered will be better for indicators specific to higher cost services. Factors affecting agreement: Patient characteristics Thus far, the discussion of factors likely to affect the level of agreement has been limited to indicator characteristics. characteristics might also affect agreement. Patient level An indication of whether a patient’s primary care provider record was received and measures of utilization are included in the models for agreement. -102 - Medical records are used as the standard against which the claims data are being assessed for accuracy. The medical records data are not always complete because all of the medical records for patients in this study were not always obtained. As a consequence, it is possible that the claims data are more complete. To control for the amount of information that was available from the medical records I determined whether a medical record from a primary care provider was abstracted for each patient. Medical records from primary care providers are especially useful because even if a patient had visits with many providers and those medical records were not available, consultation letters are typically sent to the primary care provider and incorporated into their medical record. As the number of encounters increases, there are more opportunities for diagnoses to be coded and documented in the medical records, which could promote better agreement. Agreement between claims data and medical records data about encounter dates and diagnoses has been found to be better among patients with high utilization relative to those with low utilization (Steinwachs, Stuart et al. 1998). Therefore, when analyzing the determinants of agreement, I include measures of patients’ utilization patterns. Summary of Hypotheses In sum, rates of agreement between claims and medical records data about quality assessments are likely to be higher when the indicator criteria correspond more closely with the standardized coding systems and typical medical records documentation, and when a claim is more likely to be submitted for payment. As discussed above, these considerations suggest the following hypotheses: 1. As the specifications used to construct quality of care indicators increase in complexity, the probability of agreement between claims and medical records data will decrease. 2. The probability of agreement between claims and medical records data about eligibility will be higher for indicators that do not rely on diagnostic information. -103 - 3. The probability of agreement between claims and medical records data about scoring will be lower if the indicated care could have been delivered prior to the study period. 4. The probability of agreement about eligibility will be higher for indicators specific to hospitalizations. 5. The probability of agreement about scoring will be lower for indicators specific to hospitalizations. 6. The probability of agreement about scoring will be higher when the reimbursement rate for the service is higher. 7. The probability of agreement will be higher among patients who had a primary care record abstracted. 8. The probability of agreement will be higher among patients with greater utilization of health care services. AGREEMENT ANALYSIS Building on the factors described above, 10 logistic regression equations with similar sets of covariates were used to analyze agreement between claims and medical records data about eligibility and scoring for the 52 QA Tools indicators. Two equations - one for eligibility, the other for scoring – were used to analyze each of the following: (1) overall agreement, (2) sensitivity of claims data, (3) sensitivity of medical records data, (4) specificity of claims data, and (5) specificity of medical records data. The variables used in the logistic equations, their distribution across the 10 models, and their bivariate associations with agreement are described; then the results of the multivariate analysis are presented. Following the analysis of agreement about eligibility and scoring, the performance rates calculated with claims and medical records data are compared for indicators with at least 10 eligible patients. Independent Variables Table 4.5 lists the variables used in the analysis of agreement about eligibility and scoring. The table also specifies how each -104 - covariate is related to the theory of agreement and whether it is included in the eligibility or scoring models. -105- Table 4.5 Independent Variables for Agreement Equations Included in Model? Variable Name Definition Code Correspondence ELMT_CNT Count of data elements in claims data specifications to construct eligibility or scoring statement. Link to Agreement Theory Eligibility Scoring Complexity No Yes AND_CNT Count of the number of “ands” in the claims data specifications. This variable measures the degree to which the specification for the eligibility statement has compound requirements. Complexity Yes No32 OR_CNT Count of the number of “ors” in the claims data specifications. This variable measures the degree to which the specification for the eligibility statement has parallel requirements. Complexity Yes No NOAND 1 if there are no compound statements (i.e., no “ands”) in the claims data specifications; 0=otherwise. 1 if there are no diagnoses in the claims data specification for eligibility; 0=otherwise. Complexity Yes No Type of information Yes No DX_NEW 1 if a new diagnosis is a component of the claims data specification for eligibility; 0=otherwise. Type of information Yes No DX_PREV 1 if a prevalent diagnosis is a component of the claims data specification for eligibility; 0=otherwise. Type of information Yes No TW_GT2 1 if care indicated by the quality of care measure could occur prior to the 2 years for which claims data are Time-frame No Yes DX_NO ___________ 32 Because the scoring specifications had fewer data elements than the scoring specifications, complexity was represented with only the count of data elements (ELMT_CNT) rather than measures of compound (AND_CNT) and parallel (OR_CNT) construction. While the average number of data elements in the scoring statements was 1.33 with a maximum of four data elements, the average number of data elements in the eligibility statements was 4.27 with a maximum of 16 data elements (see Tables 4.6 and 4.7). -106 - Included in Model? Variable Name Definition available; 0=otherwise. Probability of Claim Being Submitted TYPE_ACUTE 1 if indicator assesses acute care; 0=otherwise. Link to Agreement Theory Eligibility Scoring Type of care Yes Yes TYPE_CHRONIC 1 if indicator assesses chronic care; 0=otherwise. Type of care Yes Yes TYPE_PREV 1 if indicator assesses preventive care; 0=otherwise. Type of care Yes Yes MODE_LAB 1 if indicator assesses whether a laboratory test was performed; 0=otherwise. Mode of care No Yes MODE_IMM 1 if indicator assesses whether an immunization was administered; 0=otherwise. Mode of care No Yes MODE_MED 1 if indicator assesses whether a medication was prescribed; 0=otherwise. Mode of care No Yes MODE_VIS 1 if indicator assesses whether an encounter with a provider occurred; 0=otherwise. Mode of care No Yes MODE_PE 1 if indicator assesses whether a component of a physical examination was performed; 0=otherwise. Mode of care No Yes INPT 1 if measure is specific to inpatient care only; 0=otherwise. Payment structure Yes Yes FEE_VAL Reimbursement rate for the health care procedure specified in the scoring statement.33 Payment structure No Yes ___________ 33 Due to the multitude of contracts and the proprietary nature of provider contracts, HMO-specific reimbursement data were not available. Therefore, rates from the Medicare Physician Fee Schedule and the Clinical Diagnostic Laboratory Fee Schedule were used to approximate them. Medicare carriers pay claims for physician services and clinical laboratory claims with these fee schedules. Given Medicare’s large presence in the health care market, commercial health plans frequently use the Medicare fee schedule rates as benchmarks for generating their own scale. Although health plans’ rates differ from the Medicare rates, the relative levels are similar (Ginsburg 1999). The fee schedules are public use files available from the CMS website: -107- Included in Model? Variable Name Definition Link to Agreement Theory Eligibility Scoring Patient Characteristics GOT_PCP 1 if a primary care medical record for the patient was obtained for the medical record data abstraction; 0=otherwise. Completeness of medical records data Yes Yes OFFICE_VIS Count of the number of office visits patient had during study period. Utilization Yes Yes ANY_HOSP 1 if patient was hospitalized during study period; 0=otherwise Utilization Yes Yes Dependent Variables Five measures of agreement were analyzed as the dependent variables – overall agreement, sensitivity of claims data, sensitivity of medical records data, specificity of claims data, and specificity of medical records data. To analyze the sensitivity of a data source, the sample was restricted to patient-indicator dyads for which the reference data source confirmed either eligibility or passing an indicator; then, the dependent variable (y) equaled one if the other data source also confirmed eligibility or passing; otherwise the dependent variable equaled zero. For example, there were 1217 patient-indicator dyads where the eligibility criteria had been satisfied according to the medical records data. To analyze the sensitivity of claims data to determine eligibility, the sample was restricted to these 1217 observations. If the claims data agreed that the eligibility criteria were satisfied, then y=1; otherwise y=0. The dependent variables in the specificity models had analogous definitions. Specifically, the sample was restricted to patient-indicator dyads for which the reference data source determined that the eligibility or scoring criteria were not satisfied; then, the dependent variable equaled one if the other data www.hcfa.gov/stats/pufiles.htm (accessed January 28, 2002). The fee schedules include state-specific payment amounts and are updated annually. I used the 1999 fee schedules for the state where the HMO in this study is based and the patients reside. -108- source agreed that the eligibility or scoring criteria had not been satisfied; otherwise the dependent variable equaled zero. Distribution of Variables The distributions of the variables for each of the agreement equations are listed in Tables 4.6 and 4.7 for eligibility and scoring respectively. The distributions of some of the covariates differed across the five measures of agreement. These distributions are described presently — first for the eligibility models, then for the scoring models. Eligibility Models. Table 4.6 depicts the distribution of the dependent and independent variables across each of the eligibility models. Among the 13,875 patient-indicator dyads included in the analysis, the claims data specifications included four data elements on average. The specifications were more compound in nature than parallel (i.e., the average value of AND_CNT was 2.11 and the average of OR_CNT was 1.14). Fourteen percent of the eligibility statements did not refer to a diagnosis (DX_NO), while 54% of the eligibility statements included criteria for a prevalent diagnosis (DX_PREV) and 32% of the eligibility statements specified a new diagnosis (DX_NEW). Fourteen percent of the indicators in this analysis assessed acute care (TYPE_ACUTE), 68% assessed care for chronic conditions (TYPE_CHRONIC), and the remaining 19% of the indicators were for the quality of preventive services (TYPE_PREV). Among the 375 patients included in the study, a primary care record (GOT_PCP) was received for 62% of the sample. The characteristics of the observations in the sensitivity models (Models 2 and 3) were different from the observations included the overall agreement and specificity models. For example, about 60% of the observations in the sensitivity models for eligibility did not include a diagnosis compared to 15% in the overall agreement model. The distributions in Table 4.6 suggest that patients were more likely to be eligible for indicators without diagnostic criteria that measure performance on preventive care services. -109 - Table 4.6 Distribution of Covariates Across the Eligibility Models (Means with standard deviations in parentheses) Model 1 Overall Agreement 13,875 0.96 (0.19) N Dependent Independent Code Correspondence ELMT_CNT Model 2 SensitivityCD Model 3 SensitivityMR Model 4 SpecificityCD Model 5 SpecificityMR 1217 0.81 (0.39) 1286 0.77 (0.42) 12,658 0.97 (0.15) 12,589 0.98 (0.13) 2.57 (2.38) 0.81 (1.18) 0.75 (1.55) 0.50 (0.50) 0.59 (0.49) 0.26 (0.44) 0.15 (0.36) 4.44 (3.75) 2.24 (2.74) 1.18 (1.67) 0.24 (0.43) 0.09 (0.28) 0.57 (0.50) 0.34 (0.48) 4.44 (3.75) 2.24 (2.74) 1.18 (1.67) 0.25 (0.43) 0.09 (0.28) 0.57 (0.50) 0.34 (0.47) 0.06 (0.23) 0.28 (0.45) 0.67 (0.47) 0.19 (0.39) 0.14 (0.35) 0.71 (0.45) 0.14 (0.35) 0.33 (0.47) 0.14 (0.35) 0.72 (0.45) 0.14 (0.35) 0.34 (0.47) 0.60 (0.49) 20.00 (13.87) 0.52 (0.50) 0.62 (0.49) 15.34 (11.73) 0.36 (0.48) 0.62 (0.48) 15.24 (11.68) 0.36 (0.48) 4.27 2.41 (3.69) (2.29) AND_CNT 2.11 0.75 (2.27) (1.19) OR_CNT 1.14 0.66 (1.66) (1.46) NOAND 0.27 0.53 (0.44) (0.50) DX_NO 0.14 0.62 (0.34) (0.49) DX_PREV 0.54 0.25 (0.50) (0.43) DX_NEW 0.32 0.13 (0.47) (0.33) Probability of Claim Being Submitted TYPE_ACUTE 0.14 0.05 (0.34) (0.22) TYPE_CHRONIC 0.68 0.27 (0.47) (0.44) TYPE_PREV 0.19 0.68 (0.39) (0.47) INPT 0.32 0.23 (0.47) (0.42) Patient Characteristics GOT_PCP 0.62 0.63 (0.49) (0.48) OFFICE 15.68 19.22 (11.98) (13.85) ANYHOSP 0.38 0.54 (0.48) (0.50) Scoring. The distributions of the dependent and independent variables across each of the models about scoring are listed in Table 4.7. Relative to the eligibility models, there are fewer observations in the scoring models because they are limited to those patient- - 110- indicator dyads where the claims and medical records data agreed that the eligibility criteria had been satisfied. There is variation in the distributions of the variables included in both the eligibility and scoring equations. For example, the average number of data elements (ELMT_CNT) in the overall agreement model for eligibility is 4.27 and 1.33 for the corresponding scoring equation. Preventive care indicators dominate the scoring equations (67% of the observations in the overall agreement equation about scoring are for preventive care indicators), while chronic care indicators dominate the eligibility models. The distributions of covariates also vary among the different models of agreement about scoring. One-half of the observations in the overall agreement model, for example, are for indicated care that could have preceded the two years for which data are available (TW_GT2) compared to one-third of the observations in either of the sensitivity models. -111 - Table 4.7 Distribution of Covariates Across the Scoring Models (Means with standard deviations noted parenthetically) N Dependent Model 1 Overall Agreement 1451 0.72 (0.45) Model 2 SensitivityAD Model 3 SensitivityMR Model 4 SpecificityAD Model 5 SpecificityMR 413 0.63 (0.48) 512 0.51 (0.50) 1038 0.76 (0.43) 939 0.84 (0.37) 1.59 (1.00) 0.31 (0.46) 1.31 (0.71) 0.62 (0.49) 1.20 (0.51) 0.64 (0.48) 0.03 (0.17) 0.39 (0.49) 0.57 (0.49) 0.40 (0.49) 0.39 (0.49) 0.02 (0.14) 0.05 (0.21) 0.14 (0.34) 0.02 (0.14) 19.79 (91.68) 0.02 (0.13) 0.24 (0.42) 0.75 (0.44) 0.58 (0.49) 0.32 (0.47) 0.03 (0.16) 0.03 (0.18) 0.03 (0.18) 0.01 (0.12) 11.06 (24.43) 0.01 (0.12) 0.26 (0.44) 0.73 (0.45) 0.61 (0.49) 0.29 (0.46) 0.06 (0.23) 0.04 (0.19) 0.00 (0.00) 0.04 (0.20) 12.13 (35.20) 0.63 (0.48) 22.59 (13.89) 0.52 (0.50) 0.53 (0.50) 19.31 (13.30) 0.51 (0.50) 0.59 (0.49) 19.40 (14.08) 0.54 (0.50) Independent Code Correspondence ELMT_CNT 1.33 1.39 (0.75) (0.84) TW_GT2 0.52 0.28 (0.50) (0.45) Probability of Claim Being Submitted TYPE_ACUTE 0.02 0.03 (0.14) (0.17) TYPE_CHRONIC 0.31 0.49 (0.46) (0.50) TYPE_PREV 0.67 0.48 (0.47) (0.50) MODE_IMM 0.54 0.43 (0.50) (0.50) MODE_LAB 0.33 0.35 (0.47) (0.48) MODE_MED 0.04 0.08 (0.20) (0.29) MODE_PE 0.04 0.06 (0.20) (0.23) MODE_VIS 0.05 0.09 (0.21) (0.28) INPT 0.03 0.08 (0.18) (0.27) FEE_VAL 14.84 24.32 (61.46) (108.01) Patient Characteristics GOT_PCP 0.60 0.80 (0.49) (0.40) OFFICE 20.53 23.57 (14.09) (15.51) ANYHOSP 0.53 0.59 (0.50) (0.49) Bivariate Analysis of Agreement The discussion of results begins with bivariate statistics that do not control for other factors. The overall rate of agreement and the sensitivity and specificity of each data source for all categorical - 112- covariates are listed in Table 4.8 for eligibility and Table 4.9 for scoring. Chi-square tests were used to test the null hypothesis that the level of agreement was equal across all potential values of each categorical variable. When not controlling for other factors, each explanatory variable is associated with statistically different levels of agreement for at least two of the five measures of agreement. Eligibility Models – Bivariate Analysis Coding correspondence with quality indicators. The overall level of agreement about eligibility was statistically different depending on whether the claims data specifications included a new, prevalent or no diagnosis. Although statistically significant, the differences in overall agreement and specificity for eligibility statements with and without diagnoses were small for both data sources. The sensitivity of both data sources was highest among eligibility statements that did not specify a diagnosis (0.98 for claims data, 0.97 for medical records data) and lowest when a new diagnosis was a component of the eligibility criteria (0.35 for claims data, 0.25 for medical records data). Probability of claim being submitted. Quality of care indicators specific to inpatient care had a higher rate of overall agreement (98%) about whether the eligibility criteria were met relative to indicators assessing care in any setting (95%). The sensitivity of medical records data and the specificity of claims data were also better for indicators specific to inpatient care. However, the sensitivity of claims data was better when the care was not specific to the inpatient setting (0.82 versus 0.77). Statistically significant different rates of overall agreement, specificity of claims data, and specificity of medical records data were found between indicators assessing acute, chronic, or preventive care. However, the variation was small and did not exceed more than two percentage points. In contrast, the sensitivity of each data source to determine eligibility did differ substantially, and followed a clear pattern – sensitivity was highest among indicators assessing preventive care and the lowest for the acute care indicators. -113 - Patient characteristics. The sensitivity of medical records data and specificity of claims data was higher among observations where a primary care record had be received. Agreement about eligibility was also better across all measures among patients without any hospitalizations during the two-year study period. Table 4.8 Levels of Agreement about Eligibility – Bivariate Comparisons Overall Agreement SensitivityAD SensitivityMR SpecificityAD SpecificityMR 0.97 0.95 0.98 47.79*** 0.62 0.35 0.98 427.77*** 0.58 0.28 0.97 497.86*** 0.98 0.97 0.98 19.28*** 0.98 0.98 0.99 9.50*** 0.95 0.97 0.96 11.02** 0.34 0.54 0.95 359.62*** 0.30 0.50 0.92 334.02*** 0.97 0.98 0.96 30.21*** 0.98 0.98 0.98 5.30* 0.98 0.95 68.74*** 0.77 0.82 2.89* 0.91 0.73 35.71*** 1.00 0.97 96.23*** 0.99 0.98 4.12** 0.96 0.96 2.45 0.80 0.83 2.00 0.79 0.73 7.77*** 0.98 0.97 11.20*** 0.98 0.98 1.98 0.93 0.74 0.72 0.96 0.96 0.98 206.53*** 0.89 43.30*** 0.82 15.91*** 0.99 93.42*** 0.99 141.73*** 13,875 1217 1286 12,658 12,589 CODE CORRESPONDENCE Diagnosis type Prevalent diagnosis New diagnosis No diagnosis Pearson χ2 (2) PROBABILITY OF CLAIM BEING SUBMITTED Care type Acute Chronic Preventive Pearson χ2 (2) Setting Inpatient only Ambulatory or Inpatient Pearson χ2 (1) PATIENT CHARACTERISTICS Medical Record Availability Received PCP record No PCP record received Pearson χ2 (1) Utilization One or more hospitalizations No hospitalizations Pearson χ2 (1) TOTAL N * p<0.10, Wald Chi-Square test for significance difference between values for variables. ** p<0.05 ***p<0.01 Scoring Models – Bivariate Analysis Coding correspondence with quality indicators. The results of the bivariate analysis of agreement about scoring are reported in Table 4.9. -114 - For each measure of agreement about scoring, there was a statistically significant difference between the situations in which the care could have been delivered outside the two-year study period versus within the study period. Overall agreement and the specificity of each data source were better for indicators assessing care that could have occurred prior to the time for which claims and medical records data were available. The sensitivity of both data sources was substantially better for the indicators assessing care that had to be delivered during the study period. Probability of claim being submitted. Agreement between claims and medical records data about whether the indicated care had been delivered varied by the type and modality of care being assessed as well as the setting in which the care could be delivered. Across the five measures of agreement about scoring, indicators assessing the quality of care delivered for chronic conditions had lower agreement than indicators assessing acute or preventive care. In contrast, there was no consistent pattern between the mode of care being assessed and better or worse agreement across the five measures of agreement. However, among the indicators assessing whether appropriate medications were prescribed, there was complete sensitivity of claims data and specificity of medical records data. Overall agreement, the sensitivity of claims data, and the specificity of medical records data were significantly better among indicators assessing care that could be delivered in an ambulatory setting relative to those indicators assessing care specific to inpatient hospitalizations. The sensitivity of medical records data and the specificity of claims data did not vary by the setting of the indicated care. Patient characteristics. Patient characteristics, including whether a record was obtained from a patient’s primary care provider and whether the patient had one or more hospitalizations during the study period were associated with different levels of agreement. With the exception of the specificity of medical records data, having obtained a primary care record was associated with better agreement. Overall agreement, the sensitivity of claims data and the specificity of medical records data were better among patients without any hospitalizations. -115- Table 4.9 Level of Agreement about Scoring – Bivariate Comparisons Overall Agreement SensitivityAD SensitivityMR SpecificityAD SpecificityMR 0.68 0.52 9.13*** 0.57 0.38 15.46*** 0.61 0.85 72.29*** 0.72 0.91 57.02*** 0.80 0.62 0.77 33.03*** 0.92 0.58 0.67 7.27** 0.69 0.58 0.45 9.79*** 0.72 0.65 0.79 19.80*** 0.93 0.66 0.90 80.90*** 0.80 0.64 0.60 0.71 0.51 61.16*** 0.65 0.60 0.29 0.65 1.00 39.81*** 0.55 0.43 1.00 0.63 0.51 18.46*** 0.85 0.66 1.00 0.75 0.00 160.36*** 0.89 0.79 0.52 0.77 -56.67*** 0.40 0.73 26.37*** 0.21 0.67 27.18*** 0.70 0.51 1.48 0.80 0.76 0.15 0.32 0.86 79.64*** 0.77 0.66 20.21*** 0.68 0.45 15.48*** 0.69 0.20 116.43*** 0.82 0.69 21.95*** 0.81 0.88 8.81*** 0.70 0.57 0.52 0.76 0.79 0.75 4.05** 0.72 9.57*** 0.50 0.27 0.76 0.01 0.89 15.64*** 1451 413 512 1038 939 CODING CORRESPONDENCE WITH QUALITY INDICATORS Time-frame Within 2 years Greater than 2 years Pearson χ2 (1) 0.64 0.80 43.56*** PROBABILITY OF CLAIM BEING SUBMITTED Care type Acute Chronic Preventive Pearson χ2 (2) Modality of care Immunization Laboratory service Medication Physical Examination Visit Pearson χ2 (4) Setting Inpatient only Ambulatory or Inpatient Pearson χ2 (1) PATIENT CHARACTERISTICS Medical Record Availability Received PCP record No PCP record received Pearson χ2 (1) Utilization One or more hospitalizations No hospitalizations Pearson χ2 (1) TOTAL N * p<0.10, Wald Chi-Square test for significance difference between values for variables. ** p<0.05 ***P<0.01 -116 - Multivariate Analysis Ten multivariate logistic equations were used to analyze jointly the predictors of levels of agreement about eligibility and scoring. Each of the 10 equations were of the basic form: logit(Pi) = ln[Pi/(1- Pi)] = b0+Σ bkΧik where Pi = probability of agreement between claims data and medical th record data for the i patient-indicator dyad; and Χi = a vector of k indicator and patient covariates (see th Table 4.5) for the i patient-indicator dyad. Table 4.10 reports the estimated odds ratios from the logistic regressions for eligibility; the analogous scoring results are reported in Table 4.11. The odds ratio is a measure of association. For binary variables, the odds ratio approximates how much more or less likely it is for the outcome of interest to be present among those with x = 1 than among those with x = 0 (Hosmer and Lemeshow 1989). For example, in the overall agreement model for eligibility (Model 1 in Table 4.10), the estimated odds ratio (Ψ) for INPT is 3.08 – this suggests that claims data and the medical records data agreed three times more often among indicators specific to inpatient care (INPT=1) than among indicators that assessed the quality of care in any other setting (INPT=0), other things equal. Similarly, the odds ratio for DX_PREV is estimated as 0.18 in the same model, which suggests that agreement about eligibility is about one-fifth as frequent among indicators that refer to a prevalent diagnosis for the eligibility criteria than among indicators that do not include any diagnostic criteria (DX_NO=1). For continuous variables, the odds ratio approximates how much more or less likely it is for the outcome of interest to be present for an increase of “1” unit in x. The null hypothesis that the odds ratio equaled zero was tested to assess the significance of the variables in the model. Unless otherwise stated, the threshold for statistical significance corresponds to P<0.05. As reported in Tables 4.10 and 4.11, many of the variables were -117 - not statistically significant predictors of agreement. Standard errors were adjusted using Huber’s formula, which corrects for correlation in the random disturbances in the relationships that results from the same patients being observed for multiple observations (i.e., non-independent observations) (Huber 1967; White 1980). To better understand the relative levels of influence of the covariates on the different measures of agreement, semi-standardized regression coefficients were computed. Semi-standardized regression coefficients estimated the increases in the dependent variable associated with a one standard deviation increase in an independent variable, holding levels of the other covariates constant. These statistics are calculated by multiplying a regression coefficient by the standard deviation of the corresponding covariate. for the different scales of the covariates. This standardizes The semi-standardized regression coefficients are reported in Appendix E. The discussion of results from the multivariate analysis highlights the following key findings: • Factors associated with better sensitivity (i.e., positive agreement) sometimes contribute to worse specificity (i.e., negative agreement). • The sensitivity of medical records was higher when data were abstracted from a primary care provider record. • Having a diagnosis referenced in the medication specifications had a strong and negative effect on all measures of agreement about eligibility. • Agreement about scoring was most strongly associated with whether the indicator was assessing preventive care. In particular, overall agreement and the specificity of claims data were lower for indicators assessing preventive care relative to acute care, but the sensitivity of claims data was higher for the preventive care indicators. • The sensitivity of claims data to determine that the scoring criteria were satisfied was higher among indicators where (a) the care was to be delivered during a two-year study period and (b) the care was not specific to the inpatient setting. -118 - Eligibility - Multivariate Analysis about Agreement Code correspondence. Increasing complexity of the claims data specifications for eligibility had different effects on the sensitivity and specificity of the data sources. Eligibility statements that were more compound in nature (AND_CNT) had better overall agreement and specificity (Model 1: ΨAND_CNT = 1.23; 95% CI, 1.15-1.33; Model 4: ΨAND_CNT = 1.35; 95% CI, 1.19-1.54; Model 5: ΨAND_CNT = 1.17; 95% CI, 1.07-1.27), but lower sensitivity (Model 2: ΨAND_CNT = 0.70; 95% CI, 0.55-0.87; Model 3: ΨAND_CNT = 0.76; 95% CI, 0.64-0.90). These findings support the first hypothesis for sensitivity, but not for overall agreement and specificity. The first hypothesis stated that as the specifications used to construct an indicator increase in complexity, the level of agreement between claims and medical records data will decrease. The estimates indicate that eligibility statements without diagnostic criteria generally have higher levels of agreement than those that reference either a prevalent (DX_PREV=1) or new diagnosis (DX_NEW=1). The diagnosis covariates (DX_PREV and DX_NEW) had the strongest standardized effects in the estimates of overall agreement and sensitivity (see Appendix E). These findings support the second hypothesis, namely, the probability of agreement between claims and medical records data about eligibility will be higher for indicators that do not rely on diagnostic information. Likelihood of a claim being submitted. Without controlling for other factors, the bivariate analysis suggested that agreement about eligibility (especially positive agreement) was worse among indicators assessing acute care relative to indicators assessing chronic or preventive care. However, in the multivariate analysis the levels of overall agreement, sensitivity, and specificity for indicators assessing chronic care were not statistically different from those indicators assessing acute care. Nevertheless, the odds ratios suggest that agreement about eligibility is generally better among the indicators assessing chronic care and poorer among the preventive care indicators. When claims data indicated that the eligibility criteria for an -119 - indicator had been satisfied, medical records agreed about one-fifth as often among indicators assessing preventive care rather than acute care (Model 3: ΨTYPE_PREV = 0.20; 95% CI, 0.06-0.69). The odds of overall agreement about eligibility were higher for indicators that assessed care during inpatient hospitalizations (Model 1: ΨINPT = 3.08; 95% CI, 2.05-4.63). This supports the fourth hypothesis, namely the probability of agreement about eligibility will be higher for indicators specific to hospitalizations. However, the signs of the corresponding coefficients for the sensitivity (Model 2) and specificity (Model 4) of claims data were opposite. Specifically, among the observations where the eligibility criteria were satisfied according to the medical records data, agreement was less than one-fifth as frequent among indicators specific to inpatient care than among indicators assessing the quality of care delivered in ambulatory settings (Model 2: ΨINPT= 0.17; 95% CI, 0.09-0.33). In contrast, among observations where the medical records data implied that the eligibility criteria were not satisfied, agreement occurred over eleven times as often when the care was specific to inpatient care (Model 4: ΨINPT= 11.09; 95% CI, 6.59-18.67). Patient characteristics. As suggested by the seventh hypothesis, the estimates indicate that the sensitivity of medical records is higher when a primary care provider record was obtained. That is, among the observations where the eligibility criteria were satisfied according to claims data, the medical records assessments were more likely to agree when a primary care record had been obtained than when no primary care record had been obtained (Model 3: ΨGOT_PCP= 1.93; 95% CI, 1.19-3.15). The presence of a primary care record did not have a statistically significant effect on the four other measures of agreement about eligibility. The estimates indicate very small differences in the number of office visits (OFFICE) and agreement about eligibility (see Appendix E). Across all measures of agreement, the odds ratio for OFFICE is close to one. Nevertheless, as the number of office visits for a patient increased, the odds decreased for (a) overall agreement (Model 1: ΨOFFICE= 0.98; 95% CI, 0.97-0.99) and (b) agreement among observations where the -120 - eligibility criteria were not satisfied with medical records data (Model 4: ΨOFFICE= 0.97; 95% CI, 0.95-0.98). However, an increasing number of office visits was associated with better agreement among observations where the eligibility criteria were satisfied with medical records data (Model 2: ΨOFFICE= 1.03; 95% CI, 1.01-1.04). This suggests that the probability of claims data determining that the eligibility criteria have been satisfied increases slightly with the number of office visits for both patients who were found to meet the eligibility criteria with medical records data as well as those who did not. -121 - Table 4.10 Odds Ratios from Logistic Regressions for Agreement between Claims Data and Medical Records About Eligibility Model 1 Overall Agreement Model 2 SensitivityCD Code Correspondence AND_CNT Model 3 SensitivityMR Model 4 SpecificityCD Model 5 SpecificityMR 0.76* [0.07] (0.00) 1.47* [0.13] (0.00) 1.42 [0.46] (0.27) Reference Category 0.00* [0.00] (0.00) 0.01* [0.00] (0.00) 1.35* [0.09] (0.00) 1.19* [0.06] (0.00) 3.47* [0.87] (0.00) Reference Category 0.41* [0.18] (0.04) 0.29* [0.12] (0.00) 1.17* [0.05] (0.00) 0.91 [0.06] (0.19) 0.81 [0.18] (0.35) Reference Category 0.35 [0.19] (0.06) 0.41 [0.21] (0.09) 0.70* 1.23* [0.08] [0.04] (0.00) (0.00) 1.08 OR_CNT 1.06 [0.11] [0.04] (0.44) (0.13) 0.26* NOAND 1.58* [0.09] [0.27] (0.00) (0.01) DX_NO Reference Reference Category Category 0.00* DX_PREV 0.18* [0.01] [0.06] (0.00) (0.00) 0.01* DX_NEW 0.18* [0.01] [0.06] (0.00) (0.00) Likelihood of Claim Being Submitted TYPE_ACUTE Reference Reference Category Category 1.05 TYPE_CHRONIC 1.45 [0.73] [0.33] (0.94) (0.10) 0.42 TYPE_PREV 0.66 [0.32] [0.23] (0.26) (0.22) 0.17* INPT 3.08* [0.06] [0.64] (0.00) (0.00) Patient Characteristics 0.80 GOT_PCP 1.03 [0.20] [0.15] (0.38) (0.85) 1.03* OFFICE 0.98* [0.01] [0.01] (0.01) (0.00) 0.88 ANYHOSP 0.33* [0.26] [0.05] (0.67) (0.00) Reference Category 1.52 [0.82] (0.44) 0.20* [0.13] (0.01) 1.65 [0.55] (0.13) Reference Category 1.87 [0.59] (0.05) 0.66 [0.29] (0.34) 11.09* [2.95] (0.00) Reference Category 1.19 [0.38] (0.58) 0.83 [0.46] (0.74) 1.15 [0.34] (0.63] 1.93* [0.48] (0.01) 1.01 [0.01] (0.40) 1.36 [0.35] (0.23) 1.30 [0.22] (0.12) 0.97* [0.01] (0.00) 0.45* [0.08] (0.00) 0.71 [0.19] (0.22) 0.99 [0.01] (0.47) 0.21* [0.05] (0.00) N 2 Model Wald chi 1286 206.39 12,658 257.41 12,589 139.76 13,875 292.00 1217 219.54 -122 - df P(chi2) Pseudo R2 Model 1 Overall Agreement 11 0.00 Model 2 SensitivityCD Model 3 SensitivityMR Model 4 SpecificityCD Model 5 SpecificityMR 11 0.00 11 0.00 11 0.00 11 0.00 0.10 0.43 0.40 0.13 0.08 *p<0.05 ^ Each cell reports the odds ratio, [standard error], and (p value for Ho: Odds ratio =1). Scoring - Multivariate Analysis about Agreement Code correspondence. Among the observations where the medical records found the scoring criteria satisfied, the probability of the claims data agreeing increased significantly as the number of data elements increased (Model 2: ΨELMT_CNT= 3.43; 95% CI, 1.05-11.18). Although not statistically significant at p<0.05, the odd ratios for the number of data elements in the scoring specifications are also greater than one for overall rate of agreement (Model 1: ΨELMT_CNT= 1.47; 95% CI, 0.99-2.21) and the specificity of claims data (Model 4: ΨELMT_CNT= 1.52; 95% CI, 0.86-2.70). In contrast, among observations where the claims data found the scoring criteria to have been satisfied, the probability of agreement with medical records data decreased by one-half for each additional data element in the claims data specifications (Model 3: ΨELMT_CNT= 0.48; 95% CI, 0.23-0.98). Therefore, the first hypothesis that anticipated agreement to diminish with increasingly complex specifications is not supported for the scoring component of indicators. The effect of indicators assessing care that could have occurred prior to the two-year period for which data were available had opposing effects on the sensitivity and specificity of claims data. Among observations where the medical records data found the scoring criteria to be satisfied, the odds of the claims data agreeing were lower when the indicated care could have occurred prior to the study (Model 2: ΨTW_GT2= 0.12; 95% CI, 0.05-0.26). In contrast, among observations where the medical records data did not find the scoring criteria to be satisfied, the odds that claims data would concur were higher when the care could have occurred prior to the study (Model 4: ΨTW_GT2=18.92; 95% -123- CI, 8.85-40.43). This implies that when the indicated care could occur outside the time for which data are available, the likelihood of claims data missing people who received the indicated care increases, while the likelihood of including people who failed to receive the indicated care according to the medical records data decreases. Therefore, the third hypothesis is supported for positive agreement, but not for negative agreement. Probability of claim being submitted. The rates of overall agreement, sensitivity of medical records data, and specificity of claims data were all lower when the indicators assessed preventive care rather than acute care (Model 1: ΨTYPE_PREV= 0.07; 95% CI, 0.02-0.22; Model 3: ΨTYPE_PREV= 0.15; 95% CI, 0.03-0.70; Model 4: ΨTYPE_PREV= 0.01; 95% CI, 0.000.20). However, the sensitivity of claims data was higher among the preventive care indicators than the acute care indicators (Model 2: ΨTYPE_PREV= 41.22; 95% CI, 2.90-586.32). This suggests that claims data found scoring criteria to be satisfied more often for preventive care services than medical records data. Across the five measures of agreement, the largest semi-standardized coefficient (see Appendix E) was for indicators assessing preventive care (TYPE_PREV). Relative to indicators assessing acute care, the likelihood of agreement about whether the indicated care was delivered was also lower among the indicators assessing chronic care (Model 1: ΨTYPE_CHRONIC= 0.20; 95% CI, 0.05-0.73). There was no statistically significant difference between acute and chronic indicators on the level of sensitivity or specificity of either data source, however the odds ratios were greater than one for the sensitivity equations and less than one for the specificity models. This suggests better positive agreement, but worse negative agreement, among indicators assessing chronic care. Laboratory services was the reference category for the mode of care assessed by the indicators. Across the five measures, the levels of agreement were not statistically different among indicators assessing whether physical examinations were performed (MODE_PE=1) relative to indicators assessing whether laboratory tests were performed. However, the odds ratios suggest that sensitivity of claims data is lower for indicators assessing whether a physical examination was performed - 124- relative to whether a laboratory test was performed, but specificity of these indicators was higher relative to the laboratory services indicators. Among indicators assessing whether appropriate medications were prescribed (MODE_MED=1), the sensitivity of medical records (Model 3) was 100% and the specificity of claims data (Model 4) was 100%. Specifically, if the claims data determined the scoring criteria had been met, then the medical records data always concurred among indicators assessing whether medication was prescribed. Likewise, among all observation where the medical records data determined the medication had not been prescribed, the claims data concurred. Among indicators assessing whether a visit occurred (MODE_VIS=1), if the medical records data indicated that there was a visit, then the claims data always agreed (i.e., the sensitivity of claims data was 100%). If the medical records said the visit did not occur, the claims data always said that it did (i.e., specificity of claims data was 0%). When covariates perfectly predicted the agreement variable, the observations with the covariate equaling one were removed from the sample and the covariate was excluded from the model. For example, in the model analyzing the sensitivity of claims data (Model 2), there were 36 observations where MODE_VIS=1 and each of those observations was dropped from the analysis. The rates of overall agreement, sensitivity of medical records data, and specificity of claims data were higher among indicators assessing whether immunizations were administered relative to laboratory services being delivered (Model 1: ΨMODE_IMM= 3.70; 95% CI, 2.57-5.31; Model 3: ΨMODE_IMM= 8.12; 95% CI, 3.36-19.63; Model 4: ΨMODE_IMM= 12.59; 95% CI, 7.54-21.01). In contrast, the sensitivity of claims data was lower among indicators where the administration of immunizations was assessed (Model 2: ΨMODE_IMM= 0.26; 95% CI, 0.09-0.79). This suggests that if claims data determined that an immunization was administered, the medical records were likely to concur, and if medical records data found the care had not been delivered the claims data were likely to concur. However, claims data were more likely to underestimate the performance rate, relative to the medical records assessments, concerning whether -125 - immunizations were delivered than for whether laboratory tests were performed. Overall agreement and the sensitivity of claims data were worse among indicators assessing care delivered in an inpatient setting (Model 1: ΨINPT=0.41; 95% CI, 0.17-0.99; Model 2: ΨINPT=0.26; 95% CI, 0.08-0.81); this is consistent with the fifth hypothesis. The setting of indicated care was not associated with a statistically significant effect on the other measures of agreement. However, the odds-ratio on INPT in the specificity model was 2.71, suggesting better negative agreement among indicators specific to the inpatient setting. With the exception of the specificity of medical records data, the average value of the fee associated with care did not have a statistically significant effect (Model 5: ΨFEE_VAL=1.00; 95% CI, 0.991.00). This result fails to support the sixth hypothesis, namely, that the probability of agreement about scoring would be higher among indicators assessing care with higher reimbursement rates. Patient characteristics. Having information from a primary care record had a significant effect in all models except for the sensitivity of claims data. Overall agreement, the sensitivity of medical records data, and the specificity of claims data were better among observations where the primary care record was obtained (Model 1: ΨGOT_PCP=1.81; 95% CI, 1.41-2.33; Model 3: ΨGOT_PCP=14.56; 95% CI, 8.05-26.33; Model 4: ΨGOT_PCP=1.83; 95% CI, 1.25-2.68). hypothesis. This is consistent with the seventh However, among observations that the claims data did not find the indicated care to be delivered, the medical records data agreed about one-half as frequently among observations where the primary care record was received relative to observations where the record was not obtained (Model 5: ΨGOT_PCP=0.49; 95% CI, 0.32-0.76). This suggests that data abstracted from primary care records satisfy scoring criteria even when claims data do not. Patients’ utilization of health care services (OFFICE and ANYHOSP) during the two-year period for which the claims and medical records data were available had a minimal effect on the five measures of agreement. The semi-standardized coefficients for the utilization covariates were among the smallest across all five agreement models (see Appendix E). -126 - Table 4.11 Odds Ratios for Agreement between Claims Data and Medical Records About Scoring (Step 2 Models)^ Model 1 Overall Agreement Code Correspondence ELMT_CNT Model 2 SensitivityCD 3.43* 1.47 [2.07] [0.30] (0.04) (0.06) 0.12* TW_GT2 2.91* [0.05] [0.54] (0.00) (0.00) Likelihood of Claim Being Submitted TYPE_ACUTE Reference Reference Category Category 2.08 TYPE_CHRONIC 0.20* [2.10] [0.13] (0.47) (0.02) 41.22* TYPE_PREV 0.07* [55.84] [0.04] (0.01) (0.00) MODE_LAB Reference Reference Category Category 0.26* MODE_IMM 3.70* [0.15] [0.68] (0.02) (0.00) 0.37 MODE_MED 0.90 [0.21] [0.33] (0.09) (0.78) 0.44 MODE_PE 1.19 [0.33] [0.37] (0.28) (0.57) DROPPED36 MODE_VIS 0.20* [0.10] (0.00) Model 3 SensitivityMR Model 4 SpecificityCD Model 5 SpecificityMR 0.48* [0.17] (0.04) 0.90 [0.30] (0.74) 1.52 [0.45] (0.15) 18.92* [7.33] (0.00) 11.46* [8.32] (0.00) 1.45 [0.50] (0.29) Reference Category 1.90 [1.68] (0.47) 0.15* [0.12] (0.02) Reference Category 8.12* [3.66] (0.00) DROPPED34 Reference Category 0.32 [0.40] (0.37) 0.01* [0.02] (0.00) Reference Category 12.59* [3.29] (0.00) DROPPED35 2.90 [2.00] (0.12) 3.62 [2.93] (0.11) 16.00 [31.26] (0.16) DROPPED37 Reference Category 0.33 [0.43] (0.40) 7.59 [12.18] (0.21) Reference Category 0.43 [0.19] (0.06) 1.76 [1.02] (0.33) 0.60 [0.41] (0.46) DROPPED38 ___________ 34 If MODE_MED = 1, then agreement was perfectly predicted. Therefore 10 observations were removed from the sample and MODE_MED excluded from the model. 35 If MODE_MED = 1, then agreement was perfectly predicted. Therefore 27 observations were removed from the sample and MODE_MED excluded from the model 36 If MODE_VIS = 1, then agreement was perfectly predicted. Therefore 36 observations were removed from the sample and MODE_VIS excluded from the model. 37 If MODE_VIS = 1, then disagreement was perfectly predicted. Therefore 34 observations were removed from the sample and MODE_VIS excluded from the model. was was was was -127 - INPT FEE_VAL Model 2 SensitivityCD Model 3 SensitivityMR Model 4 SpecificityCD Model 5 SpecificityMR 0.26* [0.15] (0.02) 1.00 [0.00] (0.17) 0.68 [0.56] (0.64) 1.00 [0.00] (0.38) 2.71 [2.52] (0.29) 0.94 [0.05] (0.20) 0.77 [0.52] (0.69) 1.00 [0.00] (0.03) 1.98 [0.83] (0.10) 0.99 [0.01] (0.56) 0.72 [0.21] (0.26) 14.56* [4.40] (0.00) 1.00 [0.01] (0.96) 0.69 [0.17] (0.14) 1.83* [0.36] (0.00) 0.97* [0.01] (0.00) 1.75* [0.36] (0.01) 0.49* [0.11] (0.00) 0.99 [0.01] (0.97) 0.95 [0.21] (0.82) 1451 117.72 13 0.00 377 62.48 12 0.00 502 114.05 12 0.00 977 185.17 11 0.00 939 116.12 12 0.00 0.09 0.20 0.28 0.19 0.21 Model 1 Overall Agreement 0.41* [0.18] (0.05) 1.00 [0.00] (0.56) Patient Characteristics GOT_PCP 1.81* [0.00] (0.04) OFFICE 0.99* [0.00] (0.04) ANYHOSP 1.08 [0.15] (0.57) N 2 Wald chi Df 2 P(chi ) Pseudo R 2 * p<0.05 ^ Each cell reports the odds ratio, [standard error], and (P-value). Summary of Multivariate Analysis of Agreement about Eligibility and Scoring The hypotheses that were presented earlier in the chapter are listed in Table 4.12 to summarize the findings from the multivariate analysis. The results from the logistic regressions highlight that the factors associated with better sensitivity of claims data may have the opposite effect on the specificity of claims data. For example, the sensitivity of claims data to determine eligibility is better among indicators assessing care that is not specific to the inpatient setting. In contrast, the specificity of claims data is better among indicators that assess care delivered during a hospitalization. Further, the sensitivity of claims data to determine whether the indicated 38 MODE_VIS=0 for all observations where the claims data determined that the scoring criteria had been satisfied. Therefore, MODE_VIS was excluded from the model. -128 - immunizations were delivered was worse relative to assessing whether laboratory services were provided, but the opposite was true for specificity. The tolerance of error in positive and negative agreement may differ, therefore it is important to understand each. For example, quality measurement being used to monitor internal processes might be more tolerant of overestimating the eligible population for an indicator (i.e., trade specificity for sensitivity) so as to evaluate a wider cross-section of the population. On the other hand, when measuring quality for public reporting, there is probably a greater willingness on the part of reporting plans to underestimate those who satisfy eligibility criteria to avoid underestimation of the performance rate. 129 Table 4.12 Results of Hypothesis Testing Hypothesis Was the hypothesis supported? Findings (1) As the specifications used to construct quality of care indicators increase in complexity, the probability of agreement between claims and medical records data will decrease. In part. (2) The probability of agreement between claims and medical records data about eligibility will be higher for indicators that do not rely on diagnostic information. Yes. Across all measures of agreement, indicators with eligibility criteria referencing either a prevalent or new diagnosis significantly decreased the odds of agreement relative to no diagnosis in the eligibility specifications. (3) The probability of agreement between claims and medical records data about scoring will be lower if the indicated care could have been delivered prior to the study period. In part. The sensitivity of claims data was diminished when the indicated care could have been delivered prior to the study period. However, the specificity of claims data (i.e., agreement with the medical records that care had not been delivered) was improved when the care could have been delivered prior to the study period; this caused overall agreement to also be improved when the care could have occurred prior to the study period. (4) The probability of agreement about eligibility will be higher for indicators specific to hospitalizations. In part. Overall agreement and the specificity of claims data was better among eligibility statements specific to hospitalizations. However, the sensitivity of claims data was lower among these indicators. This suggests good negative agreement, but poor positive agreement about eligibility. (5) The probability of agreement about Yes. Overall agreement and the sensitivity of claims data were lower among Eligibility: Eligibility statements that were more compound in nature had better overall agreement and specificity, but worse sensitivity. Scoring: The number of data elements in the scoring statements did not affect overall agreement. However, the claims data was more likely to agree with medical records data that the indicated care had been delivered when there were multiple data elements required to score the indicator. 130 scoring will be lower for indicators specific to hospitalizations. the indicators assessing hospital specific care. The remaining measures of agreement were not affected by the setting of the indicated care. (6) The probability of agreement about scoring will be higher when the reimbursement rate for the service is higher. No. The reimbursement rate did not have a statistically significant effect on agreement about whether the indicated care was delivered. (7) The probability of agreement will be higher among patients who had a primary care record abstracted. Yes. Abstracting a patient’s primary care record was associated with better agreement across all measures except the sensitivity of claims data. (8) The probability of agreement will be higher among patients with greater utilization of health care services. No. Patients’ utilization of health care services had essentially no effect any measure of agreement. -131 - Agreement About Performance Rates Separate analysis of agreement between claims and medical records data about eligibility and scoring was helpful to understand the determinants of how well performance measurement with the two data sources correspond and to help gauge the accuracy of claims data. However, what is ultimately of interest is the performance rate. It is often presumed that claims data are likely to miss events that are recorded in the medical records. For example, HEDIS measures are typically calculated with claims and medical records data (i.e., the hybrid method) to assure that the performance rate is not underestimated by claims data alone. individual indicators. In this section I present performance rates for The comparisons are not necessarily representative of measuring quality more broadly because only a selection of indicators was constructed, the sample sizes for the indicators were quite small, and the data are from only one HMO. Performance rates based on each data source were compared for the 27 indicators where both the claims and medical records data identified at least 10 people as being eligible. The performance rates were estimated two ways – first, the overall rates for each data source were calculated. Alternatively, the performance rates were calculated conditional on agreement about eligibility. To compare the performance rates based on the two data sources, I tested the equality of the rates (Table 4.13). Equality between the performance rates constructed with claims data and medical records data could not be rejected some indicators, but claims data had higher rates for some indicators and the medical record rates were higher for others. Among the 27 indicators where the performance rates were compared, 12 were not statistically different, the claims data rate was statistically significantly higher for six of the indicators, and the medical records rate was higher for the remaining nine indicators (see Table 4.13). When comparing rates that were calculated conditional on the data sources agreeing about eligibility, 14 were not statistically different, claims data had higher rates than the medical records for 6 indicators, and for seven -132 - indicators the medical records rate was higher. However, the statistical power to discern differences between the data sources is limited by the small number of patients and indicators. Nevertheless, this analysis does suggest that medical records are not consistently better at determining whether care has been delivered. This finding is interesting because it challenges the basic assumption that claims data are likely to miss events that are recorded in medical records. 133 Table 4.13 Comparing Performance Rates from Claims and Medical Records Data Overall Rates Rates Contingent on Agreement about Eligibility Sample CD Rate MR Rate Z (sample size) (sample size) (p>|z|) Size CD Rate MR Rate Z (p>|z|) Asthma Beta2-agonist inhaler prescribed to moderate-to-severe asthmatics. 0.75 (N=12) 0.92 -1.18 (N=13) (0.24) 6 0.50 1.00 -2.00 (0.05) Moderate-to-severe asthma should not receive beta-blockers. 1.00 (N=12) 0.92 0.98 (N=13) (0.33) 6 1.00 1.00 Equivalent Pneumonia WBC blood test on the day of presentation with pneumonia if >65 or with coexisting illness. 0.16 (N=19) 0.38 -1.58 (N=21) (0.11) 7 0.29 0.14 0.65 (0.51) BUN or creatinine blood test on the day of presentation with pneumonia if >65 or with coexisting illness. Follow-up contact within 6 weeks after discharge or diagnosis of pneumonia. 0.11 (N=19) 0.82 (N=22) 0.38 -2.01 (N=21) (0.04) 0.57 1.61 (N=14) (0.11) 7 0.14 0.14 5 1.00 0.80 0.00 (N=14) 0.00 (N=63) 0.79 -4.26 (N=14) (0.00) 0.37 -5.19 (N=41) (0.00) 4 0.00 0.75 34 0.00 0.35 CAD Aspirin prescribed to patients newly diagnosed with CAD. Aspirin prescribed to patients with a prior 0.00 (1.00) 1.05 (0.29) -2.19 (0.03) -3.82 (0.00) 134 Rates Contingent on Agreement about Eligibility Overall Rates Sample CD Rate MR Rate Z (sample size) (sample size) (p>|z|) Size CD Rate MR Rate Z (p>|z|) diagnosis of CAD who are not on aspirin. 12-lead ECG when CAD is newly diagnosed. 0.36 (N=14) 0.44 -0.45 (N=16) (0.65) 4 0.75 0.50 0.73 (0.47) 12-lead ECG when being evaluated for "unstable angina" or "rule out unstable angina." 0.43 (N=21) 0.79 -2.33 (N=19) (0.02) 11 0.73 0.91 -1.11 (0.27) 0.20 1.56 (N=59) (0.12) 0.36 0.58 (N=59) (0.56) 57 0.37 0.21 Annual eye and visual exam for diabetics. 0.32 (N=74) 0.41 (N=74) 57 0.42 0.37 1.86 (0.06) 0.57 (0.57) Total serum cholesterol and HDL cholesterol tests documented for diabetics. 0.51 (N=74) 0.31 2.42 (N=59) (0.02) 57 0.53 0.32 2.28 (0.02) Annual measurement of urine protein for diabetics. 0.46 (N=74) 0.25 2.44 (N=59) (0.01) 57 0.44 0.26 1.96 (0.05) Follow-up visit at least every 6 months for diabetics. 0.99 (N=74) 0.47 6.86 (N=59) (0.00) 57 1.00 0.47 6.38 (0.00) Congestive Heart Failure Evaluation of their ejection fraction within 1 month of the start of treatment for newly diagnosed heart failure. 0.30 (N=20) 0.70 -2.08 (N=10) (0.04) 5 17 0.60 1.00 -1.58 (0.11) 0.06 0.71 -3.88 Diabetes Glycosylated hemoglobin or fructosamine measured every 6 months for diabetics. Serum electrolytes performed within one day 0.04 0.74 -5.23 135 Rates Contingent on Agreement about Eligibility Overall Rates of hospitalization for heart failure. Sample CD Rate MR Rate Z (sample size) (sample size) (p>|z|) Size (N=28) (N=23) (0.00) Serum creatinine performed within one day of hospitalization for heart failure. Serum potassium checked every year if on ACE inhibitor and has heart failure. Serum creatinine checked every year if on ACE inhibitor and has heart failure. 0.04 (N=28) 0.39 (N=31) 0.32 (N=31) 0.70 -4.98 (N=23) (0.00) 0.68 -2.18 (N=25) (0.02) 0.64 -2.37 (N=25) (0.02) Follow-up contact within 4 weeks of discharge for heart failure. 1.00 (N=21) 0.69 2.76 (N=16) (0.00) Preventive Care Tetanus/diphtheria booster within the last ten years if less than 50 years. Tetanus/diphtheria booster within the last ten years if over 50 years. Influenza vaccine annually if over 65 years. Influenza vaccine annually if less than 65 years and in high-risk group. Pneumococcal vaccine if 65 years or older. Pneumococcal vaccine if patient has chronic cardiac or pulmonary disease. Pap smear every 3 years for women. 0.09 (N=127) 0.08 (N=248) 0.67 (N=192) 0.28 (N=47) 0.19 (N=191) 0.13 (N=47) 0.45 (N=194) 0.15 (N=117) 0.10 (N=249) 0.41 (N=190) 0.23 (N=39) 0.26 (N=189) 0.14 (N=28) 0.11 (N=193) -1.62 (0.11) -0.75 (0.45) 5.23 (0.00) 0.49 (0.63) -1.68 (0.09) -0.19 (0.85) 7.41 (0.00) CD Rate MR Rate Z (p>|z|) (0.00) 17 0.06 0.65 16 0.38 0.75 16 0.25 0.69 -3.59 (0.00) -2.14 (0.03) -2.48 (0.01) 8 1.00 0.63 1.92 (0.05) 117 0.09 0.15 243 0.09 0.10 190 0.67 0.41 26 0.31 0.19 189 0.19 0.26 18 0.17 0.17 190 0.46 0.12 -1.39 (0.16) -0.47 (0.64) 5.25 (0.00) 0.96 (0.34) -1.60 (0.11) 0.00 (1.00) 7.37 (0.00) - 136 - CONCLUSIONS Claims and medical records data do not consistently yield similar measurements of quality – sometimes the measurements are very similar, and there are situations where one data source yields a higher performance rate than the other. The two data sources agree much more closely about who is not eligible for and who fails an indicator than who is eligible for or passes an indicator. Claims and medical records data are more likely to agree about whether eligibility criteria have been satisfied when diagnostic information is not required. Better agreement also occurs when the indicators being constructed are not specific to inpatient ancillary services and when the time-frame for the indicated care is less than that of the available claims data. When using medical records for quality measurement, abstracting data from a primary care provider’s record significantly improves agreement with claims data about who is eligible for and receives indicated care.