Linear Regression Models Andy Wang CIS 5930-03 Computer Systems
advertisement

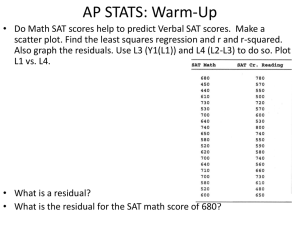
Linear Regression Models Andy Wang CIS 5930-03 Computer Systems Performance Analysis Linear Regression Models • • • • • What is a (good) model? Estimating model parameters Allocating variation Confidence intervals for regressions Verifying assumptions visually 2 What Is a (Good) Model? • For correlated data, model predicts response given an input • Model should be equation that fits data • Standard definition of “fits” is leastsquares – Minimize squared error – Keep mean error zero – Minimizes variance of errors 3 Least-Squared Error • If yˆ b0 b1x then error in estimate for xi is ei y i yˆ i • Minimize Sum of Squared Errors (SSE) n n e 2 i i 1 y i b0 b1x i 2 i 1 • Subject to the constraint n n e y i i 1 i b0 b1x i 0 i 1 4 Estimating Model Parameters • Best regression parameters are xy nx y b1 2 2 x n x b0 y b1x where 1 x xi n xy xi y i 1 y yi n 2 2 x x i • Note error in book! 5 Parameter Estimation Example • Execution time of a script for various loop counts: Loops 3 5 7 9 10 Time 1.2 1.7 2.5 2.9 3.3 • x = 6.8, y = 2.32, xy = 88.7, x2 = 264 88.7 56.82.32 0.30 • b1 2 264 56.8 • b0 = 2.32 (0.30)(6.8) = 0.28 6 Graph of Parameter Estimation Example 3 2 1 0 0 2 4 6 8 10 12 7 Allocating Variation • If no regression, best guess of y is y • Observed values of y differ from y , giving rise to errors (variance) • Regression gives better guess, but there are still errors • We can evaluate quality of regression by allocating sources of errors 8 The Total Sum of Squares • Without regression, squared error is n n SST y i y y 2y i y y i 1 2 i 1 2 i 2 n 2 n y i 2y y i ny 2 i 1 i 1 n 2 y i 2y ny ny 2 i 1 n 2 y i ny 2 SSY SS 0 i 1 9 The Sum of Squares from Regression • Recall that regression error is 2 2 SSE ei yi yˆ • Error without regression is SST • So regression explains SSR = SST - SSE • Regression quality measured by coefficient of determination SSR SST SSE 2 R SST SST 10 Evaluating Coefficient of Determination • Compute SST ( y 2 )ny 2 2 • Compute SSE y b0 y b1 xy SST SSE 2 • Compute R SST • where R = R(x,y) = correlation(x,y) 11 Example of Coefficient of Determination • For previous regression example 3 5 7 9 10 1.2 1.7 2.5 2.9 3.3 – y = 11.60, y2 = 29.88, xy = 88.7, ny 5 2.32 26.9 2 2 – SSE = 29.88-(0.28)(11.60)-(0.30)(88.7) = 0.028 – SST = 29.88-26.9 = 2.97 – SSR = 2.97-.03 = 2.94 – R2 = (2.97-0.03)/2.97 = 0.99 12 Standard Deviation of Errors • Variance of errors is SSE divided by degrees of freedom – DOF is n2 because we’ve calculated 2 regression parameters from the data – So variance (mean squared error, MSE) is SSE/(n2) • Standard dev. of errors is square root: SSE (minor error in book) se n2 13 Checking Degrees of Freedom • Degrees of freedom always equate: – SS0 has 1 (computed from y ) – SST has n1 (computed from data and y, which uses up 1) – SSE has n2 (needs 2 regression parameters) – So SST SSY SS 0 SSR SSE n 1 n 1 1 ( n 2) 14 Example of Standard Deviation of Errors • For regression example, SSE was 0.03, so MSE is 0.03/3 = 0.01 and se = 0.10 • Note high quality of our regression: – R2 = 0.99 – se = 0.10 15 Confidence Intervals for Regressions • Regression is done from a single population sample (size n) – Different sample might give different results – True model is y = 0 + 1x – Parameters b0 and b1 are really means taken from a population sample 16 Calculating Intervals for Regression Parameters • Standard deviations of parameters: sb0 se s b1 1 x2 n x 2 nx 2 se x nx • Confidence intervals are bi ts bi where t has n - 2 degrees of freedom 2 2 – Not divided by sqrt(n) 17 Example of Regression Confidence Intervals • Recall se = 0.13, n = 5, x2 = 264, x = 6.8 2 • So 1 (6.8) sb0 0.10 0.12 2 5 264 5(6.8) sb1 0.10 264 5(6.8) 2 0.017 • Using 90% confidence level, t0.95;3 = 2.353 18 Regression Confidence Example, cont’d • Thus, b0 interval is 0.38 2.353(0.12) (0.004,0.57) – Not significant at 90% • And b1 is 0.30 2.353(0.016) (0.26,0.34) – Significant at 90% (and would survive even 99.9% test) 19 Confidence Intervals for Predictions • Previous confidence intervals are for parameters – How certain can we be that the parameters are correct? • Purpose of regression is prediction – How accurate are the predictions? – Regression gives mean of predicted response, based on sample we took 20 Predicting m Samples • Standard deviation for mean of future sample of m observations at xp is xp x 1 1 2 2 m n x nx 2 syˆ mp se • Note deviation drops as m • Variance minimal at x = x • Use t-quantiles with n–2 DOF for interval 21 Example of Confidence of Predictions • Using previous equation, what is predicted time for a single run of 8 loops? • Time = 0.28 + 0.30(8) = 2.68 • Standard deviation of errors se = 0.10 1 8 6.8 s yˆ1 p 0.10 1 0.11 2 5 264 5(6.8) • 90% interval is then 2.68 2.353(0.11) (2.42,2.93) 2 22 Prediction Confidence y x 23 Verifying Assumptions Visually • Regressions are based on assumptions: – Linear relationship between response y and predictor x • Or nonlinear relationship used in fitting – Predictor x nonstochastic and error-free – Model errors statistically independent • With distribution N(0,c) for constant c • If assumptions violated, model misleading or invalid 24 Testing Linearity • Scatter plot x vs. y to see basic curve type Linear Piecewise Linear Outlier Nonlinear (Power) 25 Testing Independence of Errors • Scatter-plot i versus ŷ i • Should be no visible trend • Example from our curve fit: 0.2 0.1 0 -0.1 0 1 2 3 4 26 More on Testing Independence • May be useful to plot error residuals versus experiment number – In previous example, this gives same plot except for x scaling • No foolproof tests – “Independence” test really disproves particular dependence – Maybe next test will show different dependence 27 Testing for Normal Errors • Prepare quantile-quantile plot of errors • Example for our regression: 0.2 0.1 0 -0.1 -0.2 -1.5 -1 -0.5 0 0.5 1 1.5 28 Testing for Constant Standard Deviation • • • • Tongue-twister: homoscedasticity Return to independence plot Look for trend in spread Example: 0.2 0.1 0 -0.1 0 1 2 3 4 29 Linear Regression Can Be Misleading • Regression throws away some information about the data – To allow more compact summarization • Sometimes vital characteristics are thrown away – Often, looking at data plots can tell you whether you will have a problem 30 Example of Misleading Regression x 10 8 13 9 11 14 6 4 12 7 5 I y 8.04 6.95 7.58 8.81 8.33 9.96 7.24 4.26 10.84 4.82 5.68 x 10 8 13 9 11 14 6 4 12 7 5 II y 9.14 8.14 8.74 8.77 9.26 8.10 6.13 3.10 9.13 7.26 4.74 x 10 8 13 9 11 14 6 4 12 7 5 III y 7.46 6.77 12.74 7.11 7.81 8.84 6.08 5.39 8.15 6.42 5.73 x 8 8 8 8 8 8 8 19 8 8 8 IV y 6.58 5.76 7.71 8.84 8.47 7.04 5.25 12.50 5.56 7.91 6.89 31 What Does Regression Tell Us About These Data Sets? • • • • • • • • Exactly the same thing for each! N = 11 Mean of y = 7.5 Y = 3 + .5 X Standard error of regression is 0.118 All the sums of squares are the same Correlation coefficient = .82 R2 = .67 32 Now Look at the Data Plots 12 12 I 10 8 8 6 6 4 4 2 2 0 0 0 12 5 10 15 0 20 12 III 10 8 6 6 4 4 2 2 0 0 5 10 15 20 5 10 15 20 5 10 15 20 IV 10 8 0 II 10 0 33 White Slide