Chapter 17 Failure-Time Regression Analysis William Q. Meeker and Luis A. Escobar
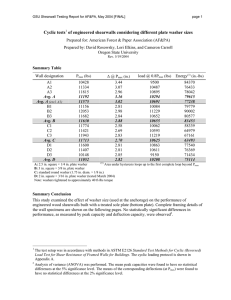
advertisement

Chapter 17
Failure-Time Regression Analysis
William Q. Meeker and Luis A. Escobar
Iowa State University and Louisiana State University
Copyright 1998-2008 W. Q. Meeker and L. A. Escobar.
Based on the authors’ text Statistical Methods for Reliability
Data, John Wiley & Sons Inc. 1998.
January 13, 2014
3h 42min
17 - 1
Chapter 17
Failure-Time Regression Analysis
Objectives
• Describe applications of failure-time regression
• Describe graphical methods for displaying censored regression data.
• Introduce time-scaling transformation functions.
• Describe simple regression models to relate life to explanatory variables.
• Illustrate the use of likelihood methods for censored regression data.
• Explain the importance of model diagnostics.
• Describe and illustrate extensions to nonstandard multiple
regression models
17 - 2
Computer Program Execution Time
Versus System Load
• Time to complete a computationally intensive task.
• Information from the Unix uptime command
• Predictions needed for scheduling subsequent steps in a
multi-step computational process.
17 - 3
Scatter Plot of Computer Program Execution Time
Versus System Load
800
•
700
Seconds
600
500
400
300
•
200
•
•
•
•
••• •
•
100
•
•
••
•
•
0
0
1
2
3
4
5
6
System Load
17 - 4
Explanatory Variables for Failure Times
Useful explanatory variables explain/predict why some units
fail quickly and some units survive a long time.
• Continuous variables like stress, temperature, voltage, and
pressure.
• Discrete variables like number of hardening treatments or
number of simultaneous users of a system.
• Categorical variables like manufacturer, design, and location.
Regression model relates failure time distribution to explanatory variables x = (x1, . . . , xk ):
Pr(T ≤ t) = F (t) = F (t; x).
17 - 5
Failure-Time Regression Analysis
• Material in this chapter is an extension of statistical regression analysis with normal distributed data and
mean = β0 + β1x1 + · · · + βsxk
where the xi are explanatory variables.
• The ideas presented here are more general:
◮ Data not necessarily from a normal distribution.
◮ Data may be censored.
◮ Nonstandard regression models that relate life to explanatory variables.
• Presentation motivated by practical problems in reliability
analysis.
17 - 6
Nickel-Base Super-alloy Fatigue Data
26 Observations in Total, 4 Censored
(Nelson 1984, 1990)
Originally described and analyzed by Nelson (1984 and 1990).
• Thousands of cycles to failure as a function of pseudostress in ksi.
• 26 units tested; 4 units did not fail.
Objective: Explore models that might be used to describe
the relationship between life length and the amount of pseudostress applied to the tested specimens.
17 - 7
Nickel-Base Super-Alloy Fatigue Data
(Nelson 1984, 1990)
250
•
•
Thousands of Cycles
200
•••
150
• •
100
•
50
•
0
60
80
•
•
100
••••••
•
120
• ••
140
160
Pseudo-stress (ksi)
17 - 8
SAFT Models
Illustrating Acceleration and Deceleration.
3.0
Time at Level x
2.5
scale
decelerating
transformation
2.0
1.5
1.0
scale
accelerating
transformation
0.5
0.0
0.0
0.5
1.0
1.5
2.0
2.5
3.0
Time at Level x0
17 - 9
Scale Accelerated Failure Time (SAFT) Model
• Scale Accelerated Failure Time (SAFT) models are defined
by
T (x) = T (x0)/AF (x),
AF (x) > 0,
AF (x0) = 1
where typical forms for AF (x) are:
◮ log[AF (x)] = β1x with x0 = 0 for a scalar x.
◮ log[AF (x)] = β1x1 + . . . + βk xk with x0 = 0 for a vector
x = (x1, . . . , xk ).
• When AF (x) > 1, the model accelerates time in the sense
that time moves more quickly at x than at x0 so that T (x) <
T (x0).
• When 0 < AF (x) < 1, T (x) > T (x0), and time is decelerated (but we still call this an SAFT model).
17 - 10
The SAFT Transformation Models and Acceleration
In a time transformation plot of T (x0) vs T (x)
• The SAFT models are straight lines through the origin:
• Accelerating SAFT models are straight lines below the diagonal.
• Decelerating SAFT models are straight lines above the diagonal.
17 - 11
Some Properties of SAFT Models
For a SAFT model T (x) = T (x0)/AF (x), (Ψ(x) > 0), with
baseline cdf F (t; x0) so AF (x0) = 1
• Scaled time: F (t; x) = F [AF (x) t; x0] . Thus the cdfs
F (t; x) and F (t; x0) do not cross each other.
• Proportional quantiles: tp(x) = tp(x0)/AF (x). Then taking logs gives
log[tp(x0)] − log[tp(x)] = log[AF (x)].
This shows that in any plot with a log-time scale tp(x0) and
tp(x) are equidistant.
In particular, in a probability plot with a log-time scale,
F (t, x) is a translation of F (t, x0) along the log(t) axis.
17 - 12
Weibull Probability Plot of Two Members from an
SAFT Model with a Baseline Lognormal Distribution
.999
.98
.9
∆
.7
.5
Probability
.3
.2
.1
.05
.03
.02
∆
.01
.005
.003
.001
1
5
10
50
100
Time
17 - 13
Lognormal Distribution Simple Regression Model with
Constant Shape Parameter β = 1/σ
• The lognormal simple regression model is
Pr(T ≤ t) = F (t; µ, σ) = F (t; β0, β1, σ) = Φnor
"
log(t) − µ
σ
#
where µ = µ(x) = β0 + β1x and σ does not depend on x.
• The failure-time log quantile function
log[tp(x)] = µ(x) + Φ−1
nor (p)σ
is linear in x.
Notice that
tp(x)
= exp (β1x)
tp(0)
implies that this regression model is a scale accelerated failure time (SAFT) model with AF (x) = exp(−β1x).
17 - 14
Computer Program Execution Time Versus System
Load Log-Linear Lognormal Regression Model
b
b
log[tbp(x)] = µ(x)
+ Φ−1
nor (p)σ
1000
90%
•
50%
Seconds
500
10%
•
200
•
•
• •
•
•
••
100
•
•
•
•
•
•
50
0
1
2
3
4
5
6
7
System Load
17 - 15
Likelihood for Lognormal Distribution Simple
Regression Model with Right Censored Data
The likelihood for n independent observations has the form
L(β0, β1 , σ) =
=
n
Y
Li (β0, β1, σ; datai )
i=1
n Y
i=1
δi 1−δi
1
log(ti ) − µi
log(ti ) − µi
φnor
1 − Φnor
σti
σ
σ
where datai = (xi, ti, δi), µi = β0 + β1xi,
δi =
(
1
0
exact observation
right censored observation
φnor (z) is the standardized normal pdf and Φnor (z) is the
corresponding normal cdf.
The parameters are θ = (β0, β1, σ).
17 - 16
Estimated Parameter Variance-Covariance Matrix
Local (observed information) estimate
b
b
b
b
d
d
d
b)
Var(β0)
Cov(β0, β1) Cov(β0, σ
b
b
b
b
d
d
d
b)
Σ̂b = Cov(β1, β0) Var(β1)
Cov(
β
,
σ
1
θ
b
b
d
d
d
b , β0 )
b , β1 )
b)
Cov(σ
Cov(σ
Var(σ
=
∂ 2 L(β0,β1,σ)
−
∂β02
∂ 2 L(β0,β1,σ)
− ∂β ∂β
1 0
∂ 2 L(β0,β1,σ)
− ∂σ∂β
0
∂ 2L(β0,β1 ,σ)
− ∂β ∂β
0 1
∂ 2L(β0,β1 ,σ)
−
∂β12
∂ 2L(β0,β1 ,σ)
− ∂σ∂β
1
∂ 2 L(β0,β1,σ)
− ∂β ∂σ
0
∂ 2 L(β0,β1,σ)
− ∂β ∂σ
1
∂ 2 L(β0,β1,σ)
−
∂σ 2
b.
Partial derivatives are evaluated at βb0, βb1, σ
−1
17 - 17
Standard Errors and Confidence Intervals
for Parameters
• Lognormal ML estimates for the computer time experiment
b = (βb , βb , σ
were θ
0 1 b ) = (4.49, .290, .312) and an estimate of
b is
the variance-covariance matrix for θ
.012 −.0037
0
Σ̂b = −.0037
.0021
0 .
θ
0
0 .0029
• Normal-approximation confidence interval for the computer
execution time regression slope is
[β1,
e
β˜1] = βb1±z(.975)sceβb = .290±1.96(.046) = [.20,
where sceβb =
1
1
√
.38]
.0021 = .046 .
17 - 18
Standard Errors and Confidence Intervals for
Quantities at Specific Explanatory Variable Conditions
• Unknown values of µ and σ at each level of x
b = βb0 + βb1x, σ does not depend on x, and
• µ
Σ̂µb,σb =
"
d µ)
b
Var(
d µ,
b σ
b)
Cov(
d µ,
d σ
b σ
b ) Var(
b)
Cov(
#
d µ)
d βb )+2xCov(
d βb , βb )+x2Var(
d βb )
b = Var(
is obtained from Var(
0
1 0
1
d µ,
d βb , σ
d b b ).
b σ
b ) = Cov(
and Cov(
0 b ) + xCov(β1 , σ
• Use the above results with the methods from Chapter 8
to compute normal-approximation confidence intervals for
F (t), h(t), and tp.
• Could also use likelihood or simulation-based confidence intervals.
17 - 19
Log-Quadratic Weibull Regression Model with
Constant (β = 1/σ) Fit to the Fatigue Data
b
b , x = log(pseudo-stress)
log[tbp(x)] = µ(x)
+ Φ−1
sev (p)σ
b = βb0 + βb1x + βb2x2
µ
500
Thousands of Cycles
•
100
•••
• •
50
•
•
10
•
•
•••
••
••
5
• 90%
•• 50%
10%
1
60
80
100
120
140
160
Pseudo-stress (ksi)
17 - 20
Weibull Distribution Quadratic Regression Model
with Constant Shape Parameter β = 1/σ
This is an AF time model with the following characteristics:
• The Weibull quadratic regression model is
Pr[T ≤ t] = Φsev {[log(t) − µ]/σ}
where µ = µ(x) = β0 + β1x + β2x2 and σ does not depend
on x.
• The failure-time log quantile function
log[tp(x)] = µ(x) + Φ−1
sev (p)σ
is quadratic in x. Also
tp(x) = exp(β1x + β2x2) × tp(0)
which shows that the model is an SAFT model.
17 - 21
Likelihood for Weibull Distribution Quadratic
Regression Model with Right Censored Data
The likelihood for n independent observations has the form
L(β0, β1 , β2, σ) =
=
n
Y
Li (β0, β1, β2 , σ; datai )
i=1
n Y
i=1
δi 1−δi
log(ti ) − µi
log(ti ) − µi
1
φsev
1 − Φsev
.
σti
σ
σ
where µi = β0 + β1xi + β2x2
i,
δi =
(
1
0
exact observation
right censored observation
The parameters are θ = (β0, β1, β2, σ).
17 - 22
Log-quadratic Weibull Regression Model with
Nonconstant β = 1/σ Fit to the Fatigue Data
b (x) x = log(pseudo-stress)
b
log[tbp(x)] = µ(x)
+ Φ−1
sev (p)σ
[σ]
[σ]
b = βb0 + βb1x + βb2x2, log(σ
b ) = βb0 + βb1 x.
µ
500
Thousands of Cycles
•
100
•••
• •
50
•
•
10
•
•
•••
••
••
5
• 90%
50%
•• 10%
1
60
80
100
120
140
160
Pseudo-stress (ksi)
17 - 23
Weibull Distribution Quadratic Regression Model
with Nonconstant β = 1/σ
• The Weibull quadratic regression model is
Pr[T ≤ t] = Φsev {[log(t) − µ]/σ} ,
[µ]
[µ]
[µ]
where µ = µ(x) = β0 + β1 x + β2 x2 and
[σ]
[σ]
log(σ) = log[σ(x)] = β0 + β1 x.
• The failure-time log quantile function is
log[tp(x)] = µ(x) + Φ−1
sev (p)σ(x)
which is not quadratic in x.
Also
i
−1
tp(x) = exp [µ(x) − µ(0)] exp Φsev (p) {σ(x) − σ(0)} × tp(0).
h
Because the coefficient in front of tp(0) depends on p this
shows that the model is not an SAFT model.
17 - 24
Likelihood for Weibull Distribution Quadratic
Regression Model with Nonconstant β = 1/σ
and Right Censored Data
The likelihood for n independent observations has the form
[µ]
[µ]
[µ]
[σ]
[σ]
[µ]
[µ]
[µ]
[σ]
L(β0 , β1 , β2 , β0 , β1 )
=
n
Y
[σ]
Li(β0 , β1 , β2 , β0 , β1 ; datai)
i=1
n (
Y
"
log(ti) − µi
1
φsev
=
σi
i=1 σi ti
#)δ (
i
"
log(ti) − µi
1 − Φsev
σi
#)1−δ
[µ]
[µ]
[µ] 2
[σ]
[σ]
where µi = β0 + β1 xi + β2 xi and σi = exp β0 + β1 xi .
[µ]
[µ]
[µ]
[σ]
[σ]
Parameters are θ = (β0 , β1 , β2 , β0 , β1 ).
17 - 25
i
.
Days
Stanford Heart Transplant Data
Quadratic Log-Mean Lognormal Regression Model
10
5
10
4
10
3
10
2
10
1
10
0
•
•
•
•
•
•
•
•
•• •
•• •
• • •• • ••• •• •••• • •
•
•• •••
•
•
•
• •• • ••• •••• •
• • •••• ••• •
•
• ••••
• •••••••••••••••••
•
•
•
•
•
•
•
•
•
•
•
90%
••
50%
10%
-1
10
10
20
30
40
50
60
70
Years
17 - 26
Days
Stanford Heart Transplant Data
Quadratic Log-Location Weibull Regression Model
10
5
10
4
10
3
10
2
10
1
10
0
•
•
•
•
•
•
•
•
•• •
•• •
• • •• • ••• •• •••• • •
•
•• •••
•
•
•
• •• • ••• •••• •
• • •••• ••• •
•
• ••••
• •••••••••••••••••
•
•
•
•
•
•
•
•
•
•
•
••
90%
50%
10%
-1
10
10
20
30
40
50
60
70
Years
17 - 27
Extrapolation and Empirical Models
• Empirical models can be useful, providing a smooth curve
to describe a population or a process.
• Should not be used to extrapolate outside of the range of
one’s data.
• There are many different kinds of extrapolation
◮ In an explanatory variable like stress
◮ To the upper tail of a distribution
◮ To the lower tail of a distribution
• Need to get the right curve to extrapolate: look toward
physical or other process theory
17 - 28
Checking Model Assumptions
• Graphical checks using generalizations of usual diagnostics
(including residual analysis)
◮ Residuals versus fitted values.
◮ Probability plot of residuals.
◮ Other residual plots.
◮ Influence analysis (or sensitivity) analysis.
(see Escobar and Meeker 1992 Biometrics).
• Most analytical tests can be suitably generalized, at least
approximately, for censored data (especially using likelihood
ratio tests).
17 - 29
Definition of Residuals
• For location-scale distributions like the normal, logistic, and
smallest extreme value,
yi − ybi
ǫbi =
b
σ
where ybi is an appropriately defined fitted value (e.g., ybi =
b i).
µ
• With models for positive random variables like Weibull, lognormal, and loglogistic, standardized residuals are defined
as
exp(ǫbi) = exp
"
#
log(ti) − log(t̂i)
=
b
σ
!1
ti bσ
t̂i
b i) and when ti is a censored observation,
where t̂i = exp(µ
the corresponding residual is also censored.
17 - 30
Plot of Standardized Residuals Versus Fitted Values
for the Log-Quadratic Weibull Regression Model Fit
to the Super Alloy Data on Log-Log Axes
Standardized Residuals
5.000
•
2.000
1.000
0.500
•
•
••
••
•
•
•
•
0.200
0.100
0.050
•
••
•
•
••
•
•
•
0.020
0.010
0.005
0.002
0.001
•
5
10
20
50
100
200
500
Fitted Values
17 - 31
Probability Plot of the Standardized Residuals from
the Log-Quadratic Weibull Regression Model
Fit to the Super Alloy Data
.98
.9
.7
Probability
.5
.3
.2
•
.1
•
•
•••
•
•
•
•
•••
•
•••
•
•
•
•
.05
.03
•
.02
.01
0.001
0.005
0.020
0.050
0.200
0.500
2.000
5.000
Standardized Residuals
17 - 32
Empirical Regression Models
and Sensitivity Analysis
Objectives
• Describe a class of regression models that can be used to
describe the relationship between failure time and explanatory variables.
• Describe and illustrate the use of empirical regression models.
• Illustrate the need for sensitivity analysis.
• Show how to conduct a sensitivity analysis.
17 - 33
Picciotto Yarn Failure Data
(Picciotto 1970)
• Cycles to failure on specimens of yarn of different lengths.
• Subset of data at particular level of stress and particular
specimen lengths (30mm, 60mm, and 90mm)
• Original data were uncensored. For purposes of illustration,
the data censored at 100 thousand cycles.
• Suppose that the goal is to estimate life for 10 mm units.
17 - 34
Picciotto Yarn Failure Data
Showing Fraction Failing at Each Length
200
Thousands of Cycles
22/99
71/99
92/100
100
50
20
10
20
40
60
80
100
Length
17 - 35
Picciotto Yarn Failure Data
Multiple Weibull Probability Plot
with Weibull ML Estimates
Subset of Piccioto Yarn Fatigue Data
With Individual Weibull MLE’s
Weibull Probability Plot
.98
30
60
90
.9
.7
.5
Probability
.3
.2
.1
.05
.03
.02
.01
.005
.003
20
40
60
80
100
Thousands of Cycles
17 - 36
Picciotto Yarn Failure Data
Multiple Lognormal Probability Plot
with Lognormal ML Estimates
Subset of Piccioto Yarn Fatigue Data
With Individual Lognormal MLE’s
Lognormal Probability Plot
.95
30
60
90
.9
.8
Probability
.7
.6
.5
.4
.3
.2
.1
.05
.02
.01
.005
.002
20
40
60
80
100
Thousands of Cycles
17 - 37
Suggested Strategy for Fitting Empirical Regression
Models and Sensitivity Analysis
• Use data and previous experience to choose a base-line
model:
◮ Distribution at individual conditions
◮ Relationship between explanatory variables and distributions at individual conditions
• Fit models
• Use diagnostics (e.g., residual analysis) to check models
• Assess uncertainty
◮ Confidence intervals quantify statistical uncertainty
◮ Perturb and otherwise change the model and reanalyze
(sensitivity analysis) to assess model uncertainty.
17 - 38
Picciotto Yarn Failure Data
Multiple Lognormal Probability Plot with
Lognormal ML Log-Linear Regression Model
Estimates
Subset of Piccioto Yarn Fatigue Data
with Lognormal log Model MLE
Lognormal Probability Plot
.99
.98
30
60
90
10
.95
Probability
.9
.8
.7
.6
.4
.3
.2
.1
.05
.02
.005
.001
5
10
20
50
100
200
500
1000
2000
Thousands of Cycles
17 - 39
Scatter Plot of the Picciotto Yarn Failure Data
with Lognormal ML Log-Linear Regression Model
Estimate Densities
b
log[tbp(x)] = βb0 + βb1 log (Length) + Φ−1
nor (p)σ
Subset of Piccioto Yarn Fatigue Data
2000
Thousands of Cycles
1000
500
200
100
90%
50
50%
10%
20
10
4
8
12
20
40
60
100
Length on log scale
17 - 40
Picciotto Yarn Failure Data
Log-Linear Model Residual vs Fitted Values Plot
Subset of Piccioto Yarn Fatigue Data
Residuals versus Fitted Values
5.00
Standardized Residuals
2.00
1.00
0.50
0.20
0.10
0.05
0.02
40
60
80
100
120
140
Fitted Values
17 - 41
Picciotto Yarn Failure Data
Multiple Lognormal Probability Plot with
Lognormal ML Squareroot-Linear Regression Model
Estimates
Subset of Piccioto Yarn Fatigue Data
with Lognormal sqrt Model MLE
Lognormal Probability Plot
.99
.98
30
60
90
10
.95
Probability
.9
.8
.7
.6
.4
.3
.2
.1
.05
.02
.005
.001
5
10
20
50
100
200
500
1000
2000
Thousands of Cycles
17 - 42
Scatter Plot of the Picciotto Yarn Failure Data
with Lognormal ML Squareroot-Linear Regression
Model Estimate Densities
√
b
b
b
b
log[tp(x)] = β0 + β1 Length + Φ−1
nor (p)σ
Subset of Piccioto Yarn Fatigue Data
2000
Thousands of Cycles
1000
500
200
100
90%
50
50%
20
10%
10
0
20
40
60
80
100
Length on sqrt scale
17 - 43
Picciotto Yarn Failure Data
Squareroot-Linear Model
Residual vs Fitted Values Plot
Subset of Piccioto Yarn Fatigue Data
Residuals versus Fitted Values
5.00
Standardized Residuals
2.00
1.00
0.50
0.20
0.10
0.05
0.02
40
60
80
100
120
140
Fitted Values
17 - 44
Examples of Monotone Increasing
Power Transformations of a
Positive Explanatory Variable
λ
−2
−1
−.5
−.333
0
.333
.5
Transformation
x∗i = −1/x2
i
x∗i = −1/xi
√
x∗i = −1/ xi
1/3
x∗i = −1/xi
def
x∗i = log(xi)
1/3
x∗i = xi
√
x∗i = xi
1
x∗i = xi
2
x∗i = x2
i
17 - 45
Box-Cox Transformation
• The Box-Cox family of power transformations of a positive
explanatory variable is
λ
xi −1
λ 6= 0
λ
∗
xi =
log(xi) λ = 0
where xi is the original, untransformed explanatory variable
for observation i and λ is the power transformation parameter.
• The Box-Cox transformation has the following properties:
◮ The transformed value x∗i is an increasing function of xi.
◮ For fixed, xi, x∗i is a continuous function of λ through 0.
17 - 46
Picciotto Yarn Failure Data
Relationship Sensitivity Analysis
for the 0.1 Quantile at Length 30 mm
0.1 Quantile of Life in Thousands of Cycles
Subset of Piccioto Yarn Fatigue Data
with Lognormal Length:log at 30
Power Transformation Sensitivity Analysis on Length
90
ML estimate of the 0.1 quantile
95% Pointwise confidence intervals
85
80
75
70
65
60
55
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
Box-Cox Transformation Power
17 - 47
Picciotto Yarn Failure Data
Relationship Sensitivity Analysis
for the 0.1 Quantile at Length 10 mm
0.1 Quantile of Life in Thousands of Cycles
Subset of Piccioto Yarn Fatigue Data
with Lognormal Length:log at 10
Power Transformation Sensitivity Analysis on Length
20000
ML estimate of the 0.1 quantile
95% Pointwise confidence intervals
10000
5000
2000
1000
500
200
100
50
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
Box-Cox Transformation Power
17 - 48
Picciotto Yarn Failure Data
Profile Plot for Different Box-Cox Parameters
for the Length Relationship
Profile Likelihood and 95% Confidence Interval
for Box-Cox Transformation Power from the Lognormal Distribution
Profile Likelihood
0.8
0.50
0.60
0.6
0.70
0.80
0.4
0.90
Confidence Level
1.0
0.2
0.95
0.99
0.0
-1.0
-0.5
0.0
0.5
1.0
1.5
Box-Cox Transformation Power
17 - 49
Picciotto Yarn Failure Data
Relationship Sensitivity Analysis
0.1, 0.5, 0.9 Quantiles at 10 mm Length
Quantile of Life in Thousands of Cycles
Subset of Piccioto Yarn Fatigue Data
with Lognormal Length:log at 10
Power Transformation Sensitivity Analysis on Length
50000
Lognormal:0.1 quantile
Lognormal:0.5 quantile
Lognormal:0.9 quantile
20000
10000
5000
2000
1000
500
200
100
50
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
Box-Cox Transformation Power
17 - 50
Picciotto Yarn Failure Data
Relationship/Distribution Sensitivity Analysis
0.1 Quantile at 10 mm Length
0.1 Quantile of Life in Thousands of Cycles
Subset of Piccioto Yarn Fatigue Data
with Length:log at 10
Power Transformation Sensitivity Analysis on Length
10000
lognormal:0.1 quantile
weibull:0.1 quantile
5000
2000
1000
500
200
100
50
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
Box-Cox Transformation Power
17 - 51
Glass Capacitor Failure Data
• Experiment designed to determine the effect of voltage and
temperature on capacitor life.
• 2 × 4 factorial, 8 units at each combination.
• Test at each combination run until 4 of 8 units failed (Type
II censoring).
• Original data from Zelen (1959).
17 - 52
Scatter Plot the Effect of Voltage and Temperature
on Glass Capacitor Life
(Zelen 1959)
1200
170 Degrees C
180 Degrees C
1000
Hours
800
600
400
200
0
200
250
300
350
Volts
17 - 53
Weibull Probability Plots of Glass Capacitor Life Test
Results at Individual Temperature and Voltage Test
Conditions
.999
170;200
170;250
170;300
170;350
180;200
180;250
180;300
180;350
.98
.9
.7
Proportion Failing
.5
.3
.2
.1
.05
.03
.02
.01
.005
.003
100
200
500
1000
2000
Hours
17 - 54
Two-Variable Regression Models
• Additive model
log[tp(x)] = yp(x) = β0 + β1x1 + β2x2 + Φ−1(p)σ.
Because
tp(x) = exp [yp(x)] = exp(β1x1 + β2x2) tp(0)
this is an SAFT model
• The interaction model
log[tp(x)] = yp(x) = β0 + β1x1 + β2x2 + β3x1x2 + Φ−1(p)σ.
is also SAFT.
• Comparing the two models gives
−2 × (L1 − L2) = −2 × (−244.24 + 244.17) = 0.14
which is small relative χ2
.95,1 = 3.84
17 - 55
Weibull Probability Plots with Weibull Regression
Model ML Estimates of F (t) at each Set of Conditions
for the Glass Capacitor Data
.999
.98
170 Deg C, 200 V
170 Deg C, 250 V
170 Deg C,300 V
170 Deg C, 350 V
180 Deg C, 200 V
180 Deg C, 250 V
180 Deg C, 300 V
180 Deg C, 350 V
.9
.7
Proportion Failing
.5
.3
.2
.1
.05
.03
.02
.01
.005
.003
100
200
500
1000
Hours
17 - 56
Estimates of Weibull t0.5 Plotted for each Combination
of the Glass Capacitor Test Conditions
Points are Estimates Regression–Model Free
1400
1200
1000
170 Degrees C
Hours
800
600
400
180 Degrees C
200
200
220
240
260
280
300
320
340
360
Volts
17 - 57
The Proportional Hazard Failure Time Model
The proportional hazard (PH) model assumes
h(t; x) = Ψ(x)h(t; x0),
for all t > 0.
h(t; x0) and F (t; x0) denote the baseline hazard function
and cdf of the model.
The PH model implies (some details later):
• S(t; x) = [S(t; x0)]Ψ(x) or 1 − F (t; x) = [1 − F (t; x0)]Ψ(x).
If Ψ(x) 6= 1, F (t; x) and F (t; x0) do not cross and the model
is accelerating if Ψ(x) > 1 and decelerating if Ψ(x) < 1.
• From 1−F (t; x) = [1−F (t; x0)]Ψ(x) and taking logs (twice):
log {− log [1 − F (t; x)]}−log {− log [1 − F (t; x0)]} = log [Ψ(x)] .
Thus in a Weibull probability scale F (t; x) and F (t; x0)
are equidistant. In particular, Weibull plots of F (t; x) and
F (t; x0) are translation of each other along the probability
axis.
17 - 58
Weibull Probability Plot of Two Members from a
PH Model with a Baseline Lognormal Distribution
.999
.98
∆
.9
.7
.5
Probability
.3
.2
∆
.1
.05
.03
.02
.01
.005
.003
.001
1
5
10
50
100
Time
17 - 59
Proportional Hazard Model (Lognormal Baseline)
as a Time Transformation
3.0
decelerating
proportional
hazards
Time at Level x
2.5
2.0
1.5
1.0
accelerating
proportional
hazards
0.5
0.0
0.0
0.5
1.0
1.5
2.0
2.5
3.0
Time at Level x0
17 - 60
Interpreting PH Models as a
Failure Time Transformation.
Suppose that T (x0) ∼ F (t; x0) and define the time transformation:
T (x) = F −1 1 − {1 − F [T (x0); x0
1
]} Ψ(x)
!
; x0 .
It can be shown that:
• T (x) and T (x0) follow the PH relationship
h(t; x) = Ψ(x)h(t; x0).
• T (x) is a monotone transformation of T (x0) such that
T (x) < T (x0)
if
Ψ(x) > 1,
accelerating
T (x) = T (x0)
if
Ψ(x) = 1,
identity transform
T (x) > T (x0)
if
Ψ(x) < 1,
decelerating
17 - 61
Some Comments on the
Proportional Hazard Failure Time Model
Here we consider the proportional hazards, PH, model
h(t; x) = Ψ(x)h(t; x0),
for all t > 0.
• In general, the PH model does not preserve the baseline
distribution. For example, if T (x0) has a lognormal distribution then T (x) has a power lognormal distribution.
• The semiparametric model without a particular specification
of h(t; x0) is known as Cox’s proportional hazards model.
17 - 62
Weibull Probability Plot of Two Members from a
PH/SAFT Model with a Baseline Weibull Distribution
.999
.98
.9
.7
.5
∆1
Probability
.3
∆2
.2
.1
.05
.03
.02
∆1
∆2
.01
.005
.003
.001
1
5
10
50
100
Time
17 - 63
Contrasting SAFT and PH Models
The scale failure time model tp(x) = tp(x0)/Ψ(x) and the
PH model h(t; x) = Ψ(x)h(t; x0) are equivalent if only if the
baseline distribution is Weibull.
In other words, the Weibull distribution is the only baseline
distribution for which a SAFT model is also a a PH model,
and vice versa.
Heuristic argument: Consider F (t; x1) and F (t; x2). The
Weibull probability plots of these two cdfs are translation
of each other in both the probability and the log(t) scale if
and only if the plots are straight parallel lines.
17 - 64
Statistical Methods for the
Semiparametric (Cox) PH Model
Data: n units, t(1), . . . , t(r) ordered failure times with n − r
censored observations (usually multiply censored).
• RS i = RS(t(i) − ε) is the risk set just before the failure at
time t(i).
• Each unit has a vector xi of explanatory variables (often
called covariates).
17 - 65
Cox PH Model Likelihood (Probability of the Data)
• The probability that individual i dies in [t, t + ∆t] is
h(t; xi)∆t = h(t; x0)∆tΨ(xi) = h(t; x0) exp(x′iβ )∆t
where Ψ(xi) = exp(x′iβ ) = exp(β1x1 +· · ·+βk xk ) and x0 = 0
• If a death occurs at time t, the probability that it was individual i is
exp(x′iβ )
h(t; xi)∆t
=P
Li = P
′
h(t;
x
)∆t
ℓ
ℓ∈RS i
ℓ∈RS i exp(xℓ β )
• Conditional on the observed failure times, the joint probability of the data is
r
Y
exp(x′iβ )
L(β ) =
P
′ β)
exp(
x
ℓ∈RS
ℓ
i=1
i
• Need mild conditions on xi and the censoring mechanism.
17 - 66
Comments on the Cox PH Model Likelihood
• Cox (1972) called L(β ) a conditional likelihood.
• L(β ) is not a true likelihood, but there is justification for
treating it as such.
• With no censoring, Kalbfleisch and Prentice (1973) show
that L(β ) can be justified as a marginal likelihood based on
ranks of the observed failures. Argument can be extended
to Type II censoring.
• Cox (1975) provided a partial likelihood justification.
• Asymptotic theory shows that the estimates obtained from
maximizing L(β ) have high efficiency.
• There are some technical difficulties when there are ties
observations. Approximations for L(β ) generally used.
17 - 67
Estimating h(t; x0) [or S(t; x0) or F (t; x0)]
b for β and maximize the prob• Basic idea is to substitute β
ability of the data (after adjustment for the explanatory
variables), as in the product limit estimator.
• Let qi = S(ti + ε; x0), i = 1, . . . , r for the r failure times and
let qj = S(tj + ε; x0), j = r + 1, . . . , n for the n − r censored
observations. If there are no ties among the failure times,
Y
r b
n
Y
b xj )
b
Ψ(
Ψ(xi )
Ψ(xi )
L(q ) =
qi−1 − qi
qj−1
i=1
j=r+1
b
c x ) = exp(x′ β
where Ψ(
i
i ) and q0 ≡ 1.
• Maximize L(q ) with respect to qi, i = 1, . . . , r to get the
step-function estimate of S(t; x0).
b
b
b
• Estimate of S(t) at x is S(t;
x) = [S(t;
x0]Ψ(x).
• Setup more complicated when there are ties.
17 - 68
Picciotto Yarn Failure Data
Cox PH Model Survival Estimates
(Linear Axes)
1.0
90 mm
0.8
Probability
60 mm
0.6
0.4
30 mm
0.2
0.0
0
50
100
150
200
Thousands of Cycles
17 - 69
Picciotto Yarn Failure Data
Cox PH Model Survival Estimates
(on Weibull Probability Scales)
.98
90 mm
.9
60 mm
.7
Proportion Failing
.5
.3
30 mm
.2
.1
.05
.03
.02
.01
.005
.003
5
10
20
50
100
200
Thousands of Cycles
17 - 70
••
••• ••••
•••••••••• •••••
• •
•••
•• ••
••••••
•
•
• ••• •••••
•• •
• •••
••
• ••
•
•
•
•
•••
•
••
• •
•
•• •
•
• •
•••
•• •• • •••••
••• • •
••
-0.6
-0.4
-0.2
0.0
•
•••
••
-0.8
Shoenfield Residuals
0.2
0.4
Picciotto Yarn Failure Data
Cox PH Model Schoenfeld Residuals versus Time
•
•••
•
•
•
•
•
• •
•••
•
•
20
40
60
80
100
Thousands of Cycles
17 - 71
General Failure Time Transformation Graph
3.0
accelerating and
decelerating
transformation
Time at Level x
2.5
decelerating
transformation
2.0
1.5
1.0
0.5
accelerating
transformation
0.0
0.0
0.5
1.0
1.5
2.0
2.5
3.0
Time at Level x0
17 - 72
General Failure Time Transformation Model
A general time transformation model is
T (x) = Υ [T (x0), x]
where x0 are some baseline conditions.
We assume that Υ (t, x) satisfies the following conditions:
• Υ (t, x) is nonnegative, i.e., Υ (t, x) ≥ 0 for all t and x.
• For fixed x, Υ (t, x) is monotone increasing in t.
• For all x, Υ (0, x) = 0.
• For x0 the transformation is the identity transformation,
i.e., Υ (t, x0) = t for all t.
17 - 73
General Failure Time Transformation Model
This general assumed transformation model implies:
• The distribution of T (x) can be determined from the distribution of T (x0) and x. In particular, tp(x) = Υ [tp(x0), x]
for 0 ≤ p ≤ 1.
• In a plot of T (x0) versus T (x)
◮ T (x) entirely below the diagonal line implies acceleration.
◮ T (x) entirely above the diagonal line implies deceleration.
◮ Other T (x)s imply acceleration sometimes and deceleration other times. The cdfs of T (x) and T (x0) cross.
◮ Scale time transformations and proportional hazard model
are special cases.
17 - 74
Other Topics in Failure-Time Regression
• Models with non-location-scale distributions.
• Nonlinear relationship regression model.
• Fatigue-limit regression model.
• Special topics in regression: random effects models, nonparametric SAFT regression models, parametric PH regression models.
17 - 75