Chapter 4 Statistics
advertisement

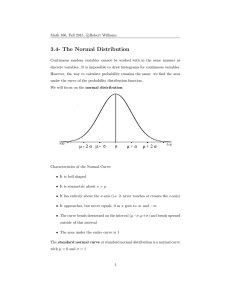
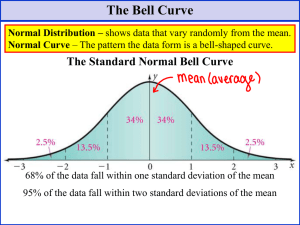
Chapter 4 Statistics Problems 3, 6, 8, 12, 14*, 16*, 17* * long problems appropriate for a take-home test Going to break slightly from the text here. I have some statistics I want to add so pay attention 4-1 Gaussian Distribution In the last chapter we talked about indeterminate or random error. This is the +/error that remains in your data once you have cleaned up your technique as much as possible. Since you can’t get rid of this kind of error, you must deal with it in some other way, and that is statistics. The statistics we will work with are based on the fact that random error has a ‘normal’ or Gaussian distribution I. RANDOM CURVE : is the actual center of the distribution F is the standard deviation of the population x-: is the deviation from the mean 2 You don’t need to memorize the above equation. It is important, since it means that it is a well defined mathematical function, and as such, mathematicians can analyze it and derive statistics based on it, but we will work just with the results of this analysis, the proven statistics, rather than worry about the theory of the Gaussian curve. If you look at the above equation you will see two key parameters; : and F . These represent the true center and the width of the distribution respectively. If you have an infinite amount of data you can plot the data to get a distribution cure, and then fit that curve mathematically to the normal curve to find out what : and F actually are. However, in real life you only have time to do a few experiments, and you must estimate this values using quick and dirty statistics. That is what this chapter is all about. DESCRIPTIVE STATISTICS II. Where is the center? A. MEAN - average - Not in the text B. Median - the middle number in a distribution C. Mode - The number that occurs most often in a distribution III. How wide is the distribution? A. STANDARD DEVIATION This is also frequently used and statistically very significant. Think back to random curve ±1 s contains 68.26% of values, ±2 contains 95.46%, ±3 contains 99.75% of values. 3 Not in the text I. Sometimes I use Relative Standard deviation, or Coefficient of Variance Useful in the lab because you can see how wide the distribution is compared to the mean. 4-2 Student’s t The student’s t is a way of evaluating the width of a distribution that has several useful forms. Let’s start with Confidence Intervals We just talked about how the number of determinations makes an estimate of the mean more reliable. This concept is integrated into a statistic called the confidence interval that tells you the statistical range of a given value. If you calculate a mean and a standard deviation you can give an answer x±s and say this is your confidence level, and guess that your answer is right about 68% of the time based on the random curve. But your confidence in n and s changes as you get more samples, and you would like to include this factor in your interval. Further you may not like a 68% confidence interval, and might like to use some other confidence level like 99 or 95% Gosset studied this problem and came up with the t statistic. We use it to evaluate a confidence interval with the following equation: where x, s, and n have the standard meanings and t is found in a table like the one on page 78 of your book. EXAMPLE You run an experiment and get the following four results of the amount of aspirin in a 200 mg pill 199.6 195.2 202.1 198.6 x = 198.88, s=2.86, n=4 If you want to say, with 99% certainty, that the true content of aspirin in the pills is between two values, what would those values be? From Table 4.2 4 First, what are the degrees of freedom? (N-1 = 3) in the table look up the t for 99% confidence and 3 degrees of freedom t=5.841 So you see to have 99% confidence in your answer you have to put very high error bars on your measurement when you only have a few samples. You might take this example and, assuming the x and s remain the same, see how many pills you would need to analyze before you could confidently say the manufacturer was cutting corners and putting out a defective product. Improving Reliability Say you have a distribution with a mean of 100 and a standard deviation of 10 The above confidence interval say that if I do 3 experiments (d.f.=2) then 90% of the time my answers will be between 84 and 116 := 16.8 ; = 2.92(10)/sqrt(3) Or, turning this around, based on my three experiments I can only guess that the mean is somewhere between 84 and 116. This is a very large range. How can I improve my guess at the mean? Do MORE experiments This has two effects SQRT(n) in denominator increases, lowering range as n increases, d.f. increases and decreases the numerator Let’s see what doubling the number of measurements does (n=6) : = 2.015(10)/sqrt(6) = 8.226 so now my guess range is from 92-108 so I have almost cut the range in half. In fact my range is LOWER than my standard deviation! Bottom line always do as many experiments as possible Comparisons of Means with Student’s t Say you do two experiments on the same sample with different methods, and get slightly different results. Say, for instance, We have a second spectroscopic method for determined aspirin, and it gives us slightly different results. At what point do you say that the two results are significantly different This is a statistically tough question because you are comparing two random distributions, and you need to know it the centers of the distributions(means) are the same as well as the width of the distributions(s). 5 To use the T statistic you first need to find a ‘pooled’ s value STEP 2 COMPARING THE MEANS Means can then be compared using the t-test. T-test for equivalent distributions: Compare the derived t to the table t. If t > table t, the data set are significantly different. Note: when you look up t here the degrees of freedom = n1 +n2 -2 EXAMPLE We do our spectroscopic method and get the following results: 198.5 196.8 203.6 198.7 199.2 x=199.36 s=2.54 n=5 spooled=sqrt((2.862(3) + 2.542(4))/(4+5-2)) =sqrt(24.54+25.81)/7) =2.68 T calc=.267 T table = 2.365 for the 95% confidence level, so the samples are 6 not significantly different. There are other uses of the T not given in this text. If you take an advanced statistics course don’t be surprised to find oterh applications of this useful calculation. 4-3 The Q test for bad data Occasionally you will have a bad data point. If you can think of something that went wrong in that experiment you are free to throw that data out. If there were no problems, however, you usually keep the bad data. The Q test is a statistic that allows you to decide if a data point is really bad and need to be thrown out anyway. 1. find the difference between the bad point and its nearest neighbor(GAP) 2. find the total range of the data 3. Q = gap/range 4. compare calculated Q to the table Q (Q table in book is table 4-6 page 71) 5. if Q calc > Q table you may reject the data EXAMPLE Carrying on with previous experiment, we get a 6th value of 187.7 mg can this value be rejected? Q calc=.572 ; Q table = 0.56 the value may be rejected Note that our table is based on a 90% confidence interval, thus when you use this test you will be wrong 10% of the time! Also note that common sense rules. If you remember that you spilled, or your lab partner spit in it, go ahead and throw it out (and get rid of the lab partner). 4-4 Fitting the “best” straight line Many times you will see data that contains correlated pairs of points, say response to a given concentration of drug, or absorbance of radiation vs concentration. It is usually easiest to see the correlation if the data is plotted in 2 dimensions ie. 7 When you plot the data you get some scatter in the points. How do you select the best line? LEAST SQUARES Remember that the equation for a line is y=mx+b In least squares you go through many equations and eventually derive values for m (slope),and intercept (b). You then will use this line to calculate values of y corresponding to some experimental value of x. The equations for doing these calculations are not the kind of thing I expect you to memorize. Indeed most of you probably have calculators where all you have to do is plug in the values hit a few appropriate keys and it will give you an answer. The equations though, aren’t that hard 8 . I won’t have you memorize and use these on an in class test, but this would be appropriate for use in a take home test. Notice that with all the math manipulation this is an ideal problem to throw at a spread sheet. I would try to do that, make up a general spreadsheet that does a least squared fit of a set of data. To check if your calculations are right you can use the spreadsheets built in line fitting routines and see if your answers are the same. Once you have a working least squares spreadsheet keep it for future use. One thing most of you calculators don’t do is give you a estimate of the error in your line. What is the uncertainty in your intercept and in your slope, and when you combine these uncertainties, what is the uncertainty in any data you fit to this line. In deriving the uncertainty of the line the first thing we do is to assume that our X values are exactly correct and that all the uncertainty in a given point lines in its y value. The first step in the error analysis of a line is to determine the standard deviation of the Y values. To do this we use our line of best fit to calculate a theoretical value for each X point and Once we have this uncertainty then (Uncertainty in slope) 9 and (Uncertainty in intercept) Where D = nE(xi2) -(Exi)2 Again these equations are too complicated to memorize, but be able to use them on homework assignments and in the lab. Now let’s say we have some data, say we have analyzed the absorbance of a protein at several concentrations and have determined that the line of best fit had the form Y (absorbance) = .0163 X (Concentration in :g) + .104 And through the above analysis we find that sm = .00022 sb = .0026 sy = .0059 If we measure the absorbance of an unknown sample and finds it has an absorbance of 0.246, what protein concentration does this correspond to and what is the uncertainty in our answer. Well the first part is easy .246= .0163(X) + .104 (.246 -.104) /.0163 = X The last equation is (y-b)/m =x At this point you should be able to think about propagation of error and work your way through the problem [(.246±.0059)-(.104±.0026)]/(.0163±.00022) and come up with an answer. The answer you get is actually not right because it assume that the error in slope are independent of each other, But as you saw earlier they are actually both calculated form the uncertainty in y. The real equation you should use for any x is: 10 You are well advised not to worry about this equation unless you have time to set it up on a spreadsheet on your computer. A final word here Never plug you numbers in to a calculator or computer without first plotting them and looking at the data critically. (Using the computer to plot simultaneously is OK) Looking at the data tells you many things. Do I have a bad data point, is the data actually linear etc. Don’t plug in without thinking first. 4-5 Calibration Curves In the previous section we looked at the math of how to calculate a calibration curve, not let’s look at the practical aspects. You need to make a set of solutions called standard solutions that contain known concentrations of the analyte molecules, as well as all the other reagents added to do the analysis. You also need one or more blank solutions that contain zero amount of the analyte, but all the other reagents. Blank solutions are used as a control to monitor impurities or interferences that may be present in your sample. Table 4-6 contains data used in making a calibration curve. Note that we have several determinations at each concentration, as well as a range of several different concentrations designed to cover the entire range of concentrations we expect to see in our assay. Why do we have several values a each concentration? Well the table illustrates how you can have a single bad value, and having repetitive data sets allows you to throw the bad value out, so it doesn’t foul up the analysis. Also notice how he has averages the blank values together, and subtracted this value form all the other values to make a ‘corrected value’ that compensates for a nonzero blank. As shown in figure 4-7 the data is not linear throughout the entire concentration range. It is preferred that you always so sample withing the liner range, because all the equations that we just went through in 4-4 can be applied in this range. If you cannot work in the linear range, you can use your computer to fit the data to a nonlinear equation but we won’t worry about that extreme in this course. I don’t want to belabor the propagation of uncertainty in the calibration curve. Just be aware that because you have uncertainty in both slope and intercept, the uncertainty is worse at the ends of your calibration curve 11 4-6 A spreadsheet We will do this in lab where it will bring all of the least squared calculations into one place for you and give you valuable practice on working with spreadsheets