Segmentation INF 5300, V-2004 Selected Themes
advertisement

Segmentation
INF 5300, V-2004
Selected Themes
from Digital Image Analysis
• Segmentation is one of the most important
components of a complete image analysis
system.
• Segmentation creates regions and objects
in images.
Lecture 1
• There are two categories of methods,
based on two different principles,
namely similarity and discontinuity.
Monday 16.02.2004
• In region based segmentation
we find those pixels that are similar.
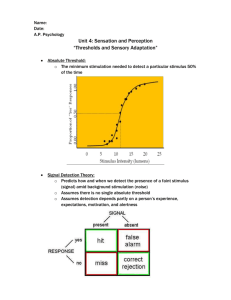
Segmentation by Thresholding
• Thresholding splits the image histogram.
Pixels belonging to same class get same
label. These pixels are not necessarily
neighbours.
Fritz Albregtsen
• In edge based segmentation we find the
basic elements of edges, i.e. edge- pixels
(or even line-pixels, corner-pixels etc),
based on local estimates of gradient.
In the next steps we thin broad edges, join
edge fragments together into edge chains.
Then we have a (partial) region border.
Department of Informatics
University of Oslo
INF 5300, 2004, Lecture 1, page 1 of 21
INF 5300, 2004, Lecture 1, page 2 of 21
Introduction to Thresholding
• Automatic thresholding is important in
applications where speed or the physical
conditions prevent human interaction.
• In bi-level thresholding, the histogram of
the image is usually assumed to have one
valley between two peaks, the peaks
representing objects and background,
respectively.
• Thresholding is usually a pre-process for
various pattern recognition techniques.
• Thresholding may also be a pre-process for
adaptive filtering, adaptive
compression etc.
INF 5300, 2004, Lecture 1, page 3 of 21
Parametric versus Non-parametric
• Parametric techniques:
— Estimate parameters of two
distributions from given histogram.
— Difficult or impossible to establish a
reliable model.
• Non-parametric case:
— Separate the two gray level classes
in an optimum manner
according to some criterion
∗ between-class variance
∗ divergence
∗ entropy
∗ conservation of moments.
— Nonparametric methods are
more robust, and usually faster.
INF 5300, 2004, Lecture 1, page 4 of 21
Global and Non-contextual ?
Automatic versus Interactive
• Automatic means that the user does not
have to specify any parameters.
• There are no truly automatic methods,
always built-in parameters.
• Distinction between
automatic methods and
interactive methods.
• Distinction between
supervised (with training) and
unsupervised (clustering).
• Global methods
use single threshold for entire image
• Local methods
optimize new threshold for a number of
blocks or sub-images.
• Global methods put severe restrictions on
— the gray level characteristics
of objects and background
— the uniformity
in lighting and detection
• The fundamental framework of the
global methods is also applicable
to local sub-images.
• Non-contextual methods rely only on the
gray level histogram of the image.
• Contextual methods make use of the
geometrical relations between pixels.
INF 5300, 2004, Lecture 1, page 5 of 21
INF 5300, 2004, Lecture 1, page 6 of 21
Bi-level thresholding
• Histogram is assumed to be twin-peaked.
Let P1 og P 2 be the a priori probabilities
of background and foreground. (P1+P 2=1).
Two distributions given by b(z) and f (z).
The complete histogram is given by
p(z) = P1 · b(z) + P2 · f (z)
• The probabilities of mis-classifying a pixel,
given a threshold t:
Z
E1 (t) =
E2(t) =
t
−∞
Z ∞
E(t) = P1 ·
t
• We get a quadratic equation:
(σ12 − σ22) · T 2
+2(µ1σ22 − µ2σ12) · T
P1 σ 2
2 2
2 2
2 2
=0
+σ1 µ2 − σ2 µ1 + 2σ1 σ2 ln
P2 σ 1
• Two thresholds may be necessary !
b(z)dz
• If the two variances are equal
• The total error is :
∞
• For Gaussian distributions
2
(T −µ2 )2
1)
−
P
P1 − (T −µ
2
2
2
√
e 2σ1 = √
e 2σ2
2πσ1
2πσ2
f (z)dz
t
Z
Bi-level thresholding
b(z)dz + P2 ·
σB2 = σF2 = σ 2
Z
t
f (z)dz
−∞
• Differentiate with respect to the threshold t
∂E
= 0 ⇒ P1 · b(T ) = P2 · f (T )
∂t
INF 5300, 2004, Lecture 1, page 7 of 21
(µ1 + µ2)
σ2
P2
T =
+
ln
2
(µ1 − µ2)
P1
• If the a priori probabilities P1 og P2 are
equal
(µ1 + µ2)
T =
2
INF 5300, 2004, Lecture 1, page 8 of 21
The method of Ridler and Calvard
The method of Otsu
• Initial threshold value, t0, equal to average
brightness.
• Maximizes the a posteriori between-class
variance σB2 (t), given by
• Threshold value for k + 1-th iteration given
by
σB2 (t) = P1(t) [µ1(t) − µ0]2 + P2(t) [µ2(t) − µ0]2
tk+1
µ1(tk ) + µ2 (tk ) 1
=
=
2
2
"P
tk
zp(z)
Pz=0
tk
z=0 p(z)
+
PG−1
z=tk +1 zp(z)
PG−1
tk +1 p(z)
#
• µ1(tk ) is the mean value of the gray values
below the previous threshold tk , and µ2(tk )
is the mean value of the gray values above
the previous threshold.
• Note that µ1(t) and µ2(t) are the
a posteriorimean values, estimated from
overlapping and truncated distributions.
The a priori µ1 and µ2 are unknown to us.
• The correctness of the estimated threshold
depends on the extent of the overlap,
as well as on the correctness of the
P1 ≈ P2-assumption.
INF 5300, 2004, Lecture 1, page 9 of 21
2
• The sum of the within-class variance σW
and the between-class variance σB2 is equal
to the total variance σ02:
2
+ σB2 = σ02,
σW
2
.
• Maximizing σB2 ⇔ minimizing σW
• The expression for σB2 (t) reduces to
σB2 (t)
=
P1 (t)µ21 (t)
+
P2(t)µ22 (t)
−
µ20
[µ0 P1 (t) − µ1 (t)]2
.
=
P1 (t) [1 − P1(t)]
• Optimal threshold T is found by a sequential search
for the maximum of σB2 (t) for values of t where
0 < P1(t) < 1.
INF 5300, 2004, Lecture 1, page 10 of 21
The method of Reddi
Maximizing inter-class
variance for M thresholds
• The method of Reddi et al. is based on the same
assumptions as the method of Otsu, maximizing the
a posteriori between-class variance σB2 (t).
• The interclass variance reaches a maximum when
• We may write σB2 = P1 (t)µ21(t) + P2(t)µ22 (t) − µ20
hP
i2
P t
2
G−1
zp(z)
z=t+1
zp(z)
+ PG−1
− µ20
σB2 (t) = Pz=0
t
z=0 p(z)
z=t+1 p(z)
• Differentiating σB2 and setting δσB2 (t)/δt = 0, we find
a solution for
"P
#
PG−1
T
zp(z)
zp(z)
+1
+ Pz=T
= 2T
Pz=0
T
G−1
p(z)
z=0
z=T +1 p(z)
• This may be written as
µ1 (T ) + µ2 (T ) = 2T,
where µ1 and µ2 are the mean values below and
above the threshold.
• Exhaustive sequential search gives same result as
Otsu’s method.
• Starting with a threshold t0 = µ0 ,
fast convergence is obtained equivalent to
the ad hoc technique of Ridler and Calvard.
INF 5300, 2004, Lecture 1, page 11 of 21
µ(0, t1) + µ(t1 , t2) = 2t1
µ(t1 , t2) + µ(t2 , t3) = 2t2
.
.
µ(tM −1, tM ) + µ(tM , G) = 2tM
where µ(ti, tj ) is the mean value between
neighbouring thresholds ti and tj .
• Starting with an arbitrary set of initial thresholds
t1 , ..., tM we iteratively compute a new set of
0
0
thresholds t1, ..., tM by
1
0
t1 = (µ(0, t1) + µ(t1 , t2))
2
.
.
1
0
tM = (µ(tM −1, tM ) + µ(tM , G))
2
• The process is repeated until all thresholds are
stable.
• This procedure has a very fast convergence.
• It gives the same numerical results as the extensive
search technique of Otsu, but is orders of magnitude
faster in multi-level thresholding !
INF 5300, 2004, Lecture 1, page 12 of 21
A “minimum error” method
• Kittler and Illingworth (1985) assume a
mixture of two Gaussian distributions
(five unknown parameters).
Find T that minimizes the KL distance
between observed histogram and model
distribution.
J(t) = 1 + 2 [P1 (t)lnσ1(t) + P2(t)lnσ2 (t)]
−2 [P1 (t)lnP1 (t) + P2 (t)lnP2 (t)] .
• As t varies, model parameters change.
Compute J(t) for all t; find minimum.
• The criterion function has local minima at
the boundaries of the gray scale.
• An unfortunate starting value for an
iterative search may cause the iteration to
terminate at a nonsensical threshold value.
• The a posteriori model parameters will
represent biased estimates.
Correctness relies on small overlap.
Cho et al. (1989) have given improvement.
INF 5300, 2004, Lecture 1, page 13 of 21
Uniform error thresholding
• The uniform error threshold is given by
E1 (t) = E2 (t)
• Suppose we knew the background area α(t), and also
which pixels belonged to object and background.
• For a given threshold t, let
p(t) = fraction of background pixels above t
q(t) = fraction of object pixels with gray level above t.
• The uniform error threshold is then found when
p(t) = 1 − q(t)
or equivalently φ − 1 = 0, where φ = p + q.
• Now define
a = Prob (pixel gray level > t)
b = Prob (two neighbouring pixels both > t)
c = Prob (four neighbouring pixels all > t)
• Assuming that border effects may be neglected, we
may find these probabilities by examining all 2 × 2
neighbourhoods throughout the image.
• Alternatively, the above probabilities may be written
a = αp + (1 − α)q
b = αp2 + (1 − α)q 2
c = αp4 + (1 − α)q 4
INF 5300, 2004, Lecture 1, page 14 of 21
Uniform error thresholding - II
Maximum correlation thresholding
• Now we note that
(α2 − α)p4 + 2α(1 − α)p2q 2 + (1 − α)2 − (1 − α) q 4
b2 − c
=
a2 − b
(α2 − α)p2 + 2α(1 − α)pq + [(1 − α)2 − (1 − α)] q 2
(p2 − q 2 )2
=
= (p + q)2 = φ2 .
(p − q)2
• Select gray level t where | φ − 1 | is a minimum.
• φ − 1 is a monotonously decreasing function.
Root-finding algorithm instead of extensive search.
• No assumptions about underlying distributions, or
about a priori probabilities. Only estimates of a, b
and c for each trial value of t.
• Instead of one pass through the whole image for
each trial value of t, probabilities may be tabulated
for all possible values of t in one initial pass.
• For a given 2 × 2 neighbourhood, the four pixels are
sorted in order of increasing gray level, g1 , g2 , g3 , g4 .
Then for all thresholds t < g1 , the neighbourhood
has four single pixels, six pairs and one 4-tuple > t.
We may set up the scheme:
Threshold Rank
t < g1
g1 ≤ t < g 2
g2 ≤ t < g 3
g3 ≤ t < g 4
1
2
3
4
Number of
single pairs 4-tuples
4
3
2
1
6
3
1
1
• In a single pass through the image, a table may be formed,
giving estimates of a, b, c for all values of t.
INF 5300, 2004, Lecture 1, page 15 of 21
• Brink (1989) maximized the correlation
between the original gray level image f
and the thresholded image g.
• The gray levels of the two classes in the
thresholded image may be represented by
the two a posteriori average values µ1(t)
and µ1(t):
µ1(t) =
t
X
zp(z)/
z=0
µ2 (t) =
G−1
X
z=t+1
t
X
p(z)
z=0
zp(z)/
G−1
X
p(z)
z=t+1
• The correlation coefficient has a very
smooth behaviour, and starting with the
overall average graylevel value, the optimal
threshold may be found by a steepest
ascent search for the value T which
maximizes the correlation coefficient
ρf g (t).
G−1
ρf g (T ) = maxt=0
ρf g (t)
INF 5300, 2004, Lecture 1, page 16 of 21
Two-feature entropy
Entropy-based methods
• Kapur et al. proposed a thresholding
algorithm based on Shannon entropy.
• For two distributions separated by a
threshold t the sum of the two class
entropies is
• Abutaleb (1989) proposed a thresholding method based on
2 − D entropy. For two distributions and a threshold pair (s, t),
where s and t denote gray level and average gray level, the
entropies are
t
s X
X
pij pij
ln
H1(st) = −
P
Pst
i=0 j=0 st
H2(st) = −
where
ψ(t) = −
t
X
z=0
G−1
X
p(z)
p(z) p(z)
p(z)
ln
−
ln
P1 (t) P1 (t) z=t+1 1 − P1 (t) 1 − P1(t)
• Using
Ht = −
HG = −
t
X
p(z)ln(p(z))
z=0
G−1
X
p(z)ln(p(z))
z=0
the sum of the two entropies may be
written as
ψ(t) = ln [P1 (t)(1 − P1(t))] +
HG − H t
Ht
+
.
P1(t) 1 − P1(t)
• The discrete value T of t which maximizes
ψ(t) is now the selected threshold.
G−1 X
G−1
X
pij
pij
ln
1 − Pst 1 − Pst
i=s+1 j=t+1
Pst = −
s X
t
X
pij .
i=0 i=0
• The sum of the two entropies is now
ψ(s, t) = H1 (st) + H2 (st) = ln [Pst (1 − Pst )] +
Hst HGG − Hst
+
Pst
1 − Pst
where the total system entropy HGG and the partial entropy
Hst are given by
HGG = −
G−1
G−1
XX
i=0 j=0
pij ln(pij ), Hst = −
s X
t
X
pij ln(pij )
i=1 j=1
• The discrete pair (S, T ) which maximizes ψ(s, t) are now the
threshold values which maximize the loss of entropy, and
thereby the gain in information by introducing the two
thresholds.
• A much faster alternative is to treat the two features s and t
separately.
• In most cases, this gives an appreciable improvement over the
single feature entropy method of Kapur et al. (1985).
INF 5300, 2004, Lecture 1, page 17 of 21
INF 5300, 2004, Lecture 1, page 18 of 21
Preservation of moments
• Observed image f is seen as blurred version of
thresholded image g with gray levels z1 and z2.
• Find threshold T such that if all below-threshold
values in f are replaced by z1,
and all above-threshold values are replaced by z2 ,
then the first three moments are preserved.
• The i-th moment may be computed from the
normalized histogram p(z) by
mi =
G−1
X
pj (zj )i,
i = 1, 2, 3.
j=0
• Let P1 (t) and P2(t) denote a posteriori fractions of
below-threshold and above-threshold pixels in f .
• We want to preserve the moments
2
X
0
Pj (t)(zj )i = mi = mi =
j=1
and we have
G−1
X
pj (zj )i,
i = 1, 2, 3.
Solving the equations
• In the bi-level case, the equations are solved as
follows
m0 m1
cd =
m1 m2
c0 = (1/cd )
−m2 m1
−m3 m2
c1 = (1/cd )
m0 −m2
m1 −m3
h
i
z1 = (1/2) −c1 − (c21 − 4c0 )1/2
h
i
z2 = (1/2) −c1 + (c21 − 4c0 )1/2
Pd =
1 1
z1 z2
P1 = (1/Pd )
1 1
m2 z 2
j=0
P1 (t) + P2 (t) = 1
• The optimal threshold, T , is then chosen as the
P1 -tile (or the gray level value closest to the P1-tile)
of the histogram of f .
• Solving the four equations will give threshold T .
INF 5300, 2004, Lecture 1, page 19 of 21
INF 5300, 2004, Lecture 1, page 20 of 21
Exponential convex hull
• “Convex deficiency” is obtained by
subtracting the histogram from its convex
hull.
• This may work even if no “valley” exists.
• Upper concavity of histogram tail regions
can often be eliminated by considering
ln{p(z)} instead of the histogram p(z).
• In the ln{p(z)}-domain, upper concavities
are produced by bimodality or shoulders,
not by tail of normal or exponential,
nor by extension of histogram.
• Transform histogram p(z) by ln{p(z)},
compute convex hull, and transform
convex hull back to histogram domain by
he(k) = exp(h(k)).
• Threshold is found by sequential search for
maximum exponential convex hull
deficiency.
INF 5300, 2004, Lecture 1, page 21 of 21