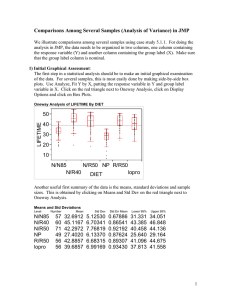
Chapter 9: Multiple Regression (2)
advertisement
")
Chapter 9: Multiple Regression (2)
We used several continuous predictors to build a model for log brain mass based on log body
mass. Multiple regression is also how we fit models involving classification variables (ANOVA
models) from Chapter 5. Let’s look again at the mice diets in 5.1. Here are the treatments used
> with(mice, tapply(lifetime,treatment,mean))
lopro
N/N85
NP
N/R40
N/R50
R/R50
39.68571 32.69123 27.40204 45.11667 42.29718 42.88571
and the coefficient estimates:
> summary(mice.lm)
Estimate Std. Error
t value
Pr(>|t|)
(Intercept)
39.685714 0.8924172 44.469910 1.870050e-144
treatmentN/N85 -6.994486 1.2565210 -5.566549 5.248159e-08
treatmentNP
-12.283673 1.3063651 -9.402941 7.794053e-19
treatmentN/R40
5.430952 1.2408558 4.376780 1.600946e-05
treatmentN/R50
2.611469 1.1935501 2.187984 2.934503e-02
treatmentR/R50
3.200000 1.2620686 2.535520 1.167155e-02
Residual standard error: 6.678 on 343 degrees of freedom
Multiple R-squared: 0.4543,Adjusted R-squared: 0.4463
F-statistic: 57.1 on 5 and 343 DF, p-value: < 2.2e-16
Which treatment does not show up in the coefficient list?
How do you compute treatment means from the coefficient estimates?
You may think of the coefficients as one for a “baseline” treatment and others which adjust the
baseline when we move to a different level of treatment. Different stat packages make different
choices in how to pick a baseline level of a factor. SAS chooses the last level (alphabetically
ordered).
We can write this out as a multiple regression model.
µ{y|x1 , x2 , x3 , x4 , x5 } = β0 + β1 x1 + β2 x2 + β3 x3 + β4 x4 + β5 x5
β0 is for the baseline group, and always get added in. The xi ’s are indicators. For any row of
the data (except for data points in the baseline group) one of the xi ’s will be 1 and the other
will be zero, so only one of β1 · · · , β5 gets used at a time.
One of the planned contrasts was to compare lopro to N/R50. Which coefficient does this?
Four of the five comparisons desired are to N/R50. Let’s make this our baseline by building
indicators for the others.
> dim(mice)
[1] 349
2
## 349 rows of data
## create 5 dummy variables.
First make them all zeroes.
5
>
>
>
>
>
>
lopro <- N.N85 <- NP <- N.R40 <- R.R50 <lopro[which(mice$treatment == "lopro")] =
N.N85[which(mice$treatment == "N/N85")] =
NP[which(mice$treatment == "NP")] = 1
N.R40[which(mice$treatment == "N/R40")] =
R.R50[which(mice$treatment == "R/R50")] =
rep(0,349)
1 ## change the right rows to 1’s
1 ## for each
## in turn
1
1
Fit these indicators as in a multiple regression. Now what is the ”intercept” estimating?
> summary(mice.fit2 <- lm(lifetime ~ lopro + N.N85 + NP + N.R40 + R.R50,mice))
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 42.2972
0.7926 53.368 < 2e-16
lopro
-2.6115
1.1936 -2.188
0.0293
N.N85
-9.6060
1.1877 -8.088 1.06e-14
NP
-14.8951
1.2403 -12.009 < 2e-16
N.R40
2.8195
1.1711
2.408
0.0166
R.R50
0.5885
1.1936
0.493
0.6223
Residual standard error: 6.678 on 343 degrees of freedom
Multiple R-squared: 0.4543,Adjusted R-squared: 0.4463
F-statistic: 57.1 on 5 and 343 DF, p-value: < 2.2e-16
We wanted to compare 4 of the treatments (N/N85, lopro, R/R50, and N/R50) to N/R50.
It’s now easy to build CI’s for those planned comparisons. The fifth comparison, NP to N/N85,
will have to be done using contrasts with C2 = 1, C3 = −1, and the other Cj = 0.
The two models we have fit are just different versions of the same model. To see that we
could use anova, or compare the residuals.
> anova(mice.fit1,mice.fit2)
Analysis of Variance Table
Model 1: lifetime ~ treatment
Model 2: lifetime ~ lopro + N.N85 + NP + N.R40 + R.R50
Res.Df
RSS Df Sum of Sq F Pr(>F)
1
343 15297
2
343 15297 0 2.0009e-11
## really a zero
> which(abs( resid(mice.fit1)-resid(mice.fit2) ) > 1.0e-11)
named integer(0)
The anova function attempts to do an ESS F test, but the extra sum of squares is zero, and
the two models use the same 5 df, so it can’t compute the F ratio. None of the differences in
residuals is greater than 10−11 . Note that each model uses 5 degrees of freedom to fit the six
levels of the predictor.
Meadowfoam Example, §9.3.2 –9.3.4
In the meadowfoam experiment, we have two predictors: timing of extra light is either day0 or
day24, and light intensity takes on six values. We can build indicator variables for these factors
as we did above. The light intensity variable can be considered continuous, or (to look at lack
of fit) as a factor with 6 levels.
> mfoam <- read.table("data/meadowfoam.txt",head=T)
> mfoam$time <- factor(mfoam$time, labels=c("day0","day24"))
## replaces the old numeric variable with a factor
> mfoam$Intens <- factor(mfoam$intensity)
## creates a new variable so we can use both factor and continuous versions.
> plot(flowers ~ intensity, pch = rep(c(1,16),each=12),mfoam)
> legend("topright",pch=c(1,16), c("Day 0","Day 24"))
## one line is not going to fit well.
6
> mfoam.fit1 <- lm(flowers ~ intensity,mfoam)
> coef(mfoam.fit1)
(Intercept)
intensity
77.38500000 -0.04047143
> abline( 77.385, -0.0405, col="gray")
## do we want two parallel lines?
> mfoam.fit2 <- lm(flowers ~ intensity + time,mfoam)
> coef(mfoam.fit2)
(Intercept)
intensity
timeday24
71.30583333 -0.04047143 12.15833333
> abline( 71.306, -0.0405,lty=2,col=4)
> abline(71.306+ 12.158, -0.0405,lty=2,col=4)
## or 2 lines which are not required to be parallel?
mfoam.fit3 <- lm(flowers ~ intensity + time + intensity*time,mfoam)
coef(mfoam.fit3)
(Intercept)
intensity
timeday24 intensity:timeday24
71.623333333
-0.041076190
11.523333333
0.001209524
> abline( 71.623,
-0.04108,col=2,lty=1)
> abline( 71.623 + 11.523 ,
-0.04108 +
0.00121 ,col=2,lty=1)
## not much different, We’ll want to pick the simpler model.
>
>
●
60
●
●
●
●
●
Both
Day 0
Day 24
●
●
●
●
●
●
●
50
●
●
40
●
●
●
●
●
●
●
●
30
flowers
70
●
●
200
400
600
800
intensity
Let’s look at the possible models.
1. One slope.
µ{y|x1 } or µ{flowers | light} = β0 + β1 x1
d = 77.385 − 0.0405 · light
flowers
2. Two parallel lines. What is this model when x2 = 0? when x2 = 1?
µ{y|x1 , x2 } or µ{flowers | light, time} = β0 + β1 x1 + β2 x2
d = 71.306 − 0.0405 · light + 12.158 · day24
flowers
3. Two lines with arbitrary slope. What is this model when x2 = 0? when x2 = 1?
µ{y|x1 , x2 } or µ{flowers|light, time} = β0 + β1 x1 + β2 x2 + β3 x1 x2
d = 71.62 − 0.04108 · light + 11.523 · day24 + 0.00121 · light · day24
flowers
7
The third model uses what is called an “interaction” between the two predictors. An interaction
is present when the effect of the first predictor depends on the value of the second predictor.
In this case, we are trying to tell if the effect of light on flowers (a slope) changes with the timing
of the light. Or, if the distance between the two lines (the timing effect) varies from low light
intensity (left side of the plot) to high (right side). If the two slopes differ, then the distance
between the lines is changing.
Here’s the full model summary of the third model:
> summary( mfoam.fit3)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept)
71.623333
4.343305 16.491 4.14e-13
intensity
-0.041076
0.007435 -5.525 2.08e-05
timeday24
11.523333
6.142360
1.876
0.0753
intensity:timeday24 0.001210
0.010515
0.115
0.9096
Residual standard error: 6.598 on 20 degrees of freedom
Multiple R-squared: 0.7993,Adjusted R-squared: 0.7692
F-statistic: 26.55 on 3 and 20 DF, p-value: 3.549e-07
Compare to Display 9.14. Our timeDay24 effect they have labeled “early”.
Let’s use sequential ESS F tests on our third model.
> anova( mfoam.fit3) ## could also include all 3 models here
Analysis of Variance Table
Response: flowers
Df Sum Sq Mean Sq F value
Pr(>F)
intensity
1 2579.75 2579.75 59.2597 2.101e-07
time
1 886.95 886.95 20.3742 0.0002119
intensity:time 1
0.58
0.58 0.0132 0.9095675
Residuals
20 870.66
43.53
Conclusions:
There is a significant (negative) effect of light intensity on the number of flowers (F = 59.3
on 1,20 df, p-value = 2.1×10−7 ). The estimated slope -0.0411 (SE = 0.0074) is conditional on
having an adjustment in the model allowing different intercepts for timing.
The effect of timing on flowers (after accounting for the light intensity effect) is also significant
(F = 20.4 on 1,20 df, p-value = 2.1×10−4 ) with an increase in flowering estimated as 11.5
(SE=6.14) for beginning the extended lighting 24 days before PFI. The interaction between the
two predictors is not significant (F = 0.13 on 1, 20 df, p-value = .91).
We can also fit a model with a mean for each of the 12 treatment combinations by using
intensity as a factor.
> mfoam.fit4 <- lm(flowers ~ Intens * time,mfoam)
> anova( mfoam.fit2,mfoam.fit4)
Analysis of Variance Table
Model 1:
Model 2:
Res.Df
1
21
2
12
flowers ~ intensity + time
flowers ~ Intens * time
RSS Df Sum of Sq
F Pr(>F)
871.24
655.92 9
215.31 0.4377 0.8894
This F test is assessing the lack of fit. The null hypothesis is that the 2 parallel lines model
is adequate, the alternative: that we should fit 12 separate means instead. We fail to reject, and
conclude that the lack of fit is not significant.
8
More on Building Indicators and the Software
It’s more efficient to use the ifelse function in R like this:
>
R.R50 <- ifelse(mice$treatment == "R/R50", 1, 0)
## instead of
> R.R50 <- rep(0,349)
> R.R50[which(mice$treatment == "R/R50")] = 1 ## change the right rows to 1’s
In both constructs, note the use of double equals signs when we want to ask “are two things
equal?”. That’s different from assigning a value to an object, or passing an argument to a
function; both of those use a single equals sign. You can look at what factor does using the
contrast function which shows what the unique rows look like.
> contrasts(mfoam$Intens)
300 450 600 750 900
150
0
0
0
0
0
300
1
0
0
0
0
450
0
1
0
0
0
600
0
0
1
0
0
750
0
0
0
1
0
900
0
0
0
0
1
## first row is all zeroes
## because R skips the L150 indicator
> contrasts(mfoam$time)
day24
day0
0
day24
1
Important Practice
What are the fitted models, with and without interactions?
> round(coef(mfoam.fit2),3)
(Intercept)
intensity
timeday24
71.306
-0.040
12.158
> round(coef(mfoam.fit3),3)
(Intercept)
intensity
71.623
-0.041
timeday24 intensity:timeday24
11.523
0.001
Write out each model for two cases: day24 = 0 and day24 = 1.
9
The full 12–mean model uses dummy variables as shown above. What are the 12 fitted
values?
> round(coef(mfoam.fit4),3) ## (I added number after R spit out its labels)
(1)(Intercept)
(2)Intens300
(3)Intens450
(4)Intens600
69.85
-15.10
-14.10
-27.30
(5)Intens750
(6)Intens900
(7)timeday24 (8)Intens300:timeday24
-31.75
-30.50
6.85
11.95
(9)Intens450:timeday24 (10)Intens600:timeday24 (11)Intens750:timeday24 (12)Intens900:timeday24
1.45
8.15
8.00
2.30
Which coefficients go into estimating which means? In this first table just write in the
coefficient numbers (1 to 12) which I added to the R output above.
L150
L300
L450
L600
L750
L900
day0
day24
Now add those values to get the means.
L150
L300
L450
L600
L750
L900
day0
day24
Summary:
The mean number of flowers is well described by a regression model with a single slope (negative)
on light intensity and a different (higher) intercept for beginning extended lighting 24 days before
PFI (as opposed to waiting for PFI before increasing hours of lighting).
Scope:
Because this was a randomized experiment, we can infer cause-effect relationships between the
predictors and the response. It is not clear where the seedlings came from. They were probably
a convenience sample of some sort, so inference extends to the sample. Experts could (probably
should) argue that these plants are representative of some larger population of meadowfoam
plants, but the statistical inference extends only to the plants which could have been used in
the experiment.
10